滴滴Flink-1.10升级之路

桔妹导读:滴滴实时计算引擎从Flink-1.4无缝升级到Flink-1.10版本,做到了完全对用户透明。并且在新版本的指标、调度、SQL引擎等进行了一些优化,在性能和易用性上相较旧版本都有很大提升。这篇文章介绍了我们升级过程中遇到的困难和思考,希望能给大家带来启发。
1.
背景

在本次升级之前,我们使用的主要版本为Flink-1.4.2,并且在社区版本上进行了一些增强,提供了StreamSQL和低阶API两种服务形式。现有集群规模达到了1500台物理机,运行任务数超过12000 ,日均处理数据 3万亿条左右。
不过随着社区的发展,尤其是Blink合入master后有很多功能和架构上的升级,我们希望能通过版本升级提供更好的流计算服务。今年2月份,里程碑版本Flink-1.10发布,我们开始在新版上上进行开发工作,踏上了充满挑战的升级之路。
2.
Flink-1.10新特性
作为Flink社区至今为止的最大的一次版本升级,加入的新特性解决了之前遇到很多的痛点。
▍1. 原生DDL语法与Catalog支持
FlinkSQL原生支持了DDL语法,比如CREATE TABLE/CREATE FUNCTION,可以使用SQL进行元数据的注册,而不需要使用代码的方式。
也提供了Catalog的支持,默认使用InMemoryCatalog将信息临时保存在内存中,同时也提供了HiveCatalog可以与HiveMetastore进行集成。也可以通过自己拓展Catalog接口实现自定义的元数据管理。
▍2.FlinkSQL的增强
基于ROW_NUMBER实现的TopN和去重语法,拓展了StreamSQL的使用场景。
实现了BinaryRow类型作为内部数据交互,将数据直接以二进制的方式构建而不是对象数组,比如使用一条数据中的某个字段时,可以只反序列其中部分数据,减少了不必要的序列化开销。
新增了大量内置函数,例如字符串处理、FIRST/LAST_VALUE等等,由于不需要转换为外部类型,相较于自定义函数效率更高。
增加了MiniBatch优化,通过微批的处理方式提升任务的吞吐
▍3.内存配置优化
之前对Flink内存的管理一直是一个比较头疼的问题,尤其是在使用RocksDB时,因为一个TaskManager中可能存在多个RocksDB实例,不好估算内存使用量,就导致经常发生内存超过限制被杀。
在新版上增加了一些内存配置,例如 state.backend.rocksdb.memory.fixed-per-slot可以轻松限制每个slot的RocksDB内存的使用上限,避免了OOM的风险。
3.
挑战与应对
本次升级最大的挑战是,如何保证StreamSQL的兼容性。StreamSQL的目的就是为了对用户屏蔽底层细节,能够更加专注业务逻辑,而我们可以通过版本升级甚至更换引擎来提供更好的服务。保证任务的平滑升级是最基本的要求。
▍1. 内部patch如何兼容
由于跨越多个版本架构差距巨大,内部patch基本无法直接合入,需要在新版本上重新实现。我们首先整理了所有的历史commit,筛选出那些必要的修改并且在新版上进行重新实现,目的是能覆盖已有的所有功能,确保新版本能支持现有的所有任务需求。
例如:
新增或修改Connectors以支持公司内部需要,例如DDMQ(滴滴开源消息队列产品),权限认证功能等。
新增Formats实现,例如binlog,内部日志采集格式的解析等。
增加ADD JAR语法,可以在SQL任务中引用外部依赖,比如UDF JAR,自定义Source/Sink。
增加SET语法,可以在SQL中设置TableConfig,指导执行计划的生成
▍2. StreamSQL语法兼容
社区在1.4版本时,FlinkSQL还处于比较初始的阶段,也没有原生的DDL语法支持,我们使用Antlr实现了一套自定义的DDL语法。但是在Flink1.10版本上,社区已经提供了原生的DDL支持,而且与我们内部的语法差别较大。现在摆在我们面前有几条路可以选择:
a.放弃内部语法的支持,修改全部任务至新语法。(违背了平滑迁移的初衷,而且对已有用户学习成本高)
b.修改Flink内语法解析的模块(sql-parser),支持对内部语法的解析。(实现较为复杂,且不利于后续的版本升级)
c.在sql-parser之上封装一层语法转换层,将原本的SQL解析提取有效信息后,通过字符串拼接的方式组织成社区语法再运行。
最终我们选用了第三种方案,这样可以最大限度的减少和引擎的耦合,作为插件运行,未来再有引擎升级完全可以复用现有的逻辑,能够降低很多的开发成本。
例如:我们在旧版本上使用"json-path"的库实现了json解析,通过在建表语句里定义类似$.status的表达式表示如何提取此字段。

新版本上原生的json类型解析可以使用ROW类型来表示嵌套结构,在转换为新语法的过程中,将原本的表达是解析为树并构建出新的字段类型,再使用计算列的方式提取出原始表中的字段,确保表结构与之前一致。类型名称、配置属性也通过映射转换为社区语法。

▍3. 兼容性测试
最后是测试阶段,需要进行完善的测试确保所有任务都能做到平滑升级。我们原本的计划是准备进行回归测试,对已有的所有任务替换配置后进行回放,但是在实际操作中有很多问题:
测试流程过长,一次运行可能需要数个小时。
出现问题时不好定位,可能发生在任务的整个生命周期的任何阶段。
无法验证计算结果,即新旧版本语义是否一致
所以我们按任务的提交流程分成多个阶段进行测试,只有在当前阶段能够全部测试通过后后进入下一个阶段测试,提前发现问题,将问题定位范围缩小到当前阶段,提高测试效率。

转换测试:对所有任务进行转换,测试结果符合预期,抽象典型场景为单元测试。
编译测试:确保所有任务可以通过TablePlanner生成执行计划,在编译成JobGraph,真正提交运行前结束。
回归测试:在测试环境对任务替换配置后进行回放,确认任务可以提交运行
对照测试:对采样数据以文件的形式提交至新旧两个版本中运行,对比结果是否完全一致(因为部分任务结果不具有确定性,所以使用旧版本连续运行2次,筛选出确定性任务,作为测试用例)
4.
引擎增强
除了对旧版本的兼容,我们也结合了新版本的特性,对引擎进行了增强。
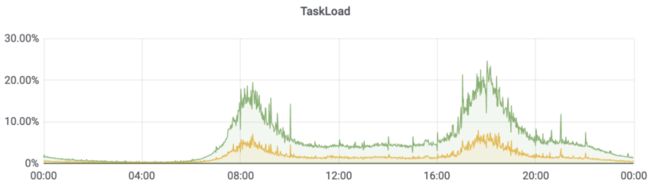
▍1. Task-Load指标
我们一直希望能精确衡量任务的负载状况,使用反压指标指标只能粗略的判断任务的资源够或者不够。
结合新版的Mailbox线程模型,所有互斥操作全部运行在TaskThread中,只需统计出线程的占用时间,就可以精确计算任务负载的百分比。
未来可以使用指标进行任务的资源推荐,让任务负载维持在一个比较健康的水平。
▍2. SubTask均衡调度
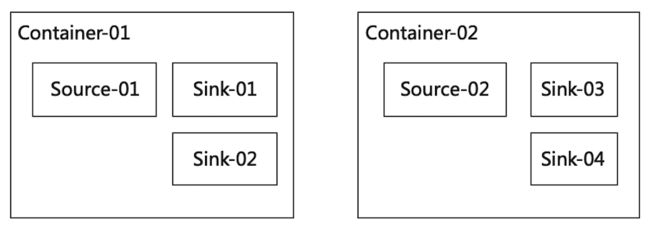
在FLIP-6后,Flink修改了资源调度模型,移除了--container参数,slot按需申请确保不会有闲置资源。但是这也导致了一个问题,Source的并发数常常是小于最大并发数的,而SubTask调度是按DAG的拓扑顺序调度,这样SourceTask就会集中在某些TaskManager中导致热点。

我们加入了"最小slot数"的配置,保证在Flink session启动后立即申请相应数量的slot,且闲置时也不主动退出,搭配cluster.evenly-spread-out-slots参数可以保证在slot数充足的情况下,SubTask会均匀分布在所有的TaskManager上。
▍3. 窗口函数增强
以滚动窗口为例 TUMBLE(time_attr, INTERVAL '1' DAY),窗口为一天时开始和结束时间固定为每天0点-24点,无法做到生产每天12点-次日12点的窗口。
对于代码可以通过指定偏移量实现,但是SQL目前还未实现,通过增加参数TUMBLE(time_attr, INTERVAL '1' DAY, TIME '12:00:00')表示偏移时间为12小时。
还有另外一种场景,比如统计一天的UV,同时希望展示当前时刻的计算结果,例如每分钟触发窗口计算。对于代码开发的方式可以通过自定义Trigger的方式决定窗口的触发逻辑,而且Flink也内置了一些Tigger实现,比如ContinuousTimeTrigger就很适合这种场景。所以我们又在窗口函数里增加了一种可选参数,代表窗口的触发周期,TUMBLE(time_attr, INTERVAL '1' DAY, INTERVAL '1' MINUTES) 。
通过增加offset和tiggger周期参数(TUMBLE(time_attr, size[,offset_time][,trigger_interval])),拓展了SQL中窗口的使用场景,类似上面的场景可以直接使用SQL开发而不需要使用代码的方式。
▍4. RexCall结果复用
在很多SQL的使用场景里,会多次使用上一个计算结果,比如将JSON解析成Map并提取多个字段

虽然通过子查询,看起来json解析只调用一次,但是经过引擎的优化后,通过结果表的投影(Projection)生成函数调用链(RexCall),结果类似

这样会导致json解析的计算重复运行了3次,即使使用视图分割成两步操作,经过Planner的优化一样会变成上边的样子。
对于确定性(isDeterministic=true)的函数来说,相同的输入一定代表相同的结果,重复执行3次json解析其实是没有意义的,如何优化才能实现对函数结果的复用呢?
在代码生成时,将RexCall生成的唯一标识(Digest)和变量符号的映射保存在CodeGenContext中,如果遇到Digest相同的函数调用,则可以复用已经存在的结果变量,这样解析JSON只需要执行第一次,之后就可以复用第一次的结果。
5.
总结
通过几个月的努力,新版本已经上线运行,并且作为StreamSQL的默认引擎,任务重启后直接使用新版本运行。兼容性测试的通过率达到99.9%,可以基本做到对用户的透明升级。对于新接触StreamSQL用户可以使用社区SQL语法进行开发,已有任务也可以修改DML部分语句来使用新特性。现在新版本已经支持了公司内许多业务场景,例如公司实时数据仓库团队依托于新版本更强的表达能力和性能,承接了多种多样的数据需求做到稳定运行且与离线口径保持一致。
版本升级不是我们的终点,随着实时计算的发展,公司内也有越来越多团队需要使用Flink引擎, 也向我们提出了更多的挑战,例如与Hive的整合做到将将结果直接写入Hive或直接使用Flink作为批处理引擎,这些也是我们探索和发展的方向,通过不断的迭代向用户提供更加简单好用的流计算服务。
本文作者
▬

团队招聘
▬
滴滴大数据架构部主要负责滴滴大数据存储与计算等引擎的开发与运维工作,通过持续应用和研发新一代大数据技术,构建稳定可靠、高性能、低成本的大数据基础设施,更多赋能业务,创造更多价值。团队近期招聘:
Flink/ClickHouse/ElasticSearch/HDFS/Presto/融合计算等领域专家,参与滴滴大数据建设工作,欢迎加入。可投递简历至

扫码了解更多岗位
延伸阅读
▬



内容编辑 | Mango
联系我们 | [email protected]