Pandas学习-期末测试
习题链接:http://datawhale.club/t/topic/579/7
任务四以及任务五的第一题是完整的做完的,任务五的其余小问把能做的尽量都做了。时间处理部分完成的还是不太ok,这部分没有熟练掌握,所以难哭了…等之后熟练之后会重新做的。还有呀,我之前觉得理解稍微有点困难的长宽表转换,现在用得66的哈哈哈,真有大用处!
暑假再开课的时候,我一定还要再学一遍!谢谢Datawhale这么好的资源和平台,以及Datawhale中这一群有能力有想法的人儿们~最后再谢谢耿老师!!!耐心且及时的答疑!!!耿老师之后要开的课,我都报名!哈哈哈
【任务四】显卡日志
下面给出了3090显卡的性能测评日志结果,每一条日志有如下结构:
Benchmarking #2# #4# precision type #1#
#1# model average #2# time : #3# ms
其中#1#代表的是模型名称,#2#的值为train(ing)或inference,表示训练状态或推断状态,#3#表示耗时,#4#表示精度,其中包含了float, half, double三种类型,下面是一个具体的例子:
Benchmarking Inference float precision type resnet50
resnet50 model average inference time : 13.426570892333984 ms
请把日志结果进行整理,变换成如下状态,model_i用相应模型名称填充,按照字母顺序排序,数值保留三位小数:

【数据下载】链接:https://pan.baidu.com/s/1CjfdtavEywHtZeWSmCGv3A 提取码:4mui
【我的思考】:
- 首先是需要把txt文件中相应有用的信息(
模型名字, Train or Inference, Float or Half of Double, 时间)提取出来。 - 然后就是将信息存入表中的问题,我是先尝试将一条信息提取出来,然后再尝试将它存入表中。过程中就启发了我,将每一条(即每两行)的信息存入列表中,再将列表的值赋值为DataFrame表的一行。
- 看到目标格式让我想到了可以长宽表的转换。
【我的解答】:
- 读取txt文件内容
import numpy as np
import pandas as pd
df = pd.read_table('benchmark.txt', header=None)
df

发现所有的内容都在df[0]里面,没有按照分行存储。其实自己也有思考了使用sep来设定空格为分隔符的,但是发现提取出来更乱了。
- 新建一个DataFrame表来存储有用的信息
df_final = pd.DataFrame(columns= ['model_name', 'Train_Infer', 'FHD', 'Time'])
df_final
- 我们可以发现每两行为一个信息,所以将每两行的关键信息存储到一个列表中,再将其赋值给DataFrame的行。
for i in range(0, len(list(df[0]))-1, 2):
temp = []
temp.append(list(df[0])[i].split(' ')[5])
temp.append(list(df[0])[i+1].split(' ')[4])
temp.append(list(df[0])[i].split(' ')[2])
temp.append(list(df[0])[i+1].split(' ')[8])
df_final.loc[i/2] = temp
df_final

过程中遇到了报错:IndexError: list index out of range,原因是因为文件的最后两行不是这个数据,所以单词数(索引数)是不同的。
解决办法:将最后两行删除即可。
- 将时间改为小数点后三位的数
df_final['Time'] = df_final['Time'].astype(float).round(3)
df_final
- 根据模型的名字、状态、精度来分组,并将结果转化为DataFrame的表。
df_trans = df_final.groupby(['model_name','Train_Infer','FHD'])['Time'].sum().reset_index()
df_trans
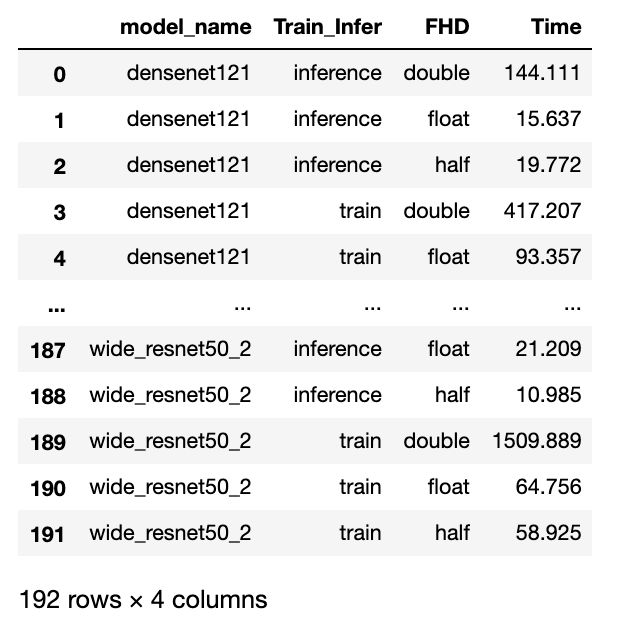
- 长表变宽表,设置为多层索引的宽表。
df_multi=df_trans.pivot(index='model_name',
columns=['Train_Infer','FHD'],
values='Time')
df_multi
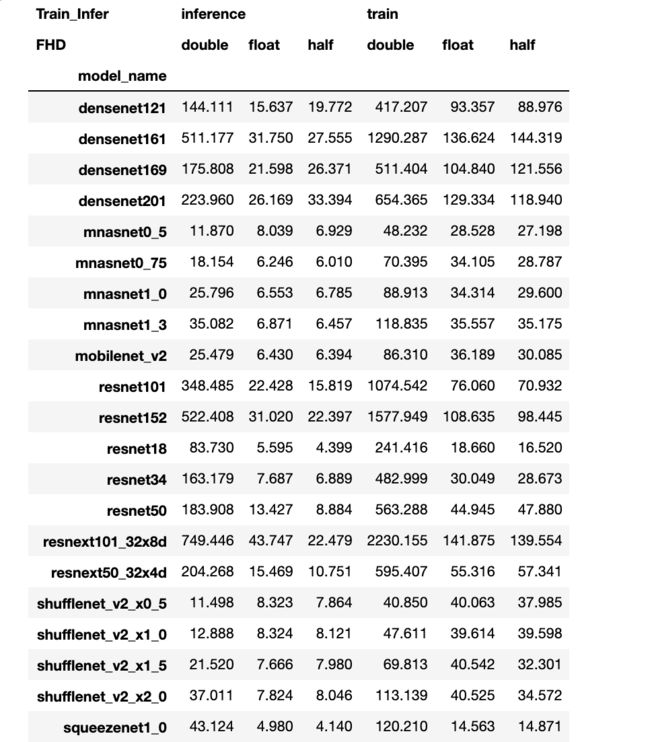
- 将多层索引的名字压缩为单层索引
new_cols=df_multi.columns.map(lambda x: (x[0]+'_'+x[1]))
df_multi.columns = new_cols
df_multi
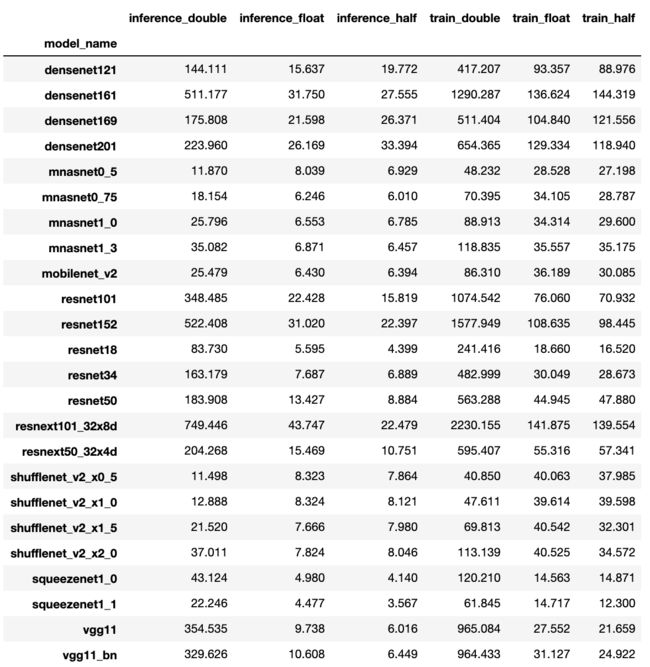
完成一题!赞哈哈哈~继续继续下一题!
【任务五】水压站点的特征工程
df1和df2中分别给出了18年和19年各个站点的数据,其中列中的H0至H23分别代表当天0点至23点;df3中记录了18-19年的每日该地区的天气情况,请完成如下的任务:
import pandas as pd
import numpy as np
df1 = pd.read_csv('yali18.csv')
df2 = pd.read_csv('yali19.csv')
df3 = pd.read_csv('qx1819.csv')
通过df1和df2构造df,把时间设为索引,第一列为站点编号,第二列为对应时刻的压力大小,排列方式如下(压力数值请用正确的值替换):
站点 压力
2018-01-01 00:00:00 1 1.0
2018-01-01 00:00:00 2 1.0
... ... ...
2018-01-01 00:00:00 30 1.0
2018-01-01 01:00:00 1 1.0
2018-01-01 01:00:00 2 1.0
... ... ...
2019-12-31 23:00:00 30 1.0
【我的解答】:
- 先将站点这列完成,用df1来做实验。即将原
MeasName这一列的值进行分割,取站点的数字作为值并命名该列为“站点”,最后再删除原MeasName这一列。
df1 = pd.read_csv('yali18.csv')
df1['站点'] = df1.MeasName.str.split('站点').apply(lambda x: x[1])
df2.drop(['MeasName'],inplace=True,axis=1)

- 将宽表变为长表,把时间(小时)的值收回为一列。
df2_trans = df2.melt(id_vars=['Time','站点'],
value_vars = df2.columns[1:-1],
var_name = 'Hour',
value_name = '压力')
df2_trans

- 将时刻的值取出来,但是不知道应该怎么使用to_datetime来怎么将
Time,Hour1作为一列表示对应的时间戳。
df2_trans['Hour1'] = df2_trans.Hour.str.split('H').apply(lambda x: x[1])
df2_trans.drop(['Hour'],inplace=True,axis=1)
df2_trans

- 教程的编写者GYH大佬说,直接使用字符串连接比较简单,这一下子为我打开了思路。连接字符串,然后将格式转换为时间戳格式。
df2_trans['Time'] = df2_trans.Time +' ' + df2_trans['Hour1'] + ':00:00'
df2_trans.drop(['Hour1'],inplace=True,axis=1)
df2_trans['Time'] = pd.to_datetime(df2_trans['Time'], format="%Y-%m-%d %H:%M:%S")
df2_trans
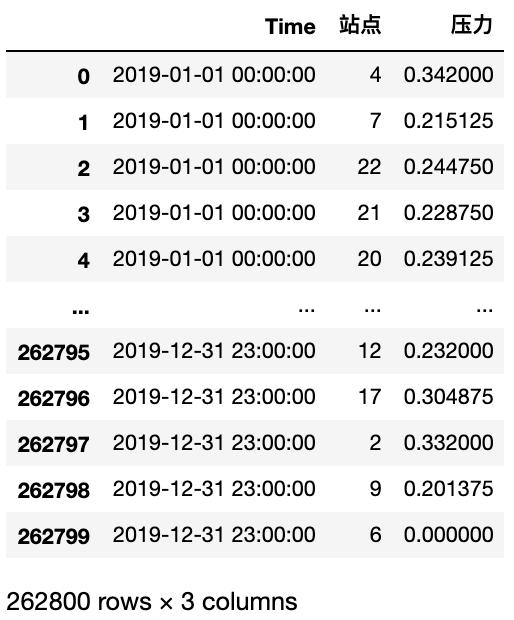
【完整代码】:
df1 = pd.read_csv('yali18.csv')
df2 = pd.read_csv('yali19.csv')
df = pd.concat([df1,df2])
df['站点'] = df.MeasName.str.split('站点').apply(lambda x: x[1])
df.drop(['MeasName'],inplace=True,axis=1)
df_trans = df.melt(id_vars=['Time','站点'],
value_vars = df.columns[1:-1],
var_name = 'Hour',
value_name = '压力')
df_trans['Hour1'] = df_trans.Hour.str.split('H').apply(lambda x: x[1])
df_trans.drop(['Hour'],inplace=True,axis=1)
df_trans['Time'] = df_trans.Time +' ' + df_trans['Hour1'] + ':00:00'
df_trans.drop(['Hour1'],inplace=True,axis=1)
df_trans['Time'] = pd.to_datetime(df_trans['Time'], format="%Y-%m-%d %H:%M:%S")
df_trans = df_trans.set_index('Time')
df_trans
在上一问构造的df基础上,构造下面的特征序列或DataFrame,并把它们逐个拼接到df的右侧
1、当天最高温、最低温和它们的温差
- 使用
str对象的split方法将某列的值拆开为两列
df3[['最高温', '最低温']] = df3['气温'].str.split('~', n=1, expand=True)
df3
- 为了方便计算温差,将温度的单位去掉。
df3['最高温'] = df3['最高温'].apply(lambda x: x.strip()[:-1])
df3['最低温'] = df3['最低温'].apply(lambda x: x.strip()[:-1])
- 用最高温所在列减去最低温所在列,得到温差作为新的一列。
df3['温差'] = pd.to_numeric(df3['最高温'], errors='ignore') - pd.to_numeric(df3['最低温'], errors='ignore')

2、当天是否有沙暴、是否有雾、是否有雨、是否有雪、是否为晴天
3、选择一种合适的方法度量雨量/下雪量的大小(构造两个序列分别表示二者大小)
4、限制只用4列,对风向进行0-1编码(只考虑风向,不考虑大小)
- 保留与风向有关的信息,去掉风的级数。
- 处理包含“转”的风,分为风向1与风向2。
- 去掉风字,只保留风向1的方向。
- 对风向进行特征编码。
df3['风向'] = df3['风向'].apply(lambda x: re.findall('\w+', x)[0])
df3[['风向1','风向2']] = df3['风向'].str.split('转', expand=True)
df3['风向1'] = df3['风向1'].apply(lambda x: x[0:1])
df3.drop(columns='风向2',inplace=True,axis=1)
pd.get_dummies(df3['风向1'])

对df的水压一列构造如下时序特征:
- 当前时刻该站点水压与本月的相同整点时间该站点水压均值的差,例如当前时刻为2018-05-20 17:00:00,那么对应需要减去的值为当前月所有17:00:00时间点水压值的均值
- 当前时刻所在周的周末该站点水压均值与工作日水压均值之差
- 当前时刻向前7日内,该站点水压的均值、标准差、0.95分位数、下雨天数与下雪天数的总和
- 当前时刻向前7日内,该站点同一整点时间水压的均值、标准差、0.95分位数
- 当前时刻所在日的该站点水压最高值与最低值出现时刻的时间差
【数据下载】链接:https://pan.baidu.com/s/1Tqad4b7zN1HBbc-4t4xc6w 提取码:ijbd