分治算法详细讲解(含经典例题分析)
分治法思路:
将整个问题分解成若干小问题后再分而治之。如果分解得到的子问题相对来说还是太大,则可反复使用分治策略将这些子问题分成更小的同类型子问题,直至产生方便求解的子问题,必要时逐步合并这些子问题的解,从而得到问题的解。
分治算法可以由递归过程来表示,因为分治法就是一种找大规模问题与小规模问题关系的方法,是递归设计的一种具体策略。
步骤
1.分解
将原问题分解为若干规模较小,相互独立,与原问题相同的子问题。
2.解决
若干子问题较小而容易被解决则直接解决,否则再继续分解为更小的子问题,直到容易解决。
3.合并
将已求解的各个子问题的解,逐步合并为原问题的解。
有的问题分解后不需要合并子问题的解,此时就不需要再做第3步了。多数问题需要子问题的解,按照题意使用恰当的方法合并成为整个问题的解。需要具体问题具体分析。
算法框架
分治法的一般算法设计模式如下:
Divide-and-Conquer(int n){
if(n<=n0){
//n为问题规模 ,n0为可解子问题的规模
解子问题;
return(子问题的解);
}
for(i=1;i<=k;i++){
//分解成较小的子问题p1,p2,...,pk
yi=Divide-and-Conquer(|Pi|);//递归解决
}
T=MERGE(y1,y2,...yk);//合并子问题
return(T);//返回问题的解
}
典型二分法
(一)
在算法设计中,每次一个问题分解成的子问题个数一般是固定的,每个子问题的规模也是平均分配的。当每次都将问题分解为原问题规模的一半时,称为二分法。
二分法是分治法较常用的分解策略,数据结构课程中的折半查找、归并排序等算法都是采用此策略实现的。
问题:金块问题
老板有一袋金块(共n块),最优秀的雇员得到其中最重的一块,最差的雇员得到其中最轻的一块,假设有一台比较重量的仪器,我们希望用最少的比较次数找出最重的金块。
方法1:逐个查找比较
最简单的方就是逐个的比较查找,算法类似于选择排序。先拿两块进行比较,留下最重的与下一块比较,直到全部比较完毕就找到了最重的金子
完整代码如下:
//金块算法1:逐个查找比较
#include方法2:分治法(二分法)
1.将数据等分为两组(两组数据可能差1),目的是分别选取其中最大值(最小值)。
2.递归分解直到每组元素的个数不大于2,可简单的找到最大值(最小值)。
3.回溯时将分解的两组解大者取大,小者取小
用分治法可以用较少的比较次数解决问题。
完整代码如下:
//金块算法2:运用递归实现分半查询
#include(二)二分法不相似情况
需要构造与原问题相似子问题。
问题:残缺棋盘
残缺棋盘是一个有2k*2k(k>0)个方格的棋盘,其中恰有一个方格残缺,其中残缺的方格用蓝色阴影表示。
①号

②号

③号

④号

这样的棋盘我们成为“三格板”,残缺棋盘问题就是要用这四种三格板覆盖更大的残缺棋盘。在此覆盖中要求:
(1)两个三格板不能重叠。
(2)三格板不能覆盖残缺方格,但必须要覆盖其他所有的方格。
解决:
以k=2为例(此时共有16个小方格),用二分法进行分解,得到的是由4个k=1的棋盘组成。
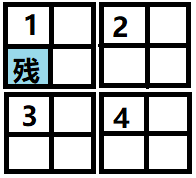
注意这四个棋盘,并不都是与原问题相似的子问题,只有残缺方格在左上角的棋盘时,左上角1号子棋盘与原问题相似。
既然不是与原问题相似的子问题,自然不能够独立求解,所以我们要用巧妙的方法,将2,3,4号子棋盘也转化成与原问题相似的子问题。
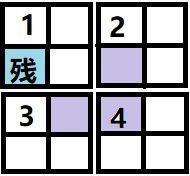
我们把紫色阴影覆盖的方格,也看作是残缺方格(我们称之为“伪”残缺方格),这样,每一个子残缺棋盘就都转化为与原问题相似的子问题了。
这样处理过后:
1号子棋盘可以用③号三格板覆盖
2号子棋盘可以用③号三格板覆盖
3号子棋盘可以用②号三格板覆盖
4号子棋盘可以用①号三格板覆盖
这样就覆盖了所有棋盘,满足题意。
如下图所示,粉色阴影是用题中给出的三格板覆盖的位置。
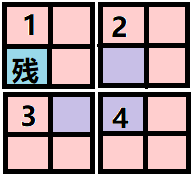
解决了k=2的情况,相当于解决了所有的情况,因为分治算法就是把大规模问题逐步分解成独立且相似的子问题。
思路清晰了之后,我们来解决一般情况
代码分析:
1.数据结构设计 :我们用一个二维数组Board[][]来模拟棋盘,覆盖残缺棋盘所需要的三格板数目为(size2-1)/3
(size为棋盘的行数或列数)
2.棋盘识别
我们用左上角方格所在行和列来唯一确定一个棋盘,残缺方格或“伪”残缺方格用行号和列号记录。
tr:棋盘左上角方格所在行
td:棋盘左上角方格所在列
dr:残缺方块所在行
dl:残缺方块所在列
3.棋盘填充
将三格板编号1-(size2-1)/3,将每个方格板的编号填充在代表棋盘的数组中,以这种方式表示棋盘被方格板覆盖。
完整代码如下:
#include(三)二分法不独立情况
上面的例题,经过二分法分解或经过简单处理后,就得到了相似且相互独立的子问题。对于分解后不独立的情况,主要表现在子问题之间包含公共子问题。
问题:求数列的最大字段和
给定n个元素的整数列(可能为负整数)(斜体标注的都为下标)
a1,a2,…,an.
求形如:ai,ai+1,…aj(i/j=1…n,i<=j)的子段
使其和为最大。当所有整数为负整数时定义其最大字段和为0。
例如当(a1,a2,a3,a4,a5,a6)=(-2,11,-1,13,-5,-2)
最大字段和为i=2,j=4(下标从1开始).
解决:
用二分法将数据分为两组,找出两个子问题的解,两个子问题的解不能简单地得到原问题的解,因为两个子问题的中间还有公共子问题,也就是说两个子问题不能真正的分开。此时再想使用二分法,则需要对公共子问题单独处理。
代码思路:
使用二分法将原问题分解,虽然分解得到的子问题并不相互独立,但是对公共子问题进行单独的处理。
将原问题分解成三部分
(从中间分开)
左边部分
右边部分
中间部分(中间部分单独处理时进行再分)
对左边部分和右边部分:
递归二分,直到分解到只剩一个元素。
对中间部分:
中间部分包含的序列可能是整个序列,把整个序列分为左右两部分,两边各向两侧扩展,最后两边的值相加为中间部分最大字段和。
从中间数据开始向一侧扩展,如果加上元素大于原来的和,则加上此元素,否则跳过这个元素继续扩展。
完整代码如下:
#include非等分分治
问题:选择第k小的数
对于给定的n个元素的数组a[0,n-1],要求从中找出第k小的数。
解决:
通过改写快速排序算法来解决选择问题。
(快速排序算法回忆:首先选择第一个数作为分界数据,将比它小的数据存储在它的左边,将比它大的数据存储在它的右边,它存储在左右两个子集中间。这样左右两个子集就是原问题分解后的独立子问题,再用同样的方法解决这些子问题,直到每个数据只有一个数据,就自然有序了,也就完成了全部数据的排序工作。)
代码思路:
一趟排序中分解出的左子集中元素个数nleft,有以下几种情况:
1. nleft=k-1,则分界数据就是选择问题的答案。
2. nleft>k-1,则选择问题的答案在左子集中找,问题规模变小了。
3. 则选择问题的答案在右子集中找,问题变为寻找第k-nleft-1小的数了,问题规模变小了。(因为随着子区间下标不同,k这个答案下标也会变化)
如果直接用快速排序算法的话,需要把数组全部排序后,再找第k小的数。而分治算法是边排边找,节省时间效率。
下面,将通过快速排序的算法和分治算法的比较,来观察两种方法的不同。
完整代码如下:
#include最后
原创不易,如果对您有帮助,请点个赞再走呀(づ ̄3 ̄)づ╭❤ ~拜托啦