AI上推荐 之 FM和FFM(九九归一)
1. 前言
随着信息技术和互联网的发展, 我们已经步入了一个信息过载的时代,这个时代,无论是信息消费者还是信息生产者都遇到了很大的挑战:
- 信息消费者:如何从大量的信息中找到自己感兴趣的信息?
- 信息生产者:如何让自己生产的信息脱颖而出, 受到广大用户的关注?
为了解决这个矛盾, 推荐系统应时而生, 并飞速前进,在用户和信息之间架起了一道桥梁,一方面帮助用户发现对自己有价值的信息, 一方面让信息能够展现在对它感兴趣的用户前面。 推荐系统近几年有了深度学习的助推发展之势迅猛, 从前深度学习的传统推荐模型(协同过滤,矩阵分解,LR, FM, FFM, GBDT)到深度学习的浪潮之巅(DNN, Deep Crossing, DIN, DIEN, Wide&Deep, Deep&Cross, DeepFM, AFM, NFM, PNN, FNN, DRN), 现在正无时无刻不影响着大众的生活。
推荐系统通过分析用户的历史行为给用户的兴趣建模, 从而主动给用户推荐给能够满足他们兴趣和需求的信息, 能够真正的“懂你”。 想上网购物的时候, 推荐系统在帮我们挑选商品, 想看资讯的时候, 推荐系统为我们准备了感兴趣的新闻, 想学习充电的时候, 推荐系统为我们提供最合适的课程, 想消遣放松的时候, 推荐系统为我们奉上欲罢不能的短视频…, 所以当我们淹没在信息的海洋时, 推荐系统正在拨开一层层波浪, 为我们追寻多姿多彩的生活!
这段时间刚好开始学习推荐系统, 通过王喆老师的《深度学习推荐系统》已经梳理好了知识体系, 了解了当前推荐系统领域各种主流的模型架构和技术。 所以接下来的时间就开始对这棵大树开枝散叶,对每一块知识点进行学习总结。 所以接下来一块目睹推荐系统的风采吧!
这次整理重点放在推荐系统的模型方面, 先从传统推荐模型开始, 然后到深度学习模型。 传统模型的演化关系拿书上的一张图片, 便于梳理传统推荐模型的进化关系脉络, 对知识有个宏观的把握:

今天是推荐系统传统模型的第四篇,也是传统推荐模型的最后一篇, 迎来的是因子分解机(Factorization Machine, FM)和域感知因子分解机(Field-aware Factorization Machine, FFM), 这两个属于因子分解机模型族, 在传统逻辑回归的基础上, 加入了二阶部分, 使得模型具备了特征组合的能力, 在上一篇文章里面谈到了逻辑回归, 这是一个简单、直观、应用的模型, 但是局限性就是表达能力不强, 无法进行特征交叉和特征筛选等, 因此为了解决这个问题, 推荐模型朝着复杂化发展, GBDT+LR的组合模型就是复杂化之一, 通过GBDT的自动筛选特征加上LR天然的处理稀疏特征的能力, 两者一结合初步实现了推荐系统特征工程化的开端。 其实, 对于改造逻辑回归模型, 使其具备交叉能力的探索还有一条线路, 就是今天这篇文章要介绍的POLY2->FM->FFM, 这条线路在探索特征之间的两两交叉, 从开始的二阶多项式, 到FM, 再到FFM, 不断演化和提升。
所以今天这篇文章的脉络会很清晰, 首先会先从POLY2开始,简单介绍一下POLY2模型的原理以及存在的不足, 从而引出后面的FM模型, 这个模型是2010年提出来的, 在POLY2的基础上把二阶交叉特征前面的权重换成了各自特征隐向量的内积形式, 这个模型还是比较重要的, 虽然现在不怎么用了, 但是他里面的隐向量思想的身影在深度学习的embedding里面得到了继承和发展, 所以接下来就会介绍FM模型的原理和一些公式的推导, 这个模型依然有点不足, 所以最后会介绍FFM模型的原理, 这个模型基于FM模型对权重又进行了改进, 引入了域的概念, 使得交叉特征的信息表达更近一步, 对了, 这个模型是2016年提出来的, 比GBDT+LR模型还晚了一些。这个模型感觉思路也是非常的有意思, 所以也是挺重要的, 为了更好的理解FM和FFM, 每一块的后面也会加上代码实践部分, 亲自玩一下这些模型
大纲如下:
- FM? 我们先从POLY2开始
- FM模型的原理及代码实战
- FFM模型的原理及代码实战
Ok, let’s go!
2. FM? 我们先从POLY2开始
在前一篇文章中已经说过, 逻辑回归模型已经把TOPN推荐的问题转成了CTR预估的问题, 也就是将特征做一个线性组合, 然后通过sigmoid得到一个概率值, 这个概率值表示用户点击某个商品的概率, 逻辑回归模型相对于传统的协同过滤来讲, 已经可以把用户特征, 商品特征以及上下文特征进行了利用, 但是逻辑回归存在很大的一个问题就是只对单一特征做简单加权, 不具备特征交叉生成组合特征的能力, 因此表达能力受到了限制, 还记得逻辑回归中 y y y的公式吗?
y = w 0 + ∑ i = 1 n w i x i y = w_0+\sum_{i=1}^nw_ix_i y=w0+i=1∑nwixi
这里就可以看到, 只是对单一特征进行了加权,这样我们说不好,因为很多情况下, 特征之间的组合是非常有意义的, 比如“USA”与“Thanksgiving”、“China”与“Chinese New Year”这样的关联特征,对用户的点击有着正向的影响。换句话说,来自“China”的用户很可能会在“Chinese New Year”有大量的浏览、购买行为,而在“Thanksgiving”却不会有特别的消费行为。这种关联特征与label的正向相关性在实际问题中是普遍存在的,如“化妆品”类商品与“女”性,“球类运动配件”的商品与“男”性,“电影票”的商品与“电影”品类偏好等。
那么我们能不能进行特征之间的组合呢?
在逻辑回归里面, 如果想得到组合特征, 往往需要人工在特征工程的时候手动的组合特征, 然后再进行筛选, 但这个比较低效, 第一个是这个会有经验的成分在里面, 第二个是可能会比较玄学, 不太好找到有用的组合特征。 于是乎, 采用POLY2模型进行特征的“暴力”组合就成了可行的选择。 POLY2是二阶多项式模型, 数学形式如下:
y = w 0 + ∑ i = 1 n w i x i + ∑ i = 1 n − 1 ∑ i + 1 n w i j x i x j y = w_0+\sum_{i=1}^nw_ix_i+\sum_{i=1}^{n-1}\sum_{i+1}^nw_{ij}x_ix_j y=w0+i=1∑nwixi+i=1∑n−1i+1∑nwijxixj
看到这个基本上不用怎么解释就明白了, 这个模型对所有的特征进行了两两的交叉, 然后又算得了一个权重, 这个其实和逻辑回归依然是超级像的, 如果我们在逻辑回归中, 做特征工程的时候, 也可以自己做出这样的一些特征来的, 就是所谓的:
for i in range(n-1):
for j in range(i, n):
data[cols[i]_cols[j]] = data[cols[i]] * data[cols[j]]
这样, 其实用逻辑回归再做就相当于那个POLY2的模型了。
但是这个模型会存在两个比较大的问题:
-
推荐系统中的数据往往是非常稀疏的(类别型数据经过独热), 这样会导致特征向量非常的稀疏, 这时候如果再交叉的时候, 往往 x i x_i xi和 x j x_j xj同时不为0的情况很少, 这会导致交叉特征的权重缺乏有效的数据进行训练而无法收敛。 就比如下面这个数据:假设一个广告分类的问题,根据用户和广告位相关的特征,预测用户是否点击了广告(本数据来自美团技术团队分享的paper)

“Clicked?”是label,Country、Day、Ad_type是特征。由于三种特征都是categorical类型的,需要经过独热编码(One-Hot Encoding)转换成数值型特征。
由上表可以看出,经过One-Hot编码之后,大部分样本数据特征是比较稀疏的。上面的样例中,每个样本有7维特征,但平均仅有3维特征具有非零值。那这样进行交叉的时候, 其实很多交叉特征的项由于 x i x j = 0 x_ix_j=0 xixj=0使得 w i j w_{ij} wij没有机会训练。因此,数据稀疏性是实际问题中不可避免的挑战。 -
POLY2中权重参数的数量是 ( n − 1 ) n 2 \frac{(n-1)n}{2} 2(n−1)n , 任意两个参数相互独立, 这时候如果数据非常稀疏, 再要训练这么多参数, 无疑是非常困难的, 最终模型也不会很好。
因此, POLY2模型虽然是引入了特征的二阶交叉组合, 但是由于其模型参数, 稀疏场景受限的问题使得FM登场了!
3. FM模型的原理及代码实践
3.1 FM模型的原理
在介绍FM之前, 依然是抛出一个问题, 就是上面的POLY2模型在特征交叉的时候采用的单独的权重, 这使得在稀疏的场景下无法适用, 那么这种问题应该怎么解决呢? 其实, 前面的矩阵分解算法就提供了一种思路—隐向量,还记得矩阵分解吗? 这个是把用户评分矩阵分解成了user矩阵和item矩阵相乘的方式, 即每个user和item都采用了一个隐向量来表示, 如果忘了, 把前面的图拿过来:
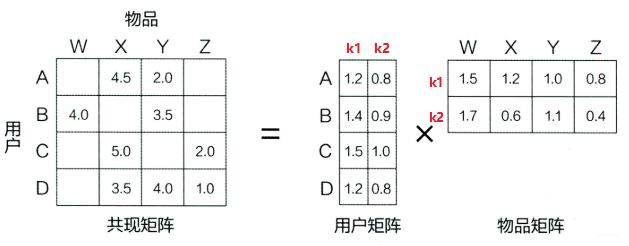
这个评分矩阵也是非常稀疏的, 如果采用普通的协同过滤算法, 真的不太好判断用户相似或者物品相似, 但是如果把这个矩阵分解成了两个矩阵相乘的形式, 那么就可以把单独考虑某个用户或者某个物品变成综合考虑所有用户和用品, 基于打分的这些数据就可以得到每个用户和物品的向量, 然后相乘得到最后的评分。
既然对于稀疏的评分矩阵, 我们有办法分解成两个向量相乘的形式, 那么为何不把这种思想用到解决POLY2的缺陷上呢? 无非就是评分矩阵换成POLY2后面的 W W W矩阵(所有二次项系数 w i j w_{ij} wij组成的)。于是乎, 这种思想真的就用过来了, 那就是把 W W W矩阵进行分解成两个矩阵相乘的方式, 可是有依据的哟:
任意一个实对称矩阵(正定矩阵) W W W都存在一个矩阵 V V V,使得 W = V . V T W=V.V^T W=V.VT成立。
所以, 对于二次项参数 w i j w_{ij} wij组成的对称阵 W W W(为了方面说明FM的由来, 对角元素设置为正实数), 我们就可以分解成 V T V V^TV VTV的形式, V V V的第 j j j列 v j v_j vj表示的是第 j j j维特征 x j x_j xj的隐向量。 换句话说, 特征分量 x i x_i xi和 x j x_j xj的交叉系数就等于 x i x_i xi和 x j x_j xj对应的隐向量的内积, 即每个参数 w i j = < v i , v j > w_{ij}=
W ⋆ = [ ω 11 ω 12 … ω 1 n ω 21 ω 22 … ω 2 n … … … … ω n 1 ω n 2 … ω n n ] = V T V = [ V 1 V 2 … V n ] × [ V 1 , V 2 , … , V n ] = [ v 11 v 12 … v 1 k v 21 v 22 … v 2 k ⋯ ⋯ ⋯ ⋯ v n 1 v n 2 … v n k ] × [ v 11 v 21 … v n 1 v 12 v 22 … v n 2 ⋯ ⋯ ⋯ ⋯ v 1 k v 2 k ⋯ v n k ] W^{\star}=\left[\begin{array}{cccc} \omega_{11} & \omega_{12} & \ldots & \omega_{1 n} \\ \omega_{21} & \omega_{22} & \ldots & \omega_{2 n} \\ \ldots & \ldots & \ldots & \ldots \\ \omega_{n 1} & \omega_{n 2} & \ldots & \omega_{n n} \end{array}\right]=V^{T} V=\left[\begin{array}{c} V_{1} \\ V_{2} \\ \ldots \\ V_{n} \end{array}\right] \times\left[V_{1}, V_{2}, \ldots, V_{n}\right]=\left[\begin{array}{cccc} v_{11} & v_{12} & \ldots & v_{1 k} \\ v_{21} & v_{22} & \ldots & v_{2 k} \\ \cdots & \cdots & \cdots & \cdots \\ v_{n 1} & v_{n 2} & \ldots & v_{n k} \end{array}\right] \times\left[\begin{array}{cccc} v_{11} & v_{21} & \ldots & v_{n 1} \\ v_{12} & v_{22} & \ldots & v_{n 2} \\ \cdots & \cdots & \cdots & \cdots \\ v_{1 k} & v_{2 k} & \cdots & v_{n k} \end{array}\right] W⋆=⎣⎢⎢⎡ω11ω21…ωn1ω12ω22…ωn2…………ω1nω2n…ωnn⎦⎥⎥⎤=VTV=⎣⎢⎢⎡V1V2…Vn⎦⎥⎥⎤×[V1,V2,…,Vn]=⎣⎢⎢⎡v11v21⋯vn1v12v22⋯vn2……⋯…v1kv2k⋯vnk⎦⎥⎥⎤×⎣⎢⎢⎡v11v12⋯v1kv21v22⋯v2k……⋯⋯vn1vn2⋯vnk⎦⎥⎥⎤
这时候, 为了求 w i j w_{ij} wij, 我们需要求出特征分量 x i x_i xi的辅助向量 v i = ( v i 1 , v i 2 , . . . v i k ) v_i=(v_{i1}, v_{i2}, ...v_{ik}) vi=(vi1,vi2,...vik), v j = ( v j 1 , v j 2 , . . . v j k ) v_j=(v_{j1}, v_{j2},...v_{jk}) vj=(vj1,vj2,...vjk)。
所以, 有了这样的一个铺垫, 就可以写出FM的模型方程了, 就是POLY2 的基础上, 把 w i j w_{ij} wij写成了两个隐向量相乘的方式。
y ^ ( X ) = ω 0 + ∑ i = 1 n ω i x i + ∑ i = 1 n − 1 ∑ j = i + 1 n < v i , v j > x i x j \hat{y}(X) = \omega_{0}+\sum_{i=1}^{n}{\omega_{i}x_{i}}+\sum_{i=1}^{n-1}{\sum_{j=i+1}^{n} \color{red}{
需要估计的参数有 ω 0 ∈ R \omega_{0}∈ R ω0∈R, ω i ∈ R \omega_{i}∈ R ωi∈R, V ∈ R V∈ R V∈R, < ⋅ , ⋅ > < \cdot, \cdot> <⋅,⋅>是长度为 k k k的两个向量的点乘,其中:
< v i , v j > = ∑ f = 1 k v i , f ⋅ v j , f
上面的公式中:
- ω 0 \omega_{0} ω0为全局偏置;
- ω i \omega_{i} ωi是模型第 i i i个变量的权重;
- ω i j = < v i , v j > \omega_{ij} = < v_{i}, v_{j}> ωij=<vi,vj>特征 i i i和 j j j的交叉权重;
- v i v_{i} vi是第 i i i维特征的隐向量;
- < ⋅ , ⋅ > <\cdot, \cdot> <⋅,⋅>代表向量点积;
- k ( k < < n ) k(k<
FM模型中二次项的参数数量减少为 k n kn kn个,远少于多项式模型的参数数量。另外,参数因子化使得 x h x i x_{h}x_{i} xhxi 的参数和 x i x j x_{i}x_{j} xixj 的参数不再是相互独立的,因此我们可以在样本稀疏的情况下相对合理地估计FM的二次项参数。具体来说, x h x i x_{h}x_{i} xhxi 和 x i x j x_{i}x_{j} xixj的系数分别为 < v h , v i > \lt v_{h},v_{i}\gt <vh,vi> 和 < v i , v j > \lt v_{i},v_{j}\gt <vi,vj> ,它们之间有共同项 v i v_{i} vi 。也就是说,所有包含“ x i x_{i} xi 的非零组合特征”(存在某个 j ≠ i j \ne i j=i ,使得 x i x j ≠ 0 x_{i}x_{j}\neq 0 xixj=0 )的样本都可以用来学习隐向量 v i v_{i} vi,这很大程度上避免了数据稀疏性造成的影响。而在多项式模型中, w h i w_{hi} whi 和 w i j w_{ij} wij 是相互独立的。关于上面说的如果不太理解, FFM论文中有个例子解释的特别贴切:
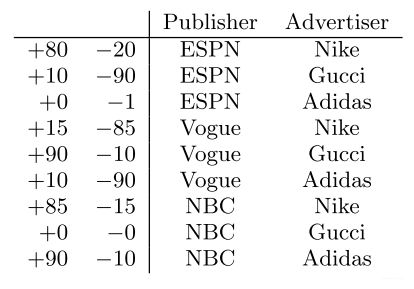
这是一个点击率数据集, 左边的±表示的点击和不点击的数量。 右边两列是特征。对于上面那句话的举例如下:

这句话直接就道出了FM相比较于POLY2的优势所在, 能够更好地解决数据稀疏, 具备计算从未出现特征组合权重的能力(和MF一样, POLY2类似于仅考虑 x i , x j x_i,x_j xi,xj本身, 而FM综合考虑其他特征)。
FM的公式是一个通用的拟合方程,可以采用不同的损失函数用于解决regression、classification等问题,比如可以采用MSE(Mean Square Error)loss function来求解回归问题,也可以采用Hinge/Cross-Entropy loss来求解分类问题。当然,在进行二元分类时,FM的输出需要使用sigmoid函数进行变换,该原理与LR是一样的。直观上看,FM的复杂度是 O ( k n 2 ) O(kn^2) O(kn2) 。但是FM的二次项可以化简,其复杂度可以优化到 O ( k n ) O(kn) O(kn) 。由此可见,FM可以在线性时间对新样本作出预测。这个地方的推导如下:
∑ i = 1 n − 1 ∑ j = i + 1 n < v i , v j > x i x j = 1 2 ∑ i = 1 n ∑ j = 1 n < v i , v j > x i x j − 1 2 ∑ i = 1 n < v i , v i > x i x i = 1 2 ( ∑ i = 1 n ∑ j = 1 n ∑ f = 1 n v i , f v j , f x i x j − ∑ i = 1 n ∑ f = 1 k v i , f v i , f x i x i ) = 1 2 ∑ f = 1 k [ ( ∑ i = 1 n v i , f x i ) ⋅ ( ∑ j = 1 n v j , f x j ) − ∑ i = 1 n v i , f 2 x i 2 ] = 1 2 ∑ f = 1 k [ ( ∑ i = 1 n v i , f x i ) 2 − ∑ i = 1 n v i , f 2 x i 2 ] \begin{aligned} \sum_{i=1}^{n-1} \sum_{j=i+1}^{n}
这样, 就对上面的公式进行了化简, 方便用梯度下降法求解参数。 但是这个式子最上面那个等式为啥成立呢? 其实, 这个就是矩阵的一个运算化简, 这里用文文大佬画的那个图看一下:
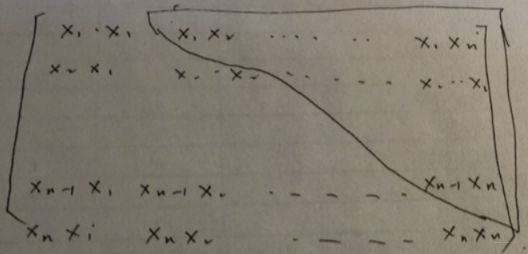
这个应该一目了然了, 就不过多解释了。 总之有了这个式子, 就可以用SGD求进行梯度更新:
∂ y ^ ( x ) ∂ θ = { 1 , if θ is ω 0 x i , if θ is ω i x i ∑ j = 1 n v j , f x j − v i , f x i 2 if θ is v i , f \frac{\partial \hat{y}(x)}{\partial \theta}=\left\{\begin{array}{ll} 1, & \text { if } \theta \text { is } \omega_{0} \\ x_{i}, & \text { if } \theta \text { is } \omega_{i} \\ x_{i} \sum_{j=1}^{n} v_{j, f} x_{j}-v_{i, f} x_{i}^{2} & \text { if } \theta \text { is } v_{i, f} \end{array}\right. ∂θ∂y^(x)=⎩⎨⎧1,xi,xi∑j=1nvj,fxj−vi,fxi2 if θ is ω0 if θ is ωi if θ is vi,f
由这个式子也可以看出来, 更新 v i , f v_{i,f} vi,f的时候, 只需要样本 x i x_i xi特征非0即可, 适合于稀疏数据。
在使用SGD训练模型时,在每次迭代中,只需计算一次所有 f f f的 ∑ j = 1 n v j , f x j \sum_{j=1}^{n} v_{j, f} x_{j} ∑j=1nvj,fxj就能够方便的得到所有 v i , f v_{i,f} vi,f的梯度, 而如果有 k k k维的话, 复杂度是 O ( k n ) O(kn) O(kn), 即FM参数训练的复杂度就是这个。
由此可见, FM可以在线性时间训练和预测, 模型非常高效和灵活, 相比后面的深度学习模型复杂的网络结构导致难以部署和线上服务, FM容易实现的模型结构使得线上推断过程相对简单, 也更容易线上部署和服务。 因此, FM在2012-2014前后, 成为了业界主流的推荐模型之一。
3.2 FM模型的代码实战
FM这里的代码实战部分比较丰富, 尝试整理了两种使用FM的思路, 一种是通过pyFM直接掉包, 二是手动实现这个模型。 掉包使用的时候, 我们需要弄清楚这里的FM参数, 还有就是数据集的格式, 必须处理成相应的格式, 否则会报错。 接下来, 尝试整理这两种方式的使用。
实战中的数据集和具体详细代码可以参考最后的GitHub链接,这里只整理重点。 实战部分分为分类和回归, 回归任务用到的数据集是前面协同过滤时电影评分的预测, 而分类任务中的数据集是CBDT+LR里面的criteo CTR数据集, 具体情况参考链接吧。
3.2.1 调包版FM的使用
这个需要调用pyFM这个包, 所以首先需要安装一下这个包。 下面的pyFM包里面介绍了最简单粗暴的pip方法, 但是我按照的有报错提示, 所以这里再提供一种方式:
- 在https://github.com/coreylynch/pyFM中手动下载包
- 将包解压,更改里面的setup.py文件,去掉setup.py文件里面的
libraries=[“m”]一行 - cd到当前文件夹下
python setup.py install
这种方法安装过程中, 如果报C++ 14.0 is required的错误, 那么就再来看这个Microsoft Visual C++ 14.0 is required 的解决方案, 第二种方法亲测了一下。
安装好包之后, 我们重点看一下怎么使用, 其实pyFM的GitHub里面也在下面写了几个上手的案例。 如果把人家那个直接复制过来, 就没啥意思了, 这里补充一点别的。掉包版依然是分为回归和分类任务, 关于回归, GitHub项目里面已经给出了电影评分的案例, 这里强调的是输入格式, 一定要按照这个格式来, 否则会报错, 这里它用的是[{'fea1': 'value1', 'fea2': 'value2'}, {}, {}]的格式, 然后将这个通过DictVectorizer()进行转换才能用它的包进行训练。 具体的看我给出的GitHub吧, 这里不整理这个。
-
回归任务
关于回归任务, 这里还是用我前面协同过滤和矩阵分解里面用的那个简单例子, 猜测用户Alice对物品5的打分。这样才有利于把知识连起来嘛,哈哈。

还是这个熟悉的任务, 前面已经用协同过滤和MF完成了一下, 这里我们看看FM如何用于这个任务。通过这个和电影评分的两个, 应该可以使用这个pyFM的包了。 如果要使用FM, 这里和前面两个模型不同的地方就是数据的存储格式, 我们知道协同过滤和矩阵分解都是直接基于这个交互矩阵, 那么在存储的时候往往是用字典, 记录用户对物品评了多少分即可。 但是FM不能直接用这样的数据, 因为FM是把上面这个问题转成一个监督的问题, 监督问题的话就需要特征列和标签。 所以要先把这个数据格式进行一个处理。 具体代码是这样:# 导入数据这部分还是原来的那个代码 def loadData(): rating_data={ 1: { 'A': 5, 'B': 3, 'C': 4, 'D': 4}, 2: { 'A': 3, 'B': 1, 'C': 2, 'D': 3, 'E': 3}, 3: { 'A': 4, 'B': 3, 'C': 4, 'D': 3, 'E': 5}, 4: { 'A': 3, 'B': 3, 'C': 1, 'D': 5, 'E': 4}, 5: { 'A': 1, 'B': 5, 'C': 5, 'D': 2, 'E': 1} } return rating_data rating_data = loadData()这个没变, 为了和原来的保持一致, 但是这里需要处理一下格式:
df = pd.DataFrame(rating_data).T df = df.stack().reset_index() df.columns = ['user', 'item', 'rating'] df['user'] = df['user'].astype('str')这里, 就把数据变成了特征-标签的形式, 这个起作用的是stack函数, 具体的可以参考我整理的另一篇博客。

下面再一步处理, 把item这个进行数字编码, 然后把前两列当做特征, 后一列当做标签划分开数据集:item_map = { item: str(idx) for idx, item in enumerate(set(df['item']))} df['item'] = df['item'].map(item_map) # 划分, 得到数据集 train_data = df[['user', 'item']] y = df['rating']下面把特征进行one-hot编码, 这里由于是pandas的DataFrame, 我用
DictVectorizer()会报错,所以这里我直接用sklearn的OneHotEncoder()处理。one = OneHotEncoder() x = one.fit_transform(train_data)这个处理完是一个稀疏矩阵存储格式, 巧了, 下面的FM还就是用这种格式的,
DictVectorizer()也是处理成这个格式。 长下面这样:

这个OneHotEncoder不过多解释了, 这样每一行的两个特征都用了独热的形式。 下面就是建立FM模型了, 主要是看看这个咋用。# 建立模型 fm = pylibfm.FM(num_factors=10, num_iter=100, verbose=True, task='regression', initial_learning_rate=0.001, learning_rate_schedule='optimal')建立模型, 只需要一句话。 但是这里面有好多参数, 我们需要知道
FM的具体参数函数如下: 这里面重点需要设置的我已标出(详细的可以参考源码)
- num_factors: 隐向量的维度, 也就是k
- num_iter: 迭代次数, 由于使用的SGD, 随机梯度下降, 要指明迭代多少个epoch
- k0, k1: k0表示是否用偏置(看FM的公式), k1表示是否要第二项, 就是单个特征的, 这俩默认True
- init_stdev: 初始化隐向量时候的方差, 默认0.01
- validation_size: 验证集的比例, 默认0.01
- learning_rate_schedule: 学习率衰减方式, 有constant, optimal, 和invscaling三种方式, 具体公式看源码
- initial_learning_rate: 初始学习率, 默认0.01
- power_t, t0: 逆缩放学习率的指数,最优学习率分母常数, 这两个和上面学习率衰减方式的计算有关
- task: 分类或者回归任务, 要指明
- verbose: 是否打印当前的迭代次数, 训练误差
- shuffle_training: 是否在学习之前打乱训练集
- seed: 随机种子
建立了模型之后, 下面训练和预测就非常简单, 还是
fit和predict.# 模型训练 fm.fit(x, y) # 测试集 test = { 'user': '1', 'item': '4'} x_test = one.transform(pd.DataFrame(test, index=[0])) # 预测 pred_rating = fm.predict(x_test) print('FM的预测评分:{}'.format(pred_rating[0])) # FM的预测评分:3.513755892491899这样就用FM完成了之前预测用户商品评分的例子, 看懂了这个再看它给的电影评分的例子就会非常简单了。
-
分类任务
掉包完成分类任务, pyFM GitHub里面给出了一个随机生成的数据集完成分类, 这里为了衔接下面的造轮子的内容, 用调包的方式在criteo数据集进行实战。这里非常重要的一个点依然是数据的格式。如果处理不当, 就无法用人家的包训练。首先是导入数据集, 并简单处理, 这部分代码直接用的GBDT+LR里面的代码, 与前面的衔接。# 数据读取 path = 'criteo/' df_train = pd.read_csv(path + 'train.csv') df_test = pd.read_csv(path + 'test.csv') # 简单的数据预处理 # 去掉id列, 把测试集和训练集合并, 填充缺失值 df_train.drop(['Id'], axis=1, inplace=True) df_test.drop(['Id'], axis=1, inplace=True) df_test['Label'] = -1 data = pd.concat([df_train, df_test]) data.fillna(-1, inplace=True) """下面把特征列分开处理""" continuous_fea = ['I'+str(i+1) for i in range(13)] category_fea = ['C'+str(i+1) for i in range(26)]下面进行类别特征的编码, 这里用
LabelEncoder(),并生成数据集# 类别特征编码 lab = LabelEncoder() for col in category_fea: data[col] = data[col].astype('str') data[col] = lab.fit_transform(data[col]) # 分开 df_train = data[:df_train.shape[0]] df_test = data[df_train.shape[0]:] del df_test['Label'] # 生成数据集 x_train = df_train.drop(columns='Label') y_train = df_train['Label'].values x_test = df_test下面是进行数据归一化, 因为我发现如果不归一化, 下面训练的时候会出现loss为nan
# 标准化 scaler = MinMaxScaler() x_train = scaler.fit_transform(x_train) x_test = scaler.transform(x_test)下面是最关键的一部, 转换格式, 这也是我花最多时间探索的一步, 需要这种格式:
# 转换格式 [{'0': 'value', '1': 'value', }, {}, {}...{}], 这样的格式, 一个列表, 然后里面元素是字典表示每个样本, 字典的键是特征的索引下标, 值是特征值 x_train = [{ v: k for k, v in zip(i, range(len(i)))} for i in x_train] x_test = [{ v: k for k, v in zip(i, range(len(i)))} for i in x_test] x_tr, x_val, y_tr, y_val = train_test_split(x_train, y_train, test_size=0.1, random_state=2020) # 这里需要进行转换一下才能用这个包 这一步也非常关键, 这样才能成为稀疏矩阵 v = DictVectorizer() x_tr = v.fit_transform(x_tr) x_val = v.transform(x_val) x_test = v.transform(x_test)下面就是建立模型了:分类任务, 注意task参数
# 建立模型 fm = pylibfm.FM(num_factors=200, num_iter=100, verbose=True, task='classification', initial_learning_rate=0.001, learning_rate_schedule='optimal') # train fm.fit(x_tr, y_tr) # envalueate val_pre = fm.predict(x_val) log_loss(y_val, val_pre) # 0.4677241466075124
3.2.2 造轮子版FM
造轮子版来自于Datawhale的推荐系统组队学习, 如意哥写的, 向大佬学习了一下这个代码, 这个是通过keras写的, 也是用的criteo的数据集, 所以和上面正好又对起来。 思路就是读入数据之后, 特征编码, 然后构建FM的组合层, 写成了类似神经网络的那种形式。不是太难理解, 下面一块块的来看:
# dense特征取对数, sparse特征类别编码
def process_feat(data, dense_feats, sparse_feats):
df = data.copy()
# dense
df_dense = df[dense_feats].fillna(0.0)
for f in tqdm(dense_feats):
df_dense[f] = df_dense[f].apply(lambda x: np.log(1+x) if x > -1 else -1)
# sparse
df_sparse = df[sparse_feats].fillna('-1')
for f in tqdm(sparse_feats):
lbe = LabelEncoder()
df_sparse[f] = lbe.fit_transform(df_sparse[f])
df_new = pd.concat([df_dense, df_sparse], axis=1)
return df_new
这个函数的作用就是完成编码, 数值特征用了对数转换, 类别特征LabelEncoder()编码。 下面就是FM的造轮子实现:
# FM 特征组合层
class crossLayer(layers.Layer):
def __init__(self, input_dim, output_dim=10, **kwargs):
super(crossLayer, self).__init__(**kwargs)
self.input_dim = input_dim
self.output_dim = output_dim
# 定义交叉特征的权重
self.kernel = self.add_weight(name='kernel', shape=(self.input_dim, self.output_dim), initializer='glorot_uniform', trainable=True)
def call(self, x): # 对照上述公式中的二次项优化公式理解
a = K.pow(K.dot(x, self.kernel), 2)
b = K.dot(K.pow(x, 2), K.pow(self.kernel, 2))
return 0.5 * K.mean(a-b, 1, keepdims=True)
这里首先, 自定义了一个交叉特征的层, 完成的是公式里面的第三部分运算。 self.kernel就是w矩阵,和上面的公式唯一不同的就是这里统一采用了矩阵运算的形式。 应该比较好理解。
# 定义FM模型
def FM(feature_dim):
inputs = Input(shape=(feature_dim, ))
# 一阶特征
linear = Dense(units=1, kernel_regularizer=regularizers.l2(0.01), bias_regularizer=regularizers.l2(0.01))(inputs)
# 二阶特征
cross = crossLayer(feature_dim)(inputs)
add = Add()([linear, cross]) # 将一阶特征与二阶特征相加构建FM模型
pred = Activation('sigmoid')(add)
model = Model(inputs=inputs, outputs=pred)
model.compile(loss='binary_crossentropy', optimizer=optimizers.Adam(), metrics=['binary_accuracy'])
return model
这里定义了FM模型, 这个就是完全是实现了FM的公式。 一阶特征部分是一个Dense层, 二阶特征交叉就是上面定义的那个层, 最后Add()连接, 再用sigmoid激活。 这里我也是新学到的这种思路, 竟然可以这样写, interesting . 后面就是常规操作了, 一块写下来吧:
# 读入数据
path = 'criteo/'
data = pd.read_csv(path + 'train.csv')
# 去掉id列, 把测试集和训练集合并, 填充缺失值
data.drop(['Id'], axis=1, inplace=True)
# dense 特征开头是I, sparse特征开头是C, label是标签
cols = data.columns.values
dense_feats = [f for f in cols if f[0] == 'I']
sparse_feats = [f for f in cols if f[0] == 'C']
# 数据预处理
feats = process_feat(data, dense_feats, sparse_feats)
# 划分训练和验证数据
x_trn, x_tst, y_trn, y_tst = train_test_split(feats, data['Label'], test_size=0.2, random_state=2020)
# 定义模型
model = FM(feats.shape[1])
model.fit(x_trn, y_trn, epochs=100, batch_size=128, validation_data=(x_tst, y_tst))
# 预测
y_pred = model.predict(x_tst)
关于FM的实战部分, 目前就学了这么多, 所以先整理到这里吧, 具体详细代码和数据集, 可以去后面的GitHub。
3.3 FM模型的应用
最直接的想法就是直接把FM得到的结果放进sigmoid中输出一个概率值,由此做CTR预估,事实上我们也可以做召回。
由于FM模型是利用两个特征的Embedding做内积得到二阶特征交叉的权重,那么我们可以将训练好的FM特征取出离线存好,之后用来做KNN向量检索。
工业上, 应用FM的具体操作步骤:
- 离线训练好FM模型(学习目标可以是CTR)
- 将训练好的FM模型Embedding取出
- 将每个uid对应的Embedding做avg pooling(平均)形成该用户最终的Embedding,item也做同样的操作
- 将所有的Embedding向量放入Faiss等
- 线上uid发出请求,取出对应的user embedding,进行检索召回
关于工业上的更多应用, 这里先占个坑, 等探索完了,后面会再来补充。
4. FFM模型的原理及代码实践
2015年, 基于FM提出的FFM在多项CTR预估大赛中夺魁, 并被Criteo、美团等公司深度应用在推荐系统、CTR预估等领域, 相比于FM模型, FFM模型引入了特征域感知(filed-aware) 这个概念, 使得模型的表达能力更强。 下面就来看看这个模型的原理。
4.1 FFM模型的原理
既然这个模型是基于FM模型, 那么应该是从FM模型上面进行的改进, 那么回顾上面的FM模型, 哪个地方会存在问题呢? FM的模型公式如下:
y ^ ( X ) = ω 0 + ∑ i = 1 n ω i x i + ∑ i = 1 n − 1 ∑ j = i + 1 n < v i , v j > x i x j \hat{y}(X) = \omega_{0}+\sum_{i=1}^{n}{\omega_{i}x_{i}}+\sum_{i=1}^{n-1}{\sum_{j=i+1}^{n} \color{red}{
说得对, 就是后面的这个权重计算。 就拿上面的那个例子来看:

我们知道, 如果是FM进行两两特征交叉的时候, 比如"USA"和"1/7/14"交叉和"USA"和"Movie"交叉的时候, 其实用的“USA"的隐向量都是 V U S A V_{USA} VUSA, 即( V U S A , V 1 / 17 / 14 ) V_{USA},V_{1/17/14}) VUSA,V1/17/14)和( V U S A , V M o v i e ) V_{USA},V_{Movie}) VUSA,VMovie), 当然在学习 V U S A V_{USA} VUSA的时候, 也是综合了 V 1 / 17 / 17 , V m o v i e V_{1/17/17}, V_{movie} V1/17/17,Vmovie等很多个和 V U S A V_{USA} VUSA有交互的特征学习到的。 这样存在的一个问题就是学习的 V U S A V_{USA} VUSA需要考虑全部的与其交互的特征, 但是其实我们会发现一个问题, 像“Day=26/11/15”、“Day=1/7/14”、“Day=19/2/15”这三个都是属于日期类的特征, 而"Movie"和"Game"都是属于Ad_type类的, 也就是说 V 1 / 17 / 14 V_{1/17/14} V1/17/14和 V M o v i e V_{Movie} VMovie的相差可能会很大, 而"USA"和"1/7/14"交叉和"USA"和"Movie"交叉的时候, 都是用的同一个 V U S A V_{USA} VUSA好像不太合理, 且学习这个隐向量的时候, 也得权衡各个类别里面的交互特征学到, 这样可能会使得模型的表达能力受到一定的限制, 感觉论文里面的这句话解释的很好:

那么, 我们为啥不先把特征先分一下类(因为很多都是one-hot之后的特征嘛, 就比如上面的Day, Ad_type, 这些特征其实是可以属于一类总体的日期类或者广告类型类), 然后对于每个特征, 我们按照不同的域学习不同的隐向量呢? 也就是一个特征对应多个隐向量。 这样在与不同域(类)里面特征交叉的时候, 用相应的隐向量去交叉计算权重, emmm, 这倒是一种思路, 并且这样做的好处是学习隐向量的时候只需要考虑相应的域的数据, 且与不同类的特征进行关联采用不同的隐向量, 这和不同类特征的内在差异也比较相符。 这其实就是FFM在FM的基础上做的改进, 引入了域的概念, 对于每个特征, 针对不同的交叉域要学习不同的隐向量特征。
这么说, 如果有点抽象, 那么就拿上面的那个例子来看一下FFM的好处, 还是"USA"和"1/7/14"交叉和"USA"和"Movie"交叉。 这时候不同于FM, FFM在USA这个特征下会有两个隐向量 V U S A , d a t e 和 V U S A , A d _ t y p e V_{USA, date}和V_{USA,Ad\_type} VUSA,date和VUSA,Ad_type, 这时候, 如果是前两者交叉, 那么权重就是( V U S A , d a t e , V 1 / 17 / 14 ) V_{USA, date},V_{1/17/14}) VUSA,date,V1/17/14)的内积, 如果是后两者交叉, 那权重就是( V U S A , A d _ t y p e , V M o v i e ) V_{USA,Ad\_type},V_{Movie}) VUSA,Ad_type,VMovie)的内积。注意体会一下FFM和FM的不同。 这样的好处就是交叉的时候, 可以更能够体现出不同域里面特征的差异性(这就是FFM里面"field-aware"的由来), 表达能力更强, 另外一个就是学习USA特征的多个隐向量的时候, 不是综合考虑所有的类别特征, 而是自个学习自个的, 也就是 V U S A , d a t e V_{USA, date} VUSA,date的学习只用USA与日期的交互数据, V U S A , A d _ t y p e V_{USA, Ad\_type} VUSA,Ad_type学习只用USA与Ad_type的交互数据, 这样 V U S A , d a t e V_{USA, date} VUSA,date和 V U S A , A d _ t y p e V_{USA, Ad\_type} VUSA,Ad_type隐向量的维度就可以少很多。

但这个由于又考虑了域嘛, 即一个特征会根据不同的域学习不同的隐向量, 那么时间复杂度上会从FM的 O ( n k ) O(nk) O(nk)到FFM的 O ( n f k ) O(nfk) O(nfk), 这里的 f f f就是域的个数, 这里的时间复杂度会到 O ( k n 2 ) O(kn^2) O(kn2), 因为隐向量和field有关, FFM的二次项并不能够化简。
这里的域理解起来的话其实就是先对特征根据性质的不同进行了一个分类,不同的分类就是不同的域,域内特征一般都是同一个categorical特征经过One-Hot编码生成的数值特征,比如用户性别, 职业, 日期啊等等。比如:

对于连续特征, 一个特征就对应一个域, 或者可以对连续特征离散化, 一个分箱成为一个特征, 总的分箱是一个域。 对于离散特征, 就像上面说的, 采用one-hot编码, 同一种属性的归到一个域。
好了, 如果经过上面的铺垫感觉FFM差不多了, 那么下面就是模型的方程了:
y ^ ( X ) = ω 0 + ∑ i = 1 n ω i x i + ∑ i = 1 n − 1 ∑ j = i + 1 n < v i , f j , v j , f i > x i x j \hat{y}(X) = \omega_{0}+\sum_{i=1}^{n}{\omega_{i}x_{i}}+\sum_{i=1}^{n-1}{\sum_{j=i+1}^{n} \color{blue}{
这里可以和FM进行一个对比, 其实就是权重计算的那块变了。
下面先用文文大佬的一个例子看一下FFM的特征组合方式, 然后简单的推导一下上面这个方程具体怎么学习求参数。
假设输入记录如下:

这条记录可以编码成5个特征,其中“Genre=Comedy”和“Genre=Drama”属于同一个field,“Price”是数值型,不用One-Hot编码转换。为了方便说明FFM的样本格式,我们将所有的特征和对应的field映射成整数编号。
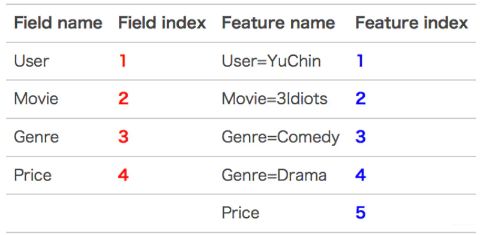
那么,FFM的组合特征有10项,如下图所示。
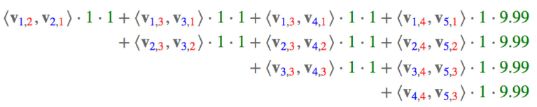
其中,红色是field编号,蓝色是特征编号。
下面来讨论FFM的具体训练细节, 我们依然会使用梯度下降来更新参数, 那么涉及到的一点依然是求导。 看看FFM这里如何求导。关于公式的前面两部分, 和FM一样, 这里不说了, 主要是蓝色的那一部分, 拿下来单独看:
y ^ = ∑ i = 1 n − 1 ∑ j = i + 1 n < v i , f j , v j , f i > x i x j \hat{y} = \sum_{i=1}^{n-1}{\sum_{j=i+1}^{n} \color{blue}{
以上面表格里面的用户1的 y ^ \hat y y^为例:
y ^ = < v 1 , f 2 ⋅ v 2 , f 1 > x 1 x 2 + < v 1 , f 3 ⋅ v 3 , f 1 > x 1 x 3 + < v 1 , f 4 ⋅ v 4 , f 1 > x 1 x 4 + ⋯ \hat{\boldsymbol{y}}=
这里由于 x 2 , x 3 , x 4 x_2,x_3,x_4 x2,x3,x4都属于field2域, 所以这里的 f 2 , f 3 , f 4 f_2,f_3,f_4 f2,f3,f4都可以用 f 2 f_2 f2来代替, 即
y ^ = < v 1 , f 2 ⋅ v 2 , f 1 > x 1 x 2 + < v 1 , f 2 ⋅ v 3 , f 1 > x 1 x 3 + < v 1 , f 2 ⋅ v 4 , f 1 > x 1 x 4 + ⋯ \hat{\boldsymbol{y}}=
这时候, 计算一下 y ^ \hat y y^对 v 1 , f 2 v_{1,f_2} v1,f2的偏导:
∂ y ^ ∂ v 1 , f 2 = v 2 , f 1 x 1 x 2 + v 3 , f 1 x 1 x 3 + v 4 , f 1 x 1 x 4 \frac{\partial \hat{y}}{\partial v_{1, f 2}}=v_{2, f 1} x_{1} x_{2}+v_{3, f 1} x_{1} x_{3}+v_{4, f 1} x_{1} x_{4} ∂v1,f2∂y^=v2,f1x1x2+v3,f1x1x3+v4,f1x1x4
注意此时 x 2 , x 3 , x 4 x_2,x_3,x_4 x2,x3,x4属于同一属性的one-hot表示, 即三个里面只有一个是1, 其他为0, 比如这里面 x 2 = 1 x_2=1 x2=1,那么
∂ y ^ ∂ v 1 , f 2 = v 2 , f 1 x 1 x 2 \frac{\partial \hat{y}}{\partial v_{1, f 2}}=v_{2, f 1} x_{1} x_{2} ∂v1,f2∂y^=v2,f1x1x2
推广到一般情况就是:
∂ y ^ ∂ v i , f j = v j , f i x i x j \frac{\partial \hat{y}}{\partial v_{i, f j}}=v_{j, f i} x_{i} x_{j} ∂vi,fj∂y^=vj,fixixj
x j x_j xj属于Field f j f_j fj, 且同一个Field里面的其他 x m x_m xm都等于0, 实际项目里面 x x x是非常高维的稀疏向量, 求导时只关注非0项即可。
那么有了导数, 后面就是采用梯度下降法进行更新了。 但是这里或许会有个疑问, 就是一般求导,不是损失函数对参数的导数吗? 这里包括上面的FM, 为啥是 y ^ \hat y y^对参数的导数呢?这个 如果你发现了这一步, 说明你对ML梯度更新这块掌握的很不错了。 这里就把这个疑问给解开:
在实际点击率预测的时候, 我们一般是不会直接用这个 y ^ \hat{y} y^的, 而是会在外面在套一层sigmoid函数, 即
z = ϕ ( v , x ) = ∑ i = 1 n ∑ j = i + 1 n v i , f j ⋅ v j , f i x i x j a = σ ( z ) = 1 1 + e − z = 1 1 + e − ϕ ( v , x ) z=\phi(v, x)=\sum_{i=1}^{n} \sum_{j=i+1}^{n} v_{i, f j} \cdot v_{j, f i} x_{i} x_{j} \\ a=\sigma(z)=\frac{1}{1+e^{-z}}=\frac{1}{1+e^{-\phi(v, x)}} z=ϕ(v,x)=i=1∑nj=i+1∑nvi,fj⋅vj,fixixja=σ(z)=1+e−z1=1+e−ϕ(v,x)1
这里的 a a a是我们对点击率预测值。 那么这时候, 假设 y = 0 y=0 y=0表示负样本, y = 1 y=1 y=1表示正样本, C C C为交叉熵损失的话, 那么
∂ C ∂ z = a − y = { − e − z 1 + e − z i f y 是正样本 1 1 + e − z i f y 是负样本 \frac{\partial C}{\partial z}=a-y=\left\{\begin{array}{cl} -\frac{e^{-z}}{1+e^{-z}} & i f y \text { 是正样本 } \\ \frac{1}{1+e^{-z}} & i f y \text { 是负样本 } \end{array}\right. ∂z∂C=a−y={ −1+e−ze−z1+e−z1ify 是正样本 ify 是负样本
这个式子如果想推一推, 可以参考我写的那篇逻辑回归,那么此时如果再把这个划开, 其实就是
∂ C ∂ v i , f j = ∂ C ∂ z ∂ z ∂ v i , f j \frac{\partial C}{\partial v_{i, f j}}=\frac{\partial C}{\partial z} \frac{\partial z}{\partial v_{i, f j}} ∂vi,fj∂C=∂z∂C∂vi,fj∂z
这不就是损失函数对参数的求导了。 后面的那一块就是上面求得那个。
当然,如果看论文, 会发现参数更新公式长这样:

这是因为这里面y=1是正样本, y=-1是负样本。 这时候损失函数就不是我们之前所学的那种逻辑回归的形式, 而是:
min w ∑ i = 1 L log ( 1 + exp { − y i ϕ ( w , x i ) } ) + λ 2 ∥ w ∥ 2 \min _{\mathbf{w}} \sum_{i=1}^{L} \log \left(1+\exp \left\{-y_{i} \phi\left(\mathbf{w}, \mathbf{x}_{i}\right)\right\}\right)+\frac{\lambda}{2}\|\mathbf{w}\|^{2} wmini=1∑Llog(1+exp{ −yiϕ(w,xi)})+2λ∥w∥2
但有了上面的推导过程, 这个应该很好理解了。无非就是损失函数换了换样子, 穿了另一个马甲而已
4.2 FFM模型的代码实战
关于FFM的代码实战, 这里参考了下面的FFM代码实现, 这个是从头手撸了一个, 在这里简单的整理一下我学习到的一些思想吧, 具体可以参考下面链接的分析。
首先,FFM模型的话, 需要的数据是有格式要求的, 一般是存储稀疏矩阵, 且格式会是

所以, 在代码具体实现中, 把这种一一看成了链表节点的形式, 所以一开始定义了一个FFM_Node
class FFM_Node(object):
'''
通常x是高维稀疏向量,所以用链表来表示一个x,链表上的每个节点是个3元组(j,f,v)
'''
__slots__ = ['j', 'f', 'v'] # 按照元组不是字典的方式存储类的成员属性
def __init__(self, j, f, v):
"""
j: Feature index (0-n-1)
f: field index(0-m-1)
v: value
"""
self.j = j
self.f = f
self.v = v
这个类就是以元组的形式储存数据, 方便后面的操作。 FFM模型具体实现的时候, 这个和FM不一样的就是这里没法先将公式化简, 然后使用向量运算一步到位, 对于交叉特征, 这里只能写两重循环去实现。所以看看FFM这个模型具体实现的时候, 需要哪些自己的属性:
def __init__(self, m, n, k, eta, lambd):
"""
m: Number of fields
n: Number of features
k: Number of latent factors
eta: learning rate
lambd: regularization coefficient
"""
self.m = m
self.n = n
self.k = k
#超参数
self.eta = eta
self.lambd = lambd
# 初始化三维权重矩阵w~U(0, 1/sqrt(k))
self.w = np.random.rand(n, m, k) / math.sqrt(k)
# 初始化累积梯度平方和, AdaGrad时要用到
self.G = np.ones(shape=(n, m, k), dtype=np.float64)
self.log = Logistic()
比较核心的就是域的个数, 特征的个数, 隐向量的维度, w矩阵。 学习率和lambda是和训练相关的参数, 而G这个是采用了Adagrad算法, 这里面更新的时候要用到。 下面看一下前向传播, 要注意那个两层的循环计算权重, 这里其实是FFM的核心部分了:
# 这个是计算第三项
def phi(self, node_list):
"""
特征组合式的线性加权求和
param node_list: 用链表存储x中的非0值
"""
z = 0.0
for a in range(len(node_list)):
node1 = node_list[a]
j1 = node1.j
f1 = node1.f
v1 = node1.v
for b in range(a+1, len(node_list)):
node2 = node_list[b]
j2 = node2.j
f2 = node2.f
v2 = node2.v
w1 = self.w[j1, f2]
w2 = self.w[j2, f1]
z += np.dot(w1, w2) * v1 * v2
return z
这里只计算的公式里面的第三项, 传入参数是node_list, 也就是所有的数据都以链表的形式穿起来了。当然具体实现的时候一个列表即可。 这里应该不用过多解释, 就是严格按照FFM的计算公式算的第三项。 下面再来看看反向传播, 也就是求导数的过程, 这里用的随机梯度下降:
# 随机梯度下降
def sgd(self, node_list, y):
"""
根据一个样本更新模型参数:
node_list: 链表存储x中的非0值
y: 正样本1, 负样本-1
"""
kappa = -y / (1+math.exp(y*self.phi(node_list))) # 论文里面的那个导数
for a in range(len(node_list)):
node1 = node_list[a]
j1 = node1.j
f1 = node1.f
v1 = node1.v
for b in range(a+1, len(node_list)):
node2 = node_list[b]
j2 = node2.j
f2 = node2.f
v2 = node2.v
c = kappa * v1 * v2 # 这是求导数
# self.w[j1,f2]和self.w[j2,f1]是向量,导致g_j1_f2和g_j2_f1也是向量
g_j1_f2 = self.lambd * self.w[j1, f2] + c * self.w[j2, f1]
g_j2_f1 = self.lambd * self.w[j2, f1] + c * self.w[j1, f2]
# 计算各个维度上的梯度累积平方和
self.G[j1, f2] += g_j1_f2 ** 2
self.G[j2, f1] += g_j2_f1 ** 2
# Adagrad 算法
self.w[j1, f2] -= self.eta / np.sqrt(self.G[j1, f2]) * g_j1_f2 # sqrt(G)作为分母,所以G必须是大于0的正数
self.w[j2, f1] -= self.eta / np.sqrt(
self.G[j2, f1]) * g_j2_f1 # math.sqrt()只能接收一个数字作为参数,而numpy.sqrt()可以接收一个array作为参数,表示对array中的每个元素分别开方
这个代码从远处看或许比较复杂, 但思路依然不难, 我们是先要求各个交叉项参数的导数, 然后根据梯度下降公式更新参数。 求导数, 根据上面推导的公式, 就会一目了然。

唯一不一样的时候,就是求出导数之后, 参数的更新方式, 这里用的Adagrad算法。
这里就把FFM具体实现过程中的细节整理了一下, 更多的参考下面的链接吧。文文大佬还给了一个TensorFlow版本的, 也可以参考一下计算方式。
5. 总结
这篇文章也是用了一周的时间整理, 因为推荐这边的文章也是现学现卖哈哈, 所以难免会有疏漏或者理解错误之处, 还请各位伙伴如果发现了即使指正。 这篇文章由于涉及到了两个模型, 所以篇幅还是比较长, 依然是各取所需即可。
下面简单的梳理一下这篇文章和推荐系统深度学习的前夜模型。 这篇文章是深度学习前夜里面的最后一篇, 主要是围绕着两个模型FM和FFM模型展开, 逻辑非常清楚, 首先是先抛出了之前的逻辑回归存在的手动交叉特征的问题, 从而先整理了POLY2模型的思路,也就是二项交叉,但是这个模型会有一些不足, 分析了一下, 然后引出了FM模型, 整理了FM模型的原理及代码实践部分。 接着在FM的基础上进行了扩展, 得到了FFM模型, 又整理了FFM模型的原理及代码实践部分。
不知不觉,从开始学习推荐系统到现在,用了大约不到1个月的时间吧, 已经过了一遍前深度学习模型时代的四五个比较重要的Model和代码, 并整理了四篇文章。 虽然花费了很多时间, 但收获很大, 并且这次亲自体验了一下任务驱动的学习方式, 确实效率会高一些(这次有幸参与了Datawhale10月推荐系统组队的文档编写任务), 下面简单的回顾一下前深度学习时代这四篇文章之间的联系

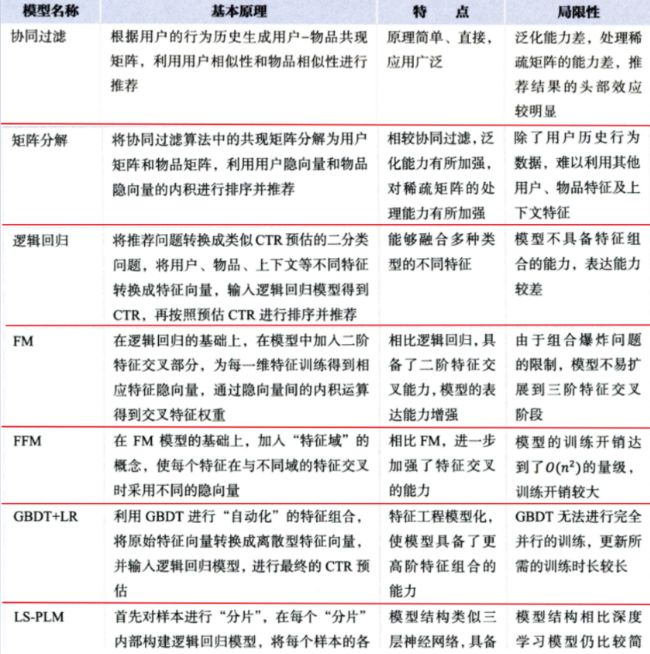
这次是按照王喆老师梳理好的这个框架进行的展开的, 逻辑应该是一目了然, 这里不再啰嗦了, 还有一个LS-PLM模型, 这个曾是阿里的主流推荐模型, 当然也是2017年以前了吧, 再这里没有具体详细整理, 这个模型是在逻辑回归的基础上采用了分而治之的思想, 先对样本进行分组(聚类), 再在样本中使用逻辑回归。因为有时候, 用户群里的类别不同, 行为会有很大的不同,比如男性往往喜欢数码产品, 而女性往往喜欢衣服等。 那么这时候, 考虑用户点击数码广告的时候, 往往不用把女性点击衣服等行为考虑进来, 因为这些和目标相关性不大, 所以为了让CTR模型对不同用户群体, 不同使用场景更有针对性, 阿里就提出了LS-PLM模型, 先对全量样本进行聚类, 再对每个分类用逻辑回归完成CTR预估, 这其实是提供了另外一种新思路,因为模型可不一定非得逻辑回归哟, 这些处理问题的idea往往是我们需要学习的。这个模型已经有了深度学习的味道, 类似于一个加入注意力机制的三层神经网络模型。 当然具体的细节还是看王喆老师的那本书吧。 下面是模型的大总结:
关于前深度学习时代的模型, 就先到这里了, 下面就是深度学习的浪潮之巅了, 这里面才更能体会到这几年深度学习对于推荐系统发展的驱动, 2016年开始, 推荐系统进入了深度学习的浪潮,至今为止, 依然高速发展。 最后, 再梳理一下时间线:

后面依然是保持一周更新一个推荐模型, 因为根据这四篇文章大体算了一下, 由于也是刚学这些知识, 所以整理的时候,一般需要先从原论文开始, 到参考很多优质的文章, 再到代码实践部分, 每天去除掉其他任务的一些时间, 感觉五天学习, 周末整理刚刚好哈哈,下面继续Rush吧
参考:
- 王喆 - 《深度学习推荐系统》
- 推荐系统遇上深度学习(一)–FM模型理论和实践
- 推荐系统遇上深度学习(二)–FFM模型理论和实践
- FM算法解析
- FM算法原理分析与实践
- 深入理解FFM原理与实践
- FFM原理及公式推导
- FM在特征组合中的应用
- FFM算法解析及Python实现
- FFM代码实现
- pyFM包
- 文文大佬的GitHub
论文:
- FM论文原文
- FFM论文原文
整理这篇文章的同时, 也刚建立了一个GitHub项目, 准备后面把各种主流的推荐模型复现一遍,并用通俗易懂的语言进行注释和逻辑整理, 今天的FM+FFM模型代码已经上传,感兴趣的可以看一下
筋斗云:https://github.com/zhongqiangwu960812/AI-RecommenderSystem