Hadoop 之 MapReduce 的工作原理及其倒排索引的建立
一、Hadoop 简介
下面先从一张图理解MapReduce得整个工作原理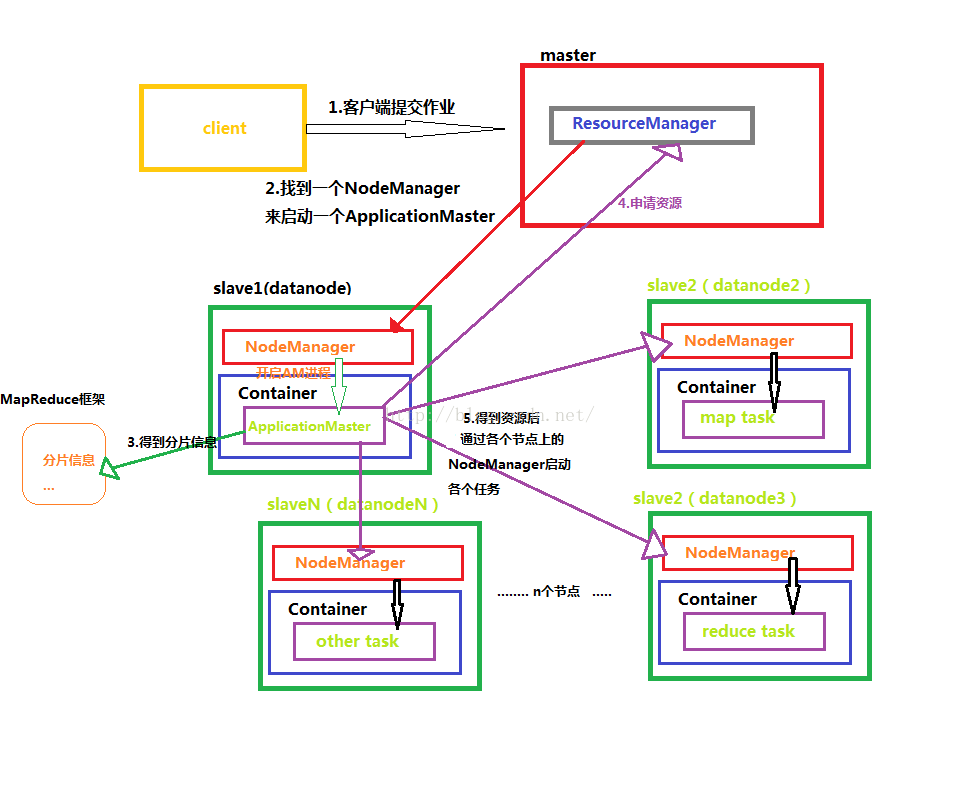
下面对上面出现的一些名词进行介绍
ResourceManager:是YARN资源控制框架的中心模块,负责集群中所有的资源的统一管理和分配。它接收来自NM(NodeManager)的汇报,建立AM,并将资源派送给AM(ApplicationMaster)。
NodeManager:简称NM,NodeManager是ResourceManager在每台机器的上代理,负责容器的管理,并监控他们的资源使用情况(cpu,内存,磁盘及网络等),以及向 ResourceManager提供这些资源使用报告。
ApplicationMaster:以下简称AM。YARN中每个应用都会启动一个AM,负责向RM申请资源,请求NM启动container,并告诉container做什么事情。
Container:资源容器。YARN中所有的应用都是在container之上运行的。AM也是在container上运行的,不过AM的container是RM申请的。
1. Container是YARN中资源的抽象,它封装了某个节点上一定量的资源(CPU和内存两类资源)。
2. Container由ApplicationMaster向ResourceManager申请的,由ResouceManager中的资源调度器异步分配给ApplicationMaster;
3. Container的运行是由ApplicationMaster向资源所在的NodeManager发起的,Container运行时需提供内部执行的任务命令(可以是任何命令,比如java、Python、C++进程启动命令均可)以及该命令执行所需的环境变量和外部资源(比如词典文件、可执行文件、jar包等)。
另外,一个应用程序所需的Container分为两大类,如下:
(1) 运行ApplicationMaster的Container:这是由ResourceManager(向内部的资源调度器)申请和启动的,用户提交应用程序时,可指定唯一的ApplicationMaster所需的资源;
(2) 运行各类任务的Container:这是由ApplicationMaster向ResourceManager申请的,并由ApplicationMaster与NodeManager通信以启动之。
以上两类Container可能在任意节点上,它们的位置通常而言是随机的,即ApplicationMaster可能与它管理的任务运行在一个节点上。
整个MapReduce的过程大致分为 Map-->Shuffle(排序)-->Combine(组合)-->Reduce
下面通过一个单词计数案例来理解各个过程
1)将文件拆分成splits(片),并将每个split按行分割形成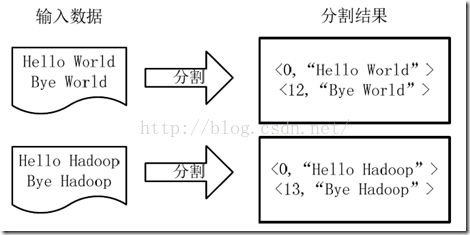
分割过程
将分割好的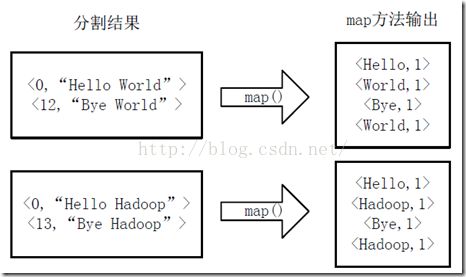
执行map方法
得到map方法输出的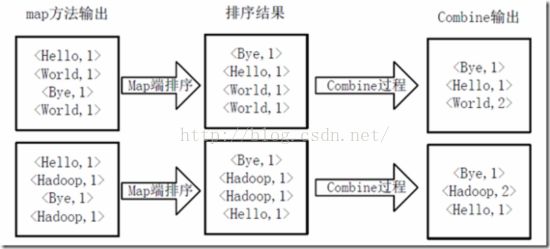
Map端排序及Combine过程
Reducer先对从Mapper接收的数据进行排序,再交由用户自定义的reduce方法进行处理,得到新的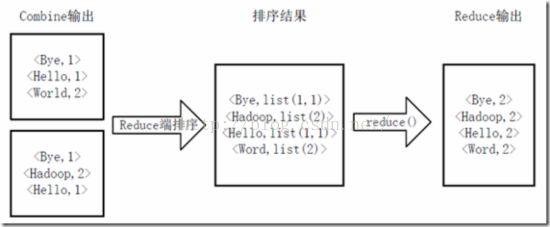
Reduce端排序及输出结果
下面看怎么用Java来实现WordCount单词计数的功能
首先看Map过程
Map过程需要继承org.apache.hadoop.mapreduce.Mapper包中 Mapper 类,并重写其map方法。
/**
* Mapper中 LongWritable,IntWritable是Hadoop数据类型表示长整型和整形
*
* LongWritable, Text表示输入类型 (比如本应用单词计数输入是 偏移量(字符串中的第一个单词的其实位置),对应的单词(值))
* Text, IntWritable表示输出类型 输出是单词 和他的个数
* 注意:map函数中前两个参数LongWritable key, Text value和输出类型不一致
* 所以后面要设置输出类型 要使他们一致
*/
//Map过程
public static class WordCountMapper extends Mapper {
/***
*
*/
@Override
protected void map(LongWritable key, Text value, Mapper.Context context)
throws IOException, InterruptedException {
//默认的map的value是每一行,我这里自定义的是以空格分割
String[] vs = value.toString().split("\\s");
for (String v : vs) {
//写出去
context.write(new Text(v), ONE);
}
}
}
Reduce过程
Reduce过程需要继承org.apache.hadoop.mapreduce包中 Reducer 类,并 重写 其reduce方法。Map过程输出中key为单个单词,而values是对应单词的计数值所组成的列表,Map的输出就是Reduce的输入,所以reduce方法只要遍历values并求和,即可得到某个单词的总次数。
//Reduce过程
/***
* Text, IntWritable输入类型,从map过程获得 既map的输出作为Reduce的输入
* Text, IntWritable输出类型
*/
public static class WordCountReducer extends Reducer{
@Override
protected void reduce(Text key, Iterable values,
Reducer.Context context) throws IOException, InterruptedException {
int count=0;
for(IntWritable v:values){
count+=v.get();//单词个数加一
}
context.write(key, new IntWritable(count));
}
}
最后执行MapReduce任务
public static void main(String[] args) {
Configuration conf=new Configuration();
try {
//args从控制台获取路径 解析得到域名
String[] paths=new GenericOptionsParser(conf,args).getRemainingArgs();
if(paths.length<2){
throw new RuntimeException("必須輸出 輸入 和输出路径");
}
//得到一个Job 并设置名字
Job job=Job.getInstance(conf,"wordcount");
//设置Jar 使本程序在Hadoop中运行
job.setJarByClass(WordCount.class);
//设置Map处理类
job.setMapperClass(WordCountMapper.class);
//设置map的输出类型,因为不一致,所以要设置
job.setMapOutputKeyClass(Text.class);
job.setOutputValueClass(IntWritable.class);
//设置Reduce处理类
job.setReducerClass(WordCountReducer.class);
//设置输入和输出目录
FileInputFormat.addInputPath(job, new Path(paths[0]));
FileOutputFormat.setOutputPath(job, new Path(paths[1]));
//启动运行
System.exit(job.waitForCompletion(true) ? 0:1);
} catch (IOException e) {
e.printStackTrace();
} catch (ClassNotFoundException e) {
e.printStackTrace();
} catch (InterruptedException e) {
e.printStackTrace();
}
}
即可求得每个单词的个数
下面把整个过程的源码附上,有需要的朋友可以拿去测试
package hadoopday02;
import java.io.IOException;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import org.apache.hadoop.util.GenericOptionsParser;
public class WordCount {
//计数变量
private static final IntWritable ONE = new IntWritable(1);
/**
*
* @author 汤高
* Mapper中 LongWritable,IntWritable是Hadoop数据类型表示长整型和整形
*
* LongWritable, Text表示输入类型 (比如本应用单词计数输入是 偏移量(字符串中的第一个单词的其实位置),对应的单词(值))
* Text, IntWritable表示输出类型 输出是单词 和他的个数
* 注意:map函数中前两个参数LongWritable key, Text value和输出类型不一致
* 所以后面要设置输出类型 要使他们一致
*/
//Map过程
public static class WordCountMapper extends Mapper {
/***
*
*/
@Override
protected void map(LongWritable key, Text value, Mapper.Context context)
throws IOException, InterruptedException {
//默认的map的value是每一行,我这里自定义的是以空格分割
String[] vs = value.toString().split("\\s");
for (String v : vs) {
//写出去
context.write(new Text(v), ONE);
}
}
}
//Reduce过程
/***
* Text, IntWritable输入类型,从map过程获得 既map的输出作为Reduce的输入
* Text, IntWritable输出类型
*/
public static class WordCountReducer extends Reducer{
@Override
protected void reduce(Text key, Iterable values,
Reducer.Context context) throws IOException, InterruptedException {
int count=0;
for(IntWritable v:values){
count+=v.get();//单词个数加一
}
context.write(key, new IntWritable(count));
}
}
public static void main(String[] args) {
Configuration conf=new Configuration();
try {
//args从控制台获取路径 解析得到域名
String[] paths=new GenericOptionsParser(conf,args).getRemainingArgs();
if(paths.length<2){
throw new RuntimeException("必須輸出 輸入 和输出路径");
}
//得到一个Job 并设置名字
Job job=Job.getInstance(conf,"wordcount");
//设置Jar 使本程序在Hadoop中运行
job.setJarByClass(WordCount.class);
//设置Map处理类
job.setMapperClass(WordCountMapper.class);
//设置map的输出类型,因为不一致,所以要设置
job.setMapOutputKeyClass(Text.class);
job.setOutputValueClass(IntWritable.class);
//设置Reduce处理类
job.setReducerClass(WordCountReducer.class);
//设置输入和输出目录
FileInputFormat.addInputPath(job, new Path(paths[0]));
FileOutputFormat.setOutputPath(job, new Path(paths[1]));
//启动运行
System.exit(job.waitForCompletion(true) ? 0:1);
} catch (IOException e) {
e.printStackTrace();
} catch (ClassNotFoundException e) {
e.printStackTrace();
} catch (InterruptedException e) {
e.printStackTrace();
}
}
}
二、通过 Hadoop 建立倒排索引
倒排索引就是根据单词内容来查找文档的方式,由于不是根据文档来确定文档所包含的内容,进行了相反的操作,所以被称为倒排索引, 它是搜索引擎最为核心的数据结构,以及文档检索的关键部分。
下面来看一个例子来理解什么是倒排索引
这里我准备了两个文件 分别为1.txt和2.txt
1.txt的内容如下
I Love Hadoop
I like ZhouSiYuan
I love me
2.txt的内容如下
I Love MapReduce
I like NBA
I love Hadoop
我这里使用的是默认的输入格式TextInputFormat,他是一行一行的读的,键是偏移量。
所以在map阶段之前的到结果如下
map阶段从1.txt的得到的输入
0 I Love Hadoop
15 I like ZhouSiYuan
34 I love me
map阶段从2.txt的得到的输入
0 I Love MapReduce
18 I like NBA
30 I love Hadoop
map阶段
把词频作为值
把单词和URI组成key值
比如
key : I+hdfs://192.168.52.140:9000/index/2.txt value:1
为什么要这样设置键和值?
因为这样设计可以使用MapReduce框架自带的map端排序,将同一单词的词频组成列表
经过map阶段1.txt得到的输出如下
I:hdfs://192.168.52.140:9000/index/1.txt 1
Love:hdfs://192.168.52.140:9000/index/1.txt 1
MapReduce:hdfs://192.168.52.140:9000/index/1.txt 1
I:hdfs://192.168.52.140:9000/index/1.txt 1
Like:hdfs://192.168.52.140:9000/index/1.txt 1
ZhouSiYuan:hdfs://192.168.52.140:9000/index/1.txt 1
I:hdfs://192.168.52.140:9000/index/1.txt 1
love:hdfs://192.168.52.140:9000/index/1.txt 1
me:hdfs://192.168.52.140:9000/index/1.txt 1
经过map阶段2.txt得到的输出如下
I:hdfs://192.168.52.140:9000/index/2.txt 1
Love:hdfs://192.168.52.140:9000/index/2.txt 1
MapReduce:hdfs://192.168.52.140:9000/index/2.txt 1
I:hdfs://192.168.52.140:9000/index/2.txt 1
Like:hdfs://192.168.52.140:9000/index/2.txt 1
NBA:hdfs://192.168.52.140:9000/index/2.txt 1
I:hdfs://192.168.52.140:9000/index/2.txt 1
love:hdfs://192.168.52.140:9000/index/2.txt 1
Hadoop:hdfs://192.168.52.140:9000/index/2.txt 1
1.txt经过MapReduce框架自带的map端排序得到的输出结果如下
I:hdfs://192.168.52.140:9000/index/1.txt list{1,1,1}
Love:hdfs://192.168.52.140:9000/index/1.txt list{1}
MapReduce:hdfs://192.168.52.140:9000/index/1.txt list{1}
Like:hdfs://192.168.52.140:9000/index/1.txt list{1}
ZhouSiYuan:hdfs://192.168.52.140:9000/index/1.txt list{1}
love:hdfs://192.168.52.140:9000/index/1.txt list{1}
me:hdfs://192.168.52.140:9000/index/1.txt list{1}
2.txt经过MapReduce框架自带的map端排序得到的输出结果如下
I:hdfs://192.168.52.140:9000/index/2.txt list{1,1,1}
Love:hdfs://192.168.52.140:9000/index/2.txt list{1}
MapReduce:hdfs://192.168.52.140:9000/index/2.txt list{1}
Like:hdfs://192.168.52.140:9000/index/2.txt list{1}
NBA:hdfs://192.168.52.140:9000/index/2.txt list{1}
love:hdfs://192.168.52.140:9000/index/2.txt list{1}
Hadoop:hdfs://192.168.52.140:9000/index/2.txt list{1}
combine阶段:
key值为单词,
value值由URI和词频组成
value: hdfs://192.168.52.140:9000/index/2.txt:3 key:I
为什么这样设计键值了?
因为在Shuffle过程将面临一个问题,所有具有相同单词的记录(由单词、URL和词频组成)应该交由同一个Reducer处理
所以重新把单词设置为键可以使用MapReduce框架默认的Shuffle过程,将相同单词的所有记录发送给同一个Reducer处理
combine阶段将key相同的value值累加
1.txt得到如下输出
I hdfs://192.168.52.140:9000/index/1.txt:3
Love hdfs://192.168.52.140:9000/index/1.txt:1
MapReduce hdfs://192.168.52.140:9000/index/1.txt:1
Like hdfs://192.168.52.140:9000/index/1.txt:1
ZhouSiYuan hdfs://192.168.52.140:9000/index/1.txt:1
love hdfs://192.168.52.140:9000/index/1.txt:1
me hdfs://192.168.52.140:9000/index/1.txt:1
2.txt得到如下输出
I hdfs://192.168.52.140:9000/index/2.txt:3
Love hdfs://192.168.52.140:9000/index/2.txt:1
MapReduce hdfs://192.168.52.140:9000/index/2.txt:1
Like hdfs://192.168.52.140:9000/index/2.txt:1
NBA hdfs://192.168.52.140:9000/index/2.txt:1
love hdfs://192.168.52.140:9000/index/2.txt:1
Hadoop hdfs://192.168.52.140:9000/index/2.txt:1
这样reducer过程就很简单了,它只用来生成文档列表
比如相同的单词I,这样生成文档列表
I hdfs://192.168.52.140:9000/index/2.txt:3;hdfs://192.168.52.140:9000/index/1.txt:3;
最后所有的输出结果如下
Hadoop hdfs://192.168.52.140:9000/index/1.txt:1;hdfs://192.168.52.140:9000/index/2.txt:1;
I hdfs://192.168.52.140:9000/index/2.txt:3;hdfs://192.168.52.140:9000/index/1.txt:3;
Love hdfs://192.168.52.140:9000/index/1.txt:1;hdfs://192.168.52.140:9000/index/2.txt:1;
MapReduce hdfs://192.168.52.140:9000/index/2.txt:1;
NBA hdfs://192.168.52.140:9000/index/2.txt:1;
ZhouSiYuan hdfs://192.168.52.140:9000/index/1.txt:1;
like hdfs://192.168.52.140:9000/index/1.txt:1;hdfs://192.168.52.140:9000/index/2.txt:1;
love hdfs://192.168.52.140:9000/index/2.txt:1;hdfs://192.168.52.140:9000/index/1.txt:1;
me hdfs://192.168.52.140:9000/index/1.txt:1;
下面是整个源代码
package com.hadoop.mapreduce.test8.invertedindex;
import java.io.IOException;
import java.util.StringTokenizer;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.input.FileSplit;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
public class InvertedIndex {
/**
*
* @author 汤高
*
*/
public static class InvertedIndexMapper extends Mapper{
private Text keyInfo = new Text(); // 存储单词和URI的组合
private Text valueInfo = new Text(); //存储词频
private FileSplit split; // 存储split对象。
@Override
protected void map(Object key, Text value, Mapper.Context context)
throws IOException, InterruptedException {
//获得对所属的FileSplit对象。
split = (FileSplit) context.getInputSplit();
System.out.println("偏移量"+key);
System.out.println("值"+value);
//StringTokenizer是用来把字符串截取成一个个标记或单词的,默认是空格或多个空格(\t\n\r等等)截取
StringTokenizer itr = new StringTokenizer( value.toString());
while( itr.hasMoreTokens() ){
// key值由单词和URI组成。
keyInfo.set( itr.nextToken()+":"+split.getPath().toString());
//词频初始为1
valueInfo.set("1");
context.write(keyInfo, valueInfo);
}
System.out.println("key"+keyInfo);
System.out.println("value"+valueInfo);
}
}
/**
*
* @author 汤高
*
*/
public static class InvertedIndexCombiner extends Reducer{
private Text info = new Text();
@Override
protected void reduce(Text key, Iterable values, Reducer.Context context)
throws IOException, InterruptedException {
//统计词频
int sum = 0;
for (Text value : values) {
sum += Integer.parseInt(value.toString() );
}
int splitIndex = key.toString().indexOf(":");
//重新设置value值由URI和词频组成
info.set( key.toString().substring( splitIndex + 1) +":"+sum );
//重新设置key值为单词
key.set( key.toString().substring(0,splitIndex));
context.write(key, info);
System.out.println("key"+key);
System.out.println("value"+info);
}
}
/**
*
* @author 汤高
*
*/
public static class InvertedIndexReducer extends Reducer{
private Text result = new Text();
@Override
protected void reduce(Text key, Iterable values, Reducer.Context context)
throws IOException, InterruptedException {
//生成文档列表
String fileList = new String();
for (Text value : values) {
fileList += value.toString()+";";
}
result.set(fileList);
context.write(key, result);
}
}
public static void main(String[] args) {
try {
Configuration conf = new Configuration();
Job job = Job.getInstance(conf,"InvertedIndex");
job.setJarByClass(InvertedIndex.class);
//实现map函数,根据输入的对生成中间结果。
job.setMapperClass(InvertedIndexMapper.class);
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(Text.class);
job.setCombinerClass(InvertedIndexCombiner.class);
job.setReducerClass(InvertedIndexReducer.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(Text.class);
//我把那两个文件上传到这个index目录下了
FileInputFormat.addInputPath(job, new Path("hdfs://192.168.52.140:9000/index/"));
//把结果输出到out_index+时间戳的目录下
FileOutputFormat.setOutputPath(job, new Path("hdfs://192.168.52.140:9000/out_index"+System.currentTimeMillis()+"/"));
System.exit(job.waitForCompletion(true) ? 0 : 1);
} catch (IllegalStateException e) {
e.printStackTrace();
} catch (IllegalArgumentException e) {
e.printStackTrace();
} catch (ClassNotFoundException e) {
e.printStackTrace();
} catch (IOException e) {
e.printStackTrace();
} catch (InterruptedException e) {
e.printStackTrace();
}
}
} 转载自: https://blog.csdn.net/tanggao1314/article/details/51340672