pytorch搭建神经网络玩转mnist
文章目录
- 引入必要的包
- 构建分类模型
-
- MNIST介绍
- 设置网络结构
- 重写_init_和forward方法,完成结构的搭建和前向传播
- 训练过程
-
- 设置超参数
- 设法使weight和bias在初始化时拥有不同的参数分布
-
- 默认型
- 正态分布
- 初始化为常数
- 初始化为xaveir_uniform来保持每一层的梯度大小都差不多相同, 在tanh中表现的很好
- kaiming是针对于Relu的初始化方法,pytorch也是使用kaiming 初始化卷积层参数的
- 对数据进行预处理
-
- 上面的图片恰好是16*8的大小,8是nrow的默认值,128是batch_size
- 正式训练
- 保存训练好的模型参数
-
- 打印模型参数
- 将参数保存在本地
- 加载模型参数
- 观察l2_norm对结果的影响
- 观察dropout对结果的影响
- 观察batch_normalization对结果的影响
- 观察数据增广对结果的影响
- 使用tensorboard进行可视化
- 检查梯度消失和爆炸问题
-
- 正常情况
- 梯度消失(学习率超小)
- 梯度爆炸(学习率很大)
- 使用模型进行单图像识别
引入必要的包
# Load all necessary modules here, for clearness
import torch
import numpy as np
import torch.nn as nn
import torch.nn.functional as F
import torch.optim as optim
# from torchvision.datasets import MNIST
import torchvision
from torchvision import transforms
from torch.optim import lr_scheduler
from tensorboardX import SummaryWriter
from collections import OrderedDict
import matplotlib.pyplot as plt
from tqdm import tqdm
cuda = torch.device('cuda:0')
构建分类模型
MNIST介绍
The MNIST database (Modified National Institute of Standards and Technology database) is a large database of handwritten digits that is commonly used for training various image processing systems.
The MNIST database contains 60,000 training images and 10,000 testing images. Each class has 5000 traning images and 1000 test images.
Each image is 32x32.
我们将定义前向传播的神经网络来完成分类任务
设置网络结构
Inputs: For every batch
[batchSize, channels, height, width] -> [B,C,H,W]
Outputs: prediction scores of each images, eg. [0.001, 0.0034 …, 0.3]
[batchSize, classes]
Network Strutrue
Inputs Linear/Function Output
[128, 1, 28, 28] -> Linear(28*28, 100) -> [128, 100] # first hidden lyaer
-> ReLU -> [128, 100] # relu activation function, may sigmoid
-> Linear(100, 100) -> [128, 100] # second hidden lyaer
-> ReLU -> [128, 100] # relu activation function, may sigmoid
-> Linear(100, 100) -> [128, 100] # third hidden lyaer
-> ReLU -> [128, 100] # relu activation function, may sigmoid
-> Linear(100, 10) -> [128, 10] # Classification Layer
如果隐层的层数过多,需要用循环来设置层的话,那么要注意把新增的层设为神经网络的属性。
fc = nn.Linear(input_size, 10)
setattr(self, 'fc%i' % i, fc)
重写_init_和forward方法,完成结构的搭建和前向传播
class FeedForwardNeuralNetwork(nn.Module):
"""
Inputs Linear/Function Output
[128, 1, 28, 28] -> Linear(28*28, 100) -> [128, 100] # first hidden lyaer
-> ReLU -> [128, 100] # relu activation function, may sigmoid
-> Linear(100, 100) -> [128, 100] # second hidden lyaer
-> ReLU -> [128, 100] # relu activation function, may sigmoid
-> Linear(100, 100) -> [128, 100] # third hidden lyaer
-> ReLU -> [128, 100] # relu activation function, may sigmoid
-> Linear(100 , 10) -> [128, 10] # Classification Layer
"""
def __init__(self, input_size, hidden_size, output_size, activation_function='RELU'):
super(FeedForwardNeuralNetwork, self).__init__()
self.use_dropout = False
self.use_bn = False
self.hidden1 = nn.Linear(input_size, hidden_size) # Linear function 1: 784 --> 100
self.hidden2 = nn.Linear(hidden_size, hidden_size) # Linear function 2: 100 --> 100
self.hidden3 = nn.Linear(hidden_size, hidden_size) # Linear function 3: 100 --> 100
# Linear function 4 (readout): 100 --> 10
self.classification_layer = nn.Linear(hidden_size, output_size)
self.dropout = nn.Dropout(p=0.5) # Drop out with prob = 0.5
self.hidden1_bn = nn.BatchNorm1d(hidden_size) # Batch Normalization
self.hidden2_bn = nn.BatchNorm1d(hidden_size)
self.hidden3_bn = nn.BatchNorm1d(hidden_size)
# 定义激活函数
if activation_function == 'SIGMOID':
self.activation_function1 = nn.Sigmoid()
self.activation_function2 = nn.Sigmoid()
self.activation_function3 = nn.Sigmoid()
elif activation_function == 'RELU':
self.activation_function1 = nn.ReLU()
self.activation_function2 = nn.ReLU()
self.activation_function3 = nn.ReLU()
def forward(self, x):
"""Defines the computation performed at every call.
Should be overridden by all subclasses.
Args:
x: [batch_size, channel, height, width], input for network
Returns:
out: [batch_size, n_classes], output from network
"""
x = x.view(x.size(0), -1) # 将x的大小调整为 [batch_size, 784]
out = self.hidden1(x)
out = self.activation_function1(out) # Non-linearity 1
if self.use_bn == True:
out = self.hidden1_bn(out)
out = self.hidden2(out)
out = self.activation_function2(out)
if self.use_bn == True:
out = self.hidden2_bn(out)
out = self.hidden3(out)
if self.use_bn == True:
out = self.hidden3_bn(out)
out = self.activation_function3(out)
if self.use_dropout == True:
out = self.dropout(out)
out = self.classification_layer(out)
return out
def set_use_dropout(self, use_dropout):
"""Whether to use dropout. Auxiliary function for our exp, not necessary.
Args:
use_dropout: True, False
"""
self.use_dropout = use_dropout
def set_use_bn(self, use_bn):
"""Whether to use batch normalization. Auxiliary function for our exp, not necessary.
Args:
use_bn: True, False
"""
self.use_bn = use_bn
def get_grad(self):
"""Return average grad for hidden2, hidden3. Auxiliary function for our exp, not necessary.
"""
hidden2_average_grad = np.mean(np.sqrt(np.square(self.hidden2.weight.grad.detach().numpy())))
hidden3_average_grad = np.mean(np.sqrt(np.square(self.hidden3.weight.grad.detach().numpy())))
return hidden2_average_grad, hidden3_average_grad
训练过程
设置超参数
### Hyper parameters
batch_size = 128 # batch size is 128
n_epochs = 5 # train for 5 epochs
learning_rate = 0.01 # learning rate is 0.01
input_size = 28*28 # input image has size 28x28
hidden_size = 100 # hidden neurons is 100 for each layer
output_size = 10 # classes of prediction
l2_norm = 0 # not to use l2 penalty
dropout = False # not to use
get_grad = False # not to obtain grad
# create a model object
model = FeedForwardNeuralNetwork(input_size=input_size, hidden_size=hidden_size, output_size=output_size)
# Cross entropy
loss_fn = torch.nn.CrossEntropyLoss()
# weight)decay的含义是权重衰减,或者说是采用l2正则化
optimizer = torch.optim.SGD(model.parameters(), lr=learning_rate, weight_decay=l2_norm)
设法使weight和bias在初始化时拥有不同的参数分布
默认型
def show_weight_bias(model):
# Create a figure and a set of subplots
fig, axs = plt.subplots(2,3, sharey=False, tight_layout=True)
# weight and bias for every hidden layer
h1_w = model.hidden1.weight.detach().numpy().flatten()
h1_b = model.hidden1.bias.detach().numpy().flatten()
h2_w = model.hidden2.weight.detach().numpy().flatten()
h2_b = model.hidden2.bias.detach().numpy().flatten()
h3_w = model.hidden3.weight.detach().numpy().flatten()
h3_b = model.hidden3.bias.detach().numpy().flatten()
axs[0,0].hist(h1_w)
axs[0,1].hist(h2_w)
axs[0,2].hist(h3_w)
axs[1,0].hist(h1_b)
axs[1,1].hist(h2_b)
axs[1,2].hist(h3_b)
# set title for every sub plots
axs[0,0].set_title('hidden1_weight')
axs[0,1].set_title('hidden2_weight')
axs[0,2].set_title('hidden3_weight')
axs[1,0].set_title('hidden1_bias')
axs[1,1].set_title('hidden2_bias')
axs[1,2].set_title('hidden3_bias')
# Show default initialization for every hidden layer by pytorch
# it's uniform distribution
show_weight_bias(model)

正态分布
# If you want to use other intialization method, you can use code below
# and define your initialization below
def weight_bias_reset(model):
"""Custom initialization, you can use your favorable initialization method.
"""
for m in model.modules():
if isinstance(m, nn.Linear):
# initialize linear layer with mean and std
mean, std = 0, 0.1
# Initialization method
torch.nn.init.normal_(m.weight, mean, std)
torch.nn.init.normal_(m.bias, mean, std)
# Another way to initialize
# m.weight.data.normal_(mean, std)
# m.bias.data.normal_(mean, std)
weight_bias_reset(model) # reset parameters for each hidden layer
show_weight_bias(model) # show weight and bias distribution, normal distribution now.

初始化为常数
# TODO
def weight_bias_reset_constant(model):
"""Constant initalization
"""
for m in model.modules():
if isinstance(m, nn.Linear):
# initialize linear layer with mean and std
val = 1
# Initialization method
torch.nn.init.constant_(m.weight, val)
torch.nn.init.constant_(m.bias, val)
weight_bias_reset_constant(model) # reset parameters for each hidden layer
show_weight_bias(model)

初始化为xaveir_uniform来保持每一层的梯度大小都差不多相同, 在tanh中表现的很好
# TODO
def weight_bias_reset_xavier_uniform(model):
"""xaveir_uniform, gain=1
"""
for m in model.modules():
if isinstance(m, nn.Linear):
# initialize linear layer with mean and std
gain = 1
# Initialization method
torch.nn.init.xavier_uniform_(m.weight, gain)
# torch.nn.init.xavier_uniform_(m.bias, gain)
# print(m.bias.shape)
weight_bias_reset_xavier_uniform(model) # reset parameters for each hidden layer
show_weight_bias(model)
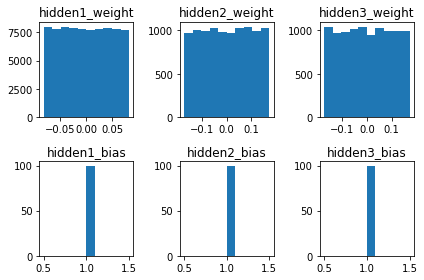
kaiming是针对于Relu的初始化方法,pytorch也是使用kaiming 初始化卷积层参数的
# TODO
def weight_bias_reset_kaiming_uniform(model):
"""xaveir_uniform, gain=1
"""
for m in model.modules():
if isinstance(m, nn.Linear):
# initialize linear layer with mean and std
a = 0
# Initialization method
torch.nn.init.kaiming_uniform_(m.weight, a, mode='fan_in')
# torch.nn.init.kaiming_uniform_(m.bias, a, mode='fan_in')
# print(m.bias.shape)
weight_bias_reset_kaiming_uniform(model) # reset parameters for each hidden layer
show_weight_bias(model)
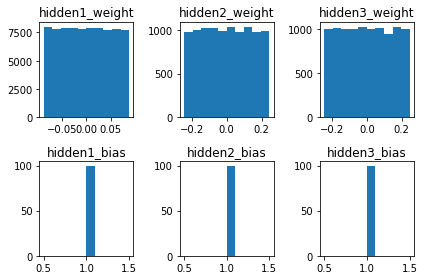
对数据进行预处理
可以用transforms进行以下操作:
-
PIL.Image/numpy.ndarray与Tensor的相互转化;
-
归一化;
-
对PIL.Image进行裁剪、缩放等操作。
-
transforms.Compose就是将transforms组合在一起;
-
取值范围为[0, 255]的PIL.Image,转换成形状为[C, H, W],取值范围是[0, 1.0]的torch.FloadTensor;
形状为[H, W, C]的numpy.ndarray,转换成形状为[C, H, W],取值范围是[0, 1.0]的torch.FloadTenso -
transforms.Normalize使用如下公式进行归一化:channel=(channel-mean)/std
train_transform = transforms.Compose([
transforms.ToTensor(), # transforms.ToTensor() 将 PIL.Image/numpy.ndarray 数据转化为torch.FloadTensor,并归一化到[0, 1.0],大小为3*H*W
# Normalize a tensor image with mean 0.1307 and standard deviation 0.3081
transforms.Normalize((0.1307,), (0.3081,))
])
test_transform = transforms.Compose([
transforms.ToTensor(),
transforms.Normalize((0.1307,), (0.3081,))
])
torchvision.datasets的使用说明:https://pytorch-cn.readthedocs.io/zh/latest/torchvision/torchvision-datasets/
root指定了数据集存放的路径,transform指定导入数据集时需要进行何种变换操作,train设置为True说明导入的是训练集合,否则为测试集合。
# use MNIST provided by torchvision
# torchvision.datasets provide MNIST dataset for classification
train_dataset = torchvision.datasets.MNIST(root='./data/MNIST/',
train=True,
transform=train_transform,
download=False)
test_dataset = torchvision.datasets.MNIST(root='./data/MNIST/',
train=False,
transform=test_transform,
download=False)
# pay attention to this, train_dataset doesn't load any data
# It just defined some method and store some message to preprocess data
train_dataset
Dataset MNIST
Number of datapoints: 60000
Split: train
Root Location: ./data/MNIST/
Transforms (if any): Compose(
ToTensor()
Normalize(mean=(0.1307,), std=(0.3081,))
)
Target Transforms (if any): None
PyTorch中数据读取的一个重要接口是torch.utils.data.DataLoader,该接口定义在dataloader.py脚本中,只要是用PyTorch来训练模型基本都会用到该接口,该接口主要用来将自定义的数据读取接口的输出或者PyTorch已有的数据读取接口的输入按照batch size封装成Tensor,后续只需要再包装成Variable即可作为模型的输入。
__init__中的几个重要的输入:
- dataset,这个就是PyTorch已有的数据读取接口(比如torchvision.datasets.ImageFolder)或者自定义的数据接口的输出,该输出要么是torch.utils.data.Dataset类的对象,要么是继承自torch.utils.data.Dataset类的自定义类的对象。
- batch_size,根据具体情况设置即可。
- shuffle,一般在训练数据中会采用。
- collate_fn,是用来处理不同情况下的输入dataset的封装,一般采用默认即可,除非你自定义的数据读取输出非常少见。
- batch_sampler,从注释可以看出,其和batch_size、shuffle等参数是互斥的,一般采用默认。
- sampler,从代码可以看出,其和shuffle是互斥的,一般默认即可。
- num_workers,从注释可以看出这个参数必须大于等于0,0的话表示数据导入在主进程中进行,其他大于0的数表示通过多个进程来导入数据,可以加快数据导入速度。
- pin_memory,注释写得很清楚了: pin_memory (bool, optional): If True, the data loader will copy tensors into CUDA pinned memory before returning them. 也就是一个数据拷贝的问题。
- timeout,是用来设置数据读取的超时时间的,但超过这个时间还没读取到数据的话就会报错。
# Data loader.
# Combines a dataset and a sampler,
# and provides single- or multi-process iterators over the dataset.
train_loader = torch.utils.data.DataLoader(dataset=train_dataset,
batch_size=batch_size,
shuffle=False)
test_loader = torch.utils.data.DataLoader(dataset=test_dataset,
batch_size=batch_size,
shuffle=False)
# functions to show an image
def imshow(img):
"""show some imgs in datasets
!!YOU CAN READ THIS CODE LATER!! """
npimg = img.numpy() # convert tensor to numpy
plt.imshow(np.transpose(npimg, (1, 2, 0))) # [channel, height, width] -> [height, width, channel]
plt.show()
make_grid的作用是将若干幅图像拼成一幅图像。其中padding的作用就是子图像与子图像之间的pad有多宽。
使用:torchvision.utils.make_grid(tensor, nrow=8, padding=2, normalize=False, range=None, scale_each=False, pad_value=0)
tensor (Tensor or list) – 4D mini-batch Tensor of shape (B x C x H x W) or a list of images all of the same size.
nrow (int, optional) – Number of images displayed in each row of the grid. The Final grid size is (B / nrow, nrow). Default is 8.
padding (int, optional) – amount of padding. Default is 2.
normalize (bool, optional) – If True, shift the image to the range (0, 1), by subtracting the minimum and dividing by the maximum pixel value.
range (tuple, optional) – tuple (min, max) where min and max are numbers, then these numbers are used to normalize the image. By default, min and max are computed from the tensor.
scale_each (bool, optional) – If True, scale each image in the batch of images separately rather than the (min, max) over all images.
pad_value (float, optional) – Value for the padded pixels.
# get some random training images by batch
dataiter = iter(train_loader)
images, labels = dataiter.next() # get a batch of images
# show images
print(images.shape)
print(labels)
print(torchvision.utils.make_grid(images).shape)
imshow(torchvision.utils.make_grid(images))
torch.Size([128, 1, 28, 28])
tensor([5, 0, 4, 1, 9, 2, 1, 3, 1, 4, 3, 5, 3, 6, 1, 7, 2, 8, 6, 9, 4, 0, 9, 1,
1, 2, 4, 3, 2, 7, 3, 8, 6, 9, 0, 5, 6, 0, 7, 6, 1, 8, 7, 9, 3, 9, 8, 5,
9, 3, 3, 0, 7, 4, 9, 8, 0, 9, 4, 1, 4, 4, 6, 0, 4, 5, 6, 1, 0, 0, 1, 7,
1, 6, 3, 0, 2, 1, 1, 7, 9, 0, 2, 6, 7, 8, 3, 9, 0, 4, 6, 7, 4, 6, 8, 0,
7, 8, 3, 1, 5, 7, 1, 7, 1, 1, 6, 3, 0, 2, 9, 3, 1, 1, 0, 4, 9, 2, 0, 0,
2, 0, 2, 7, 1, 8, 6, 4])
torch.Size([3, 482, 242])
Clipping input data to the valid range for imshow with RGB data ([0..1] for floats or [0..255] for integers).

上面的图片恰好是16*8的大小,8是nrow的默认值,128是batch_size
通常通过 module.train() 和 module.eval() 来切换模型的训练测试阶段。train的基本单位是epoch。
def train(train_loader, model, loss_fn, optimizer, get_grad=False):
"""train model using loss_fn and optimizer. When thid function is called, model trains for one epoch.
Args:
train_loader: train data
model: prediction model
loss_fn: loss function to judge the distance between target and outputs
optimizer: optimize the loss function
get_grad: True, False
Returns:
total_loss: loss
average_grad2: average grad for hidden 2 in this epoch
average_grad3: average grad for hidden 3 in this epoch
"""
# set the module in training model, affecting module e.g., Dropout, BatchNorm, etc.
model.train()
total_loss = 0
grad_2 = 0.0 # store sum(grad) for hidden 3 layer
grad_3 = 0.0 # store sum(grad) for hidden 3 layer
for batch_idx, (data, target) in enumerate(train_loader):
optimizer.zero_grad() # clear gradients of all optimized torch.Tensors'
outputs = model(data) # make predictions
loss = loss_fn(outputs, target) # compute loss
total_loss += loss.item() # accumulate every batch loss in a epoch
loss.backward() # compute gradient of loss over parameters
if get_grad == True:
g2, g3 = model.get_grad() # get grad for hiddern 2 and 3 layer in this batch
grad_2 += g2 # accumulate grad for hidden 2
grad_3 += g3 # accumulate grad for hidden 2
optimizer.step() # update parameters with gradient descent
average_loss = total_loss / batch_idx # average loss in this epoch
average_grad2 = grad_2 / batch_idx # average grad for hidden 2 in this epoch
average_grad3 = grad_3 / batch_idx # average grad for hidden 3 in this epoch
return average_loss, average_grad2, average_grad3
model.eval(),让model变成测试模式,此时pytorch会自动把BN和DropOut固定住,不会取平均,而是用训练好的值。不然的话,一旦test的batch_size过小,很容易就会被BN层导致生成图片颜色失真极大。
def evaluate(loader, model, loss_fn):
"""test model's prediction performance on loader.
When thid function is called, model is evaluated.
Args:
loader: data for evaluation
model: prediction model
loss_fn: loss function to judge the distance between target and outputs
Returns:
total_loss
accuracy
"""
# context-manager that disabled gradient computation
with torch.no_grad():
# set the module in evaluation mode
model.eval()
correct = 0.0 # account correct amount of data
total_loss = 0 # account loss
for batch_idx, (data, target) in enumerate(loader):
outputs = model(data) # make predictions
# return the maximum value of each row of the input tensor in the
# given dimension dim, the second return vale is the index location
# of each maxium value found(argmax)
_, predicted = torch.max(outputs, 1)
# Detach: Returns a new Tensor, detached from the current graph.
#The result will never require gradient.
correct += (predicted == target).sum().detach().numpy()
loss = loss_fn(outputs, target) # compute loss
total_loss += loss.item() # accumulate every batch loss in a epoch
accuracy = correct*100.0 / len(loader.dataset) # accuracy in a epoch
return total_loss, accuracy
fit函数训练多轮epoch完成整个的训练过程
def fit(train_loader, val_loader, model, loss_fn, optimizer, n_epochs, get_grad=False):
"""train and val model here, we use train_epoch to train model and
val_epoch to val model prediction performance
Args:
train_loader: train data
val_loader: validation data
model: prediction model
loss_fn: loss function to judge the distance between target and outputs
optimizer: optimize the loss function
n_epochs: training epochs
get_grad: Whether to get grad of hidden2 layer and hidden3 layer
Returns:
train_accs: accuracy of train n_epochs, a list
train_losses: loss of n_epochs, a list
"""
grad_2 = [] # save grad for hidden 2 every epoch
grad_3 = [] # save grad for hidden 3 every epoch
train_accs = [] # save train accuracy every epoch
train_losses = [] # save train loss every epoch
for epoch in range(n_epochs): # train for n_epochs
# train model on training datasets, optimize loss function and update model parameters
train_loss, average_grad2, average_grad3 = train(train_loader, model, loss_fn, optimizer, get_grad)
# evaluate model performance on train dataset
_, train_accuracy = evaluate(train_loader, model, loss_fn)
message = 'Epoch: {}/{}. Train set: Average loss: {:.4f}, Accuracy: {:.4f}'.format(epoch+1, \
n_epochs, train_loss, train_accuracy)
print(message)
# save loss, accuracy, grad
train_accs.append(train_accuracy)
train_losses.append(train_loss)
grad_2.append(average_grad2)
grad_3.append(average_grad3)
# evaluate model performance on val dataset
val_loss, val_accuracy = evaluate(val_loader, model, loss_fn)
message = 'Epoch: {}/{}. Validation set: Average loss: {:.4f}, Accuracy: {:.4f}'.format(epoch+1, \
n_epochs, val_loss, val_accuracy)
print(message)
# Whether to get grad for showing
if get_grad == True:
fig, ax = plt.subplots() # add a set of subplots to this figure
ax.plot(grad_2, label='Gradient for Hidden 2 Layer') # plot grad 2
ax.plot(grad_3, label='Gradient for Hidden 3 Layer') # plot grad 3
plt.ylim(top=0.004)
# place a legend on axes
legend = ax.legend(loc='best', shadow=True, fontsize='x-large')
return train_accs, train_losses
def show_curve(ys, title):
"""plot curlve for Loss and Accuacy
!!YOU CAN READ THIS LATER, if you are interested
Args:
ys: loss or acc list
title: Loss or Accuracy
"""
x = np.array(range(len(ys)))
y = np.array(ys)
plt.plot(x, y, c='b')
plt.axis()
plt.title('{} Curve:'.format(title))
plt.xlabel('Epoch')
plt.ylabel('{} Value'.format(title))
plt.show()
正式训练
### Hyper parameters
batch_size = 128 # batch size is 128
n_epochs = 5 # train for 5 epochs
learning_rate = 0.01 # learning rate is 0.01
input_size = 28*28 # input image has size 28x28
hidden_size = 100 # hidden neurons is 100 for each layer
output_size = 10 # classes of prediction
l2_norm = 0 # not to use l2 penalty
dropout = False # not to use
get_grad = False # not to obtain grad
# declare a model
model = FeedForwardNeuralNetwork(input_size=input_size, hidden_size=hidden_size, output_size=output_size)
# Cross entropy
loss_fn = torch.nn.CrossEntropyLoss()
# l2_norm can be done in SGD
optimizer = torch.optim.SGD(model.parameters(), lr=learning_rate, weight_decay=l2_norm)
train_accs, train_losses = fit(train_loader, test_loader, model, loss_fn, optimizer, n_epochs, get_grad)
Epoch: 1/5. Train set: Average loss: 1.8444, Accuracy: 76.8783
Epoch: 1/5. Validation set: Average loss: 69.3857, Accuracy: 77.4200
Epoch: 2/5. Train set: Average loss: 0.5882, Accuracy: 87.0650
Epoch: 2/5. Validation set: Average loss: 33.3306, Accuracy: 87.5500
Epoch: 3/5. Train set: Average loss: 0.3835, Accuracy: 89.4333
Epoch: 3/5. Validation set: Average loss: 26.6955, Accuracy: 89.6800
Epoch: 4/5. Train set: Average loss: 0.3243, Accuracy: 90.8367
Epoch: 4/5. Validation set: Average loss: 23.5091, Accuracy: 90.9600
Epoch: 5/5. Train set: Average loss: 0.2885, Accuracy: 91.8267
Epoch: 5/5. Validation set: Average loss: 21.1413, Accuracy: 91.9300
show_curve(train_accs, "Accu")
show_curve(train_losses, "Loss")


并未出现过拟合现象,因为验证集的准确率一直在上升,损失函数值一直在下降,与训练集的变化趋势保持一致。
Ans: 并未出现过拟合现象,因为验证集的准确率一直在上升,损失函数值一直在下降,与训练集的变化趋势保持一致。另外一方面,将学习率调整到原来的十倍之后,由于学习速度大大加快,产生了过拟合的现象,第六轮Epoch之后模型在验证集上的准确率有所下降,小于epoch5的水平。
保存训练好的模型参数
打印模型参数
# show parameters in model
# Print model's state_dict
print("Model's state_dict:")
for param_tensor in model.state_dict():
print(param_tensor, "\t", model.state_dict()[param_tensor].size())
# Print optimizer's state_dict
print("\nOptimizer's state_dict:")
for var_name in optimizer.state_dict():
print(var_name, "\t", optimizer.state_dict()[var_name])
Model's state_dict:
hidden1.weight torch.Size([100, 784])
hidden1.bias torch.Size([100])
hidden2.weight torch.Size([100, 100])
hidden2.bias torch.Size([100])
hidden3.weight torch.Size([100, 100])
hidden3.bias torch.Size([100])
classification_layer.weight torch.Size([10, 100])
classification_layer.bias torch.Size([10])
hidden1_bn.weight torch.Size([100])
hidden1_bn.bias torch.Size([100])
hidden1_bn.running_mean torch.Size([100])
hidden1_bn.running_var torch.Size([100])
hidden1_bn.num_batches_tracked torch.Size([])
hidden2_bn.weight torch.Size([100])
hidden2_bn.bias torch.Size([100])
hidden2_bn.running_mean torch.Size([100])
hidden2_bn.running_var torch.Size([100])
hidden2_bn.num_batches_tracked torch.Size([])
hidden3_bn.weight torch.Size([100])
hidden3_bn.bias torch.Size([100])
hidden3_bn.running_mean torch.Size([100])
hidden3_bn.running_var torch.Size([100])
hidden3_bn.num_batches_tracked torch.Size([])
Optimizer's state_dict:
state {}
param_groups [{'lr': 0.01, 'momentum': 0, 'dampening': 0, 'weight_decay': 0, 'nesterov': False, 'params': [2361592445112, 2361592446120, 2361592445184, 2361595752312, 2361596540464, 2361596526808, 2361596528032, 2361596528320, 2361590420680, 2361590421328, 2361590420320, 2361590421544, 2361590420104, 2361590421040]}]
将参数保存在本地
# save model
save_path = './model.pt'
torch.save(model.state_dict(), save_path)
加载模型参数
# load parameters from files
saved_parametes = torch.load(save_path)
print(saved_parametes)
# initailze model by saved parameters
new_model = FeedForwardNeuralNetwork(input_size, hidden_size, output_size)
new_model.load_state_dict(saved_parametes)
观察l2_norm对结果的影响
we could minimize the regularization term below by use w e i g h t _ d e c a y weight\_decay weight_decay in SGD optimizer
\begin{equation}
L_norm = {\sum_{i=1}{m}{\theta_{i}{2}}}
\end{equation}
使用l2_norm=0.01训练模型
### Hyper parameters
batch_size = 128
n_epochs = 5
learning_rate = 0.01
input_size = 28*28
hidden_size = 100
output_size = 10
l2_norm = 0.01 # use l2 penalty
get_grad = False
# declare a model
model = FeedForwardNeuralNetwork(input_size=input_size, hidden_size=hidden_size, output_size=output_size)
# Cross entropy
loss_fn = torch.nn.CrossEntropyLoss()
# l2_norm can be done in SGD
optimizer = torch.optim.SGD(model.parameters(), lr=learning_rate, weight_decay=l2_norm)
train_accs, train_losses = fit(train_loader, test_loader, model, loss_fn, optimizer, n_epochs, get_grad)
Epoch: 1/5. Train set: Average loss: 1.9078, Accuracy: 72.7167
Epoch: 1/5. Validation set: Average loss: 78.3702, Accuracy: 72.9900
Epoch: 2/5. Train set: Average loss: 0.6579, Accuracy: 86.0950
Epoch: 2/5. Validation set: Average loss: 36.8969, Accuracy: 86.3800
Epoch: 3/5. Train set: Average loss: 0.4124, Accuracy: 89.0433
Epoch: 3/5. Validation set: Average loss: 28.6882, Accuracy: 89.3300
Epoch: 4/5. Train set: Average loss: 0.3507, Accuracy: 90.2167
Epoch: 4/5. Validation set: Average loss: 25.6519, Accuracy: 90.4100
Epoch: 5/5. Train set: Average loss: 0.3207, Accuracy: 90.9800
Epoch: 5/5. Validation set: Average loss: 23.7643, Accuracy: 91.3100
使用 l2_norm = 1, 训练模型
### Hyper parameters
batch_size = 128
n_epochs = 5
learning_rate = 0.01
input_size = 28*28
hidden_size = 100
output_size = 10
l2_norm = 1 # use l2 penalty
get_grad = False
# declare a model
model = FeedForwardNeuralNetwork(input_size=input_size, hidden_size=hidden_size, output_size=output_size)
# Cross entropy
loss_fn = torch.nn.CrossEntropyLoss()
# l2_norm can be done in SGD
optimizer = torch.optim.SGD(model.parameters(), lr=learning_rate, weight_decay=l2_norm)
train_accs, train_losses = fit(train_loader, test_loader, model, loss_fn, optimizer, n_epochs, get_grad)
Epoch: 1/5. Train set: Average loss: 2.3069, Accuracy: 11.2367
Epoch: 1/5. Validation set: Average loss: 181.8871, Accuracy: 11.3500
Epoch: 2/5. Train set: Average loss: 2.3073, Accuracy: 11.2367
Epoch: 2/5. Validation set: Average loss: 181.8870, Accuracy: 11.3500
Epoch: 3/5. Train set: Average loss: 2.3073, Accuracy: 11.2367
Epoch: 3/5. Validation set: Average loss: 181.8871, Accuracy: 11.3500
Epoch: 4/5. Train set: Average loss: 2.3073, Accuracy: 11.2367
Epoch: 4/5. Validation set: Average loss: 181.8871, Accuracy: 11.3500
Epoch: 5/5. Train set: Average loss: 2.3073, Accuracy: 11.2367
Epoch: 5/5. Validation set: Average loss: 181.8871, Accuracy: 11.3500
从结果中可以看出,将l2_norm调整为1之后准确率大幅下降,说明正则化的权重过大,导致模型对于减少特征的数量发展出了强烈的偏好,使得从特征中可利用的特征和信息数减少,模型的预测能力下降。
观察dropout对结果的影响
During training, randomly zeroes some of the elements of the input tensor with probability p using samples from a Bernoulli distribution.
Each channel will be zeroed out independently on every forward call.
### Hyper parameters
batch_size = 128
n_epochs = 5
learning_rate = 0.01
input_size = 28*28
hidden_size = 100
output_size = 10
l2_norm = 0 # without using l2 penalty
get_grad = False
# declare a model
model = FeedForwardNeuralNetwork(input_size=input_size, hidden_size=hidden_size, output_size=output_size)
# Cross entropy
loss_fn = torch.nn.CrossEntropyLoss()
# l2_norm can be done in SGD
optimizer = torch.optim.SGD(model.parameters(), lr=learning_rate, weight_decay=l2_norm)
# Set dropout to True and probability = 0.5
model.set_use_dropout(True)
train_accs, train_losses = fit(train_loader, test_loader, model, loss_fn, optimizer, n_epochs, get_grad)
Epoch: 1/5. Train set: Average loss: 2.0297, Accuracy: 74.1700
Epoch: 1/5. Validation set: Average loss: 89.8412, Accuracy: 74.3100
Epoch: 2/5. Train set: Average loss: 0.8378, Accuracy: 86.6600
Epoch: 2/5. Validation set: Average loss: 36.5149, Accuracy: 87.0900
Epoch: 3/5. Train set: Average loss: 0.5397, Accuracy: 88.9917
Epoch: 3/5. Validation set: Average loss: 28.3120, Accuracy: 89.1800
Epoch: 4/5. Train set: Average loss: 0.4486, Accuracy: 90.5850
Epoch: 4/5. Validation set: Average loss: 24.2983, Accuracy: 90.5500
Epoch: 5/5. Train set: Average loss: 0.3940, Accuracy: 91.5483
Epoch: 5/5. Validation set: Average loss: 21.7570, Accuracy: 91.4200
观察batch_normalization对结果的影响
Batch normalization is a technique for improving the performance and stability of artificial neural networks
\begin{equation}
y=\frac{x-E[x]}{\sqrt{Var[x]+\epsilon}} * \gamma + \beta,
\end{equation}
γ \gamma γ and β \beta β are learnable parameters
### Hyper parameters
batch_size = 128
n_epochs = 5
learning_rate = 0.01
input_size = 28*28
hidden_size = 100
output_size = 10
l2_norm = 0 # without using l2 penalty
get_grad = False
# declare a model
model = FeedForwardNeuralNetwork(input_size=input_size, hidden_size=hidden_size, output_size=output_size)
# Cross entropy
loss_fn = torch.nn.CrossEntropyLoss()
# l2_norm can be done in SGD
optimizer = torch.optim.SGD(model.parameters(), lr=learning_rate, weight_decay=l2_norm)
model.set_use_bn(True)
model.use_bn
True
train_accs, train_losses = fit(train_loader, test_loader, model, loss_fn, optimizer, n_epochs, get_grad)
Epoch: 1/5. Train set: Average loss: 1.0543, Accuracy: 91.7083
Epoch: 1/5. Validation set: Average loss: 35.6068, Accuracy: 92.0500
Epoch: 2/5. Train set: Average loss: 0.3326, Accuracy: 94.5767
Epoch: 2/5. Validation set: Average loss: 19.0148, Accuracy: 94.4000
Epoch: 3/5. Train set: Average loss: 0.2085, Accuracy: 95.9867
Epoch: 3/5. Validation set: Average loss: 13.7753, Accuracy: 95.5100
Epoch: 4/5. Train set: Average loss: 0.1552, Accuracy: 96.8933
Epoch: 4/5. Validation set: Average loss: 11.2369, Accuracy: 96.2400
Epoch: 5/5. Train set: Average loss: 0.1243, Accuracy: 97.4067
Epoch: 5/5. Validation set: Average loss: 9.7330, Accuracy: 96.5500
观察数据增广对结果的影响
- torchvision.transforms.RandomHorizontalFlip:随机水平翻转给定的PIL.Image,概率为0.5。即:一半的概率翻转,一半的概率不翻转。
- class torchvision.transforms.RandomCrop(size, padding=0),随机裁剪,size可以是tuple也可以是Integer。
详见 https://pytorch-cn.readthedocs.io/zh/latest/torchvision/torchvision-transform/
# only add random horizontal flip
train_transform_1 = transforms.Compose([
transforms.RandomHorizontalFlip(),
transforms.ToTensor(), # Convert a PIL Image or numpy.ndarray to tensor.
# Normalize a tensor image with mean and standard deviation
transforms.Normalize((0.1307,), (0.3081,))
])
# only add random crop
train_transform_2 = transforms.Compose([
transforms.RandomCrop(size=[32,32], padding=4),
transforms.ToTensor(), # Convert a PIL Image or numpy.ndarray to tensor.
# Normalize a tensor image with mean and standard deviation
transforms.Normalize((0.1307,), (0.3081,))
])
# add random horizontal flip and random crop
train_transform_3 = transforms.Compose([
transforms.RandomHorizontalFlip(),
transforms.RandomCrop(size=[32,32], padding=4),
transforms.ToTensor(), # Convert a PIL Image or numpy.ndarray to tensor.
# Normalize a tensor image with mean and standard deviation
transforms.Normalize((0.1307,), (0.3081,))
])
# reload train_loader using trans
train_dataset_1 = torchvision.datasets.MNIST(root='./data',
train=True,
transform=train_transform_1,
download=False)
train_loader_1 = torch.utils.data.DataLoader(dataset=train_dataset_1,
batch_size=batch_size,
shuffle=True)
print(train_dataset_1)
Dataset MNIST
Number of datapoints: 60000
Split: train
Root Location: ./data
Transforms (if any): Compose(
RandomHorizontalFlip(p=0.5)
ToTensor()
Normalize(mean=(0.1307,), std=(0.3081,))
)
Target Transforms (if any): None
### Hyper parameters
batch_size = 128
n_epochs = 5
learning_rate = 0.01
input_size = 28*28
hidden_size = 100
output_size = 10
l2_norm = 0 # without using l2 penalty
get_grad = False
# declare a model
model = FeedForwardNeuralNetwork(input_size=input_size, hidden_size=hidden_size, output_size=output_size)
# Cross entropy
loss_fn = torch.nn.CrossEntropyLoss()
# l2_norm can be done in SGD
optimizer = torch.optim.SGD(model.parameters(), lr=learning_rate, weight_decay=l2_norm)
train_accs, train_losses = fit(train_loader_1, test_loader, model, loss_fn, optimizer, n_epochs, get_grad)
Epoch: 1/5. Train set: Average loss: 2.0279, Accuracy: 68.6250
Epoch: 1/5. Validation set: Average loss: 92.1617, Accuracy: 69.8500
Epoch: 2/5. Train set: Average loss: 0.8009, Accuracy: 79.2333
Epoch: 2/5. Validation set: Average loss: 49.5853, Accuracy: 79.8800
Epoch: 3/5. Train set: Average loss: 0.6014, Accuracy: 82.1367
Epoch: 3/5. Validation set: Average loss: 42.1372, Accuracy: 82.8200
Epoch: 4/5. Train set: Average loss: 0.5312, Accuracy: 83.8583
Epoch: 4/5. Validation set: Average loss: 37.6811, Accuracy: 84.7300
Epoch: 5/5. Train set: Average loss: 0.4776, Accuracy: 85.8750
Epoch: 5/5. Validation set: Average loss: 33.9977, Accuracy: 86.6100
# reload train_loader using trans
test_transform = transforms.Compose([
transforms.RandomCrop(size=[32,32], padding=4),
transforms.ToTensor(),
transforms.Normalize((0.1307,), (0.3081,))
])
test_dataset = torchvision.datasets.MNIST(root='./data/MNIST/',
train=False,
transform=test_transform,
download=False)
test_loader = torch.utils.data.DataLoader(dataset=test_dataset,
batch_size=batch_size,
shuffle=False)
train_dataset_2 = torchvision.datasets.MNIST(root='./data',
train=True,
transform=train_transform_2,
download=False)
train_loader_2 = torch.utils.data.DataLoader(dataset=train_dataset_2,
batch_size=batch_size,
shuffle=True)
### Hyper parameters
batch_size = 128
n_epochs = 5
learning_rate = 0.01
input_size = 32*32
hidden_size = 100
output_size = 10
l2_norm = 0 # without using l2 penalty
get_grad = False
# declare a model
model = FeedForwardNeuralNetwork(input_size=input_size, hidden_size=hidden_size, output_size=output_size)
# Cross entropy
loss_fn = torch.nn.CrossEntropyLoss()
# l2_norm can be done in SGD
optimizer = torch.optim.SGD(model.parameters(), lr=learning_rate, weight_decay=l2_norm)
train_accs, train_losses = fit(train_loader_2, test_loader, model, loss_fn, optimizer, n_epochs, get_grad)
Epoch: 1/5. Train set: Average loss: 2.1805, Accuracy: 46.8083
Epoch: 1/5. Validation set: Average loss: 143.3776, Accuracy: 47.1100
Epoch: 2/5. Train set: Average loss: 1.2855, Accuracy: 68.1933
Epoch: 2/5. Validation set: Average loss: 77.3718, Accuracy: 68.7600
Epoch: 3/5. Train set: Average loss: 0.8984, Accuracy: 75.2133
Epoch: 3/5. Validation set: Average loss: 60.4608, Accuracy: 76.2300
Epoch: 4/5. Train set: Average loss: 0.7193, Accuracy: 81.0950
Epoch: 4/5. Validation set: Average loss: 49.5156, Accuracy: 81.4100
Epoch: 5/5. Train set: Average loss: 0.5722, Accuracy: 85.3317
Epoch: 5/5. Validation set: Average loss: 38.4313, Accuracy: 85.7600
# reload train_loader using trans
train_dataset_3 = torchvision.datasets.MNIST(root='./data',
train=True,
transform=train_transform_3,
download=False)
train_loader_3 = torch.utils.data.DataLoader(dataset=train_dataset_3,
batch_size=batch_size,
shuffle=True)
### Hyper parameters
batch_size = 128
n_epochs = 5
learning_rate = 0.01
input_size = 32*32
hidden_size = 100
output_size = 10
l2_norm = 0 # without using l2 penalty
get_grad = False
# declare a model
model = FeedForwardNeuralNetwork(input_size=input_size, hidden_size=hidden_size, output_size=output_size)
# Cross entropy
loss_fn = torch.nn.CrossEntropyLoss()
# l2_norm can be done in SGD
optimizer = torch.optim.SGD(model.parameters(), lr=learning_rate, weight_decay=l2_norm)
train_accs, train_losses = fit(train_loader_3, test_loader, model, loss_fn, optimizer, n_epochs, get_grad)
Epoch: 1/5. Train set: Average loss: 2.2192, Accuracy: 36.5367
Epoch: 1/5. Validation set: Average loss: 153.8687, Accuracy: 36.2300
Epoch: 2/5. Train set: Average loss: 1.4885, Accuracy: 59.1383
Epoch: 2/5. Validation set: Average loss: 93.1653, Accuracy: 60.1300
Epoch: 3/5. Train set: Average loss: 1.1089, Accuracy: 65.2250
Epoch: 3/5. Validation set: Average loss: 79.0645, Accuracy: 66.8100
Epoch: 4/5. Train set: Average loss: 0.9566, Accuracy: 70.8733
Epoch: 4/5. Validation set: Average loss: 68.2114, Accuracy: 71.9500
Epoch: 5/5. Train set: Average loss: 0.8243, Accuracy: 74.8700
Epoch: 5/5. Validation set: Average loss: 58.6696, Accuracy: 76.3400
使用tensorboard进行可视化
示例 教程1 教程2
with SummaryWriter(comment="simplenet") as s:
s.add_graph(model, (images,))
s.close()
接下来进入run文件夹同级的terminal,输入:tensorboard --logdir runs,双击之后可以查看细节的。
检查梯度消失和爆炸问题
正常情况
### Hyper parameters
batch_size = 128
n_epochs = 15
learning_rate = 0.01
input_size = 28*28
hidden_size = 100
output_size = 10
l2_norm = 0 # use l2 penalty
get_grad = True
# declare a model
model = FeedForwardNeuralNetwork(input_size=input_size, hidden_size=hidden_size, output_size=output_size)
# Cross entropy
loss_fn = torch.nn.CrossEntropyLoss()
# l2_norm can be done in SGD
optimizer = torch.optim.SGD(model.parameters(), lr=learning_rate, weight_decay=l2_norm)
fit(train_loader, test_loader, model, loss_fn, optimizer, n_epochs, get_grad)
Epoch: 1/15. Train set: Average loss: 1.8366, Accuracy: 78.8000
Epoch: 1/15. Validation set: Average loss: 63.6212, Accuracy: 79.8800
Epoch: 2/15. Train set: Average loss: 0.5435, Accuracy: 87.6750
Epoch: 2/15. Validation set: Average loss: 31.8640, Accuracy: 88.1300
Epoch: 3/15. Train set: Average loss: 0.3700, Accuracy: 89.9000
Epoch: 3/15. Validation set: Average loss: 26.0366, Accuracy: 90.0600
Epoch: 4/15. Train set: Average loss: 0.3155, Accuracy: 91.2067
Epoch: 4/15. Validation set: Average loss: 23.0006, Accuracy: 91.3300
Epoch: 5/15. Train set: Average loss: 0.2810, Accuracy: 92.1017
Epoch: 5/15. Validation set: Average loss: 20.7663, Accuracy: 92.1800
Epoch: 6/15. Train set: Average loss: 0.2538, Accuracy: 92.8850
Epoch: 6/15. Validation set: Average loss: 18.9108, Accuracy: 92.9700
Epoch: 7/15. Train set: Average loss: 0.2308, Accuracy: 93.5200
Epoch: 7/15. Validation set: Average loss: 17.3296, Accuracy: 93.5200
Epoch: 8/15. Train set: Average loss: 0.2110, Accuracy: 94.0817
Epoch: 8/15. Validation set: Average loss: 16.0059, Accuracy: 93.9200
Epoch: 9/15. Train set: Average loss: 0.1941, Accuracy: 94.5667
Epoch: 9/15. Validation set: Average loss: 14.8797, Accuracy: 94.2600
Epoch: 10/15. Train set: Average loss: 0.1795, Accuracy: 94.9167
Epoch: 10/15. Validation set: Average loss: 13.9058, Accuracy: 94.7200
Epoch: 11/15. Train set: Average loss: 0.1670, Accuracy: 95.3200
Epoch: 11/15. Validation set: Average loss: 13.0572, Accuracy: 95.1200
Epoch: 12/15. Train set: Average loss: 0.1561, Accuracy: 95.6383
Epoch: 12/15. Validation set: Average loss: 12.3507, Accuracy: 95.4000
Epoch: 13/15. Train set: Average loss: 0.1465, Accuracy: 95.9200
Epoch: 13/15. Validation set: Average loss: 11.7505, Accuracy: 95.5900
Epoch: 14/15. Train set: Average loss: 0.1381, Accuracy: 96.1933
Epoch: 14/15. Validation set: Average loss: 11.2232, Accuracy: 95.7700
Epoch: 15/15. Train set: Average loss: 0.1305, Accuracy: 96.3700
Epoch: 15/15. Validation set: Average loss: 10.7843, Accuracy: 95.9200
([78.8,
87.675,
89.9,
91.20666666666666,
92.10166666666667,
92.885,
93.52,
94.08166666666666,
94.56666666666666,
94.91666666666667,
95.32,
95.63833333333334,
95.92,
96.19333333333333,
96.37],
[1.8365707892892706,
0.5434680474269339,
0.36995476882299805,
0.31546069086234796,
0.2810159547604684,
0.25381433282397753,
0.23079734468339091,
0.2109861063540109,
0.19405433198866937,
0.17953249415717062,
0.1669697950506567,
0.15606886974703044,
0.14652140330300373,
0.13807939636544922,
0.1305215704676687])
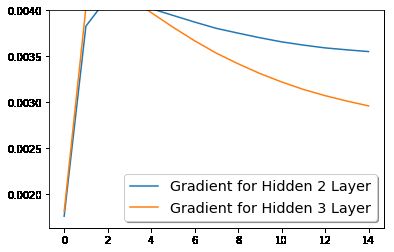
梯度消失(学习率超小)
### Hyper parameters
batch_size = 128
n_epochs = 15
learning_rate = 1e-20
input_size = 28*28
hidden_size = 100
output_size = 10
l2_norm = 0 # use l2 penalty
get_grad = True
# declare a model
model = FeedForwardNeuralNetwork(input_size=input_size, hidden_size=hidden_size, output_size=output_size)
# Cross entropy
loss_fn = torch.nn.CrossEntropyLoss()
# l2_norm can be done in SGD
optimizer = torch.optim.SGD(model.parameters(), lr=learning_rate, weight_decay=l2_norm)
fit(train_loader, test_loader, model, loss_fn, optimizer, n_epochs, get_grad=get_grad)
Epoch: 1/15. Train set: Average loss: 2.3062, Accuracy: 9.9650
Epoch: 1/15. Validation set: Average loss: 181.8200, Accuracy: 9.6200
Epoch: 2/15. Train set: Average loss: 2.3062, Accuracy: 9.9650
Epoch: 2/15. Validation set: Average loss: 181.8200, Accuracy: 9.6200
Epoch: 3/15. Train set: Average loss: 2.3062, Accuracy: 9.9650
Epoch: 3/15. Validation set: Average loss: 181.8200, Accuracy: 9.6200
Epoch: 4/15. Train set: Average loss: 2.3062, Accuracy: 9.9650
Epoch: 4/15. Validation set: Average loss: 181.8200, Accuracy: 9.6200
Epoch: 5/15. Train set: Average loss: 2.3062, Accuracy: 9.9650
Epoch: 5/15. Validation set: Average loss: 181.8200, Accuracy: 9.6200
Epoch: 6/15. Train set: Average loss: 2.3062, Accuracy: 9.9650
Epoch: 6/15. Validation set: Average loss: 181.8200, Accuracy: 9.6200
Epoch: 7/15. Train set: Average loss: 2.3062, Accuracy: 9.9650
Epoch: 7/15. Validation set: Average loss: 181.8200, Accuracy: 9.6200
Epoch: 8/15. Train set: Average loss: 2.3062, Accuracy: 9.9650
Epoch: 8/15. Validation set: Average loss: 181.8200, Accuracy: 9.6200
Epoch: 9/15. Train set: Average loss: 2.3062, Accuracy: 9.9650
Epoch: 9/15. Validation set: Average loss: 181.8200, Accuracy: 9.6200
Epoch: 10/15. Train set: Average loss: 2.3062, Accuracy: 9.9650
Epoch: 10/15. Validation set: Average loss: 181.8200, Accuracy: 9.6200
Epoch: 11/15. Train set: Average loss: 2.3062, Accuracy: 9.9650
Epoch: 11/15. Validation set: Average loss: 181.8200, Accuracy: 9.6200
Epoch: 12/15. Train set: Average loss: 2.3062, Accuracy: 9.9650
Epoch: 12/15. Validation set: Average loss: 181.8200, Accuracy: 9.6200
Epoch: 13/15. Train set: Average loss: 2.3062, Accuracy: 9.9650
Epoch: 13/15. Validation set: Average loss: 181.8200, Accuracy: 9.6200
Epoch: 14/15. Train set: Average loss: 2.3062, Accuracy: 9.9650
Epoch: 14/15. Validation set: Average loss: 181.8200, Accuracy: 9.6200
Epoch: 15/15. Train set: Average loss: 2.3062, Accuracy: 9.9650
Epoch: 15/15. Validation set: Average loss: 181.8200, Accuracy: 9.6200
([9.965,
9.965,
9.965,
9.965,
9.965,
9.965,
9.965,
9.965,
9.965,
9.965,
9.965,
9.965,
9.965,
9.965,
9.965],
[2.3061594305894313,
2.3061594305894313,
2.3061594305894313,
2.3061594305894313,
2.3061594305894313,
2.3061594305894313,
2.3061594305894313,
2.3061594305894313,
2.3061594305894313,
2.3061594305894313,
2.3061594305894313,
2.3061594305894313,
2.3061594305894313,
2.3061594305894313,
2.3061594305894313])
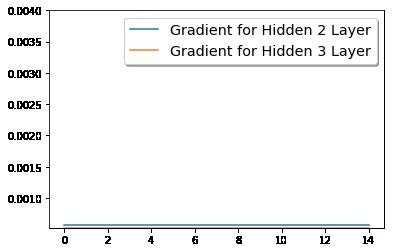
梯度爆炸(学习率很大)
### Hyper parameters
batch_size = 128
n_epochs = 15
learning_rate = 10.168
input_size = 28*28
hidden_size = 100
output_size = 10
l2_norm = 0 # not to use l2 penalty
get_grad = True
# declare a model
model = FeedForwardNeuralNetwork(input_size=input_size, hidden_size=hidden_size, output_size=output_size)
# Cross entropy
loss_fn = torch.nn.CrossEntropyLoss()
# l2_norm can be done in SGD
optimizer = torch.optim.SGD(model.parameters(), lr=learning_rate, weight_decay=l2_norm)
fit(train_loader, test_loader, model, loss_fn, optimizer, n_epochs, get_grad=True)
E:\train\anaconda\envs\torch\lib\site-packages\ipykernel_launcher.py:80: RuntimeWarning: overflow encountered in square
E:\train\anaconda\envs\torch\lib\site-packages\ipykernel_launcher.py:81: RuntimeWarning: overflow encountered in square
Epoch: 1/15. Train set: Average loss: nan, Accuracy: 9.8717
Epoch: 1/15. Validation set: Average loss: nan, Accuracy: 9.8000
Epoch: 2/15. Train set: Average loss: nan, Accuracy: 9.8717
Epoch: 2/15. Validation set: Average loss: nan, Accuracy: 9.8000
Epoch: 3/15. Train set: Average loss: nan, Accuracy: 9.8717
Epoch: 3/15. Validation set: Average loss: nan, Accuracy: 9.8000
Epoch: 4/15. Train set: Average loss: nan, Accuracy: 9.8717
Epoch: 4/15. Validation set: Average loss: nan, Accuracy: 9.8000
Epoch: 5/15. Train set: Average loss: nan, Accuracy: 9.8717
Epoch: 5/15. Validation set: Average loss: nan, Accuracy: 9.8000
Epoch: 6/15. Train set: Average loss: nan, Accuracy: 9.8717
Epoch: 6/15. Validation set: Average loss: nan, Accuracy: 9.8000
Epoch: 7/15. Train set: Average loss: nan, Accuracy: 9.8717
Epoch: 7/15. Validation set: Average loss: nan, Accuracy: 9.8000
Epoch: 8/15. Train set: Average loss: nan, Accuracy: 9.8717
Epoch: 8/15. Validation set: Average loss: nan, Accuracy: 9.8000
Epoch: 9/15. Train set: Average loss: nan, Accuracy: 9.8717
Epoch: 9/15. Validation set: Average loss: nan, Accuracy: 9.8000
Epoch: 10/15. Train set: Average loss: nan, Accuracy: 9.8717
Epoch: 10/15. Validation set: Average loss: nan, Accuracy: 9.8000
Epoch: 11/15. Train set: Average loss: nan, Accuracy: 9.8717
Epoch: 11/15. Validation set: Average loss: nan, Accuracy: 9.8000
Epoch: 12/15. Train set: Average loss: nan, Accuracy: 9.8717
Epoch: 12/15. Validation set: Average loss: nan, Accuracy: 9.8000
Epoch: 13/15. Train set: Average loss: nan, Accuracy: 9.8717
Epoch: 13/15. Validation set: Average loss: nan, Accuracy: 9.8000
Epoch: 14/15. Train set: Average loss: nan, Accuracy: 9.8717
Epoch: 14/15. Validation set: Average loss: nan, Accuracy: 9.8000
Epoch: 15/15. Train set: Average loss: nan, Accuracy: 9.8717
Epoch: 15/15. Validation set: Average loss: nan, Accuracy: 9.8000
([9.871666666666666,
9.871666666666666,
9.871666666666666,
9.871666666666666,
9.871666666666666,
9.871666666666666,
9.871666666666666,
9.871666666666666,
9.871666666666666,
9.871666666666666,
9.871666666666666,
9.871666666666666,
9.871666666666666,
9.871666666666666,
9.871666666666666],
[nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan])
梯度消失:反向传播时,当梯度从后往前传时,梯度不断减小,最后变为零,此时,浅层的神经网络权重得不到更新,这种现象称为“饱和”(saturate),整个网络学习速度非常慢。梯度消失导致后层的权重更新的快,而前层网络由于梯度传递不过去而得不到更新。这样在网络很深的时候,学习的速度很慢或者无法学习。
梯度爆炸:这是一种与梯度消失相反的情况,当进行反向传播时,梯度从后往前传时,梯度不断增大,导致权重更新太大,以致不断波动,使网络在最优点之间波动。
使用模型进行单图像识别
input_data = images[0]
test_img = torchvision.utils.make_grid(input_data)
imshow(test_img)
Clipping input data to the valid range for imshow with RGB data ([0..1] for floats or [0..255] for integers).

output = model(input_data)
output = F.softmax(output, dim=1)
output = output.detach().numpy().tolist()[0]
for label, prob in enumerate(output):
print('预测数字为%d的概率为: %f' % (label, prob))
预测数字为0的概率为: 0.010734
预测数字为1的概率为: 0.000016
预测数字为2的概率为: 0.001222
预测数字为3的概率为: 0.262739
预测数字为4的概率为: 0.000002
预测数字为5的概率为: 0.722390
预测数字为6的概率为: 0.000050
预测数字为7的概率为: 0.001125
预测数字为8的概率为: 0.001215
预测数字为9的概率为: 0.000506