使用Docker搭建Hadoop集群和Spark集群
一、前言
Hadoop是分布式管理、存储、计算的生态系统,Hadoop的框架最核心的设计就是:HDFS和MapReduce,HDFS分布式文件系统(Hadoop Distributed File System)为海量的数据提供了存储,而MapReduce则为海量的数据提供了计算。
Spark是专为大规模数据处理而设计的快速通用的计算引擎,Spark是开源的类Hadoop MapReduce的通用并行框架,Spark拥有Hadoop MapReduce所具有的优点,但不同于MapReduce的是——Job中间输出结果可以保存在内存中,从而不再需要读写HDFS,因此Spark能更好地适用于数据挖掘与机器学习等需要迭代的MapReduce的算法。
二、安装Docker和Docker-compose
参考以前的文章
三、网络
将Hadoop集群和Spark集群装在同一个网络中,以便Spark能访问到Hadoop中的HDFS,可以将计算的结果保存到HDFS的文件中。
# 创建一个名为anron的docker网络
docker network create --subnet 172.20.0.1/16 anron如果提示以下错误信息,那就把172.20.0.1换个网段后再试
Error response from daemon: Pool overlaps with other one on this address space四、Hadoop集群
4.1 集群的组成
hoodoop集群包括有:
- namenode 1个节点
- datanode 2个节点(datanode1,datanode2)
- resourcemanager 1个节点
- nodemanager 1个节点
- historyserver 1个节点
namenode、datanode1、datanode2在hadoop-1.yml文件中
resourcemanager、nodemanager、historyserver在hadoop-2.yml文件中
hadoop.env、hadoop-1.yml、hadoop-2.yml这3个文件放在宿主机的同个目录下
4.2 hadoop.env文件
CORE_CONF_fs_defaultFS=hdfs://namenode:9000
CORE_CONF_hadoop_http_staticuser_user=root
CORE_CONF_hadoop_proxyuser_hue_hosts=*
CORE_CONF_hadoop_proxyuser_hue_groups=*
CORE_CONF_io_compression_codecs=org.apache.hadoop.io.compress.SnappyCodec
HDFS_CONF_dfs_webhdfs_enabled=true
HDFS_CONF_dfs_permissions_enabled=false
HDFS_CONF_dfs_namenode_datanode_registration_ip___hostname___check=false
YARN_CONF_yarn_log___aggregation___enable=true
YARN_CONF_yarn_log_server_url=http://historyserver:8188/applicationhistory/logs/
YARN_CONF_yarn_resourcemanager_recovery_enabled=true
YARN_CONF_yarn_resourcemanager_store_class=org.apache.hadoop.yarn.server.resourcemanager.recovery.FileSystemRMStateStore
YARN_CONF_yarn_resourcemanager_scheduler_class=org.apache.hadoop.yarn.server.resourcemanager.scheduler.capacity.CapacityScheduler
YARN_CONF_yarn_scheduler_capacity_root_default_maximum___allocation___mb=8192
YARN_CONF_yarn_scheduler_capacity_root_default_maximum___allocation___vcores=4
YARN_CONF_yarn_resourcemanager_fs_state___store_uri=/rmstate
YARN_CONF_yarn_resourcemanager_system___metrics___publisher_enabled=true
YARN_CONF_yarn_resourcemanager_hostname=resourcemanager
YARN_CONF_yarn_resourcemanager_address=resourcemanager:8032
YARN_CONF_yarn_resourcemanager_scheduler_address=resourcemanager:8030
YARN_CONF_yarn_resourcemanager_resource__tracker_address=resourcemanager:8031
YARN_CONF_yarn_timeline___service_enabled=true
YARN_CONF_yarn_timeline___service_generic___application___history_enabled=true
YARN_CONF_yarn_timeline___service_hostname=historyserver
YARN_CONF_mapreduce_map_output_compress=true
YARN_CONF_mapred_map_output_compress_codec=org.apache.hadoop.io.compress.SnappyCodec
YARN_CONF_yarn_nodemanager_resource_memory___mb=16384
YARN_CONF_yarn_nodemanager_resource_cpu___vcores=8
YARN_CONF_yarn_nodemanager_disk___health___checker_max___disk___utilization___per___disk___percentage=98.5
YARN_CONF_yarn_nodemanager_remote___app___log___dir=/app-logs
YARN_CONF_yarn_nodemanager_aux___services=mapreduce_shuffle
MAPRED_CONF_mapreduce_framework_name=yarn
MAPRED_CONF_mapred_child_java_opts=-Xmx4096m
MAPRED_CONF_mapreduce_map_memory_mb=4096
MAPRED_CONF_mapreduce_reduce_memory_mb=8192
MAPRED_CONF_mapreduce_map_java_opts=-Xmx3072m
MAPRED_CONF_mapreduce_reduce_java_opts=-Xmx6144m
MAPRED_CONF_yarn_app_mapreduce_am_env=HADOOP_MAPRED_HOME=/opt/hadoop-3.2.1/
MAPRED_CONF_mapreduce_map_env=HADOOP_MAPRED_HOME=/opt/hadoop-3.2.1/
MAPRED_CONF_mapreduce_reduce_env=HADOOP_MAPRED_HOME=/opt/hadoop-3.2.1/4.3 hadoop-1.yml文件
version: '3'
networks:
anron:
external: true
volumes:
hadoop_namenode:
hadoop_datanode1:
hadoop_datanode2:
hadoop_historyserver:
services:
namenode:
container_name: namenode
image: bde2020/hadoop-namenode
ports:
- 9000:9000
- 9870:9870
volumes:
- hadoop_namenode:/hadoop/dfs/name
environment:
- CLUSTER_NAME=test
env_file:
- ./hadoop.env
networks:
- anron
datanode1:
container_name: datanode1
image: bde2020/hadoop-datanode
depends_on:
- namenode
volumes:
- hadoop_datanode1:/hadoop/dfs/data
environment:
SERVICE_PRECONDITION: "namenode:9870"
env_file:
- ./hadoop.env
networks:
- anron
datanode2:
container_name: datanode2
image: bde2020/hadoop-datanode
depends_on:
- namenode
volumes:
- hadoop_datanode2:/hadoop/dfs/data
environment:
SERVICE_PRECONDITION: "namenode:9870"
env_file:
- ./hadoop.env
networks:
- anron4.4 hadoop-2.yml文件
version: '3'
networks:
anron:
external: true
volumes:
hadoop_namenode:
hadoop_datanode1:
hadoop_datanode2:
hadoop_historyserver:
services:
historyserver:
container_name: historyserver
image: bde2020/hadoop-historyserver
ports:
- 8188:8188
volumes:
- hadoop_historyserver:/hadoop/yarn/timeline
environment:
SERVICE_PRECONDITION: "namenode:9000 namenode:9870 datanode1:9864 datanode2:9864 resourcemanager:8088"
env_file:
- ./hadoop.env
networks:
- anron
nodemanager:
container_name: nodemanager
image: bde2020/hadoop-nodemanager
environment:
SERVICE_PRECONDITION: "namenode:9000 namenode:9870 datanode1:9864 datanode2:9864 resourcemanager:8088"
env_file:
- ./hadoop.env
networks:
- anron
resourcemanager:
container_name: resourcemanager
image: bde2020/hadoop-resourcemanager
ports:
- 8088:8088
environment:
SERVICE_PRECONDITION: "namenode:9000 namenode:9870 datanode1:9864 datanode2:9864"
env_file:
- ./hadoop.env
networks:
- anron 4.5 启动Hadoop集群
先启动hadoop-1.yml
docker-compose -f hadoop-1.yml up等namenode容器(或者在WebUI中查看)出现以下信息,提示hdfs的安全模式已经关闭
Safe mode is OFF然后再启动hadoop-2.yml
docker-compose -f hadoop-2.yml up注意:由于resourcemanager在启动的时候需要创建目录/rmstate,SafeMode下是不可以更改文件只能读取,导致resourcemanager无法启动。namenode大概在启动30秒后会自动关闭SafeMode,所有这里把yml文件分成2个,先启动hadoop-1,再启动hadoop-2。
当然也可以手动开启或关闭SafeMode
# 查看safemode
docker exec -it namenode hdfs dfsadmin -safemode get
# 打开safemode
docker exec -it namenode hdfs dfsadmin -safemode enter
# 关闭safemode
docker exec -it namenode hdfs dfsadmin -safemode leave
4.6 查看WebUI
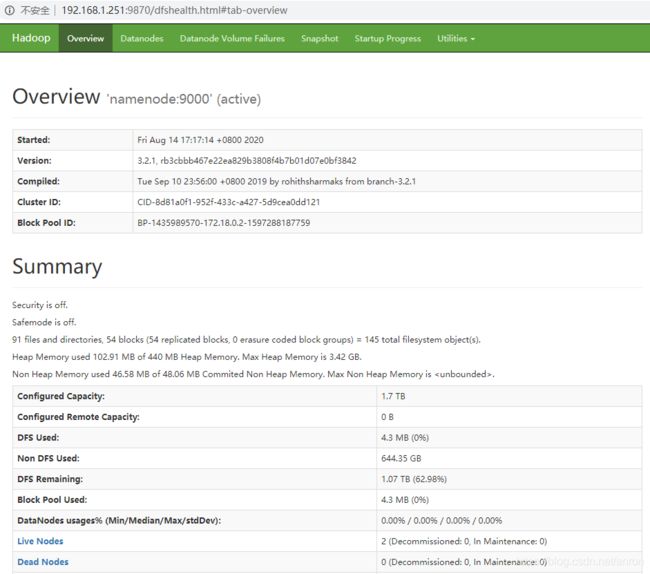
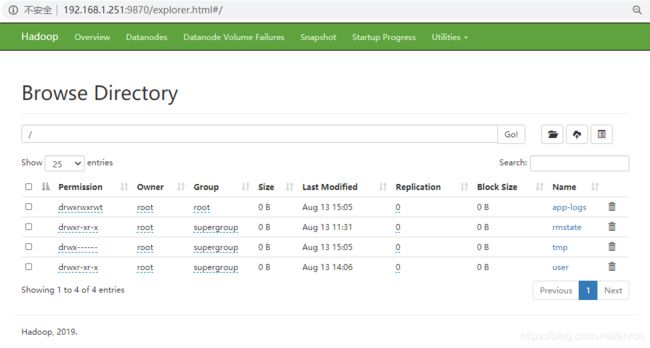
查看HDFS文件系统
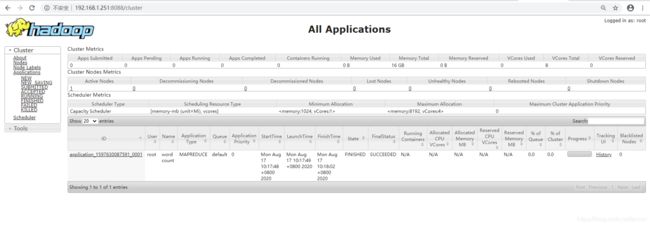
 查看resourcemanager
查看resourcemanager
4.7 运行wordcount例子
# 进入namenode容器
docker exec -it namenode bash
# 在namenode容器里创建目录和2个文件
mkdir input
echo "Hello World" > input/f1.txt
echo "Hello Docker" > input/f2.txt
# 在HDFS创建一个input目录(绝对路径为/user/root/input)
hdfs dfs -mkdir -p input
# 把容器/input目录下的所有文件拷贝到HDFS的input目录,如果HDFS的input目录不存在会报错
hdfs dfs -put /input/* input
# 在容器里运行WordCount程序,该程序需要2个参数:HDFS输入目录和HDFS输出目录(需要先把hadoop-mapreduce-examples-2.7.1-sources.jar从宿主机拷贝到容器里)
hadoop jar hadoop-mapreduce-examples-2.7.1-sources.jar org.apache.hadoop.examples.WordCount input output
# 打印输出刚才运行的结果,结果保存到HDFS的output目录下
hdfs dfs -cat output/part-r-00000五、Spark集群
5.1 hadoop-3.yml
version: '3'
networks:
anron:
external: true
services:
spark-master:
container_name: spark-master
image: bde2020/spark-master
environment:
- INIT_DAEMON_STEP=setup_spark
- constraint:node==master
ports:
- 8080:8080
- 7077:7077
networks:
- anron
spark-worker-1:
container_name: spark-worker-1
image: bde2020/spark-worker
depends_on:
- spark-master
environment:
- SPARK_MASTER=spark://spark-master:7077
- constraint:node==worker1
ports:
- 8081:8081
networks:
- anron
spark-worker-2:
container_name: spark-worker-2
image: bde2020/spark-worker
depends_on:
- spark-master
environment:
- SPARK_MASTER=spark://spark-master:7077
- constraint:node==worker2
ports:
- 8082:8081
networks:
- anron5.2 启动Hadoop集群
启动hadoop-3.yml
docker-compose -f hadoop-3.yml up5.3 查看WebUI
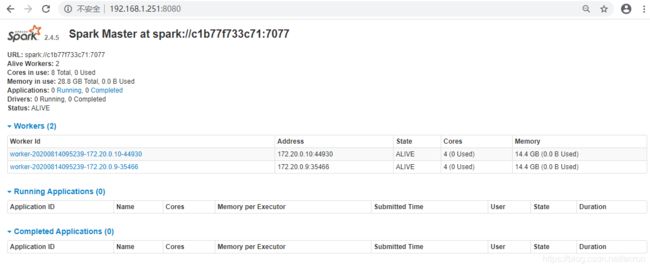
5.4 运行wordcount例子
# 进入spark-worker容器
docker exec -it spark-worker-1 bash
# 运行spark-shell
/spark/bin/spark-shell --master spark://spark-master:7077
#从HDFS读取文件计算后输出到HDFS
val textFile=sc.textFile("hdfs://namenode:9000/user/root/input")
val wordCounts = textFile.flatMap(line=>line.split(" ")).map(word=>(word,1)).reduceByKey((a,b)=>a+b)
# 参数是目录不是文件
wordCounts.saveAsTextFile("hdfs://namenode:9000/user/root/out1");
#从HDFS读取文件计算后输出到控制台
val textFile=sc.textFile("hdfs://namenode:9000/user/root/input")
val wordCounts = textFile.flatMap(line=>line.split(" ")).map(word=>(word,1)).reduceByKey((a,b)=>a+b)
wordCounts.collect
#读取spark中的文件计算后输出到控制台
# 1.如果是spark-shell --master spark://spark-master:7077启动,spark集群下每台机子都要有/input目录,否则提示文件不存在
# 2.如果是spark-shell --master local启动,只要本机有/input目录就可以了
val textFile=sc.textFile("file:///input")
val wordCounts = textFile.flatMap(line=>line.split(" ")).map(word=>(word,1)).reduceByKey((a,b)=>a+b)
wordCounts.collect
注意:先要确保HDFS中存在/user/root/input目录及相应的文件