End-to-End Object Detection with Transformers 论文学习
Abstract
本文提出了一个新的方法,将目标检测看作一个直接的集合预测问题。该方法让检测变得更简洁,去除了人为设计的后处理步骤如 NMS 或 anchor 生成,显式地编码了关于任务的先验知识。该框架的主要结构叫做 DEtection TRansformer 或 DETR,基于集合的全局损失,通过二分匹配和一个 transformer 编码器-解码器架构来做到唯一的预测。给定一个固定小集合的目标,DETR 会推理出这些目标与全局图像环境的关系,并行地直接输出最终的预测集合。和其它检测器相比,该模型在概念上很简单,无需一个特别定制的库。DETR 在MS COCO 目标检测数据集上与 Faster R-CNN 做了比较,展现了优异的准确性和速度性能。而且,DETR 可以很容易地泛化到其它任务上,如全景分割。作者证明它能明显地优于其它基线模型。训练代码和预训练模型位于:https://github.com/facebookresearch/detr。
1. Introduction
目标检测的目的是为感兴趣的目标预测一组边框及其类别标签。现有的检测器都是以一种间接的方式来解决该预测问题,在一个由候选框、anchors或窗口中心点组成的大集合上定义替代的回归问题和分类问题。其表现很大程度上受到后处理步骤影响,通过 anchor 集合的设计和目标框如何赋给 anchor 的启发式规则来消除相邻的重复边框。为了简化这些流程,作者提出了一个直接的集合预测方法,绕过这些代替任务。该端到端的思想极大地推动了一些复杂结构的预测任务的进步,如机器翻译、语音识别,但还没涉及到目标检测:以前的尝试[43,16,4,39] 要么需要其它形式的先验知识,要么在具有挑战性的数据集上表现不佳。

图1. DETR 直接预测(并行地)检测结果的最终集合,它将常见的 CNN 和 transformer 架构结合起来。训练时,二分匹配会给每个 ground-truth 边框分配一个预测框。没有配对的预测框会得到一个“no object” ( ∅ ) (\varnothing) (∅)的类别预测。
作者简化了训练流程,将目标检测任务看作为一个直接的集合预测问题。基于序列预测架构 transformer,采用了一个编码器-解码器架构。Transformer 的自注意力机制显式地对序列元素间的相互作用进行建模,特别适合集合预测中的一些约束条件,如去除重复预测框。
DETR(图1)一次性地预测所有的目标,通过一个集合损失函数来端到端地训练,该损失函数对预测框和 ground-truth 边框做二分匹配。DETR 舍弃了编码先验知识的人为组件(如空间 anchors 或 NMS),简化了检测流程。与大多数现有的目标检测方法不同,DETR 无需任何特殊实现的层,因此可以很容易复现,只要该框架包含了标准的 CNN 类和 transformer 类。
与之前大多数的直接进行集合预测的方法相比,DETR 的主要特点就是将二分匹配损失和(非自回归)并行解码的 Transformer 结合起来用。而以前的方法则关注在 RNN 自回归解码上。本文的匹配损失函数给 ground-truth 目标框只分配一个预测框,该函数对预测目标的排列是不变的,所以我们可以并行地忽略掉它们。
作者在 COCO 数据集上评价了 DETR,与 Faster R-CNN 基线模型做比较。Faster R-CNN 迭代设计了多次,性能得到大幅度提升。本文实验表明,DETR 可以取得相同的性能。DETR 对大目标而言,效果要更优,这可能是因为 transformer 中的 non-local 计算造成的。但是,对小目标而言,其表现要差一些。作者期待在将来,可以通过类似于 Faster RCNN 中的 FPN 设计来改善这个问题。
DETR 的训练设置与标准的目标检测器在多个方面有不同。该模型需要更长的训练时间,需要 transformer 中的解码损失作为辅助。作者仔细地研究了到底哪些组件对性能最重要。
DETR 的设计思想可以扩展到其它任务上去。在实验中,作者证明在全景分割任务上,一个简单的、基于 DETR 预训练的分割 head 就可以超过基线模型。
2. Related Work
本文基于多个领域而构建:用于集合预测的二分匹配损失、基于 transformer 的编码器-解码器架构、并行解码,和目标检测方法。
2.1 集合预测
并没有一个经典的深度学习模型来直接预测集合。基本的集合预测任务是多标签分类,其基线方法(one-vs-rest)无法应用到检测问题上,因为元素之间有着潜在的结构(即近似边框)。第一个难点就是避免近似重复。大多数检测器都使用 NMS 来解决这个问题,但是直接的集合预测就不需要后处理了。它们需要一个全局推理机制,对所有预测元素之间的关系建模,避免冗余性。对于大小固定的集合预测,密集的全连接网络可以做到,但是成本太高。一个常用的方法是使用自回归序列模型,如循环神经网络。在所有情形中,损失函数应该对所有预测的排列保持不变。常用的办法是基于匈牙利算法来设计损失函数,找到 ground-truth 和预测框之间的二分匹配。这就有了排列-不变性,确保了每个目标元素只有一个配对。作者遵循了二分匹配损失方法。但是与之前的方法不同,作者没有用自回归模型,而是用 transformer 来并行地解码。
2.2 Transformers 和并行解码
Vaswani 等人提出了 Transformer,作为一个新的基于注意力的构建模块,用于机器翻译。注意力机制是能从整个输入序列中聚合信息的神经网络层。Transformers 引入了自注意力层,与 Non-Local 神经网络类似,会扫描一个序列的所有元素,通过融合整个序列的信息来更新它。基于注意力方法的一个主要优势就是它们的全局计算和完美的记忆功能,使之比 RNN 更适合用在长序列上。Transformers 如今在许多自然语言处理、语音处理和计算机视觉问题上替代了 RNN。
Transformers 首先在自回归模型中被使用,伴随着早期的 sequence-to-sequence 模型,挨个地生成输出 tokens。但是推理成本过高(与输出长度成正比,很难批量化),就有了并行序列生成,比如在语音领域、机器翻译领域、单词表示学习、语音识别等。作者也将 transformers 和并行解码结合起来,从而实现计算成本和集合预测所需全局计算的平衡。
2.3 目标检测
目前大多数的目标检测算法都跟初始盲猜有关,再做预测。双阶段检测器会根据区域候选框来做边框预测,而单阶段方法则根据 anchors 来做预测。[52]前不久证明,这些系统的最终表现严重依赖于初始盲猜的方式。本文方法可以去除人为后处理步骤,将检测过程变得更简洁,根据输入图像而非 anchors,直接预测检测边框的集合。
基于集合的损失函数。有一些检测器[9,25,35]使用二分匹配损失函数。但是,早期的深度学习模型是通过卷积层或全连接层来对不同预测之间的关系建模,需要一个人为设计的 NMS 来提升性能。前不久刚出现的检测器[37,23,53]则在 ground truth 和预测边框之间使用一个非唯一的分配规则及 NMS。
可学习的NMS方法和关系网络显式地通过注意力机制,对不同预测边框之间的关系建模。它们不需要任何后处理步骤,使用直接的集合损失。但是这些方法都使用了额外的前后关系特征,如候选框坐标,来对检测结果之间的关系建模,而本文则试图降低模型中先验知识的编码。
循环检测器。与本文最接近的方法是端到端的集合预测,用于目标检测和实例分割。与本文类似,它们也用了二分匹配损失和基于CNN激活的编码器-解码器架构,直接输出边框的集合。但是这些方法只在小规模数据集上验证过,无法达到 SOTA 基线模型的性能。而且它们都基于自回归模型(RNNs),没有使用最近并行解码的 transformers。
3. DETR 模型
如果想在检测任务中直接进行集合预测,两个组成最为关键:(1) 集合预测损失,迫使预测结果和 ground-truth 边框之间只有唯一的配对;(2) 能预测一组目标并对其相互关系建模的网络架构。在图2中,作者介绍了该架构。
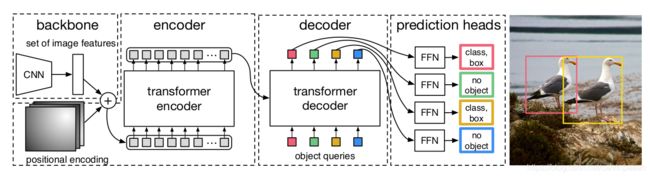
图2. DETR 使用了一个传统的 CNN 主干网络来学习输入图像的 2D 特征。然后模型会将之 flatten,并用位置编码(positional encoding)来填充,然后传递入一个 transformer 编码器。然后 transformer 解码器会将一个固定个数、不多的位置编码作为输入,作者称之为目标查询,然后输入编码器的输出。最后解码器的每个 embedding 输出会输入进一个共享的前馈网络(FFN),预测检测结果(类别和边框坐标)或 “no object” 类别。
3.1 目标检测集合预测损失
DETR 在解码器的单次传播中,会推理出一个固定大小的集合,共包含 N N N个预测, N N N会远远多于图像中目标的常见个数。训练过程中的一个主要难点就是,关于 ground-truth 对预测目标(类别、位置、大小)打分。该损失能在预测边框和 ground-truth 边框之间产生最佳的二分匹配,然后优化边框的损失。
我们用 y y y来表示目标的 ground truth 集合, y ^ = { y ^ i } i = 1 N \hat y=\{\hat y_i\}_{i=1}^N y^={ y^i}i=1N 表示 N N N 个预测的集合。假设 N N N 大于图像中目标的个数,我们考虑 y y y 也是一个大小为 N N N的集合,包含 ∅ \varnothing ∅(no object)。为了在这两个集合之间找到二分配对,我们用最小的代价来搜索 N N N 个元素的排列 σ ∈ G N \sigma \in \mathfrak{G}_N σ∈GN:
σ ^ = arg min σ ∈ G N ∑ i N L m a t c h ( y i , y ^ σ ( i ) ) \hat \sigma = \argmin_{\sigma\in \mathfrak{G}_N} \sum_i^N \mathcal{L}_{match}(y_i, \hat y_{\sigma(i)}) σ^=σ∈GNargmini∑NLmatch(yi,y^σ(i))
其中 L m a t c h ( y i , y ^ σ ( i ) ) \mathcal{L}_{match}(y_i, \hat y_{\sigma(i)}) Lmatch(yi,y^σ(i))是 ground-truth y i y_i yi和索引为 σ ( i ) \sigma(i) σ(i)的预测边框之间的配对代价。通过匈牙利算法可高效率地计算出该最佳配对。
配对代价既考虑了类别预测,也考虑了预测框和 ground-truth 边框的相似度。Ground-truth 集合中的每个元素 i i i都可看作为 y i = ( c i , b i ) y_i = (c_i, b_i) yi=(ci,bi),其中 c i c_i ci是目标类别标签(可能是 ∅ \varnothing ∅), b i ∈ [ 0 , 1 ] 4 b_i\in[0,1]^4 bi∈[0,1]4是定义 ground-truth 边框中心坐标及高度、宽度的向量。对于索引是 σ ( i ) \sigma(i) σ(i)的边框预测,作者定义了类别 c i c_i ci的概率为 p ^ σ ( i ) ( c i ) \hat p_{\sigma(i)}(c_i) p^σ(i)(ci),预测边框为 b ^ σ ( i ) \hat b_{\sigma(i)} b^σ(i)。有了这些记号,作者定义 L m a t c h ( y i , y ^ σ ( i ) ) \mathcal{L}_{match}(y_i, \hat y_{\sigma(i)}) Lmatch(yi,y^σ(i)) 为 − 1 { c i ≠ ∅ } p ^ σ ( i ) ( c i ) + 1 { c i ≠ ∅ } L b o x ( b i , b ^ σ ( i ) ) -\mathbb{1}_{\{c_i \neq \varnothing\}} \hat p_{\sigma(i)}(c_i) + \mathbb{1}_{\{c_i \neq \varnothing\}} \mathcal{L}_{box}(b_i, \hat b_{\sigma(i)}) −1{ ci=∅}p^σ(i)(ci)+1{ ci=∅}Lbox(bi,b^σ(i))。
在现有的检测器中,搜索配对扮演着与启发式分配规则(heuristic assignment rules)相同的角色,为 ground-truth 目标分配候选框或 anchors。主要的不同是,我们要找到直接集合预测中一一对应的配对,没有重复项。
第二步就是计算损失函数,这里用的是匈牙利损失来计算上一步产生的所有配对。作者定义的损失函数与常用的目标检测器差不多,即类别预测的负 log 概率和边框损失的线性结合:
L H u n g a r i a n ( y , y ^ ) = ∑ i = 1 N [ − log p ^ σ ^ ( i ) ( c i ) + 1 { c i ≠ ∅ } L b o x ( b i , b ^ σ ^ ( i ) ) ] \mathcal{L}_{Hungarian}(y, \hat y) = \sum_{i=1}^N [-\log \hat p_{\hat \sigma(i)}(c_i) + \mathbb{1}_{\{c_i \neq \varnothing\}} \mathcal{L}_{box}(b_i, \hat b_{\hat \sigma}(i))] LHungarian(y,y^)=i=1∑N[−logp^σ^(i)(ci)+1{ ci=∅}Lbox(bi,b^σ^(i))]
其中 σ \sigma σ是第一步计算出的最佳配对。实际上出于类别均衡考量,当 c i = ∅ c_i = \varnothing ci=∅时,我们将 log-概率那一项的权重除以10。这和 Faster R-CNN 的训练过程相似,通过亚采样来平衡正负样本。注意,目标和 ∅ \varnothing ∅的配对代价并不取决于预测结果,也就是说该代价是一个常数。在配对代价上,作者使用的是概率 p ^ σ ^ ( i ) ( c i ) \hat p_{\hat \sigma(i)}(c_i) p^σ^(i)(ci),而非 log-概率。这就使得类别预测项与 L b o x ( ⋅ , ⋅ ) \mathcal{L}_{box}(\cdot, \cdot) Lbox(⋅,⋅)等量,我们可以观测到更佳的实验表现。
边框损失。配对代价的第二部分即匈牙利损失, L b o x ( ⋅ , ⋅ ) \mathcal{L}_{box}(\cdot, \cdot) Lbox(⋅,⋅),对边框打分。许多检测器做边框预测时,一开始几乎是盲猜的,而本文方法直接做边框预测。尽管该方法简化了实现过程,它也带来了一个关于相对缩放损失的问题。最常用的 ℓ 1 \ell_1 ℓ1损失对于小边框和大边框有着不同的缩放比例,如果它们的相对损失很接近。为了缓解这个问题,作者使用了一个 ℓ 1 \ell_1 ℓ1 损失和 generalized IoU 损失的线性结合, L i o u ( ⋅ , ⋅ ) \mathcal{L}_{iou}(\cdot,\cdot) Liou(⋅,⋅)是尺度不变的。总之,该边框损失 L b o x ( b i , b ^ σ ( i ) ) \mathcal{L}_{box}(b_i, \hat b_{\sigma(i)}) Lbox(bi,b^σ(i)) 定义为 λ i o u L i o u ( b i , b ^ σ ( i ) ) + λ L 1 ∣ ∣ b i − b ^ σ ( i ) ∣ ∣ 1 \lambda_{iou} \mathcal{L}_{iou}(b_i, \hat b_{\sigma(i)}) + \lambda_{L1} ||b_i - \hat b_{\sigma(i)}||_1 λiouLiou(bi,b^σ(i))+λL1∣∣bi−b^σ(i)∣∣1,其中 λ i o u , λ L 1 ∈ R \lambda_{iou}, \lambda_{L1}\in \mathbb{R} λiou,λL1∈R 是超参数。这两个损失都用该batch内目标的个数做了归一化。
3.2 DETR 架构
DETR 的整体架构非常简单,如图2所示。它包含3个主要部分,下面会介绍:一个 CNN 主干网络来提取紧致的特征表示,一个编码器-解码器 transformer,一个简单的前馈网络(FFN)做最终的检测预测。
与现有的检测器不同,DETR 可以用任何一个深度学习框架实现,只要改框架能提供一个通用的 CNN 主干网络和 transformer 架构,实现起来仅需数百行代码。用 PyTorch 实现 DETR 的推理代码甚至少于50行。作者希望,该方法的简洁性会引起更多的研究人员的关注。
主干网络。输入图像 x i m g ∈ R 3 × H 0 × W 0 x_{img}\in \mathbb{R}^{3\times H_0\times W_0} ximg∈R3×H0×W0(3个颜色通道,输入图像是按batch输入的,所以根据该batch内的最大的图像大小,对其它图片进行0-填充,保证一个batch内图像大小一样),传统 CNN 主干网络会生成一个较低分辨率的激活图 f ∈ R C × H × W f\in \mathbb{R}^{C\times H\times W} f∈RC×H×W。本文用的值是 C = 2048 , H = H 0 32 , W = W 0 32 C=2048,H=\frac{H_0}{32},W=\frac{W_0}{32} C=2048,H=32H0,W=32W0。
Transformer encoder。首先,一个 1 × 1 1\times 1 1×1卷积会降低高层级激活图 f f f的通道维度,从 C C C降低到一个较小的维度 d d d,创建出一个新的特征图 z 0 ∈ R d × H × W z_0 \in \mathbb{R}^{d\times H\times W} z0∈Rd×H×W。该编码器的输入是一个序列,因此作者将 z 0 z_0 z0的空间维度坍缩为一维,形成一个 d × H W d\times HW d×HW的特征图。每个编码器层都有一个标准的架构,由一个 multi-head 自注意力模块和前馈网络(FFN)构成。由于 transformer 架构是排列-不变的,我们用固定的位置编码来填充它,加到每一个注意力层的输入后面。在补充材料中作者详细介绍了该架构的设计。
Transformer decoder。解码器遵循了 transformer 的标准设计,使用 multi-head 自注意力机制和编码器-解码器注意力机制,将 N N N 个大小是 d d d 的 embeddings 进行变换。和原来的 transformer 不同,本文方法在每个解码层,并行地解码 N N N 个目标,而 Vaswani 等则使用了一个自回归模型来一次一个元素地预测序列的输出。在补充材料,作者提供了该内容的介绍。由于解码器也是排列-不变的,要想输出不同的结果, N N N个输入 embeddings 必须是不一样的。这些输入 embeddings 是学到的位置编码,作者称之为目标查询,与编码器类似,作者将它们加到每个注意力层的输入后面。 N N N个目标查询就被解码器转化为一个输出 embedding。然后通过一个前馈网络,它们独立地被解码为边框坐标和类别标签,这样就有了 N N N个最终预测结果。对这些 embeddings 使用自注意力和编码器-解码器注意力,模型就可通过它们彼此间的关系,全局地推理出所有目标,将整张图像作为前后信息使用。
预测前馈网络(FFNs)。通过一个三层感知机(带有ReLU激活函数、隐藏维度是 d d d,并带有线性映射层),最终的预测结果就可计算出来。FFN 预测边框归一化后的中心坐标、高度和宽度,线性层会通过 softmax 函数预测类别标签。由于我们预测一个固定大小 N N N的边框集合, N N N通常要大于图像中的实际目标个数,用一个额外的类别标签 ∅ \varnothing ∅来表示"no object"类别。该类的角色和标准的目标检测中背景类相似。
辅助解码损失。训练时在解码器中使用辅助损失是有帮助的,尤其能帮助模型输出每类正确个数的目标。在每个解码层后,作者增加了预测 FFN 和匈牙利损失函数。所有的预测 FFN 共享参数。作者使用了一个额外的共享norm-层,从不同的解码层对预测 FFN 的输入做归一化。
4. 实验
Pls read paper for more details.
A.3 细节架构

图10. DETR 中 transformer 的结构。
DETR 用到的 transformer 的细节信息如图10所示,每个注意力层都会传入位置编码。CNN 主干网络输出的图像特征会贯穿 transformer 编码器,在每个 multi-head 自注意力层位置上,加进 queries 和 keys 的空间位置编码也会贯穿 transformer 编码器。然后解码器会接收 queries(初始设为0),输出位置编码(目标queries)和编码器记忆,通过多个 multi-head 自注意力和解码器-编码器注意力机制输出最终预测类别标签和边框。第一个解码层中的自注意力层可以忽略。