国科大 - 自然语言处理(刘洋)- 期末复习
Content
文章目录
-
-
-
- 20201231
- LM
- 分词
-
- 最大匹配算法
- 最短路径法(最少分词法)
- 句法分析
-
- Chart Parsing
- 9.4 CYK 分析算法
- 9.5 概率上下文无关文法
- 9.6 PCFG 的三个问题
-
- 第一个问题:内向概率
- 第一个问题:外向概率
- 第二个问题:Viterbi 算法
- 第三个问题:参数估计
- 9.8 短语结构分析方法评估
- 9.10 依存句法分析
-
- 表示方法
- 依存句法分析方法
- **决策式的 (确定性的) 分析方法 (deterministic parsing)**
- 实现一个依存句法分析器
- 9.11 依存句法分析器 性能评价
- 9.12 短语结构与依存结构的关系
- MT
-
- 噪声信道模型
- 对位模型
- 基于短语的翻译模型
- 短语翻译模型
- 短语调序模型
- 译文评估
- 熵熵熵
- CLS
- HMM
-
- HMM:观测状态序列概率计算
- 概念题知识点
- 参考
-
-
20201231
题型(概念+计算,其中 60 送分,30 中等,10 分难题)
- 30 分:判断 10、选择 10、填空 10
- 70 分:7 道计算题(计算不会超出课件上的题目)
- HMM
- 线图分析法(点规则)、CYK(步骤 1. 汉语分词和词性标注;2. 构造识别矩阵;3. 执行分析过程)
- Shift-Reduce
- LM,n-gram,平滑(根据二元文法求句子概率,结合数据平滑方法)
- 分词算法(最大匹配法)
- 评价指标:分词、词性标注、句法分析
- 机器翻译:基于短语的翻译模型
- 分类:Naïve Beyes
- 依靠中心词将短语结构转换为依存结构
一个热心同学提供的期末考点列表(赞)。
LM
给定训练语料:
- “John read Moby Dick”,
- “Mary read a different book”,
- “She read a book by Cher”
计算句子 “John read a book“ 的概率。
解:
注:为了保证一个词的句子的合理性,并利用某个词属于句首或句尾的信息,在进行参数估计时,会为每个句子加上 和 。分别代表 beginning of sentence、ending of sentence。
填充后,得到
John read Moby Dick
Mary read a different book
She read a book by Cher
目标:John read a book
计算:
p ( J o h n ∣ < B O S > ) = c ( < B O S > J o h n ) ∑ w c ( < B O S > w ) = 1 3 p(John|
p ( r e a d ∣ J o h n ) = c ( J o h n r e a d ) ∑ w c ( J o h n w ) = 1 1 p(read|John)=\frac{c(John\ read)}{\sum_wc(John\ w)}=\frac 1 1 p(read∣John)=∑wc(John w)c(John read)=11
p ( a ∣ r e a d ) = c ( r e a d a ) ∑ w c ( r e a d w ) = 2 3 p(a|read)=\frac{c(read\ a)}{\sum_wc(read\ w)}=\frac 2 3 p(a∣read)=∑wc(read w)c(read a)=32
p ( b o o k ∣ a ) = c ( a b o o k ) ∑ w c ( a w ) = 1 2 p(book|a)=\frac{c(a\ book)}{\sum_wc(a\ w)}=\frac 1 2 p(book∣a)=∑wc(a w)c(a book)=21
p ( < E O S > ∣ b o o k ) = c ( b o o k < E O S > ) ∑ w c ( b o o k w ) = 1 2 p(
注: w w w 表示任意一个词。
则
p ( John read a book ) = 1 3 ⋅ 1 1 ⋅ 2 3 ⋅ 1 2 ⋅ 1 2 ≈ 0.06 p(\text{John read a book})=\frac1 3\cdot\frac1 1\cdot\frac2 3\cdot\frac1 2\cdot\frac1 2\approx0.06 p(John read a book)=31⋅11⋅32⋅21⋅21≈0.06
Add-one Smoothing(Laplace Smoothing)
P Add − 1 ( w i ∣ w i − 1 ) = c ( w i − 1 , w i ) + 1 c ( w i ) + V \mathrm{P}_{\text {Add }-1}\left(\mathrm{w}_{\mathrm{i}} | \mathrm{w}_{\mathrm{i}-1}\right)=\frac{\mathrm{c}\left(\mathrm{w}_{\mathrm{i}-1}, \mathrm{w}_{\mathrm{i}}\right)+1}{\mathrm{c}\left(\mathrm{w}_{\mathrm{i}}\right)+\mathrm{V}} PAdd −1(wi∣wi−1)=c(wi)+Vc(wi−1,wi)+1
其中,V 是语料库词表大小。
Add-K Smoothing(Laplace Smoothing)
P Add − 1 ( w i ∣ w i − 1 ) = c ( w i − 1 , w i ) + k c ( w i ) + k V \mathrm{P}_{\text {Add }-1}\left(\mathrm{w}_{\mathrm{i}} | \mathrm{w}_{\mathrm{i}-1}\right)=\frac{\mathrm{c}\left(\mathrm{w}_{\mathrm{i}-1}, \mathrm{w}_{\mathrm{i}}\right)+k}{\mathrm{c}\left(\mathrm{w}_{\mathrm{i}}\right)+\mathrm{kV}} PAdd −1(wi∣wi−1)=c(wi)+kVc(wi−1,wi)+k
其中,V 是语料库词表大小。

分词
最大匹配算法
- 正向最大匹配算法(Forward MM, FMM)
- 逆向最大匹配算法(Backward MM, BMM)
- 双向最大匹配算法(Bi-directional MM)

1 + β 2 F β = 1 P + β 2 R \frac{1+\beta^2}{F_\beta}=\frac{1}{P}+\frac{\beta^2}{R} Fβ1+β2=P1+Rβ2
最短路径法(最少分词法)
有词典切分。从产生的所有路径中,选择路径最短的词数最少的作为最终分词结果。
求最短路径:贪心法或简单扩展法。

句法分析
Chart Parsing
Chart Parsing:
- 维护三个栈:Agenda、Active、Closed
- 遍历词性,
- 添加到 Agenda
- 匹配规则(匹配成功则进 Active)
- 匹配 Active
- 如果匹配上,划掉两个旧项(Agenda + Active),添弧(从 Agenda 移除都要添弧),合成新项移到 Closed,再从 Closed 移进 Agenda,继续匹配规则
- 如果匹配不上,划掉该项,添弧,
板书:

完整例题:

注意:不能出现弧相交的情况,否则为错解。
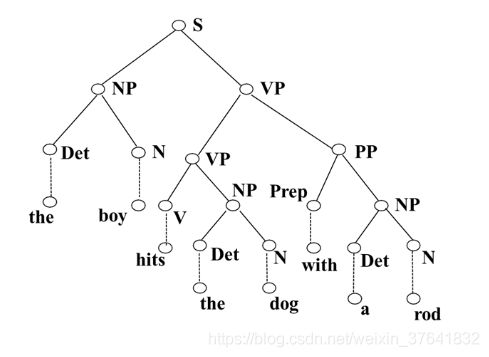
将上图中的边改为结点,将结点改为边,得到分析结果的直观图(主要是给人看,机器不需要)。
具体地说,首先看最外层弧 S,S 下有两个小组长,NP 和 VP,而 VP 下有两个小组长 VP 和 PP…
9.4 CYK 分析算法
Coke-Younger-Kasami (CYK) 算法
- 对 Chomsky 文法进行范式化(CNF):
- 自下而上的分析方法
- 构造 ( n + 1 ) × ( n + 1 ) (n+1)\times(n+1) (n+1)×(n+1) 识别矩阵, n n n 为输入句子长度。
板书:
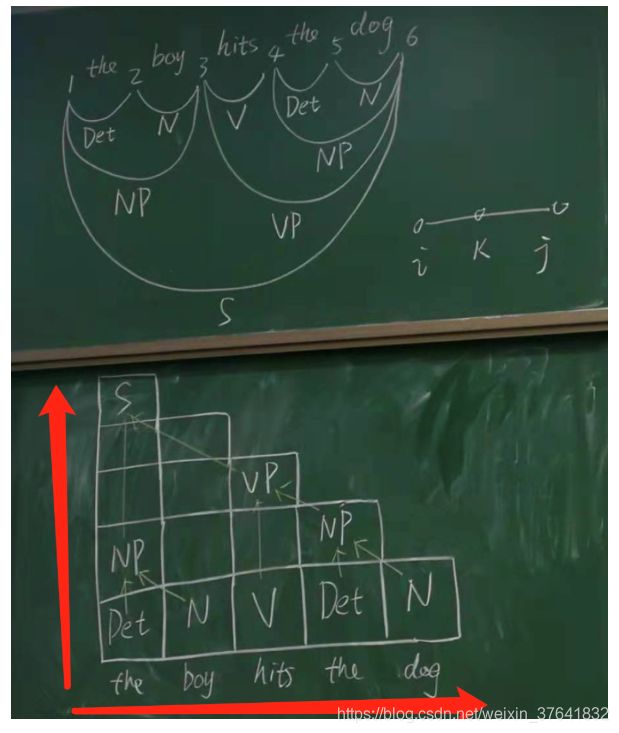
例子。

转换为树:
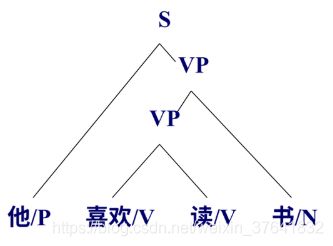
Chart 线图分析法和 CYK 算法的比较:
共同点
- 都属于基于 CFG 规则的分析方法,需要高质量的规则,分析结果与规则质量密切相关;
- 缺点:都难以区分歧义结构。(也是基于 CFG 规则算法共有的缺点,因此需要引入概率,即 PCFG)
不同点
- 相比 CYK 算法,线图分析法的时间复杂度更高(但同为 O ( n 3 ) \mathcal O(n^3) O(n3),其中 n n n 为句长)。
- CYK 算法必须对文法进行范式化处理;但 Chart parsing 算法不需要。
9.5 概率上下文无关文法
需要掌握的 3 点:
- PCFG 定义和概率约束规则
- 什么是上下文无关
- 一颗(子)树的概率怎么算
基于 CFG 规则的分析方法有一个共同的缺点,即难以区分歧义结构。因此概率上下文无关文法(GCFG)引入了概率。新事物的产生会带来新的矛盾。引入概率后,发生了两个变化
- 通过概率选取歧义度低(即概率大)的结构;
- 计算复杂度增加。
GCFG 中的概率是上下文无关的,那和什么有关呢(既然是概率,就要归一),PCFG 规则如下,
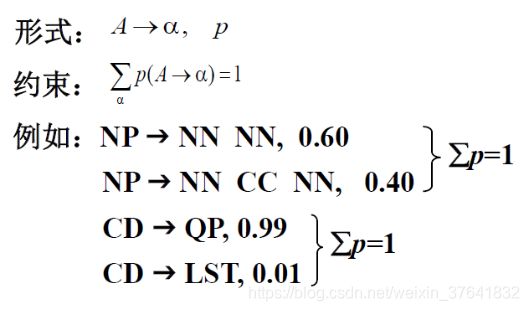
即从某个具体左部出发的规则的概率要归一,如从 CD 出发的两条规则。
通过线图分析法、CYK 等算法构成树后,子树的概率计算方式如下,即通过概率连乘。

同时我们也注意到:NP 子树的计算与 PP 子树有关,但与其父节点(或祖先节点)无关,此即上下文无关性:子树的概率与子树管辖范围以外的词无关。
但要注意局部子树的概率计算的坑,如下图的 VP 子树,参与计算的不是 NP 节点的概率,而是 NP 子树概率本身。

对于给定的句子 S S S ,假设可以得到两棵不同的句法分析树(即存在结构歧义),但 P ( t r e e 1 ) > P ( t r e e 2 ) P(tree_1) > P(tree_2) P(tree1)>P(tree2),因此,可以得出结论:分析结果 t r e e 1 tree_1 tree1 正确的可能性大于 t r e e 2 tree_2 tree2。PCFG 从概率的角度,一定程度上减缓了结构歧义的问题。
9.6 PCFG 的三个问题
1、给定句子的词性 W = w 1 w 2 … w n W=w_1w_2…w_n W=w1w2…wn 和 PCFG G,如何快速计算 p ( W ∣ G ) p(W|G) p(W∣G)?答:内向、外向算法。
2、给定句子的词性 W = w 1 w 2 … w n W=w_1w_2…w_n W=w1w2…wn 和 PCFG G,如何快速地选择最佳句法结构树?答:Viterbi 算法。
3、给定句子的词性 W = w 1 w 2 … w n W=w_1w_2…w_n W=w1w2…wn 和 PCFG G,如何调节 G 的参数,使得 p ( W ∣ G ) p(W|G) p(W∣G) 最大?答:EM 算法。
假设文法 G(S) 的规则只有两种形式:
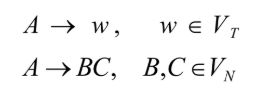
可以通过范式化处理,使 CFG 规则满足上述形式。这种假设的文法形式称为乔姆斯基范式(Chomsky normal form, CNF)。
第一个问题:内向概率
我们定义内向概率 α i j ( A ) \alpha_{ij}(A) αij(A) 是由非终止符 A 推导出的语句 W 中子字串 w i ⋯ w j w_i\cdots w_j wi⋯wj 的概率,其计算有两种情况,
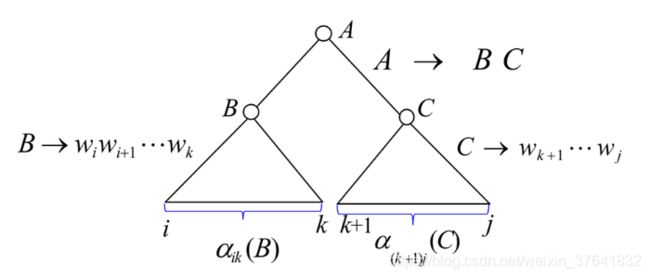
对于第二条公式的理解:因为 A → B C A\to BC A→BC 的 BC 是不确定的,BC 不同则 i j ij ij 的分界点 k k k 也随之变化,因此这里求的是期望(准确说是各种情况下概率的总和)。
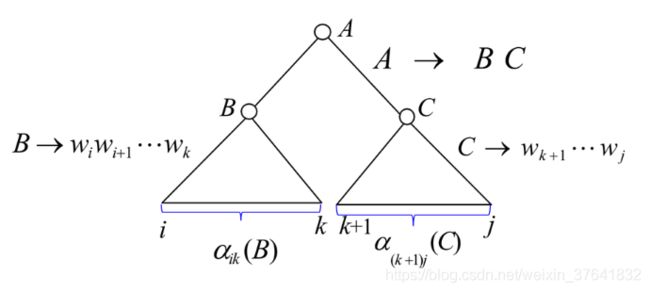
内向概率的计算(自底向上,或者说自外向内)的可视化理解如下:
第一个问题:外向概率
外向概率的计算如下式。要注意的是外向概率的计算使用到了内向概率,因此在计算外向概率前要首先计算内向概率(这一点与前向后向算法是不同的)。

第二个问题:Viterbi 算法
其实就是把内向概率所有路径的求和改为求最大路径。
第三个问题:参数估计
情况一:如果有大量已标注语法结构的训练语料,则可直接通过计算每个语法规则的使用次数,用最大似然估 计方法计算 PCFG 规则的概率参数,即:
p ^ ( N j → ξ ) = # ( N j → ξ ) ∑ γ # ( N j → γ ) \hat p(N^j\to \xi)=\frac{\#(N^j\to \xi)}{\sum_\gamma\#(N^j\to \gamma)} p^(Nj→ξ)=∑γ#(Nj→γ)#(Nj→ξ)
情况二:多数情况下,没有可利用的标注语料,只好借助 EM (Expectation Maximization) 迭代算法估计 PCFG 的概率参数。
初始时随机地给参数赋值,得到语法 G 0 G_0 G0,依据 G 0 G_0 G0 和 训练语料,得到语法规则使用次数的期望值,以期望次 数运用于最大似然估计,得到语法参数新的估计值,由 此得到新的语法 G 1 G_1 G1,由 G 1 G_1 G1 再次得到语法规则的使用次数 的期望值,然后又可以重新估计语法参数。循环这个过 程,语法参数将收敛于最大似然估计值。
内外向算法
给定 CFG G 和训练数据 W = w 1 ⋯ w n W=w_1\cdots w_n W=w1⋯wn,语法规则 A → B C A\to BC A→BC 使用次数的期望值为:
C o u n t ( A → B C ) = ∑ 1 ≤ i ≤ k ≤ j ≤ n p ( A i j , B i k , C ( k + 1 ) j ∣ w 1 ⋯ w n , G ) = 1 p ( w 1 ⋯ w n ∣ G ) ∑ 1 ≤ i ≤ k ≤ j ≤ n p ( A i j , B i k , C ( k + 1 ) j , w 1 ⋯ w n ∣ G ) = 1 p ( w 1 ⋯ w n ∣ G ) ∑ 1 ≤ i ≤ k ≤ j ≤ n β i i ( A ) p ( A → B C α i k ( B ) α ( k + 1 ) j ( C ) \begin{aligned} Count(A\to BC) &=\sum_{1\le i\le k\le j\le n}p(A_{ij},B_{ik},C_{(k+1)j}|w_1\cdots w_n, G)\\ &=\frac{1}{p\left(w_{1} \cdots w_{n} \mid G\right)} \sum_{1\le i\le k\le j\le n} p\left(A_{ij},B_{ik},C_{(k+1)j}, w_{1} \cdots w_{n} \mid G\right) \\ &=\frac{1}{p\left(w_{1} \cdots w_{n} \mid G\right)} \sum_{1\le i\le k\le j\le n} \beta_{i i}(A) p(A\to BC\ \alpha_{ik}(B)\alpha_{(k+1)j}(C) \end{aligned} Count(A→BC)=1≤i≤k≤j≤n∑p(Aij,Bik,C(k+1)j∣w1⋯wn,G)=p(w1⋯wn∣G)11≤i≤k≤j≤n∑p(Aij,Bik,C(k+1)j,w1⋯wn∣G)=p(w1⋯wn∣G)11≤i≤k≤j≤n∑βii(A)p(A→BC αik(B)α(k+1)j(C)
公式理解:分母为 w 1 ⋯ w n w_1\cdots w_n w1⋯wn 生成的所有合法句法树的概率之和。
在实际建模时,我们有宾州树库(PCTB),即属于情况一。
PCFG 的评价
优点:
- 可利用概率减少分析过程的搜索空间;
- 可利用概率对概率较小的子树剪枝,加快分析效率;
- 可以定量地比较两个语法的性能。
弱点:
- 分析树的概率计算条件非常苛刻,甚至不够合理。
9.8 短语结构分析方法评估
句法分析器性能评测
目前使用比较广泛的句法分析器评价指标 PARSEVAL测度,三个基本的评测指标:
精度(precision):句法分析结果中正确的短语个数所占的比例,即分析结果中与标准分析 树(答案)中的短语相匹配的个数占分析结果中所有短语个数的比例。
召回率(recall):句法分析结果中正确的短语个数占标准分析树中全部短语个数的比例。
F-measure:
F = ( β 2 + 1 ) × P × R β 2 × P + R × 100 % F=\frac{(\beta^2+1)\times P \times R}{\beta^2\times P+R}\times 100\% F=β2×P+R(β2+1)×P×R×100%
例如:Sales executives were examining the figures with great care yesterday.
句子长度为 10,span 为 0 − 10 0-10 0−10,其中 11 为句点。(自己要会标跨度)
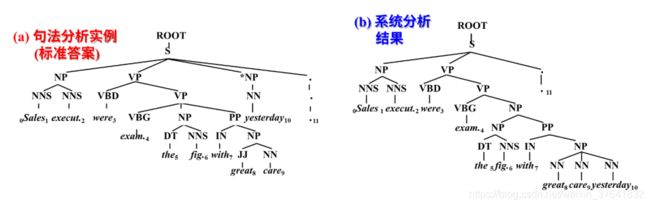
在标准答案树中,除了词性标注符号以外(即除了叶子节点和 其直接父节点以外)的其他非终结符节点(短语)有:S-(0:11), NP-(0:2), VP-(2:9), VP-(3:9), NP-(4:6), PP-(6:9), NP-(7:9), NP-(9:10) 。
在系统输出的分析树中,除了词性标注符号以外的其他非终结符节点(短语)有:S-(0:11), NP-(0:2), VP-(2:10), VP-(3:10), NP-(4:10), NP-(4:6), PP-(6:10), NP-(7:10)。
注:蓝字表示结果一致。
只有 3 个短语与标准答案完全一样,因此,
P = R = 3 8 × 100 % = 37.5 % P=R=\frac{3}{8}\times100\%=37.5\% P=R=83×100%=37.5%
其他指标:
词性标注的准确率 (tagging accuracy)。在该句子的分析树中,11 个词中除了 great 被错误地标注以外,其他的词性标注均为正确的,因此,词性标注准确率为 10/11=90.9%.
9.10 依存句法分析
现代依存语法 (dependency grammar) 理论的创立者是法国语言学家 L. Tesnière。
L. Tesnière 的理论认为:一切结构句法现象可以概括为
- 关联 (connexion)
- 组合 (jonction)
- 转位 (tanslation)
这三大核心。句法关联建立起词与词之间的从属关系,这种从属关系是由支配词和从属词联结而成。L. Tesnière 理论认为:动词是句子的中心,并支配其他成分,它本身不受其他任何成分的支配。
在依存语法理论中,“依存”就是指词与词之间支配与被支配的关系,这种关系不是对等的,而是有方向的。处于支配地位的成分称为支配者,而处于被支配地位的成分称为从属者。
依存语法的优势
- 依存分析树是天然词汇化的,每个节点天然就是一个词。
- 不过多强调句子中的固定词序,对自由语序的语言分析更有优势(你吃饭了吗?饭你吃了吗?)
- 受深层语义结构的驱动,词汇的依存本质是语义的;
- 形式化程度较短语结构语法浅,对句法结构的表述更为灵活。
表示方法
可以使用有向图:被支配者在箭头端,支配者在有向弧的发出端,我们通常说被支配者依存于支配者。

依存句法分析方法
依存句法分析 (dependency parsing) 的任务就是分析出句子中所有词汇之间的依存关系。
建立一个依存句法分析器一般需要完成以下三部分工作:
- 依存句法结构描述
- 分析算法设计与实现
- 文法规则或参数学习
目前依存句法结构描述一般采用有向图方法或依存树方法,所采用的句法分析算法可大致归为以下 4 类:
- 生成式的分析方法 (generative parsing):采用联合概率模型,复杂度高,不易加入语言特征。但准确率高。
- 判别式的分析方法 (discriminative parsing):把所有的情况都考察一边(生成树),挑出最佳结果(因此要设计特征和打分函数)。
- 决策式的 (确定性的) 分析方法 (deterministic parsing)【重点】
- 基于约束满足的分析方法 (constraint satisfaction parsing)
决策式的 (确定性的) 分析方法 (deterministic parsing)
基本思想:模仿人的认知过程,按照特定方向每次读入一个词。每读入一个词,都要根据当前状态做出决策 (比如判断是否与前一个词发生依存关系)。一旦决策做出,将不再改变。所做决策即“采取什么样的分析动作 (action)”。分析过程可以看作是一步一步地作用于输入句子之上的分析动作 (action) 的序列。
移进-归约算法
J. Nivre 等 (2003) 提出的自左向右、自底向上的分析算法。
当前分析状态的格局 (configuration) 是一个三元组:
( S , I , A ) (S,I,A) (S,I,A)
S, I, A 分别表示栈顶词、未处理序列中的当前词 (Input) 和依存弧集合 (Arcs)。分析体系主要包含两种分析动作组合,
- 一种是采用标准移进-规约方式,使用 Left-Reduce、Right-Reduce 和 Shift 三种动作。
- 另一种是 Arc-eager 分析算法——4 种分析动作 (Actions)。【不要求掌握】
标准移进-规约
Shift,Left,Right。
注:共 n = 5 n=5 n=5 个词,因此执行了 2 n − 1 = 9 2n-1=9 2n−1=9 次操作,其中 n = 5 n=5 n=5 次移栈(Shift),另外 n − 1 = 4 n-1=4 n−1=4 次是加弧操作。其中 Left 是以左为首,Right 是以右为首。注:这里的相对位置是在栈中而言。存放 input 的是队列。
综上,对于给定 n n n 个词的句子,**标准移进-规约(Shift-Reduce)**算法只需执行 2 n − 1 2n-1 2n−1 次操作,即可完成依存分析。
方法评价
- 优点:
- 可以达到线性复杂度,
- 算法可以使用之前产生的所有句法结构作为特征。
- 弱点:
- 以局部最优的加和代替全局最优,导致错误传递;
- 不可处理非投射现象,准确率稍逊于全局最优算法。
额外话:Shift-Reduce 算法在执行上并不复杂,但真正困难的地方在于每一步选取哪个操作,这需要设计大量的特征。同时,因为这个算法是“一条路走到白”,为了降低风险,在实践中加入集束搜索(beam search)效果会更好。
出题:给句法树、动作体系,还原唯一的动作序列。
实现一个依存句法分析器
以由 Arc-eager 算法实现基于转换的 (transition-based) 句法分析器为例。
基本思路:在每一个状态 (configuration) 下根据当前状态提取特征, 然后通过分类决定下一步应该采的动作(action),执行分类器选择的最优动作,转换到下一个状态。
具体实现:
- 标注大量的依存关系句法树,建立训练集。每个 句子都可以一对一地转换为动作序列;
- 确定特征集合,以构造动作分类器。
如何构建特征?
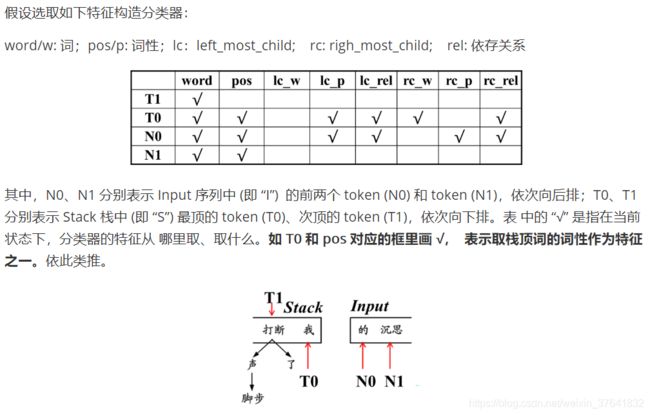
9.11 依存句法分析器 性能评价
无标记依存正确率 (unlabeled attachment score, UA):不看弧上的标记,所有词中找到其正确支配词的词所占的百分比, 没有找到支配词的词 (即根结点) 也算在内。(找老大)
带标记依存正确率 (labeled attachment score, LA): 所有词中找到其正确支配词并且依存关系类型也标注正确的词所占的百分比,根结点也算在内。
依存正确率 (dependency accuracy, DA):所有非根结点词中找到其正确支配词的词所占的百分比。
根正确率 (root accuracy, RA):有两种定义方式:
- 一种是:正确根结点的个数与句子个数的比值;
- 另一种是:所有句子中找到正确根结点的句子所占的百分比。
注:对单根结点语言或句子来说,二者是等价的。
完全匹配率 (complete match, CM):所有句子中无标记依存结构完全正确的句子所占的百分比。
例子。
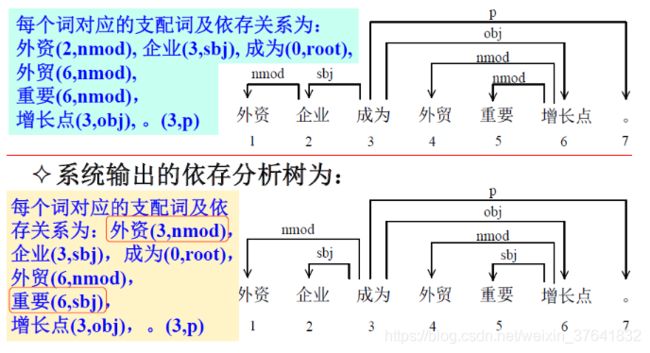
解:
U A = 6 7 × 100 % = 85.71 % UA=\frac{6}{7}\times100\%=85.71\% UA=76×100%=85.71%
L A = 5 7 × 100 % = 71.43 % LA=\frac{5}{7}\times100\%=71.43\% LA=75×100%=71.43%
D A = 5 6 × 100 % = 83.33 % DA=\frac{5}{6}\times100\%=83.33\% DA=65×100%=83.33%
9.12 短语结构与依存结构的关系
短语结构可转换为依存结构
实现方法:
-
定义中心词抽取规则,产生中心词表;
-
根据中心词表,为句法树中每个节点选择中心子节点;
-
将非中心子节点的中心词依存到中心子节点的中心词上,得到相应的依存结构。
例1:给定如下短语结构树。
注:在短语结构树中,有两种标记,一是词性标注(如 DT、NN),二是句法标注(如 NP)。
句子:Vinken will join the board as a nonexecutive director Now 29.
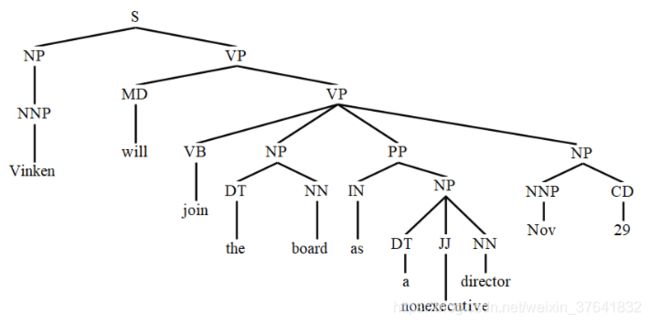
根据中心词表(可自行设计,反正就是一些 PK 规则),自底向上,一颗子树的所有子节点 PK,赢的成为代表,作为中心词往上传递。如下图中 the 和 board PK,board 胜利,因此把 ( b o a r d , N N ) (board,\ NN) (board, NN) 传递给 NP。
将非中心子节点的中心词依存到中心子节点的中心词上

例2:句子 “我喜欢这本书。” 的短语结构树如下:

MT
噪声信道模型
源语言句子: S = s 1 s 2 ⋯ s m S=s_1s_2\cdots s_m S=s1s2⋯sm
目标语言句子: T = t 1 t 2 ⋯ t l T=t_1t_2\cdots t_l T=t1t2⋯tl
P ( T ∣ S ) = P ( T ) P ( S ∣ T ) P ( S ) P(T|~S)=\frac{P(T)P(S|~T)}{P(S)} P(T∣ S)=P(S)P(T)P(S∣ T)
T ∗ = arg max T P ( T ) P ( S ∣ T ) T^*=\arg\max_T P(T)P(S|~T) T∗=argTmaxP(T)P(S∣ T)
因此,统计翻译中的三个关键问题:
- 估计语言模型概率 p ( T ) p(T) p(T)
- 估计反翻译概率 p ( S ∣ T ) p(S|~T) p(S∣ T)。
- 高效搜索 T T T 使得 p ( T ) ⋅ p ( S ∣ T ) p(T)\cdot p(S | T) p(T)⋅p(S∣T) 最大
注:在这个任务中,似然函数也称为反翻译模型。
对位模型
我们引入一个隐变量 A = A ( S , T ) A=A(S,T) A=A(S,T),称为对位模型(alignment model),其代表的目标语言句子中的词与源语言句子中的词之间的对应关系。如下是对位模型的一个 case,

对于 S S S(长度为 m m m) 和 T T T(长度为 l l l),对位模型共有 2 l × m 2^{l\times m} 2l×m 种(指数级空间,因此如何找到合适的对位模型是一个挑战)。

注:
-
上式中 a 1 m a_1^m a1m 的意思是 a 1 : m a_{1:m} a1:m,即 a 1 m = a 1 a 2 ⋯ a m a_1^m=a_1a_2\cdots a_m a1m=a1a2⋯am
-
a i a_i ai 可以等于 0,表示不参与对齐,如下图。

此时, A = ( 1 , 5 , 6 , 2 , 0 , 4 ) . A=(1,5,6,2,0,4). A=(1,5,6,2,0,4).
基于短语的翻译模型
基于词的翻译模型的问题:
- 很难处理词义消岐问题
- 很难处理一对多、多对一和多对多的翻译问题
以短语为基本翻译单元!!
注:这里所说的短语指一个连续的词串 (n-gram),不一定是语言学中定义的短语 (phrase)。
如:I would like to
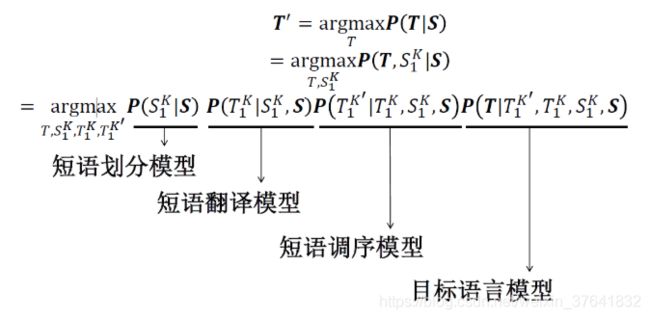
短语划分模型
- 目标:将一个词序列如何划分为短语序列
- 方法:一般假设每一种短语划分方式都是等概率的
剩下的三个核心模型:
- 短语翻译模型
- 短语调序模型
- 目标语言模型
短语翻译模型
- 如何学习短语翻译规则(分两步)
- 双语句对词语对齐
- 短语翻译规则抽取(抽取 corpus 中所有的短语)
- 如何估计短语翻译概率
一、如何学习短语翻译规则。
首先,使用 IBM 1-5 做双语句对(Bilingual sentence pairs)词语对齐,

短语翻译规则抽取:根据对齐一致性,抽取合法短语(可以在 O ( n 2 ) \mathcal O(n^2) O(n2) 时间内完成)。
什么是对齐一致性?即如下图中的红框,左右上下横冲不会撞到其他黑格。

二、如何估计短语翻译概率。
抽取完所有短语后,如何估计其概率?——相对频度(数数)。
短语翻译概率估计:4个翻译概率(最大似然)
- 正向、逆向短语翻译概率 p ( t ∣ s ) , p ( s ∣ t ) p(t|s),p(s|t) p(t∣s),p(s∣t)
- 正向、逆向词汇化翻译概率 p l e x ( t ∣ s ) , p l e x ( s ∣ t ) p_{lex}(t|s),p_{lex}(s|t) plex(t∣s),plex(s∣t)
计算例子(正向、逆向短语翻译概率)

短语调序模型
如何评估两个句子在语序上的差异(句子结构)?
两种常用方法:
- 距离跳转模型
- 分类模型
距离跳转模型
距离定义:
d = current begin − last end − 1 d=\text{current}_{\text{begin}} -\text{last}_{\text{end}}-1 d=currentbegin−lastend−1
即当前短语开始的位置 - 上一个短语结束的位置 - 1.
例子。

注:中文是源句子。
从左到右依次数 目标句子的短语,
+ 4 = 7 − 2 − 1 − 6 = 5 − 10 − 1 − 4 = 3 − 6 − 1 \begin{aligned} +4&=7-2-1\\ -6&=5-10-1\\ -4&=3-6-1 \end{aligned} +4−6−4=7−2−1=5−10−1=3−6−1
距离跳转模型是一种相对粗糙的方法,没有关注乱序的是哪些词。于是有接下来的分类模型的工作。
分类模型
分为三类:Monotone (M)、Swap (S)、Discontinuous (D)。

译文评估
BLEU:

其中, w n = 1 / N . w_n=1\Big/ N. wn=1/N.
B P = { 1 if c > r exp ( ( 1 − r ) / c ) if c ≤ r . BP=\begin{cases} 1\quad &\text{if }c>r\\ \exp\Big((1-r)/c\Big)\quad &\text{if }c\le r.\\ \end{cases} BP={ 1exp((1−r)/c)if c>rif c≤r.
其中 c c c 是机器译文的词数(长度), r r r 是参考译文的词数。
参考链接:
- https://blog.csdn.net/wwj_748/article/details/79686042
- https://blog.csdn.net/qq_30232405/article/details/104219396
常用的评测指标
主观评测:
- 流畅度
- 充分性;
- 语义保持性。
客观评测
-
句子错误率:译文与参考答案不完全相同的句子为错误句子。错误句子占全部译文的比率。
-
单词错误率 (Multiple Word Error Rate on Multiple Reference, 记作 mWER):分别计算译文与每个参考译文的编辑距离,以最短的为评分依据,进行归一化处理
-
与位置无关的单词错误率 (Position independent mWER, 记作 mPER ):不考虑单词在句子中的顺序
-
METEOR 评测方法
对候选译文与参考译文进行词对齐,计算词汇完全匹配、词干匹配、同义词匹配等各种情况的准确率 §、召回率 ® 和 F 平均值 -
BLEU 评价方法 [Papineni, 2002]:Bi-Lingual Evaluation Understudy, IBM
基本思想:将机器翻译产生的候选译文与人翻译的多个参考译文相比较,越接近,候选译文的正确率越高。
实现方法:统计同时出现在系统译文和参考译文中的 n n n 元词的个数,最后把匹配到的 n 元词的数目除以系统译文的 n n n 元词数目,得到评测结果。
BLEU 分值范围:0 ~ 1,分值越高表示译文质量越好,分值越小,译文质量越差。
-
NIST:对 BLEU 的改进。
基本思想:BLEU 评分公式中采用的 n 元语法同现概率的几何平均方法使评分值对于各种 n 元语法同现的比例具有相同的敏感性,但实际上,这种做法存在着潜在的矛盾,因为 n 值较大的统计单元出现的概率较低。因此,NIST 的研究人员提出了另外一种处理方法,就是用 n-gram 同现概率的算术平均值取代几何平均值。另外,如果一个 n n n 元词在参考译文中出现的次数越少,表明它所包含的信息量越大,那么,它对于该 n n n 元词就赋予更高的权重。
熵熵熵
自信息
I ( x i ) = − log p ( x i ) I(x_i)=-\log p(x_i) I(xi)=−logp(xi)
熵(自信息的期望)
H ( x ) = − ∑ x p ( x i ) log p ( x i ) H(x)=-\sum_x p(x_i)\log p(x_i) H(x)=−x∑p(xi)logp(xi)
联合熵(联合 = 逼到边缘 + 谈条件)
H ( x , y ) = − ∑ ∑ p ( x , y ) log p ( x , y ) = H ( x ) + H ( y ∣ x ) H(x,y)=-\sum\sum p(x,y)\log p(x,y)=H(x)+H(y|~x) H(x,y)=−∑∑p(x,y)logp(x,y)=H(x)+H(y∣ x)
条件熵,
H ( x ∣ y ) = − ∑ ∑ p ( x , y ) log p ( x ∣ y ) H(x|~y)=-\sum\sum p(x,y)\log p(x|~y) H(x∣ y)=−∑∑p(x,y)logp(x∣ y)
连锁规则,
P ( A , B , C , D ) = P ( A ) ⋅ P ( B ∣ A ) ⋅ P ( C ∣ A B ) ⋅ P ( D ∣ A B C ) P(A,B,C,D)=P(A)\cdot P(B|A)\cdot P(C|AB)\cdot P(D|ABC) P(A,B,C,D)=P(A)⋅P(B∣A)⋅P(C∣AB)⋅P(D∣ABC)
熵率,
相对熵(KL 距离),⽤于衡量两个概率分布的差距。当两个随机分布相同时,其相对熵为 0。当两个随机分布的差别增加时,其相对熵也增加。
D ( p ∣ ∣ q ) = ∑ p ( x ) log p ( x ) q ( x ) = ∑ p ( x ) log p ( x ) − ∑ p ( x ) log q ( x ) = − H ( p ( x ) ) − ∑ p ( x ) log q ( x ) ⏟ CE \begin{aligned} D(p~||~q) &=\sum p(x)\log\frac{p(x)}{q(x)}\\ &=\sum p(x)\log p(x)-\sum p(x)\log q(x)\\ &=-H(p(x)) \underbrace{-\sum p(x)\log q(x)}_{\text{CE}}\\ \end{aligned} D(p ∣∣ q)=∑p(x)logq(x)p(x)=∑p(x)logp(x)−∑p(x)logq(x)=−H(p(x))CE −∑p(x)logq(x)
交叉熵(Cross Entropy,CE),
H ( p , q ) = − ∑ p ( x ) log q ( x ) H(p,q)=-\sum p(x)\log q(x) H(p,q)=−∑p(x)logq(x)
困惑度,
P P L ( s e n t ) = p ( w 1 w 2 ⋯ w s ) − 1 S = 1 p ( w 1 w 2 ⋯ w s ) S where s is the length of sentence tested. PPL(sent)=p(w_1w_2\cdots w_s)^{-\frac 1 S}=\sqrt[S]{\frac{1}{p(w_1w_2\cdots w_s)}} \quad \text{where }\text{s is the length of sentence tested.} PPL(sent)=p(w1w2⋯ws)−S1=Sp(w1w2⋯ws)1where s is the length of sentence tested.
互信息:互信息是关于两个随机变量互相依赖程度的一种度量。互信息也称信息增益(IG),即在引入 y y y 后对 x x x 的不确定性消除了多少,或者说引入 y y y 后 为分类系统带来多少信息。
I ( x , y ) = H ( x ) − H ( x ∣ y ) = ∑ ∑ p ( x , y ) log p ( x , y ) p ( x ) p ( y ) I(x,y)=H(x)-H(x|~y)=\sum\sum p(x,y)\log\frac{p(x,y)}{p(x)p(y)} I(x,y)=H(x)−H(x∣ y)=∑∑p(x,y)logp(x)p(y)p(x,y)
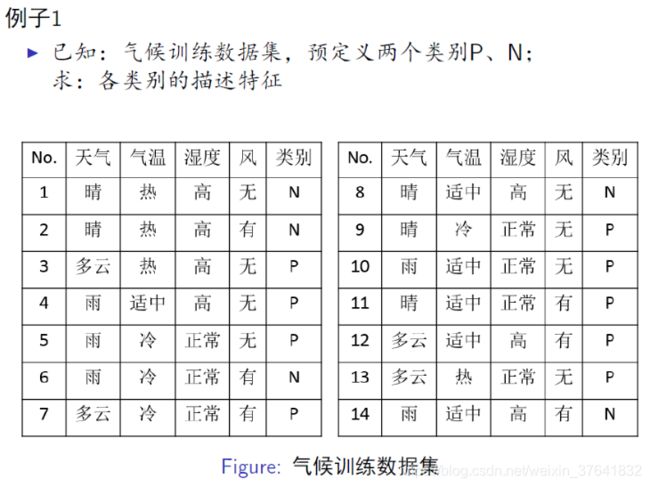
14 个样本中,9 个 P,5 个 N,我们可以使用熵度量这件事(类别属于 P 还是 N)的不确定性, H 0 = 0.94 b i t H_0=0.94 ~bit H0=0.94 bit 。此时的熵叫先验熵。
先对天气这个特征进行讨论,
5 个天气为晴的样本,其中 2P 3N,此时的熵叫后验熵, H 11 = 0.97 b i t H_{11}=0.97~bit H11=0.97 bit
4 个天气为多云的样本,其中 4P 0N,此时的熵叫后验熵, H 12 = 0 b i t H_{12}=0~bit H12=0 bit
5 个天气为雨的样本,其中 3P 2N,此时的熵叫后验熵, H 13 = 0.97 b i t H_{13}=0.97~bit H13=0.97 bit
则 H 1 = 5 / 14 H 11 + 4 / 14 H 12 + 5 / 14 H 13 = 0.69 b i t H_1=5/14~H_{11}+4/14~H_{12}+5/14~H_{13}=0.69~bit H1=5/14 H11+4/14 H12+5/14 H13=0.69 bit,此时的熵,是在知道天气这个特征后,对这件事(类别属于 P 还是 N)的不确定性的度量,称为条件熵。
我们在引入天气这个特征后,消除了多少不确定性呢? I 1 = H 0 − H 1 = 0.25 b i t I_1=H_0-H_1=0.25~bit I1=H0−H1=0.25 bit,被消除的那部分不确定性叫互信息(AKA. 信息增益)。
依次可求其它特征的 I 2 、 I 3 . . . I_2、I_3... I2、I3...
最后,可建立决策树,首先用哪个特征作为判断分支呢?互信息最大的那个特征!因为引入它消除了最多的不确定性。
CLS

HMM
HMM:观测状态序列概率计算
前向概率
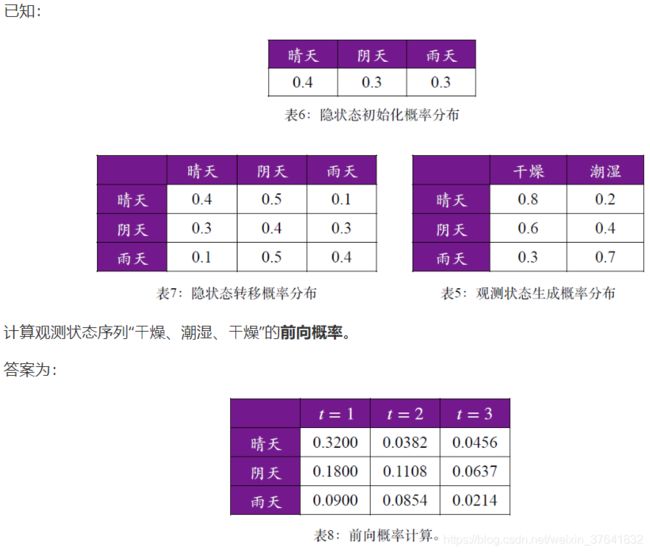
不妨以“0.0382”为例,计算
( 0.32 × 0.4 + 0.18 × 0.3 + 0.09 × 0.1 ) × 0.2 = 0.0382 (0.32\times 0.4+0.18\times 0.3+0.09\times 0.1)\times 0.2=0.0382 (0.32×0.4+0.18×0.3+0.09×0.1)×0.2=0.0382
…
根据表 8,可知观测状态序列“⼲燥、潮湿、⼲燥”的前向概率为(相加)

t = 3 t=3 t=3,初始化没什么好说的。
t = 2 t=2 t=2,以“0.65”为例,计算
KaTeX parse error: Expected '}', got '_' at position 31: …4}_{\text{trans_̲prob}}\times \u…
注意:计算 t = 2 t=2 t=2 时,emit_prob 计算的是 t = 3 t=3 t=3 时刻的 dry(而非 wet)。
…
根据表 10,可知观测状态序列“⼲燥、潮湿、⼲燥”的后向概率为(可看做 t = 0 t=0 t=0)

当 t = 2 t=2 t=2,先计算晴天。
max { 0.32 × 0.4 × 0.2 ; 0.18 × 0.3 × 0.2 ; 0.09 × 0.1 × 0.2 } = max { 0.0256 ; 0.0108 ; 0.0018 } = 0.0256 \begin{aligned} &\max\{0.32\times 0.4\times 0.2;\ 0.18\times 0.3\times 0.2;\ 0.09\times 0.1\times 0.2 \}\\ \\ =&\max\{0.0256;\ 0.0108;\ 0.0018\} =0.0256 \end{aligned} =max{ 0.32×0.4×0.2; 0.18×0.3×0.2; 0.09×0.1×0.2}max{ 0.0256; 0.0108; 0.0018}=0.0256
注:0.0256 后面的 1 表示该结点最优前继结点为 node 1(即晴天).
接着确定 t = 2 t=2 t=2 时的阴天,接着确定 t = 2 t=2 t=2 时的雨天。
当 t = 3 t=3 t=3,
0.064 × 0.3 × 0.2 = 0.00384 0.064\times 0.3\times 0.2=0.00384 0.064×0.3×0.2=0.00384
…
根据表 11,可知观测状态序列“⼲燥、潮湿、潮湿”对应的最优隐状态序列为“晴天、阴天、⾬天”,其概率为0.0134。(三条路径搜索)
概念题知识点
编辑距离:最少操作次数(插入、删除、替换、交换)
连词歧义:我和她的朋友。
问答式检索应用 ——Watson(沃森),DeepQA 问答系统是 Watson 实现的核心
命名实体识别:识别出待处理文本中七类命名实体(人名、机构名、地名、时间、日期、货币和百分比)
概括地说就是:专有名词和数字类名词。
命名实体消歧:确定上下文语境中的一个实体指称项所指向的真实世界实体。(e.g. Michael Jordan)
实体链接:给定实体指称项和它所在的文本,将其链接到给定知识库中的相应实体上。
关系抽取:自动识别由一对概念和联系这对概念的关系构成的相关三元组。
如:比尔盖茨是微软的 CEO。 → CEO( 比尔盖茨, 微软)
事件抽取:抽取事件及相关信息(事件触发词、事件元素)
语料库 (corpus) 是存放语言材料的仓库 ( 语言数据库)
基于语料库进行语言学研究,被称为语料库语言学
词汇知识库的四种语义关系:同义关系,反义关系,上下位关系,部分关系
对汉字而言四元语法效果会好一些
语言模型参数估计的两个重要点:训练语料,最大似然估计(MLE)
数据平滑方法:加一法,减值法 / 折扣法 (古德图灵估计),删除差值法
词是自然语言中能够独立运用的最小单位,是自然语言处理的基本单位。
自动词法分析就是利用计算机对自然语言的形态(morphology)进行分析,任务包括:
- 判断词的结构和类别;
- 词的形态还原(e.g. ate → \to → eat);
- 分词等。注:大部分基于词的分词方式采用的是生成式模型,而基于字的分词方式采用判别式模型。
词性或称词类(Part of Speech, POS)是词汇最重要的特性,是连接词汇到句法的桥梁。
不同语言的词法分析
- 曲折语(如,英语、德语、俄语等):用词的形态变化表示语法关系,一个形态成分可以表示若干种不同的语法意义,词根和词干与语词的附加成分结合紧密。
词法分析任务为:形态还原(无需分词,比如英语中的空格是词与词之间天然的间隔)。 - 分析语(也称孤立语,如: 汉语):词法分析的任务为:分词。
- 黏着语(如:日语等):词法分析的任务为:分词+形态还原。
词性标注
词性(part of speech, POS)标注(tagging) 的主要任务是:消除词性兼类歧义。在任何一种自然语言中,词性兼类问题都普遍存在。比如说:每次他都会在会上制造点新闻。
标注集的确定原则(标注集的规范)
不同语言中,词性划分基本上已经约定俗成。自然语言处理中对词性标记要求相对细致。
一般原则
- 标准性: 普遍使用和认可的分类标准和符号集;
- 兼容性: 与已有资源标记尽量一致,或可转换;
- 可扩展性:扩充或修改。
UPenn Treebank 的词性标注集确定原则
- 可恢复性:从标注语料能恢复原词汇或借助于句法信息能区分不同词类;
- 一致性:功能相同的词应该属于同一类;
- 不明确性:为了避免标注者在不明确的条件下任意决定标注类型,允许标注者给出多个标记(限于一些特殊情况)。
句法分析
任务:句法分析(syntactic parsing)的任务就是识别句子的句法结构(syntactic structure)。
句法分析本质是一个为句子的结构建模的过程,这里的结构是指句法结构。既然是为句子的句法结构建模,那么最主要的困难就是结构歧义。
句法分析类型:
- 短语结构分析(Phrase parsing)
- 完全句法分析(Full parsing)
- 局部句法分析(Partial parsing)
- 依存句法分析(Dependency parsing)
短语结构分析
目标:实现高正确率、高鲁棒性(robustness)、高速度的自动句法分析过程。
困难:
- 自然语言中存在大量的复杂的结构歧义(structural ambiguity)。
- 英语中的结构歧义随介词短语组合个数的增加而不断加深的,这个组合个数我们称之为卡特兰数(Catalan number)。
基本方法和开源的句法分析器:
-
基于 CFG 规则的分析方法:
- 线图分析法(chart parsing):见 9.3 节
- CYK 算法:见 9.4 节
- Earley(厄尔利)算法
- LR 算法 / Tomita 算法……
- Top-down: Depth-first/ Breadth-first
- Bottom-up
-
基于 PCFG 的分析方法(引入概率)
依存句法分析
1970 年计算语言学家 J. Robinson 在论文《依存结构和转换规则》中提出了依存语法的 4 条公理:
-
一个句子只有一个独立的成分;
-
句子的其他成分都从属于某一成分;
-
任何一成分都不能依存于两个或多个成分;
-
如果成分 A 直接从属于成分 B,而成分 C 在句子中位于 A 和 B 之间,那么,成分 C 或者从属于 A,或者从属于 B,或者从属于 A 和 B 之间的某一成分。
这 4 条公理相当于对依存图和依存树的形式约束为:
- 单一父结点 (single headed)
- 连通 (connective)
- 无环 (acyclic)
- 可投射 (projective)
由此来保证句子的依存分析结果是一棵有“根 (root) ”的树结构。
基本翻译方法
- 直接转换法
- 基于规则的翻译方法
- 优点:可以较好地保持原文的结构
- 缺点:规则。。
- 基于中间语言的翻译方法
- 优点:中间语言的设计可以不考虑具体的翻译语言对,因此,该方法尤其适合多语言之间的互译。
- 弱点:如何定义和设计中间语言的表达方式,以及如何维护并不是一件容易的事情,中间语言在语义表达的准确性、完整性等很多方面,都面临若干困难。
- 基于语料库的翻译方法
- 基于事例的翻译方法
- 优点:不要求源语言句子必须符合语法规定,翻译机制一般不需要对源语言句子做深入分析。
- 弱点:句子之间的相似性?第一次出现的句子?当事例库过大,检索效率?
- 统计翻译方法(SMT)
- 神经网络机器翻译(NMT)
- 基于事例的翻译方法
文本自动摘要:利用计算机按照某类应用自动地将文本(或文本集合)转换生成简短摘要的一种信息压缩技术。
要求:信息量足、覆盖面广、冗余度低和可读性高。
摘要方法:抽取式摘要、压缩式摘要、理解式摘要
文本摘要中消除冗余句子的方法是 CSIS, MMR
语义网络是一种由概念和关系构成的图结构的知识表示模型。强调的是认知模型。
语义网是为将互联网建设为以语义互联的海量分布式数据库的技术框架,强调的是标准化和体系化,是对互联网数据进行知识化的工程规范。
知识图谱可以看做是语义网技术框架在大规模知识库构建方面的一个工程实现,是一类使用语义网技术标准实现语义网络认知模型的知识工程产品集合。
知识图谱:不仅包含了具体的实例知识数据,更包括了对知识数据的描述和定义,这部分对数据进行描述和定义的“元”数据被称为知识体系(Schema)或者本体(Ontology)。
知识建模就是知识体系构建
- 知识体系:对概念的分类、概念属性的描述以及概念之间相互关系的定义。
- 完全自动构建知识体系还难以达到,目前主要依赖人机协同。
本体 (Ontology) 通过对于概念 (Concept)、术语 (Terminology) 及其相互关系 (Relation, Property) 的规范化 (Conceptualization) 描述,勾画出某一领域的基本知识体系和描述语言
语义网络
语义网络通过由概念和语义关系组成的有向图来表达知识、描述语义。
语义网络各概念之间的关系(边表示关系),主要由 IS-A,PART-OF, IS, HAVE, BEFORE,LOCATED-ON 等谓词表示。
在语义网络中,
- 内涵是指词本身的意义,是对词代表的概念描述;
- 外延是指词所指代的物体。
问题:如何在语义网络中表示和区分词的内涵和外延?—— 词义消歧。
话题链 (topic chain):一组以名词回指(同物不同名)、**代词回指(如其)和零形回指(省略但存在)**形式的话题连接起来的小句或句子。
回指:一个词或短语在语篇中用于(回)指代同一语篇中的另一个词或短语的概念。

语言模型的自适应方法有:
- 基于缓存的语言模型(在文本中刚刚出现过的一些词在后边的句子中再次出现的可能性往往较大);
- 基于混合方法的语言模型(由于大规模训练语料本身是异源的,来自不同领域的语料无论在主题方面,还是在风格方面,, 或者两者都有一定的差异,而测试语料一般是同源的,因此,为了获得最佳性能,语言模型必须适应各种不同类型的语料对其性能的影响);
- 基于最大熵的语言模型(通过结合不同信息源的信息构建一个语言模型。每个信息源提供一组关于模型参数的约束条件,在所有满足约束的模型中,选择熵最大的模型)
实现 CRFs 需要解决三个问题:特征选取,参数训练,解码
参考
* https://blog.csdn.net/yuanninesuns/article/details/110481479