【front-end】Unified Mandarin TTS Front-end Based on Distilled BERT Model
中文TTS前端一般由3个主要部分组成:文本正则化、G2P(中文的难点主要在多音字消歧)、韵律边界预测。本文应用预训练语言模型BERT提取特征,将多音字消歧任务和韵律边界任务联合训练,得到了一个可以同时进行多音字消歧及韵律边界预测的模型。同时应用了蒸馏方法,对bert进行压缩,得到了TinyBERT,模型大小压缩至原BERT的25%,并效果相当。
模型结构
如下图所示,模型由语言模型(BERT or TinyBERT)+ 多音字预测层以及韵律边界预测层组成。
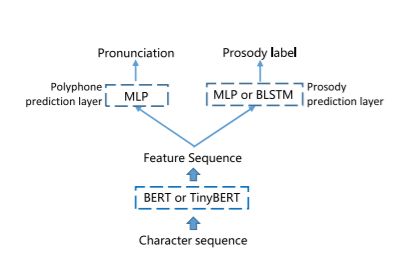
预训练的BERT/TinyBERT
字符级别的BERT,具体用了多少预料预训练文中没有给出。(猜测可能是用网上开源的ChineseBERT?)
多音字消歧
多音字消歧同时计算了一句中的多个多音字的loss并按照多音字的个数求平均。如公式所示:
L poly = − 1 ∣ W x ∣ ∑ ω ∈ W x ∑ c 1 { c = k ω } × log y c \mathcal{L}_{\text {poly }}=-\frac{1}{\left|W^{x}\right|} \sum_{\omega \in W^{x}} \sum_{c} \mathbb{1}\left\{c=k_{\omega}\right\} \times \log y_{c} Lpoly =−∣Wx∣1ω∈Wx∑c∑1{ c=kω}×logyc
k ω k_{\omega} kω表示true label, ∣ W x ∣ \left|W^{x}\right| ∣Wx∣表示该句中包含的多音字的个数。
韵律预测
依然是交叉熵loss,分类分为4类:I(非边界) B1(#1 韵韵律词边界)B2(#2 韵律短语边界) B3(#3 语调短语边界)。
多任务联合训练
L global = α 1 L poly + α 2 L prosody \mathcal{L}_{\text {global }}=\alpha_{1} \mathcal{L}_{\text {poly }}+\alpha_{2} \mathcal{L}_{\text {prosody }} Lglobal =α1Lpoly +α2Lprosody
α 1 \alpha_{1} α1, α 2 \alpha_{2} α2是超参(把两个loss调到一个scale上)。
既有多音字标注又有韵律边界标注的数据是比较少的,标注起来他也比较昂贵。因此本文采用了仅有多音字标注、仅有韵律边界标注的数据,仅会更新带label的任务相关的参数,一个batch里混有仅有多音字标注的以及仅有韵律边界标注的数据。
TinyBERT的蒸馏
从两个非显式的表达蒸馏BERT,分别是MHA的attention matrix以及经过MHA+FFN处理后的Hidden states,因此蒸馏的Loss也分为两部分:
L attn = 1 h ∑ i = 1 n MSE ( A i S , A i T ) \mathcal{L}_{\text {attn }}=\frac{1}{h} \sum_{i=1}^{n} \operatorname{MSE}\left(\mathbf{A}_{i}^{S}, \mathbf{A}_{i}^{T}\right) Lattn =h1i=1∑nMSE(AiS,AiT)
L embed = MSE ( H S W h , H T ) \mathcal{L}_{\text {embed }}=\operatorname{MSE}\left(\mathbf{H}^{S} \mathbf{W}_{h}, \mathbf{H}^{T}\right) Lembed =MSE(HSWh,HT)
蒸馏的步骤如下图所示:
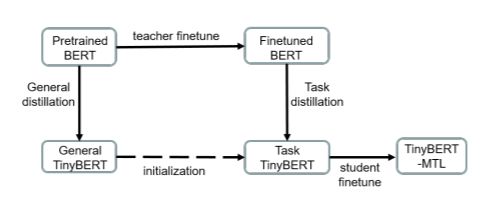
(1) pre-trained BERT distill TinyBERT, 得到general TinyBERT
(2) 使用前端数据finetune pre-trained BERT, 得到Finetuned BERT
(3) 使用Finetuned BERT distill general TinyBERT, 得到 Task TinyBERT
(4) finetune task BERT
实验
数据和实验配置
多音字消歧:34w+条, 661个多音字。
韵律预测:23w+条。
训练验证集划分比例9:1,多音字消歧衡量指标采用了ACC和SENT ACC,韵律预测衡量指标采用了PW/PPH/IPH的F1得分。
模型配置:Chinese BERT与原始的base BERT结构一模一样, 12层768节点,TinyBERT 4层312节点。MLP采用3层 512节点,BLSTM是256节点。
对比实验
多音字消歧对比系统:
WFST-based G2P:[1]中开源工具,在WFST中应用了ngram,完成G2P.。
BLSTM: G2PM模型,应用了character embedding 以及 词性标注,由一层BLSTM 两层全连接组成[2]。
BERT-polyphone: BERT仅外接多音字消歧任务。
韵律预测对比系统:
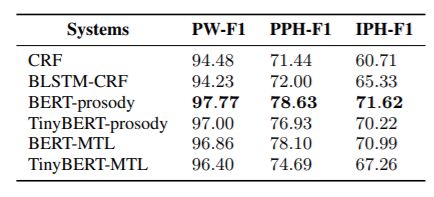
CRF:crf++
BLSTM-CRF:[3]
BERT-prosody: BERT仅外接韵律预测任务。
BERT-MTL: Multitask learning的BERT。
TniyBERT-MTL: Multitask learning的TinyBERT。
实验结果
-
多音字消歧效果对比

-
韵律边界预测效果对比
-
韵律预测的prediction layer结构探究

用BLSTM和MLP效果很相近。 -
多音字消歧prediction layer结构探究
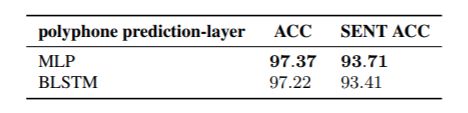
MLP略好。 -
模型大小及预测时间
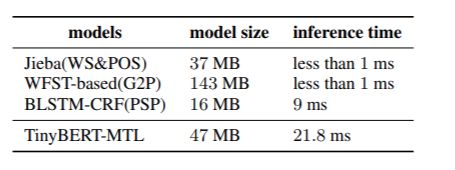
句子长度为64,使用推测时间为20ms+,延时可接受。
[1]J. R. Novak, N. Minematsu, and K. Hirose, “Phonetisaurus:
Exploring grapheme-to-phoneme conversion with joint n-gram
models in the wfst framework,” Natural Language Engineering, vol. 22, no. 6, pp. 907–938, 2016
[2] K. Park and S. Lee, “g2pm: A neural grapheme-to-phoneme conversion package for mandarinchinese based on a new open benchmark dataset,” arXiv preprint arXiv:2004.03136, 2020
[3]H. Pan, X. Li, and Z. Huang, “A mandarin prosodic boundary prediction model based on multi-task learning,” Proc. Interspeech 2019, pp. 4485–4488, 2019.