NLP汉语自然语言处理原理与实践 7 建设语言资源ku
这里介绍了两类语料库:语法语料库和语义知识库。它们都可以作为算法的训练资源。除此之外,还介绍一种新兴的大规模语料库:百科知识库。目前对它的研究还处于初级阶段。虽然在某些方面获得了很大的突破,但是在自动语义解析方面仍面临诸多的难题。
7.1 语料库概述
语料库的简史
布朗语料库:1961年
朗文语料库:80年代,分别为:朗文、兰开斯特英语语料库(LLELC)、朗文口语语料库(LSC)、朗文英语学习者语料库(LCLE),其建设的主要目标之一是编纂英语学习词典,为外国人学习英语提供服务。
语言资源联盟(LDC):1992年,美国宾夕法尼亚大学,它的目的是构建、收集和发布用于研发的语音和文本数据库、词典及其他资源。宾州树库(UPenn Tree Bank,PTB),完成了近300万个词的英语句子的句法结构标注。
中文树库(CTB):2000年
搜狗互联网语料库:2008版,可免费下载。1.3亿个原始网页。
国家现代汉语语料库:1993年开始建设。
PFR语料库:由北京大学计算语言所和富士通合作,以2700万字的1998年《人民日报》为源语料,手工加工、标注建立的语料库,加工项目包括词语切分、词性标注、专有名词标注,并制定出《现代汉语语料库加工手册--词语切分和词性标注》
语言资源库的分类
常见的语料库类别大概有两种:语法语料库和语义知识库
语法语料库:常作为NLP的基础资源,用于学习和训练NLP模型。大多来自影响面较大的大众媒体、书籍文献等语料,具有广泛性和代表性;语料的选择都经过精挑细选,构成上要求具有典型性,能够涵盖绝大多数的语言现象。例如分词语料需包含足够的高频、常用词汇;句法树库必须含大多汉语句型。最终训练成语言模型,因此对标注精度要求高。在开发过程中不可避免地需要大量人工标注或人工校对工作,容量一般不会超过1GB。
语义知识库:早期手工建立的语义知识库,如HowNet、WordNet语义知识库。近些年逐渐流行起来的百科知识库。由于Word2Vec算法的成功,不依赖于手工标注,语义相似度正确率很高。百科知识库的建设目标是为NLP语义计算提供大规模、全覆盖的语义知识资源,有条件地兼顾推理运算的支持。容量比较大,最小的中文维基百科也有30GB
语料库的设计实例:国家语委语料库
用户可以将器作为自主开发语料库的一个范本
(1)选材的内容分布:人文与社科类、自然科学类、综合类。
(2)选材的历时性分布:1919-2002
(3)选材的抽样
(4)开发资源:http://www.aihanyu.org/cncorpus/index.aspx
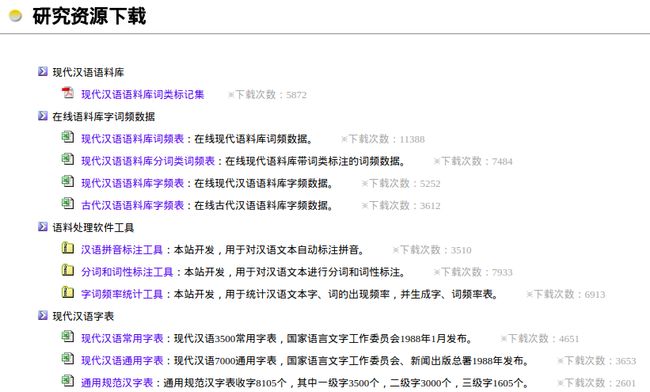
在构建自己的语料库时,使用下面的程序资源,特别是在小规模的分词、词性标注、拼音标注、字频、词频统计处理时,这些应用程序能发挥高精度、高速度的作用。
语料库的层次加工:人工标注和自动标注
在实践中,不同项目有领域专业性,构建自己的语法语料库。P322
7.2 语法语料库
在构建NLP系统时,常要用到一套高精度的NLP算法库,以及一套高质量的、广为接受的基础语料资源。
中文分词语料库
作为基础语料使用的中文分词库(含词性标注)在网上能找到的有很多。例如,LANCAST中文语料库、浙大汉语译文语料库、搜狗mini语料库等。最常用的中文分词语料库有两个:一个是PFR,另一个是MSR语料库。
一个基于CRF++的中文分词器Nlpbamboo,已经将PFR的1998年1月的语料训练成CRF++的模型库。http:www.threedweb.cn/thread-1319-1-1.html, http://www.threedweb.cn/thread-1591-1-1.html
MSR语料库http://www.threedweb.cn/thread-1593-1-1.html,仅对词汇做了切分。
中文分词的测评
包括分词正确率、切分速度、词典或语言模型的大小、功能完备性、易扩充性和可维护性6个方面。
宾州大学CTB简介
对源文件进行最初的解析,提取句法树来,然后保存到数据库中。
7.3 语义知识库
语义知识库是现代语义网和百科知识库的前身。经历义原抽取、分类体系的规划、属性和属性值的界定。它是现代语义理论在实践应用的产物。使用了义素分析法、本体论等语义学甚至哲学的理论。知识库基本可以满足语义辨析的需要。后来,W3C组织公布的语义网规范,从理论上来看,两者之间一脉相承,差异不大。其中HowNet中的实体与OWL本体的概念相对应,事件与Property相对应,属性与Attribute相对应。唯一不同的是,语义网将知识库的构建从领域知识扩展到了整个互联网。
因此,通过对HowNet的深入研究,读者可以了解到如何构建一个汉语通用知识库的全过程,有助于读者从一个整体上把握一个知识库的完整构建原理和步骤。
知识库与HowNet简介
WordNet:以词汇为基础的英语词汇知识库,试图建立一个模仿人脑词汇组织原则的词汇网络,在构建中利用心理学的发现和新历词典的研究成果。
HowNet:以汉语和英语的词语所代表的概念为描述对象,以揭示概念与概念之间,以及概念所具有的属性之间的关系为基本内容的常识知识库。中科院董振东先生构建知网的目的是建立一个常识性的知识体系或语言以外的知识体系。
1998年董振东提出:知识被假定为一个系统,它包含一个基于关系和基于推理的系统。在基于关系的系统中有两种类型的关系:一种是概念特征之间的关系;另一种是事件之间的关系。概念由两部分组成,即概念核心和与概念相关的特征。推理系统是基于关系工作的,有两类的推理:一种是基于概念特征的关系,其中典型的表现是替代;另一种是基于事件的关系。这种关系可以典型地看作”who-done-it“类的事件。
虽然目前多用word2Vec计算出的语义向量表示词汇,并计算词汇间的语义相似度。
发掘义原:义素分析的理论是基于还要论思想的。中文语言在字面水平就表现出相当多的语义信息。
语义角色:被定义为知网的内在关系,其中事件的参与者有真实的或想象的上下文语境,这也被称为主题角色或深层格。
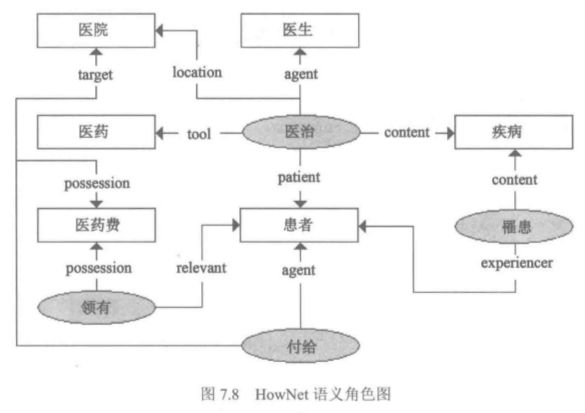
带箭头的线段上的标签就是语义角色,知网使用了91个语义角色其分为两类:主要语义角色和周边语义角色。
分类原则与事件分类:HowNet的分类系统很有特点,它不是机械地按照静态实体和动态事件进行分类,而是将构成静态实体和动态事件的所有组件,包括属性、属性值、时间等作为顶层的分类根节点,可以看到即使在当时就已经渗透了面向对象的设计思想。
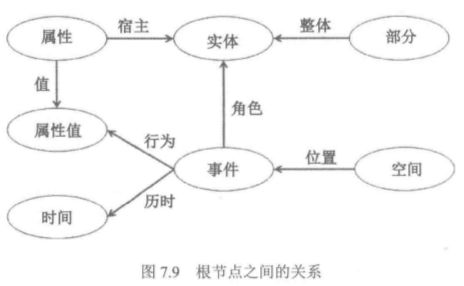
HowNet中有812个事件类,可分为内在事件和外在事件。
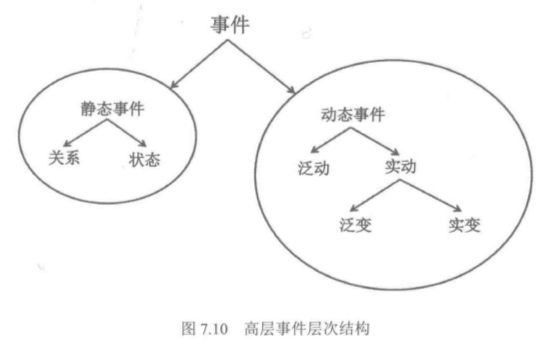
实体分类:知网的实体分类包含的万物、部件、时间和空间是其顶级节点的义原。有151个实体分类。

属性与分类:包含247个义原类,并且它们被划分为7个子类。
相似度计算和实例:概念相似性计算器(CRC)
7.4 语义网与百科知识库
HowNet的发布一度成为人工构建汉语知识库的标准。近些年,人们不满足与中小规模的人工知识库的构建,而是转向大规模的、自动知识库的构建理论方向。本节以维基百科为例,从理论到实践介绍了语义网理论和目前较大规模的百科知识库。
语义网理论介绍

第三层:RDF层:资源描述框架(Resource Description Framework, RDF)是一种用于描述万维网资源信息的通用框架,如网页的内容、作者及被创建和修改的日期等。RDF本质上是一种数据模型,由主体,谓词或属性,客体或属性值所构成的三元组来描述资源的元数据。RDF的定义很像自然语言中单句的最基本结构--SVO。所以,RDF天生就具有很强的语义表达能力。它可用于表达其他元数据,如图书的节目信息、自然语言句子、以及生物、化学等许多领域表达元数据。可以说,RDF已经成为知识表达的通用形式。

RDF的基本数据模型包括资源、属性及陈述,确切地说,陈述是资源和属性的一种组合。
资源:一切能够使用RDF表示的对象都称为资源,包括网络上的所有信息、虚拟概念和现实事物等。资源用唯一的URI来表示,不同的资源拥有不同的URI,通常使用的URL只是它的一个子集。
属性:用来描述资源的特征或资源间的关系。每个属性都有其意义,用于定义资源的属性值、描述属性所属的资源形态,以及与其他属性或资源的关系。
陈述:一条陈述包含三个部分,通常称为RDF三元组<主体、属性、客体>。其中,主体是被描述的资源,用URI表示。客体表示主体在该属性上的取值,可以是另外一个资源(由URI表示)或者一个文本。

最后,生成机器可读的XML格式的RDF,代码如下:
第四层:本体层。目前,本体的构建仍旧依赖于手工处理,大规模的本体自动构建距离还比较遥远,建议参考W3C组织提供的相关规范和教程文档。
第5~7层:逻辑层、验证层和信任层。逻辑层在前面各层的基础上进行逻辑推理操作。验证层根据逻辑陈述进行验证,以得到结论。信任层是语义网安全的组成部分,与加密不同的是,该层主要负责发布语义网所能支持的信任评估。目前第6层和第7层正处于设想阶段。
由于RDF三元组是语义网数据表示的基础。要实现从万维网到语义网的转变,构建海量的RDF数据集是一项基础性工作。因此,如何自动化地从现有的Web内容中抽取出符合语义网规范的语义内容是语义网走向实用化面临的难题之一。
把句子映射为RDFs的格式。只要句法解析系统的精度达到商业化的要求。
维基百科知识库
https://zh.wikipedia.org/zh-cn/Wikipedia下载资源
DBPedia抽取原理:是语义网在RDF和OWL层的应用范例,它能从维基百科的词条里抽取出结构化的数据,强化了维基百科在语义方面的搜寻功能,并将用户的数据集连接到维基百科。通过专门的语义分析和提取技术,使维基百科的庞杂知识有了许多创新而有趣的应用,如手机版本、地图整合、多面向搜寻、关系查询、文件分类与标注等
