Apollo无人驾驶课程笔记 第四课-感知
1. 感知简介
感知系统中使用了大量的计算机视觉的技术。对于目标识别目标检测来说,目前工业界用的比较多的是CNN,也就是卷积神经网络(Convolutional Neural Network)。
2. Sebastian 介绍感知
略
3. 计算机视觉
计算机不能像人类那样理解图像,图像在计算机的世界里只是一堆数值。
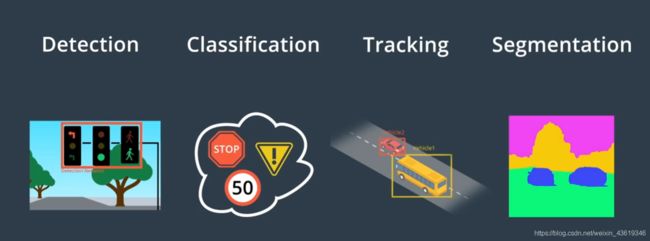
无人驾驶中的感知任务主要有四个:检测、分类、跟踪和语义分割。
- 检测是指找出物体在环境中的位置;分类是指明确对象是什么;
- 分类是指明确对象是什么;
- 跟踪是指随时间的推移观察移动的物体(例如其他车辆、自行车和行人);
- 语义分割是指将图像中的每个像素与语义类别进行匹配(如道路、汽车或天空)。
我们可以将分类作为研究计算机视觉一般流程的例子。图像分类器是一种将图像作为输入并输出标识改图像的”标签"或者“类别"的算法。
例如,交通标志分类器查看停车标志并识别它是停车标志、让路标志、限速标志还是其他类型的标志。

分类器甚至可以识别行为,比如一个人是在走路还是跑步。
分类器有很多种,但它们都包含一系列类似的步骤。
- 首先,计算机接受摄像头等成像设备的输入,这通常被捕获为图像或一系列图像。
- 然后通过预处理发送每个图像,预处理对每个图像进行了标准化处理,常见的预处理步骤包括调整图像大小或旋转图像,或将图像从一个色彩空间转化为另一个色彩空间,例如从全彩转化为灰度。预处理可以帮助我们的模型更快的处理和学习图像。
- 接下来就是提取特征。
- 最后,这些特征被输入到分类模型中,通过图像特征来选择类别,输出结果。

4. 摄像头图像
在计算机的世界里,图像就是数值矩阵。对于图像的处理,说白了就是对于矩阵的处理。(可见数学的重要性呀!
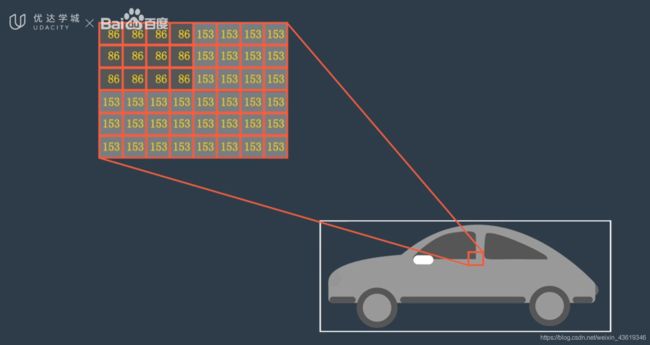
这是一个二维的灰度图像示例:

对于彩色图像,可以看成是一个深度为3的二维色层的叠加:
5. LiDAR 图像
感知扩展到传感器,而不仅仅是摄像头,激光雷达传感器创建环境的点云表征,提供了难以通过摄像头提供的图像信息(例如距离和高度)。
下图是一个典型的激光雷达点云图像:激光雷达通过发射光脉冲来检测汽车周围的环境。蓝色点表示反射激光脉冲的物体,中间的黑色部分则是无人车本身占据的空间。
这些点云可以告诉我们关于物体的很多信息,例如其形状和表面纹理。通过对点进行聚类和分析,这些数据提供了足够的对象检测、跟踪和分类信息。下图是一个典型的在点云上的检测和分类结果:红色的代表行人,绿色的代表其他车辆。
6. 机器学习
机器学习可以分成下面几种类别:
- 监督学习从给定的训练数据集中学习出一个函数,当新的数据到来时,可以根据这个函数预测结果。监督学习的训练集要求是包括输入和输出,也可以说是特征和目标。训练集中的目标是由人标注的。常见的监督学习算法包括回归分析和统计分类。
监督学习和非监督学习的差别就是训练集目标是否人标注。他们都有训练集 且都有输入和输出
- 无监督学习与监督学习相比,训练集没有人为标注的结果。常见的无监督学习算法有生成对抗网络(GAN)、聚类。
- 半监督学习介于监督学习与无监督学习之间。
- 增强学习机器为了达成目标,随着环境的变动,而逐步调整其行为,并评估每一个行动之后所到的回馈是正向的或负向的。
具体的机器学习算法有:
构造间隔理论分布:聚类分析和模式识别
人工神经网络
决策树
感知器
支持向量机
集成学习AdaBoost
降维与度量学习
聚类
贝叶斯分类器
构造条件概率:回归分析和统计分类
高斯过程回归
线性判别分析
最近邻居法
径向基函数核
通过再生模型构造概率密度函数:
最大期望算法
概率图模型:包括贝叶斯网和Markov随机场
Generative Topographic Mapping
近似推断技术:
马尔可夫链
蒙特卡罗方法
变分法
最优化:大多数以上方法,直接或者间接使用最优化算法。
7. 神经网络
典型的人工神经网络具有以下三个部分:
- 结构(Architecture)结构指定了网络中的变量和它们的拓扑关系。例如,神经网络中的变量可以是神经元连接的权重(weights)和神经元的激励值(activities of the neurons).
- 激励函数(Activation Rule)大部分神经网络模型具有一个短时间尺度的动力学规则,来定义神经元如何根据其他神经元的活动来改变自己的激励值。一般激励函数依赖于网络中的权重(即该网络的参数)
- 学习规则(Learning Rule)学习规则指定了网络中的权重如何随着时间推进而调整。这一般被看做是一种长时间尺度的动力学规则。一般情况下,学习规则依赖于神经元的激励值。它也可能依赖于监督者提供的目标值和当前权重的值。例如,用于手写识别的一个神经网络,有一组输入神经元。输入神经元会被输入图像的数据所激发。在激励值被加权并通过一个函数(由网络的设计者确定)后,这些神经元的激励值被传递到其他神经元。这个过程不断重复,直到输出神经元被激发。最后,输出神经元的激励值决定了识别出来的是哪个字母。
8. 反向传播算法
基本结构
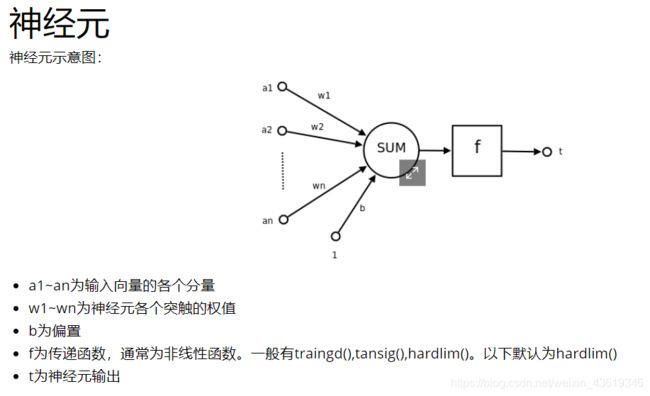
一种常见的多层结构的前馈网络(Multilayer Feedforward Network)由三部分组成,
- 输入层(Input layer),众多神经元(Neuron)接受大量非线形输入讯息。输入的讯息称为输入向量。
- 输出层(Output layer),讯息在神经元链接中传输、分析、权衡,形成输出结果。输出的讯息称为输出向量。
- 隐藏层(Hidden
layer),简称“隐层”,是输入层和输出层之间众多神经元和链接组成的各个层面。隐层可以有一层或多层。隐层的节点(神经元)数目不定,但数目越多神经网络的非线性越显著,从而神经网络的强健性(robustness)(控制系统在一定结构、大小等的参数摄动下,维持某些性能的特性)更显著。习惯上会选输入节点1.2至1.5倍的节点。
这种网络一般称为感知器(对单隐藏层)或多层感知器(对多隐藏层),神经网络的类型已经演变出很多种,这种分层的结构也并不是对所有的神经网络都适用。
学习过程
通过训练样本的校正,对各个层的权重进行校正(learning)而建立模型的过程,称为自动学习过程(training algorithm)。具体的学习方法则因网络结构和模型不同而不同,常用反向传播算法(Backpropagation/倒传递/逆传播,以output利用一次微分Delta rule(英语:Delta rule)来修正weight)来验证。
前馈:
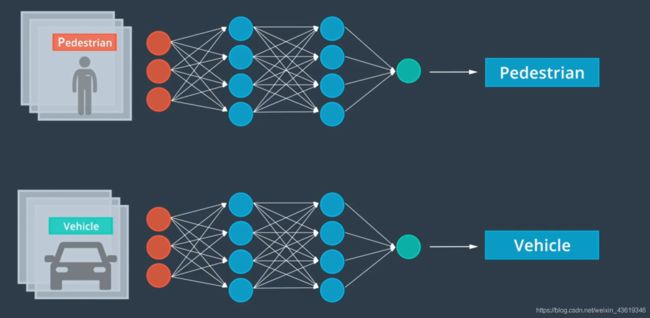
误差测定: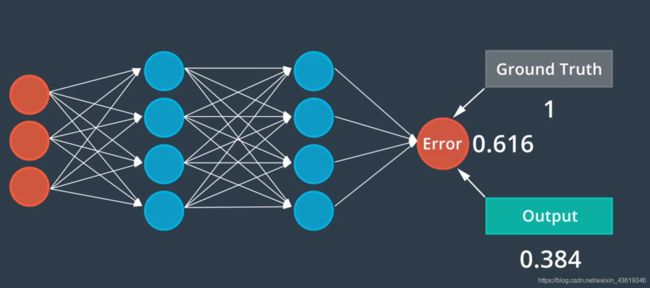
反向传播:
9. 卷积神经网络
wiki百科的相关词条
卷积神经网络由一个或多个卷积层和顶端的全连通层(对应经典的神经网络)组成,同时也包括关联权重和池化层(pooling layer)。这一结构使得卷积神经网络能够利用输入数据的二维结构。与其他深度学习结构相比,卷积神经网络在图像和语音识别方面能够给出更好的结果。这一模型也可以使用反向传播算法进行训练。相比较其他深度、前馈神经网络,卷积神经网络需要考量的参数更少,使之成为一种颇具吸引力的深度学习结构。
“卷积神经网络”表示在网络采用称为卷积的数学运算。卷积是一种特殊的线性操作。卷积网络是一种特殊的神经网络,它们在至少一个层中使用卷积代替一般矩阵乘法。
结构
卷积层
卷积层是一组平行的特征图(feature map),它通过在输入图像上滑动不同的卷积核并执行一定的运算而组成。此外,在每一个滑动的位置上,卷积核与输入图像之间会执行一个元素对应乘积并求和的运算以将感受野内的信息投影到特征图中的一个元素。这一滑动的过程可称为步幅 Z_s,步幅 Z_s 是控制输出特征图尺寸的一个因素。卷积核的尺寸要比输入图像小得多,且重叠或平行地作用于输入图像中,一张特征图中的所有元素都是通过一个卷积核计算得出的,也即一张特征图共享了相同的权重和偏置项。
线性整流层
线性整流层(Rectified Linear Units layer, ReLU layer)使用线性整流(Rectified Linear Units, ReLU) f ( x ) = max ( 0 , x ) {\displaystyle f(x)=\max(0,x)} f(x)=max(0,x)作为这一层神经的激励函数(Activation function)。它可以增强判定函数和整个神经网络的非线性特性,而本身并不会改变卷积层。
事实上,其他的一些函数也可以用于增强网络的非线性特性,如双曲正切函数 f ( x ) = tanh ( x ) {\displaystyle f(x)=\tanh(x)} f(x)=tanh(x), f ( x ) = ∣ tanh ( x ) ∣ {\displaystyle f(x)=|\tanh(x)|} f(x)=∣tanh(x)∣,或者Sigmoid函数 f ( x ) = ( 1 + e − x ) − 1 {\displaystyle f(x)=(1+e^{-x})^{-1}} f(x)=(1+e−x)−1。相比其它函数来说,ReLU函数更受青睐,这是因为它可以将神经网络的训练速度提升数倍,而并不会对模型的泛化准确度造成显著影响。
池化层
完全连接层
最后,在经过几个卷积和最大池化层之后,神经网络中的高级推理通过完全连接层来完成。就和常规的非卷积人工神经网络中一样,完全连接层中的神经元与前一层中的所有激活都有联系。因此,它们的激活可以作为仿射变换来计算,也就是先乘以一个矩阵然后加上一个偏差(bias)偏移量(向量加上一个固定的或者学习来的偏差量)。
损失函数层
损失函数层(loss layer)用于决定训练过程如何来“惩罚”网络的预测结果和真实结果之间的差异,它通常是网络的最后一层。各种不同的损失函数适用于不同类型的任务。例如,Softmax交叉熵损失函数常常被用于在K个类别中选出一个,而Sigmoid交叉熵损失函数常常用于多个独立的二分类问题。欧几里德损失函数常常用于标签取值范围为任意实数的问题。
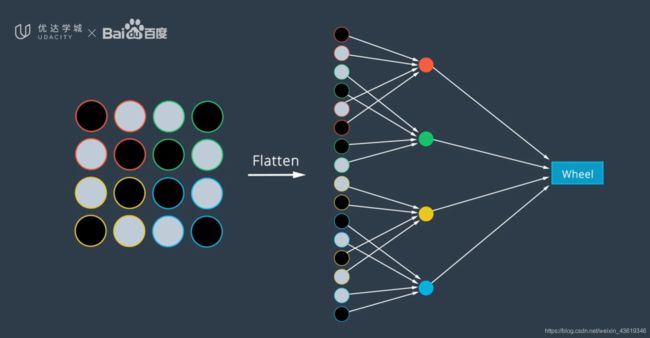
卷积示例:

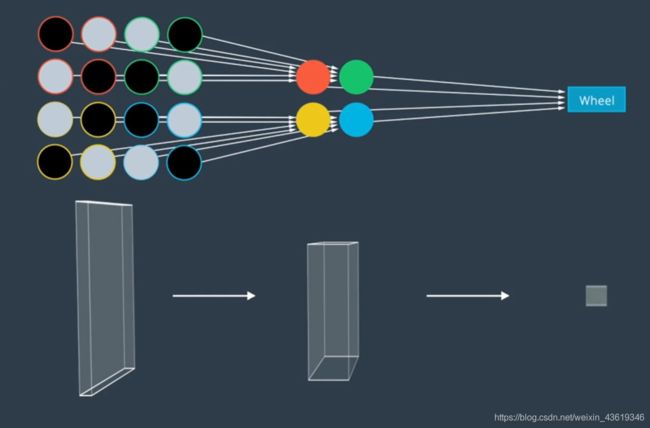
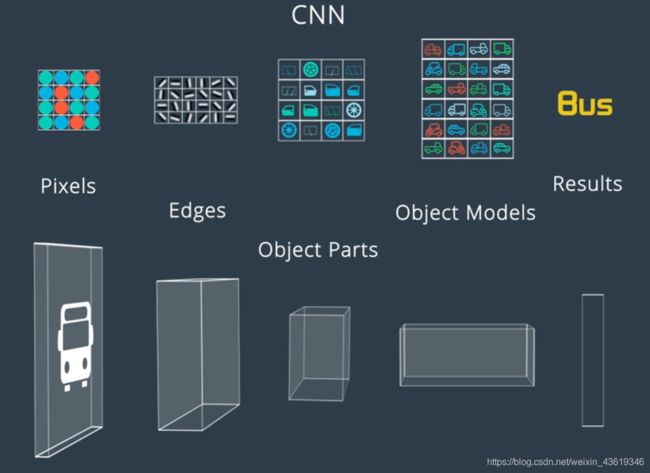
10. 检测与分类
利用CNN来进行感知任务的最基本需求,检测和分类不同的事物。
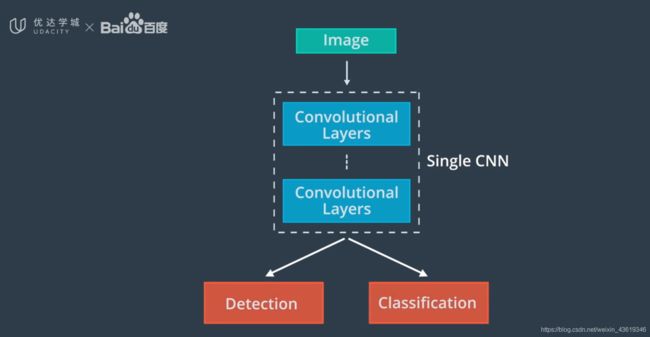
这其中的经典结构有:R-CNN及其变体的Fast R-CNN和Faster R-CNN。YOLO和SSD是具有类似形式的不同体系结构。
11. 跟踪
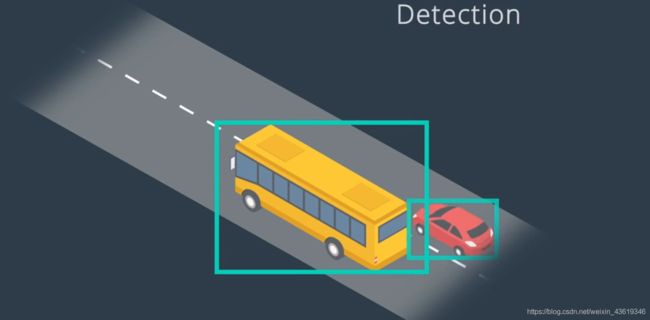
在检测完之后,我们就需要进行跟踪了,跟踪有以下几个重要意义:
- 跨帧追踪对象能够有效防止目标丢失,当检测对象被其他对象遮挡时,很容易检测失败,而追踪则可以解决这样的遮挡问题。
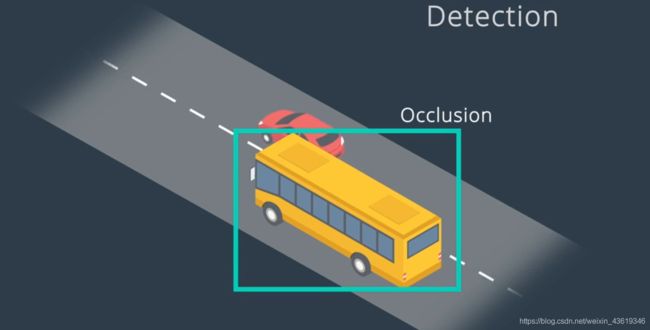
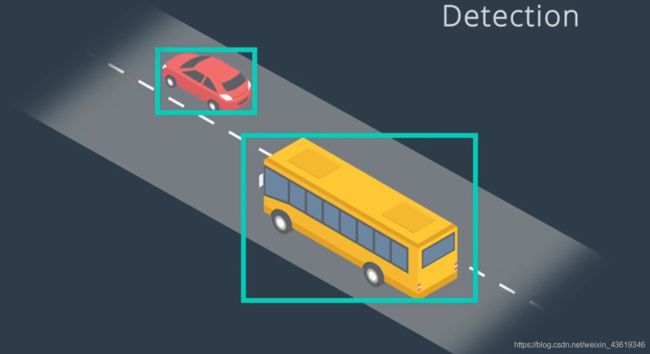
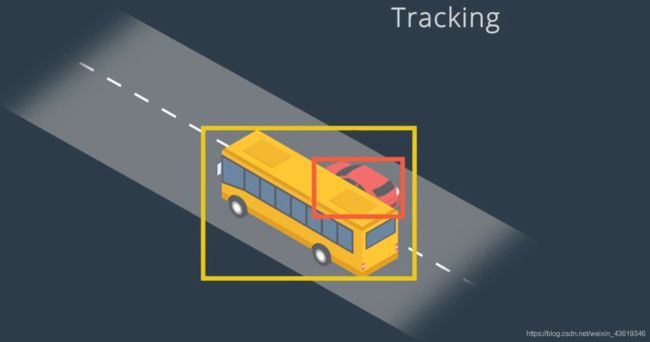
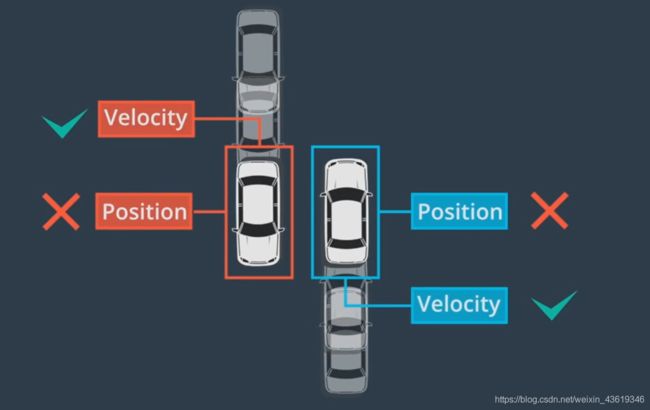
- 另一个意义在于追踪可以保留身份,确定身份后,我们可以使用对象的位置,并结合预测算法,以确定在下一个时间帧中的位置和速度,从而帮助我们识别下一帧中的相应对象。
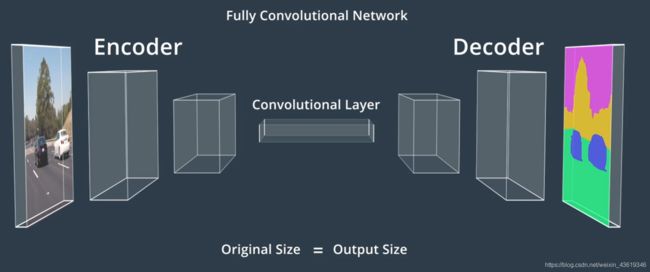
12. 分割
语义分割涉及到对图像中的每一个像素进行分类,它用于尽可能的了解环境并确定车辆的可行驶区域。语义分割依赖于一种特殊的CNN,叫做全卷积网络 (Fully Convolutional Networks).

关于FCN可以参考这篇文章。
13. Apollo 感知
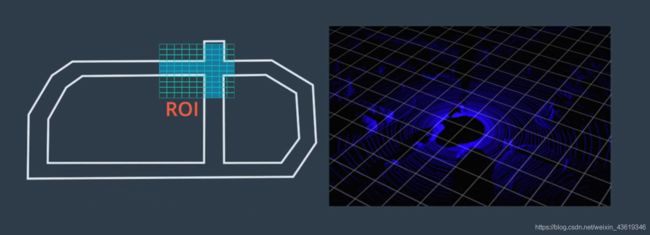
对于三维对象检测,Apollo在高精地图的基础上使用感兴趣区域(ROI)来重点关注相关对象。Apollo将ROI过滤器应用于点云和图像数据,从而缩小搜素范围并加快感知的速度。
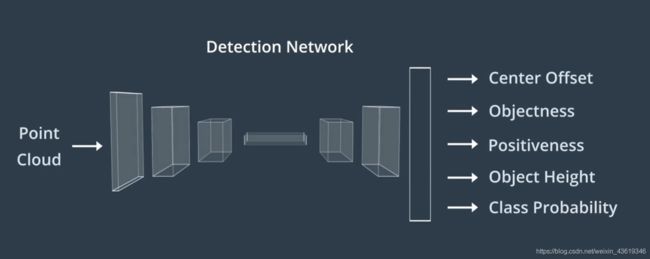
然后通过检测网络馈送已过滤的点云,输出用于构建围绕对象的三维边界框。
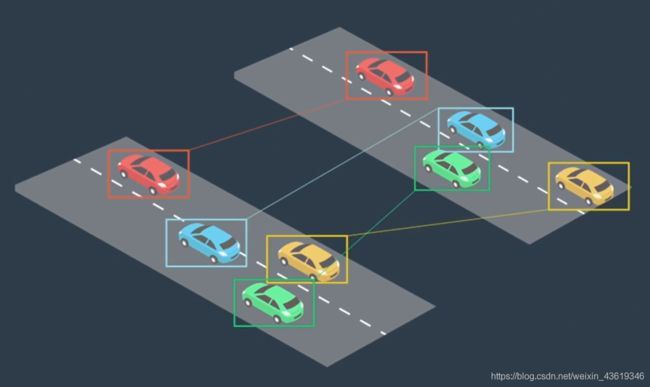
最后使用被称为检测跟踪关联的算法来跨时间步识别单个对象,改算法先保留在每个时间步要跟踪的对象列表,然后在下一个时间步中找到每个对象的最佳匹配。
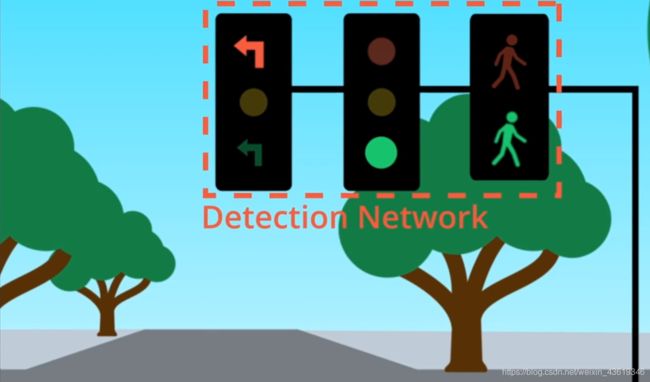
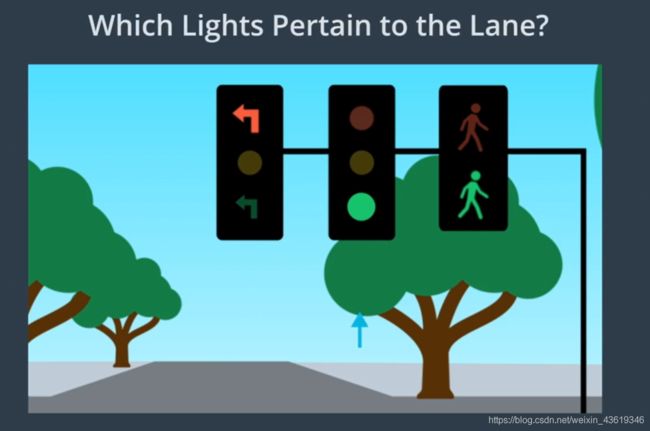
对于交通信号灯的分类,Apollo先使用高精度地图来确定前方是否有信号灯,如果有,高精地图则会返回灯的位置,这侧重于摄像头搜索范围,在摄像头捕捉到交通信号灯后,Apollo使用检测网络对图像中的灯进行定位,然后Apollo从较大的图像中提取信号灯,将裁剪后的交通的图像提供给分类网络,从而确定灯的颜色。如果有许多灯,则系统需要选择哪些与其车道相关。

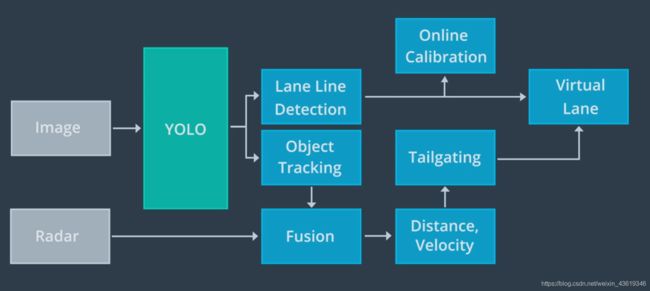
Apollo使用YOLO网络来检测车道线和动态物体。经过YOLO网络检测后,在线模块会并入来自其他传感器的数据对车道线预测进行调整,车道线最终被并入名为”虚拟车道“的单一数据结构中。同样,也通过其他传感器的数据,对YOLO网络所检测到的动态对象进行调整,以获得每个对象的类型、位置、速度和前进方向。虚拟车道和动态对象均被传递到规划与控制模块。
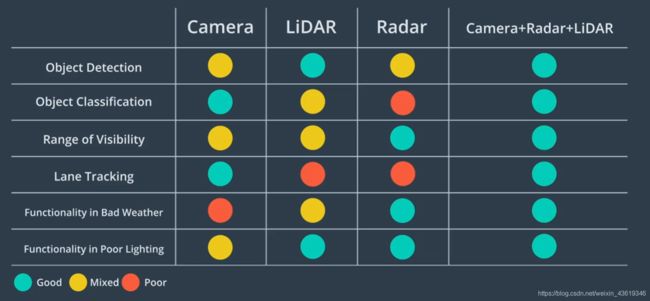
14. 传感器数据比较
下图是不同传感器的优缺点比较:
- 摄像头非常适用于分类,在Apollo中,摄像头主要用于交通信号灯的分类以及车道线检测;
- 激光雷达的优势在于障碍物检测,即使是在夜间,也依然能够准确的检测到障碍物;
- 雷达在探测范围和应对恶劣天气方面占优势。
因此传感器融合是必不可少的。
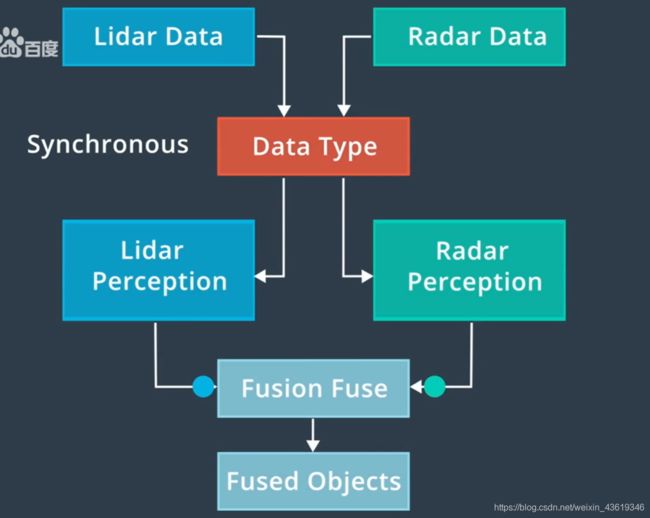
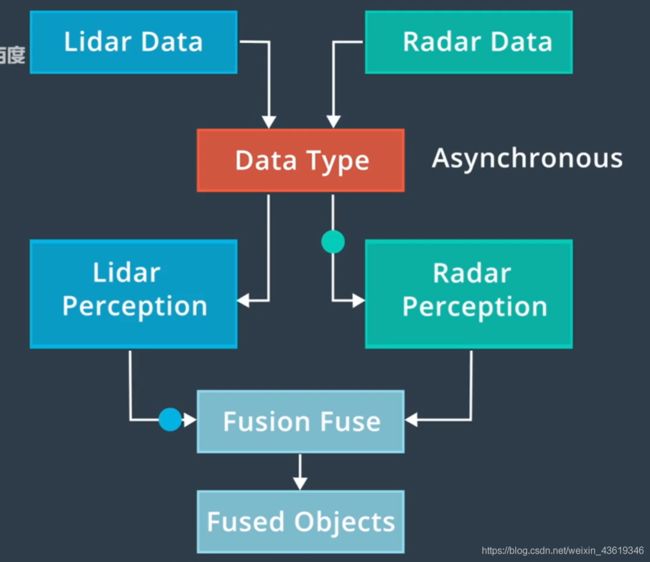
15. 感知融合策略
以激光雷达和雷达的融合举例,依然采用的是卡尔曼滤波算法。
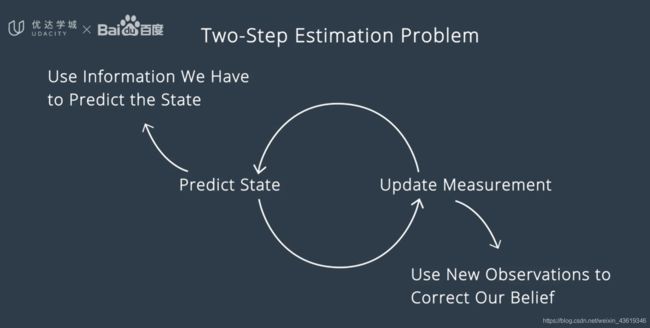
融合又分为同步和异步:同步是同时更新不同传感器的测量结果;异步则是逐个更新状态。
16. 项目示例:感知与融合& 17. 课程综述
略