TensorFlow与深度学习基础
TensorFlow与深度学习基础
- TensorFlow与深度学习基础
-
- 目标识别与分类
-
- 卷积神经网络
- 卷积
-
- 输入和卷积核
- 跨度
- 边界填充
- 数据格式
- 深入探讨卷积核
- 常见层
-
- 卷积层
- 激活函数
- 池化层
- 归一化
- 高级层
- 图像与TensorFlow
-
- 加载图像
- 图像格式
-
- 1.JPEG与PNG
- 2.TFRecord
- 图像操作
-
- 1.裁剪
- 2.边界填充
- 3.翻转
- 4.饱和与平衡
- 颜色
-
- 1.灰度
- 2.HSV空间
- 3.RGB空间
- 4.LAB空间
- 5.图像数据类型转换
- CNN的实现
-
- Stanford Dogs数据集
- 将图像转为TFRecord文件
- 加载图像
- 模型
- 训练
- 用TensorBoard调试滤波器
- 小结
- 循环神经网络与自然语言处理
- 循环神经网络简介
-
- 时序的世界
- 近似任意程序
- 随时间反向传播
- 序列的编码和解码
- 实现第一个循环神经网络
- 梯度消失与梯度爆炸
- 长短时记忆网络
- 词向量嵌入
-
- 准备维基百科语料库
- 模型结构
- 噪声对比分类器
- 训练模型
- 序列分类
-
- Imdb影评数据集
- 使用词向量嵌入
- 序列标注模型
- 来自最后相关活性值的softmax层
- 梯度裁剪
- 训练模型
- 序列标注
-
- OCR数据集
- 时间步之间共享的softmax层
- 训练模型
- 双向RNN
- 预测编码
-
- 字符级语言建模
- ArXiv摘要API
- 数据预处理
- 预测编码模型
- 训练模型
- 生成相似序列
TensorFlow与深度学习基础
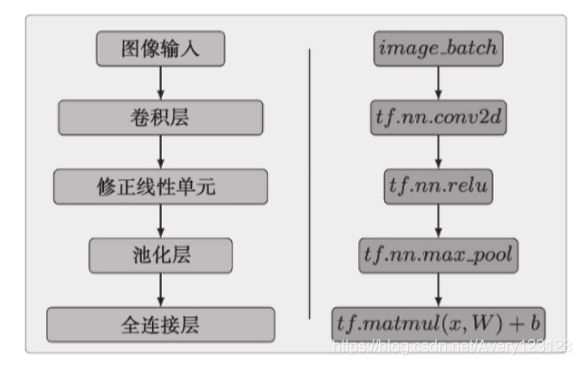
目标识别与分类
卷积神经网络
简化的卷积层
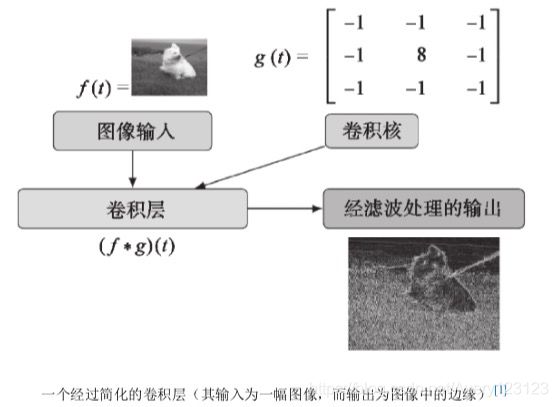
简单的对应一下:
Tensorflow使用图像时检查样例输入的结构:
image_batch = tf.constant([
[#第一幅图像
[[0,255,0],[0,255,0],[0,255,0]],
[[0,255,0],[0,255,0],[0,255,0]]
],
[#第二幅图像
[[0,0,255],[0,0,255],[0,0,255]],
[[0,0,255],[0,0,255],[0,0,255]]
]
])
image_batch.get_shape()
得到输出:


![]()
sess,run(image_batch)[0][0][0]
得到输出:
卷积
卷积运算图示:

输入和卷积核
卷积运算实验,推荐使用tf.nn.conv2d
可试验计算两个张量的卷积,并查看结果
#建立input和kernel
input_batch = tf.constant(
[ #第一个输入
[[0.0],[1.0]],
[[2.0],[3.0]]
],
[ #第二个输入
[[2.0],[4.0]],
[[6.0],[8.0]]
]
)
kernel = tf.constant([
[
[[1.0,2.0]]
]
])

上述实例代码中包含了一个卷积核(变量kernel的第1维度)。该卷积核的作用是返回一个其中第一个通道等于原始输入,第二个通道等于原始输入值两倍的张量。
进行卷积运算
conv2d = tf.nn.conv2d(input_batch,kernel,strides=[1,1,1,1],padding = 'SAME')
sess,run(conv2d)
得到输出:

该输出是另一个与input_batch同秩的张量,但其维数与卷积核相同。若input_batch代表一幅图像,它拥有一个通道。在这种情形下,它将被视为一幅灰度图 像。该张量中的每个元素都表示这幅图像中的一个像素。该图像中右下角的像素值将为3.0
可将卷积运算tf.nn.conv2d视为图像(用input_batch表示)和卷积核张量kernel的组合。这两个张量的卷积会生成一幅特征图(feature map)。特征图是一个比较宽泛的术语,但在计算机视觉中,它与使用图像卷积核的运算的输出相关,而现在,特征图通过为输出添加新层代表了这些张量的卷积。
输入图像与输出的特征图之间的关系可结合代码来分析。访问输入批数据和特征图中的元素时使用的是相同的索引。通过访问输入批数据和特征图中位置相同的像素,可了解当输入与kernel进行卷积运算时,它的值是如何改变的。在下面的例子中,图像中右下方的像素经过卷积后的值变为3.01.0和3.02.0。这些值对 应于像素值和kernel中的相应值。
lower_right_image_pixel = sess.run(input_batch)[0][1][1]
lower_right_kernel_pixel = sess.run(conv2d)[0][1][1]
lower_right_image_pixel,lower_right_kernel_pixel
得到输出:

跨度
在计算机视觉中,卷积的价值体现在对输入(本例中为图像)降维的能力上。一幅2D图像的维数包括其宽度、高度和通道数。如果图像具有较高的维数,则
意味着神经网络扫描所有图像以判断各像素的重要性所需的时间呈指数级增长。利用卷积运算对图像降维是通过修改卷积核的strides(跨度)参数实现的。
参数strides使得卷积核可跳过图像中的一些像素,从而在输出中不包含它们。实际上,说这些像素“被跳过”并不十分准确,因为它们仍然会对输出产生影响。 strides参数指定了当图像维数较高,且使用了较为复杂的卷积核时,卷积运算应如何进行。当卷积运算用卷积核遍历输入时,它利用这个跨度参数来修改遍历输入 的方式。strides参数使得卷积核无需遍历输入的每个元素,而是可以直接跳过某些元素。
例如,假设需要计算一幅较大的图像和一个较大的卷积核之间的卷积运算。在这个例子中,图像的高度为6个像素,宽度为6个像素,而深度为1个通道 (6×6×1),卷积核尺寸为(3×3×1)。

输出结果:

通过将kernel在input_batch上滑动,同时跨过(或跳过)某些元素,input_batch与kernel便结合在一起。kernel每次移动时,都将input_batch的一个元素作为中心。然后,位置重叠的值相乘,再将这些乘积相加得到卷积的结果。卷积就是通过这种逐点相乘的方式将两个输入整合在一起的。利用下图可更容易地将卷积运算可视化。
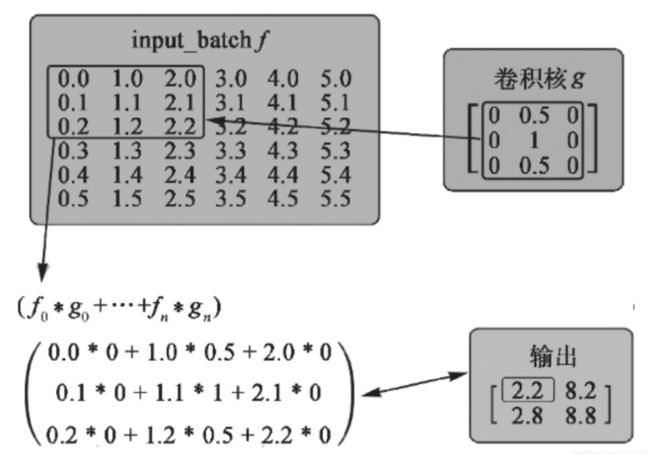
上图所体现的是与之前的代码完全相同的逻辑。两个张量进行了卷积运算,但卷积核会跳过输入中的一些固定数目的元素。strides显著降低了输出的维数,而卷积核允许卷积使用所有的输入值。在输入数据中,没有任何元素在被跳过时被移除,但它仍然变成了一个形状更小的张量。
设置跨度是一种调整输入张量维数的方法。降维可减少所需的运算量,并可避免创建一些完全重叠的感受域。strides参数的格式与输入向量相同,即 (image_batch_size_stride、image_height_stride、image_width_stride、image_channels_stride)。第1个和最后一个跨度参数通常很少修改,因为它们会在tf.nn.conv2d运算中 跳过一些数据,从而不将这部分数据予以考虑。如果希望降低输入的维数,可修改image_height_stride和image_width_stride参数。
边界填充
当卷积核与图像重叠时,它应当落在图像的边界内。有时,两者尺寸可能不匹配,一种较好的补救策略是对图像缺失的区域进行填充,即边界填充。
TensorFlow会用0进行边界填充,或当卷积核与图像尺寸不匹配,但又不允许卷积核跨越图像边界时,会引发一个错误。tf.nn.conv2d的零填充数量或错误状态是由 参数padding控制的,它的取值可以是SAME或VALID。
·SAME :卷积输出与输入的尺寸相同。这里在计算如何跨越图像时,并不考虑滤波器的尺寸。选用该设置时,缺失的像素将用0填充,卷积核扫过的像素数 将超过图像的实际像素数。
·VALID :在计算卷积核如何在图像上跨越时,需要考虑滤波器的尺寸。这会使卷积核尽量不越过图像的边界。在某些情形下,可能边界也会被填充。
在计算卷积时,最好能够考虑图像的尺寸,如果边界填充是必要的,则TensorFlow会有一些内置选项。在大多数比较简单的情形下,SAME都是一个不错的选 择。当指定跨度参数后,如果输入和卷积核能够很好地工作,则推荐使用VALID。关于这两个参数的更多介绍,请参考https://www.tensorflow.org/versions/master/api_docs/python/nn.html#convolution。
数据格式
tf.nn.conv2d还有另外一个参数data_format未在上述例程中使用。tf.nn.conv2d文档详细解释了如何修改数据格式,以使input、kernel和strides遵循某种与到目前为止 所使用的格式不同的格式。如果有某个输入张量未遵循[batch_size,height,width,channel]标准,则修改该格式便非常有用。除了修改输入的格式,使之与标准匹 配外,也可修改data_format参数以使用一种不同的布局。
data_format:该参数可取为“NHWC”或“NCHW”,默认值为“NHWC”,用于指定输入和输出数据的格式。当取默认格式“NHWC”时,数据的存储顺序为 [batch,in_height,in_width,in_channels]。若该参数取为“NCHW”,数据存储顺序为[batch,in_channels,in_height,in_width]。

深入探讨卷积核
在TensorFlow中,滤波器参数用于指定与输入进行卷积运算的卷积核。滤波器通常用于摄影中以调整图片的属性,如允许到达摄像机透镜的光通量。在摄影中,摄影者可借助滤波器对所拍摄的图片做出大幅度的修改。摄影者之所以能够利用滤波器对图片进行修改,是因为滤波器能够识别到达透镜的光线的特定属 性。例如,红色透镜滤波器会吸收(或阻止)不同于红色的每种频率的光,使得只有红色光可通过该滤波器。
在计算机视觉中,卷积核(滤波器)常用于识别数字图像中的重要属性。当某些滤波器感兴趣的特征在图像中存在时,滤波器会使用特定模式突出这些特征。若将除红色外的所有颜色值减小,则可得到一个红色滤波器的卷积核。在这种情形下,红色值将保持不变,而其他任何匹配的颜色值将被减小。
本章一开始所展示的例子使用了一个专为边缘检测设计的卷积核。边缘检测卷积核在计算机视觉应用中极为常见,它可用基本的TensorFlow运算和一个 tf.nn.conv2d运算实现。
将一幅图像与一个边缘检测卷积核进行卷积所得到的输出将是所有被检测到边缘的区域。这段代码假设已有一个图像批数据(image_batch)可用。在这个例 子中,示例图像来自Stanford Dogs数据集,卷积核拥有3个输入和3个输出通道,这些通道对应于[0,255]区间内的RGB值,其中255为最大灰度值。调用tf.minimum 和tf.nn.relu的目的是将卷积值保持存在RGB颜色值的合法范[0,255]内。
在这个简单的示例中,也可使用许多其他的常见卷积核。这些卷积核中的每一个都会突出图像中的不同模式,从而得到不同的结果。下列卷积核通过增加颜色的变化幅度可产生锐化效果。


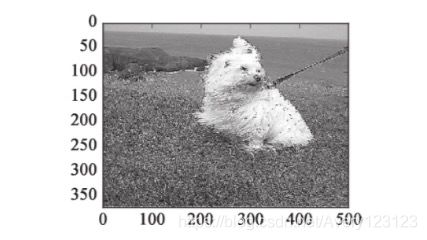
这个卷积核的作用是增加卷积核中心位置像素的灰度,并降低周围像素的灰度。这种灰度的调整能够匹配那些具有较强灰度的像素的模式,并提升它们的灰度,从而使输出在视觉上呈现出锐化的效果。请注意,这里的卷积核四角的元素均为0,并不会对“+”形状的模式产生影响。
这些卷积核在比较初级的层次上能够与图像中的一些模式匹配。卷积神经网络通过使用从训练过程中学习到的复杂卷积核不但可以匹配边缘,还可以匹配更为复杂的模式。在训练过程中,这些卷积核的初值通常随机设定,随着训练迭代的进行,它们的值会由CNN的学习层自动调整。当CNN训练完成一轮迭代后,它 接收一幅图像,并将其与某个卷积核进行卷积,然后依据预测结果与该图像真实标签是否一致,对卷积核中的参数进一步调整。例如,若一幅牧羊犬的照片被 CNN模型预测为斗牛犬,则卷积核参数将适当调整以试图更好地匹配牧羊犬图片。
用CNN学习复杂的模式并非只用一个单层卷积就可完成,即使上述示例代码中包含了一个tf.nn.relu层用于准备输出以便可视化,也是不够的。在CNN中,卷 积层可多次出现,但通常也会包含其他类型的层。这些层联合起来构成了成功的CNN架构所必需的要素。
常见层
一个神经网络架构要成为CNN,必须至少包含一个卷积层(tf.nn.conv2d)。单层CNN的一种实际用途是检测边缘。对于图像识别和分类任务而言,更常见的情形是使用不同的层类型支持某个卷积层。这些层有助于减少过拟合,并可加速训练过程和降低内存占用率。
本章所涵盖的层主要集中于那些在CNN架构中经常使用的层上。CNN可使用的层并非只局限于这些层,它们完全可以与为其他网络架构设计的层混合使用。
卷积层
我们已经对一种类型的卷积层——tf.nn.conv2d进行了详细介绍,但对高级用户,还有一些注意事项需要说明。TensorFlow中的卷积层所完成的并非真正的卷积,
细节可参考https://www.tensorflow.org/versions/master/api_docs/python/nn.html#convolution。
实际上,卷积与TensorFlow所采用的运算的差异主要体现在性能上。TensorFlow 采用了一种可对所有不同类型的卷积层中的卷积运算进行加速的技术。
每种类型的卷积层都有一些用例,但tf.nn.conv2d是一个较好的切入点。其他类型的卷积也十分有用,但在构建能够完成目标识别和分类任务的网络时,并不需要它们。下面对这些卷积类型做一简要概括。
1.tf.nn.depthwise_conv2d
当需要将一个卷积层的输出连接到另一个卷积层的输入时,可使用这种卷积。一种高级用例是利用tf.nn.depthwise_conv2d创建一个遵循Inception架构的网络(参 见https://arxiv.org/abs/1512.00567 )。
2.tf.nn.separable_conv2d
它与tf.nn.conv2d类似,但并非后者的替代品。对于规模较大的模型,它可在不牺牲准确率的前提下实现训练的加速。对于规模较小的模型,它能够快速收敛, 但准确率较低。
3.tf.nn.conv2d_transpose
它将一个卷积核应用于一个新的特征图,后者的每一部分都填充了与卷积核相同的值。当该卷积核遍历新图像时,任何重叠的部分都相加在一起。这就很好地解释了斯坦福大学课程CS231n Winter 2016:Lecture 13中关于如何将tf.nn.conv2d_transpose用于可学习的降采样的问题。
激活函数
这些函数与其他层的输出联合使用可生成特征图。它们用于对某些运算的结果进行平滑(或微分)。其目标是为神经网络引入非线性。非线性意味着输入和输出的关系是一条曲线,而非直线 。曲线能够刻画输入中更为复杂的变化。例如,非线性映射能够描述那些大部分时间值都很小,但在某个单点会周期性地出现极值的输入。为神经网络引入非线性可使其对在数据中发现的复杂模式进行训练。
TensorFlow提供了多种激活函数。在CNN中,人们之所以主要使用tf.nn.relu,是因为它虽然会带来一些信息损失,但性能较为突出。开始设计模型时,推荐使用 tf.nn.relu,但高级用户也可创建自己的激活函数。评价某个激活函数是否有用时,可考虑下列为数不多的几个主要因素。
1)该函数应是单调 的 ,这样输出便会随着输入的增长而增长,从而使利用梯度下降法寻找局部极值点成为可能。
2)该函数应是可微分的 ,以保证该函数定义域内的任意一点上导数都存在,从而使得梯度下降法能够正常使用来自这类激活函数的输出。
任何满足这些条件的函数都可用作激活函数。在TensorFlow中,有少量激活函数值得一提,它们在各种CNN架构中都极为常见。下面给出这些激活函数的简要 介绍,并通过一些示例代码片段来说明其用法。
1.tf.nn.relu

在某些文档中,修正线性单元也被称为斜坡函数,因为它的图形与滑板的斜坡非常相似。ReLU是分段线性的,当输入为非负时,输出将与输入相同;而当输入 为负时,输出均为0。它的优点在于不受“梯度消失”的影响,且取值范围为:0到正无穷 ;其缺点在于当使用了较大的学习速率时,易受达到饱和的神经元的影响。
features = tf.range(-2,3)
#注意值为负的特征的输出值
sess.run([features,tf,nn,relu(features)])
的得输出:

2.tf.sigmoid

sigmoid函数的返回值位于区间[0.0,1.0]中。当输入值较大时,tf.sigmoid将返回一个接近于1.0的值,而输入值较小时,返回值将接近于0.0。对于在那些真实输出位于[0.0,1.0]的样本上训练的神经网络,sigmoid函数可将输出保持在[0.0,1.0]内的能力非常有用。当输入接近饱和或变化剧烈时,对输出范围的这种缩减往往会带来一些不利影响。
features = tf.to_float(tf.range(-1,3))
sess.run([features,tf.sigmoid(features)])
得到输出:

在本例中,一组整数被转化为浮点类型(1变为1.0),并传入一个sigmoid函数。当输入为0时,sigmoid函数的输出为0.5,即sigmoid函数值域的中间点。
3.tf.tanh
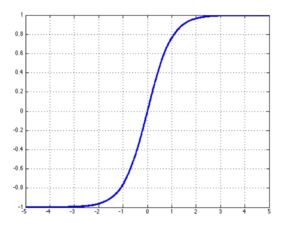
双曲正切函数(tanh)与tf.sigmoid非常接近,且与后者具有类似的优缺点。tf.sigmoid和tf.tanh的主要区别在于后者的值域为[-1.0,1.0]。在某些特定的网络架构 中,能够输出负值的能力可能会非常有用。
#注意,tf.tanh(tf.nn,tanh)目前只支持浮点类型的输入
features = tf.to_float(tf.range(-1,3))
sess.run([features,tf.tanh(features)])
得到输出:

4.tf.nn.dropout
依据某个可配置的概率将输出设为0.0。当引入少量随机性有助于训练时,这个层会有很好的表现。一种适合的场景是:当要学习的一些模式与其近邻特征耦合 过强时。这种层会为所学习到的输出添加少量噪声。
注意:这种层应当只在训练阶段使用。如果在测试阶段使用该层,它所引入的随机噪声将对结果产生误导。
features = tf.constant([-0.1,0.0,0.1,0.2])
#注意,每次执行时,输入都应不同。你的数字不会与这些输出匹配
sess.run([features,tf.nn.dropout(features,keep_prob = 0.5)])
得到输出:

池化层
池化层能够减少过拟合,并通过减小输入的尺寸来提高性能。它们可用于对输入降采样,但会为后续层保留重要的信息。只使用tf.nn.conv2d来减小输入的尺寸 也是可以的,但池化层的效率更高。
1.tf.nnmax_pool

这个例子也可通过下列示例代码来说明,目标是找到张量中的最大分量。
#输入通常为前一层的输出,而非直接为图像
batch_size= 1
input_height= 3
input_width = 3
input_channels = 1
layer_input = tf.constant([
[
[[1.0],[0.2],[1.5]],
[[0.1],[1.2],[1.4]],
[[1.1],[0.4],[0.4]]
]
])
#strides 会使用image_height 和image_width遍历整个输入
kernel = [batch_size,input_height,input_width,input_channels]
max_pool = tf.nn.max_pool(layer_input,kernel,[1,1,1,1],"VALID")
sess.run(max_pool)
得到输出:
![]()
layer_input是一个形状类似于tf.nn.conv2d或某个激活函数的输出的张量。目标是仅保留一个值,即该张量中的最大元素。在本例中,该张量的最大分量为1.5,并 以与输入相同的格式被返回。
最大池化(max-pooling)通常是利用2×2的接受域(高度和宽度均为2的卷积核)完成的,它通常也被称为“2×2的最大池化运算”。使用2×2的接受域的原因之一 在于它是在单个通路上能够实施的最小数量的降采样。如果使用1×1的接受域,则输出将与输入相同。
2.tf.nn.avg_pool
跳跃遍历一个张量,并将被卷积核覆盖的各深度值取平均。当整个卷积核都非常重要时,若需实现值的缩减,平均池化是非常有用的,例如输入张量宽度和高
度很大,但深度很小的情况。
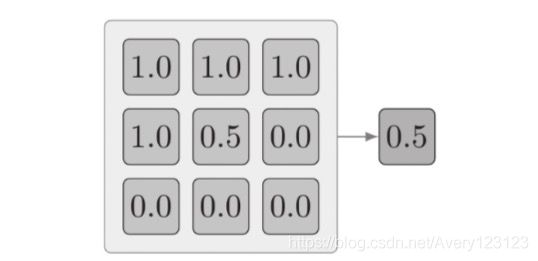
这个例子可以用下列代码片段来模拟,目标是求出张量中所有分量的均值。
batch_size= 1
input_height= 3
input_width = 3
input_channels = 1
layer_input = tf.constant([
[
[[1.0],[1.0],[1.0]],
[[1.0],[0.5],[0.0]],
[[0.0],[0.0],[0.0]]
]
])
#strides 会使用image_height 和image_width遍历整个输入
kernel = [batch_size,input_height,input_width,input_channels]
max_pool = tf.nn.max_pool(layer_input,kernel,[1,1,1,1],"VALID")
sess.run(max_pool)
得到输出:
![]()

归一化
归一化层并非CNN所独有。在使用tf.nn.relu时,考虑输出的归一化是有价值的。由于ReLU是无界函数,利用某些形式的归一化来识别那些高频特征通常是十分有用的。
tf.nn.local_response_normalization(tf.nn.lrn)
局部响应归一化是一个依据求和操作而形成输出的函数,详情请参考TensorFlow官方文档 。
…在某个给定向量中,每个分量都被depth_radius覆盖的输入的加权和所除。
归一化的目标之一在于将输入保持在一个可接受的范围内。例如,将输入归一化到[0.0,1.0]区间内将使输入中所有可能的分量归一化为一个大于等于0.0且小于 等于1.0的值。局部响应归一化在对若干值归一化时,还会将每个值的重要性加以考虑。
#创建一组浮点数值
layer_input = tf.constant([
[[[1.]],[[2.]],[[3.]]]
])
lrn = tf.nn.local_response_normalization(layer_input)
sess.run([layer_input,lrn])
得到输出:

高级层
为使标准层的定义在创建时更加简单,TensorFlow引入了一些高级网络层。这些层不是必需的,但它们有助于减少代码冗余,同时遵循最佳的实践。开始时,这些层需要为数据流图添加大量非核心的节点。在使用这些层之前,投入一些精力了解相关基础知识是非常值得的。
1.tf.contrib.layers.convolution2d
convolution2d层与tf.nn.conv2d的逻辑相同,但还包括权值初始化、偏置初始化、可训练的变量输出、偏置相加以及添加激活函数的功能。CNN中的这些步骤有许 多目前尚未介绍,但应熟练掌握。每个卷积核都是一个可训练的变量(CNN的目标是训练该变量),权值初始化用于在卷积核首次运行时,为其进行值的填充 (tf.truncated_normal)。其余参数与之前使用过的类似,只是使用了缩写的版本。无需声明完整的卷积核,它采用简单的元组形式(1,1)表示卷积核的高度和宽度。

得到输出:

这个例子设置了一个与由单幅图像构成的批数据的完整卷积,所有的参数都基于本章所介绍的各步骤。主要的差异在于tf.contrib.layers.convolution2d需要完成大量 设置,而一旦设置完成,便无需再次编写。对于高级用户而言,该层可帮助他们节省大量时间。
注意:当输入为一幅图像时,不应使用tf.to_float,而应使用tf.image.convert_image_dtype,该方法将以恰当的方式调整各分量以表示颜色值。在这段示例代码中, 使用了浮点值255.0,这并不是TensorFlow用浮点值表示图像所期望的方式。TensorFlow要求用浮点型描述图像颜色时,应当将各颜色分量控制在[0,1]范围内。
2.tf.contrib.layers.fully_connected
在全连接层中,每个输入与每个输出之间都存在连接。在许多架构中,这个层都极为常见。对于CNN,最后一层通常都是全连接层。 tf.contrib.layers.funlly_connected层提供了大量创建这个最后层的捷径,同时遵循了最佳实践原则。
通常,TensorFlow中的全连接层的格式是tf.matmul(features,weight)+bias,其中feature、weight和bias均为张量。该层完成的也是相同的任务,但同时也会对由管 理张量weight和bias所引发的复杂性加以考虑。

得到输出:

3.输入层
在CNN架构中,每一层都有特定的意图。(至少)从高层来理解它们是非常重要的,但如果不具体实践,是很容易遗忘的。在任何神经网络中,输入层都至关 重要。无论是训练还是测试,原始输入都需要传递给输入层。对于目标识别与分类,输入层为tf.nn.conv2d,它负责接收图像。接下来的步骤是在训练中使用真实图 像,而非tf.constant或tf.range变量形式的样例输入。
图像与TensorFlow
TensorFlow在设计时,就考虑了给将图像作为神经网络的输入提供支持。TensorFlow支持加载常见的图像格式(JPG、PNG),可在不同的颜色空间(RGB、 RGBA)中工作,并能够完成常见的图像操作任务。虽然TensorFlow使得图像操作变得容易,但仍然面临一些挑战。使用图像时,所面临的最大挑战便是最终需要 加载的张量的尺寸。每幅图像都需要用一个与图像尺寸(heightwidthchannel)相同的张量表示。再次提醒,通道是用一个包含每个通道中颜色数量的标量的秩1张量表示。
在TensorFlow中,一个红色的RGB像素可用如下张量表示:
red = tf.constant([255,0,0])
每个标量都可修改,以使像素值为另一个颜色值或一些颜色值的混合。对于RGB颜色空间,像素对应的秩1张量的格式为[red,green,blue]。一幅图像中的所 有像素都存储在磁盘文件中,它们都需要被加载到内存中,以便TensorFlow对其进行操作。
加载图像
TensorFlow在设计时便以能够从磁盘快速加载文件为目标。图像的加载与其他大型二进制文件的加载是相同的,只是图像的内容需要解码。加载下列3×3的JPG格式的示例图像的过程与加载任何其他类型的文件完全一致。

在上述代码中,假定该图像位于代码运行的当前目录的某个相对路径之下。输入生成器(tf.train.string_input_producer)会找到所需的文件,并将其加载到一个队 列中。加载图像要求将完整的文件加载到内存中(tf.WholeFileReader)。一旦文件被读取(image_reader.read),所得到的图像就将被解码(tf.image.decode_jpeg)。
这样便可以查看这幅图像。由于按照名称只存在一个文件,所以队列将始终返回同一幅图像。

加载图像后,查看输出。注意,它是一个非常简单的三阶张量。RGB值对应9个一阶张量。通过前面章节的学习,应该对图像张量的高阶数已经比较熟悉了。 被加载到内存中的图像格式为[batch_size,image_height,image_width,channels]。
图像格式
考虑图像的各个方面以及它们如何对模型造成影响非常重要。当使用来自一台RED Weapon摄像机的单帧图像训练一个网络时,考虑会发生什么。在笔者撰写本书时,这种摄像机的分辨率为6144×3160像素。这样的一帧图像需要用包含19415040个带有3个维度的颜色信息的一阶张量表示。
实际上,这种尺寸的输入将占用个大量系统内存。训练一个CNN需要大量时间,加载非常大的文件会进一步增加训练所需的时间。即便增加的时间在可接受的范围内,单幅图像的尺寸也很难存放在大多数系统的GPU显存中。 输入图像尺寸过大也会为大多数CNN模型的训练产生不利影响。CNN总是试图找到图像中的本征属性,虽然这些属性有一定的独特性,但也需要推广到其他
具有类似结果的图像上。使用尺寸过大的输入会使网络中充斥大量无关信息,从而影响模型的泛化能力。
在Stanford Dogs数据集中,哈巴狗类别中存在两幅外观迥异的图像。虽然非常可爱,但这些图像中充斥了大量会在训练中对网络造成误导的无用信息。例如, 文件n02110958_4030.jpg中的哈巴狗所戴的帽子不是CNN为匹配哈巴狗所需要学习的特征。大多数哈巴狗喜欢海盗帽,因此图像中有小丑帽实际上是在训练网络去 匹配一个大多数哈巴狗都没戴着的帽子。

图像中的重要信息是通过按照某种恰当的文件格式存储并处理得以强调的。在使用图像时,不同的格式可用于解决不同的问题。
1.JPEG与PNG
TensorFlow拥有两种可对图像数据解码的格式,一种是tf.image.decode_jpeg,另一种是tf.image.decode_png。在计算机视觉应用中,这些都是常见的文件格式,因为将其他格式转换为这两种格式非常容易。
值得注意的是,JPEG图像不会存储任何alpha通道的信息,但PNG图像会。如果在训练模型时需要利用alpha信息(透明度),则这一点非常重要。一种应用场 景是当用户手工切除图像的一些区域,如狗所戴的不相关的小丑帽。将这些区域置为黑色会使它们与该图像中的其他黑色区域看起来有相似的重要性。若将所移 除的帽子对应的区域的alpha值设为0,则有助于标识该区域是被移除的区域。
使用JPEG图像时,不要进行过于频繁的操作,因为这样会留下一些伪影(artifact)。在进行任何必要的操作时,获取图像的原始数据,并将它们导出为JPEG 文件。为了节省训练时间,请试着尽量在图像加载之前完成对它们的操作。
如果一些操作是必要的,PNG图像可以很好地工作。PNG格式采用的是无损压缩,因此它会保留原始文件(除非被缩放或降采样)中的全部信息。PNG格式 的缺点在于文件体积相比JPEG要大一些。
2.TFRecord
为将二进制数据和标签(训练的类别标签)数据存储在同一个文件中,TensorFlow设计了一种内置文件格式,该格式被称为TFRecord,它要求在模型训练之前 通过一个预处理步骤将图像转换为TFRecord格式。该格式的最大优点是将每幅输入图像和与之关联的标签放在同一文件中。
从技术角度讲,TFRecord文件是protobuf格式的文件。作为一种经过预处理的格式,它们是非常有用的。由于它们不对数据进行压缩,所以可被快速加载到内 存中。在下面这个例子中,我们将一幅图像及其标签写入一个新的TFRecord格式的文件中。

标签的格式被称为独热编码(one-hot encoding),这是一种用于多类分类的有标签数据的常见表示方法。Stanford Dogs数据集之所以被视为多类分类数据,是因为狗会被分类为单一品种,而非多个品种的混合。在现实世界中,当预测狗的品种时,多标签解决方案通常较为有效,因为它们能够匹配同时属于多个品种的狗。
在这段示例代码中,图像被加载到内存中并被转换为字节数组。之后,这些字节被添加到tf.train.Example文件中,而后者在被保存到磁盘之前先通过 SerializeToString序列化为二进制字符串。序列化是一种将内存对象转换为某种可安全传输到某个文件的格式。上面序列化的样本现在被保存为一种可被加载的格 式,并可被反序列化为这里的样本格式。
由于图像被保存为TFRecord文件,所以可被再次加载(从TFRecord文件加载,而非从图像文件加载)。在训练阶段,加载图像及其标签是必需的。这样相比将 图像及其标签分开加载会节省一些时间。

首先,按照与其他任何文件相同的方式加载该文件,主要差别在于之后该文件会由TFRecordReader对象读取。
tf.parse_single_example并不对图像进行解码,而是 解析TFRecord,然后图像会按原始字节(tf.decode_raw)被读取。
该文件被加载后,为使其布局符合tf.nn.conv2d的要求,即[image_height,image_width,image_channels],需要对形状进行调整(tf.reshape)。为将batch_size维添加 到input_batch中,需要对维数进行扩展(tf.expand)。
在本例中,TFRecord文件中虽然只包含一个图像文件,但这类记录文件也支持被写入多个样本。将整个训练集保存在一个TFRecord文件中是安全的,但分开存 储也完全可以。
当需要检查保存到磁盘的文件是否与从TensorFlow加载的图像是同一图像时,可使用下列代码:

可以看出,原始图像的所有属性都和从TFRecord文件加载的图像一致。为确认这一点,可从TFRecord文件加载标签,并检查它与之前保存的版本是否一致。

创建一个既可存储原始图像数据,也可存储其期望的输出标签的文件,能够降低训练中的复杂性。尽管使用TFRecord文件并非必需,但在使用图像数据时, 却是强烈推荐的。如果对于某个工作流,它不能很好地工作,那么仍然建议在训练之前对图像进行预处理并将预处理结果保存下来。每次加载图像时才对其进行 处理是不推荐的做法。
图像操作
当给定大量不同质量的训练数据时,CNN往往能够很好地工作。图像能够通过可视化的方式传达复杂场景所蕴涵的某种目标主题。在Stanford Dogs数据集中,很重要的一点是图像能够以可视化的方式突出图片中狗的重要性。一幅狗位于画面中心的图像会被认为比狗作为背景的图像更有价值。
并非所有数据集都拥有最有价值的图像。下面所示的两幅图像都来自Stanford Dogs数据集,按照假设,该数据集本应突出不同的狗的品种。

左图n02113978_3480.jpg突出的是一条典型的墨西哥无毛犬的重要属性,而右图n02113978_1030.jpg强调的是两个参加聚会的人在逗一条墨西哥无毛犬。右图中 充斥了大量的无关信息,这可能会导致所训练的CNN模型对参加聚会的人的面部信息更为关注,而非墨西哥无毛犬。类似这样的图像中可能会包含狗,我们可对 其进行操作,使狗而非人成为真正被突出的对象。
在大多数场景中,对图像的操作最好能在预处理阶段完成。预处理包括对图像裁剪、缩放以及灰度调整等。另一方面,在训练时对图像进行操作有一个重要
的用例。当一幅图像被加载后,可对其做翻转或扭曲处理,以使输入给网络的训练信息多样化。虽然这个步骤会进一步增加处理时间,但却有助于缓解过拟合现
象。
TensorFlow并未设计成一个图像处理框架。与TensorFlow相比,有一些Python库(如PIL和OpenCV)支持更丰富的图像操作。对于TensorFlow,可将那些对训练 CNN十分有用的图像处理方法总结如下。
1.裁剪
裁剪会将图像中的某些区域移除,将其中的信息完全丢弃。裁剪与tf.slice类似,后者是将一个张量中的一部分从完整的张量中移除。当沿某个维度存在多余的
输入时,为CNN对输入图像进行裁剪便是十分有用的。例如,为减少输入的尺寸,可对狗位于图像中心的图片进行裁剪。
sess.run(tf.image.central_crop(image,0.1))
得到输出:
![]()
这段示例代码利用了tf.image.central_crop将图像中10%的区域抠出,并将其返回。该方法总是会基于所使用的图像的中心返回结果。 裁剪通常在预处理阶段使用,但在训练阶段,若背景也有用时,它也可派上用场。当背景有用时,可随机化裁剪区域起始位置到图像中心的偏移量来实现裁剪。

为从位于(0,0)的图像的左上角像素开始对图像裁剪,这段示例代码使用了tf.image.crop_to_bounding_box。目前,该函数只能接收一个具有确定形状的张量。因此,输入图像需要事先在数据流图中运行。
2.边界填充
为使输入图像符合期望的尺寸,可用0进行边界填充。可利用tf.pad函数完成该操作,但对于尺寸过大或过小的图像,TensorFlow还提供了另外一个非常有用的 尺寸调整方法。对于尺寸过小的图像,该方法会围绕该图像的边界填充一些灰度值为0的像素。通常,该方法用于调整小图像的尺寸,因为任何其他调整尺寸的方 法都会使图像的内容产生扭曲。
#该边界值填充方法仅可以接受实值输入
real_image = see.run(image)
pad = tf.image.pad_to_bounding_box(
real_image,offset_height=0,offset_width=0,
target_height=4,target_width=4)
sess.run(pad)
得到输出:

这段示例代码将图像的高度和宽度都增加了一个像素,所增加的新像素的灰度值均为0。对于尺寸过小的图像,这种边界填充方式是非常有用的。如果训练集 中的图像存在多种不同的长宽比,便需要这样的处理方法。对于那些长宽比不一致的图像,TensorFlow还提供了一种组合了pad和crop的尺寸调整的便捷方法。
#该边界值填充方法仅可以接受实值输入
real_image = see.run(image)
crop_or_pad = tf.image.resize_image_with_crop_or_pad(
real_image,target_hight=2,target_width=5)
sess.run(crop_or_pad)
得到输出:

real_image的高度被减小了两个像素,而通过边界填充0像素使宽度得以增加。这个函数的操作是相对图像输入的中心进行的。
3.翻转
翻转操作的含义与其字面意思一致,即每个像素的位置都沿水平或垂直方向翻转。从技术角度讲,翻转是在沿垂直方向翻转时所采用的术语。利用TensorFlow 对图像执行翻转操作是非常有用的,这样可以为同一幅训练图像赋予不同的视角。例如,一幅左耳卷曲的澳大利亚牧羊犬图像如果经过了翻转,便有可能与其他 的图像中右耳卷曲的狗匹配。
TensorFlow有一些函数可实现垂直翻转、水平翻转,用户可随意选择。随机翻转一幅图像的能力对于防止模型对图像的翻转版本产生过拟合非常有用。
top_left_pixels= tf.slice(image,[0,0,0][2,2,3])
flip_horizon = tf.image.flip_left_right(top_left_pixels)
flop_vertial = tf.image.flip_up_down(flip_horizon)
sess.run([top_left_pixels,flip])
得到输出:

这段示例代码对一幅图像的一个子集首先进行水平翻转,然后进行垂直翻转。该子集是用tf.slice选取的,这是因为对原始图像翻转返回的是相同的图像(仅对 这个例子而言)。这个像素子集解释了当图像发生翻转时所发生的变化。tf.image.flip_left_right和tf.image.flip_up_down都可对张量进行操作,而非仅限于图像。这些函 数对图像的翻转具有确定性,要想实现对图像随机翻转,可利用另一组函数。
top_left_pixels= tf.slice(image,[0,0,0][2,2,3])
random_flip_horizon = tf.image.random_flip_left_right(top_left_pixels)
random_flip_vertical =
tf.image.random_flip_up_down(random_flip_horizon)
sess.run(random_flip_vertical)
得到输出:

这个例子与之前的例子具有相同的逻辑,唯一的区别在于本例中的输出是随机的。这个例程每次运行时,都会得到不同的输出。有一个名称为seed的参数可控 制翻转发生的随机性。
4.饱和与平衡
可在互联网上找到的图像通常都事先经过了编辑。例如,Stanford Dogs数据集中的许多图像都具有过高的饱和度(大量颜色)。当将编辑过的图像用于训练
时,可能会误导CNN模型去寻找那些与编辑过的图像有关的模式,而非图像本身所呈现的内容。
为向在图像数据上的训练提供帮助,TensorFlow实现了一些通过修改饱和度、色调、对比度和亮度的函数。利用这些函数可对这些图像属性进行简单的操作和 随机修改。对训练而言,这种随机修改是非常有用的,原因与图像的随机翻转类似。对属性的随机修改能够使CNN精确匹配经过编辑的或不同光照条件下的图像的某种特征。

这个例子提升了一个以红色为主的像素的灰度值(增加了0.2)。不幸的是,在TensorFlow 0.9版本中,该方法尚不支持tf.uint8类型的输入 的是TensorFlow 0.9以下的版本,且在预处理环节需要对图像的灰度值进行调整时,请尽量避免使用tf.uint8类型。

这段示例代码将对比度调整了-0.5,这将生成一个识别度相当差的新图像。调节对比度时,最好选择一个较小的增量,以避免对图像造成“过曝”。这里的“过 曝”的含义与神经元出现饱和类似,即达到了最大值而无法恢复。当对比度变化时,图像中的像素可能会呈现出全白和全黑的情形。
简而言之,tf.slice运算的目的是突出发生改变的像素。当运行该运算时,它是不需要的。

这段示例代码调整了图像中的色度,使其色彩更加丰富。该调整函数接收一个delta参数,用于控制需要调节的色度数量。

这段代码与调节对比度的那段代码非常类似。为识别边缘,对图像进行过饱和处理是很常见的,因为增加饱和度能够突出颜色的变化。
颜色
CNN通常使用具有单一颜色的图像来训练。当一幅图像只有单一颜色时,我们称它使用了灰度颜色空间,即单颜色通道。对大多数计算机视觉相关任务而 言,使用灰度值是合理的,因为要了解图像的形状无须借助所有的颜色信息。缩减颜色空间可加速训练过程。为描述图像中的灰度,仅需一个单个分量的秩1张量即可,而无须像RGB图像那样使用含3个分量的秩1张量。
虽然只使用灰度信息有一些优点,但也必须考虑那些需要利用颜色的区分性的应用。在大多数计算机视觉任务中,如何使用图像中的颜色都颇具挑战性,因
为很难从数学上定义两个RGB颜色之间的相似度。为在CNN训练中使用颜色,对图像进行颜色空间变换有时是非常有用的。
1.灰度

这个例子将RGB图像转换为灰度图。tf.slice运算提取了最上一行的像素,并查看其颜色是否发生了变化。这种灰度变换是通过将每个像素的所有颜色值取平 均,并将其作为灰度值实现的。
2.HSV空间
色度、饱和度和灰度值构成了HSV颜色空间。与RGB空间类似,这个颜色空间也是用含3个分量的秩1张量表示的。HSV空间所度量的内容与RGB空间不同,它所度量的是图像的一些更为贴近人类感知的属性。有时HSV也被称为HSB,其中字母B表示亮度值。

3.RGB空间
到目前为止,所有的示例代码中使用的都是RGB颜色空间。它对应于一个含3个分量的秩1张量,其中红、绿和蓝的取值范围均为[0,255]。大多数图像本身就
位于RGB颜色空间中,但考虑到有些图像可能会来自其他颜色空间,TensorFlow也提供了一些颜色空间转换的内置函数。

这段示例代码非常简单,只是从灰度空间转换到RGB空间并无太大的实际意义。RGB图像需要三种颜色,而灰度图像只需要一种颜色。当转换(灰度到RGB) 发生时,RGB中每个像素的各通道都将被与灰度图中对应像素的灰度值填充。
4.LAB空间
TensorFlow并未为LAB颜色空间提供原生支持。它是一种有用的颜色空间,因为与RGB相比,它能够映射大量可感知的颜色。虽然TensorFlow并未为它提供原生支持,但它却是一种经常在专业场合使用的颜色空间。Python库python-colormath为LAB和其他本书未提及的颜色空间提供了转换支持。
使用LAB颜色空间最大的好处在于与RGB或HSV空间相比,它对颜色差异的映射更贴近人类的感知。在LAB颜色空间中,两个颜色的欧氏距离在某种程度上能
够反映人类所感受到的这两种颜色的差异。
5.图像数据类型转换
在这些例子中,为说明如何修改图像的数据类型,tf.to_float被多次用到。对于某些例子,使用这种方式是可以的,但TensorFlow还提供了一个内置函数,用于 当图像数据类型发生变化时恰当地对像素值进行比例变换。tf.image.convert_iamge_dtype(image,dtype,saturate=False)是将图像的数据类型从tf.uint8更改为tf.float的 便捷方法。
CNN的实现
利用TensorFlow实现目标识别与分类要求对卷积(对CNN)、常见层(非线性、池化、全连接等)、图像加载、图像操作和颜色空间相关的基础知识有所了 解。当掌握了这些内容后,便有可能利用TensorFlow构建一个用于图像识别与分类的CNN模型。在这种情况下,训练数据来自于Stanford的一个包含了许多狗及其品 种标签的数据集。我们需要依据这些图像训练一个网络,然后再评估它对狗的品种的预测准确性。
我们的网络架构采取了Alex Krizhevsky的AlexNet的简化版本,但并未使用AlexNet的所有层。AlexNet架构在本章最开始已做过介绍,它是ILSVRC2012挑战赛的冠 军。这个网络使用了本章介绍过的层和技术,与TensorFlow提供的CNN入门教程也非常类似。

本节所介绍的网络包含每层之后的输出TensorShape。这些层按照自左向右、自上向下的顺序被依次读取,且存在关联的层被分为一组。当输入经过网络时,其 高度和宽度都会减小,而其深度会增加。深度值的增加减少了使用该网络所需的计算量。
Stanford Dogs数据集
用于训练该模型的数据集可从Stanford的计算机视觉站点http://vision.stanford.edu/aditya86/ImageNetDogs/ 下载。训练模型时需要事先下载相关的数据。下载完包含所有图像的压缩文件后,需要将其解压至一个新的名为imagenet-dogs的目录下,该目录应当与用于构建模型的代码位于同一路径下。
由Stanford提供的压缩文件包含被组织为120个不同品种的狗的图像。该模型的目标是将这个数据集中80%的图像用于训练,而用其余20%做测试。如果这是一个 产品模型,则还应预留一些原始数据做交叉验证。为验证模型的准确性,交叉验证是一个有用的步骤,但该模型的设计初衷只是为说明这个过程,而非出于完整性 的考虑。
这个数据压缩包遵循了ImageNet的实践原则。每个狗品种都对应一个类似于n02085620-Chihuahua的文件夹,其中目录名称的后一半对应于狗品种的英语表述 (Chihuahua)。在每个目录中,都有大量属于该品种的狗的图像,每幅图像都为JPEG格式(RGB)且尺寸各异。各图像尺寸不一是一种挑战,因为TensorFlow希望 各张量都具有相同的维数。
将图像转为TFRecord文件
被组织在某个目录中的原始图像无法直接用于训练,因为这些图像尺寸不一,且相应的品种标签也不在图像文件中。将图像提前转换为TFRecord文件将有助于
加速训练,并简化与图像标签的匹配。另一个好处是与训练和测试有关的图像可以事先分离,这样当训练开始时,就可利用检查点文件对模型进行不间断的测试。
转换图像数据格式时需要将它们的颜色空间变为灰度空间,将图像尺寸修改为统一尺寸,并将标签依附于每幅图像。在训练开始前,这种转换应当仅进行一
次,通常它会花费较长的时间。

这个例子展示了该文档的结构。利用glob模块可枚举指定路径下的目录,从而显示出数据集中的文件结构。文件名中的8个数字对应于ImageNet中每个类别的 WordNet ID。ImageNet网站拥有一个可依据WordNet ID查询图像细节的浏览器。例如,要查看Chihuahua(吉娃娃)品种的样本,可通过下列网址访问http://www.image- net.org/synset?wnid=n02085620。
from itertools import groupby
from collections import defaultdict
training_dataset = defaultdict(list)
testing_dataset = defaultdict(list)
#将文件名分解为品种和想应的文件名,品种对应于文件夹名称
image_filename_with_breed = map(lambda filename:(filename.split("/")[2],filename),image_filename)
#依据品种(上述返回的元组的第0个分量)对图像分组
for dog_breed,breed_images in groubby(image_filename_with_breed,lambda x:x[0]):
#枚举每个品种的图像,将大致20%的图像划入测试集
for i,breed_image in enumerate(breed_images):
if i % 5 ++ 0:
testing_dataset[dog_breed].append(breed_image[1])
else:
training_dataset[dog_breed].append(breed_image[1])
#检查每个品种的测试图像是否至少有全部图像的18%
breed_training_count = len(training_dataset[dog_breed])
breed_testing_count = len(testing_dataset[dog_breed])
assert round(breed_testing_count/(breed_training_count+breed_testing_count),2) > 0.18,"Not enough testing images"
这段示例代码将目录和图像(’./imagenet-dogs/n02085620-Chihuahua/n02085620_10131.jpg’)组织到了两个与每个品种相关的字典中,这些字典中包含了属于各品种 的所有图像。现在,每个字典就按照下列格式包含了所有的Chihuahua(吉娃娃)图像:

将各品种的狗的图像组织到这些字典中能够简化选择每种类型的图像并对其归类的过程。在预处理阶段,所有品种的狗的图像都会被依次遍历,并依据列表中的文件名被打开。
def write_records_file(dataset,record_location):
#用dataset中的图像填充一个TFRecord 文件,并将其类别包含进来
writer = None
#枚举dataset,因为当前索引用于文件进行划分,每隔100幅图像,训练样本的信息就被写入到一个新的TFRecord文件中,以加快写操作的进程
current_index= 0
for breed,images_filenames in dataset.items()
for image_filename in images_filenames:
if current_index % 100 == 0:
if writer:
writer.close()
record_filename = "{record_location}-{current_index}.tfrecords".format(rercord_location = record_location,current_index = current_index)
writer = tf.python_io.TFRecordWriter(record_filename)
current_index += 1
image_file = tf.read_file(image_filename)
#在ImageNet的狗的图像中,在少量无法被TensorFlow识别为JPEG的图像,利用try/catch可将这些图像忽略
try:
image = tf.image.decode_jpeg(image_file)
except:
print(image_filename)
continue
#转换为灰度图可减少处理的计算量和内存占用,但是这不是必须的
grayscale_image = tf.image.rgb_to_grayscale(image)
reszied_image = tf.image.resize_images(grayscale_image,250,151)
#这里之所以使用tf.cast,是因为虽然尺寸更改后的图像的数据类型是浮点类型,但是RGB值尚未转到[0,1)区间
image_bytes = sess.run(tf.cast(resized_image,tf.uint8)).tobytes()
#将标签按字符串存储较高效,推荐的做法是将其转成整数索引或one-hot的秩1张量
image_label = breed.encode("utf-8")
example = tf.train.Example(features=tf.train.Features(feature={
‘label’:
tf.train.Feature(bytes_list=tf.train.BytesList(value=[image_label]))
'image':
tf.train.Feature(bytes_list=tf.trainBytesList)
}))
writer.write(example.SerializeToString())
writer.close()
write_records_file(testing_dataset,"./output/testing-image/testing-image")
write_records_file(training_dataset,"./output/training-images/training-image")
这段示例代码完成的任务包括:打开每幅图像,将其转换为灰度图,调整其尺寸,然后将其添加到一个TFRecord文件中。这个逻辑与之前的例子基本一致,唯 一的区别是这里使用了tf.image.resize_images函数。这个尺寸调整方法会将所有图像变为相同的尺寸,即便会有扭曲发生。例如,假设有一幅纵向的图像和一幅横向的 图像,若用这段代码调整两者的尺寸,则横向图像的输出将会产生扭曲。这种扭曲之所以发生,是因为tf.image.resize_images并不考虑图像的长宽比(宽度与高度的比 值)。为了对一组图像进行恰当的尺寸调整,裁剪或边界填充是一种推荐的方法,因为这些方式能够保持图像的纵横比,不至于使图像产生扭曲。
加载图像
一旦测试集和训练集被转换为TFRecord格式,便可按照TFRecord文件而非JPEG文件进行读取。我们的目标是每次加载少量图像及相应的标签。
filename_queue = tf.train.string_input_producer(tf.train.match_filenames_once("./output/training-images/*tfrecords"))
reader = tf.TFRecordReader()_,serialized = reader.read(filename_queue)
features = tf.parse_single_example(
serialized,
features={
'label':tf.FixedLenFeature([],tf.string),
'image':tf.FixedLenFeature([],tf.string)
})
record_image = tf.decode_raw(features['image'],tf.uint8)
#修改图像的形状有助于训练和输出的可视化
image = tf.reshape(record_image,[250,151,1])
label = tf.cast(features['label'],tf.string)
min_after_dequeue = 10
batch_size = 3
capacity = min_after_dequeue + 3 * batch_size
image_batch,label_batch = tf.train.shuffle_batch([image,label],batch_size=batch_size,capacity=capacity,min_after_dequeue = min_after_dequeue)
这段示例代码通过匹配所有在训练集所在目录下找到的TFRecord文件而加载训练图像。每个TFRecord文件中都包含了多幅图像,但tf.parse_single_example将只从 该文件中提取单个样本。之前讨论过的批运算可用于同时训练多幅图像。对多幅图像进行批处理非常有用,因为这些运算既可对多幅图像进行处理,也可对单幅图 像进行处理。批处理时,必须要满足的条件是系统拥有足够的内存。
当可用的图像都加载到内存中后,接下来的步骤便是创建用于训练和测试的模型。
模型
这里所使用的模型与前面的MNIST卷积网络的例子非常类似,也常出现在介绍卷积神经网络的TensorFlow入门教程中。该模型的架构虽然简单,但对于解释图 像分类与识别中所使用的不同技术却非常有价值。更复杂的模型可参考AlexNet的设计,它引入了更多的卷积层。
#将图像转换为灰度位于[0,1)的浮点类型,以与convolution2d期望的输入匹配
float_image_batch = tf,image.convert_image_dtype(image_batch,tf,float32)
conv2d_layer_one = tf.contrib.layers.concolution2d(
float_image_batch,
num_output_channels = 32, #要生成的滤波器的数量
kernel_size(5,5),#滤波器的宽度和高度
activation_fn = tf.nn.relu,
weight_init = tf.random_normal,
stride = (2,2),
trainable = True)
pool_layer_one = tf.nn.max_pool(conv2d_layer_one,
ksize = [1,2,2,1],
strides = [1,2,2,1]
padding = 'SAME')
#注意,卷积输出的第一维和最后一维未发生改变,但中间的两维发生了变化
conv2d_layer_one.get_shape(),pool_layer_one.get_shape()
)

该模型的第1层是利用tf.contrib.layers.convolution2d创建的。值得注意的是weight_init被设置为正态随机值,这意味着第一组滤波器填充了服从正态分布的随机数 (自TensorFlow 0.9起,该参数被重命名为weights_initializer)。这些滤波器被设置为trainable,以便当将信息输入给网络时,这些权值能够调整,以提高模型的准确率。
当将卷积运用于图像之后,利用一个max_pool运算将输出降采样。该运算之后,由于在池化运算中使用的ksize和strides,卷积的输出形状减半。这里输出形状的 减小,并不改变滤波器的数量(输出通道)或图像批数据的尺寸。减少的分量与图像(滤波器)的高度和宽度有关。
conv2d_layer_two = tf,contrib.layers.convolution2d(
pool_layer_one,
num_output_channels = 64,
kernel_size=(5,5),
activation_fn = tf.nn.relu,
weight_init = tf.random_normal,
stride = (1,1),
trainable=True)
pool_layer_two = tf.nn.max_pool(conv2d_layer_two,
ksize=[1,2,2,1]
strides = [1,2,2,1],
padding = 'SAME')
conv2d_layer_two.get_shape(),pool_layer_two.get_shape()
)
)

与第1层相比,第2层改动很小,唯一的区别在于滤波器的深度。现在滤波器的数量变为第一层的2倍,同时减小了图像的高度和宽度。多个卷积和池化层连续地 减少了输入的高度和宽度,同时进一步增加了深度。
此时,可进一步增加卷积和池化步骤。在许多架构中,卷积层和池化层都超过5层。最复杂的架构需要的训练和调试时间也更长,但它们能够匹配更多更复杂的 模式。在本例中,为解释卷积网络的基本原理,使用两个卷积层和池化已经足够了。
被处理的张量仍然相当复杂,接下来的步骤是将图像中的每个点都与输出神经元建立全连接。由于在本例中,后面要使用softmax,因此全连接层需要修改为二 阶张量。张量的第1维将用于区分每幅图像,而第2维对应于每个输入张量的秩1张量。
flattened_layer_two = tf.reshape(
pool_layer_two,
[
batch_size,#image_batch 中的每幅图像
-1 #输入的其他所有维
]
)
flattened_layer_two.get_shape()
得到输出:

tf.reshape拥有一个特殊值,其可用于指示和使用其余所有维。在这段示例代码中,-1用于将最后一个池化层调整为一个巨大的秩1张量。 池化层展开后,便可与将网络当前状态与所预测的狗的品种关联的两个全连接层进行整合。

这段示例代码创建了网络的最后一个全连接层,其中的每个像素都与每个狗的品种关联着。该网络的每一步都会通过将输入图像转化为滤波器来减小它们的尺寸,这些滤波器之后又会与一个品种的狗(标签)进行匹配。这项技术减少了训练和测试一个网络所需的计算量,同时使输出更具一般性。
训练
一旦模型做好了训练的准备,最后的步骤便与本书前面的章节所讨论的过程完全一致。依据模型对输入到训练优化器(作用是优化每层的权值)的训练数据的真实标签和模型的预测结果计算模型的损失。这个优化过程会经历数次迭代,每次迭代时都试图提升模型的准确率。
对于该模型,有一点需要注意,那就是在训练过程中,大部分分类函数(tf.nn.softmax)都要求标签为数值类型。在介绍从TFRecord文件加载图像的那一节中已 经强调过这一点。在本例中,每个标签都是一个类似于n02085620-Chihuahua的字符串。由于tf.nn.softmax无法直接使用这些字符串,所以需要将每个标签转换为一个独 一无二的数字。将这些标签转换为整数表示应当在预处理阶段进行。
对于本数据集,每个标签都被转换为一个代表包含所有狗的品种的列表中名称索引的整数。完成该任务有多种方法。在本例中,将使用一个新的TensorFlow工具 运算tf.map_fn。

这段示例代码使用了两种不同形式的map运算。第一种形式的map用于依据一个目录列表创建一个仅包含狗的品种名的列表。第二种形式的map是tf.map_fn,它是 一个TensorFlow运算,可用指定的函数对数据流图中的张量进行映射。tf.map_fn用于生成一个仅包含每个标签在所有类标签构成的列表中的索引的秩1张量。这样,tf.nn.softmax便可利用这些独一无二的整数对狗的品种进行预测。
用TensorBoard调试滤波器
CNN拥有多个可调整的部分,它们在训练阶段可能会引发一些问题,从而导致模型的准确率较差。在调试CNN中的问题时,通常可从观察滤波器(卷积核)在每轮迭代后的变化入手。当网络试图依据训练方法学习最精确的一组权重时,滤波器中的每个权值都会持续不断地发生改变。
在一个设计良好的CNN中,当第一个卷积层开始工作时,输入权值被随机初始化(在本例中使用了weight_init=tf.random_normal)。这些权值通过一幅图像激活,且激活函数的输出(特征图)也是随机的。可将特征图作为图像可视化,输出的外观与原始图像类似,并被施加了静力(static)。静力是由所有权值的随机激发所 导致的。经过多轮迭代之后,权值不断地被调整以拟合训练反馈,每个滤波器都趋于一致。当网络收敛时,各个滤波器都与从图像中能够找到的不同的细小模式非 常类似。下图展示的是一幅作为训练数据的尚未经过第一个卷积层的原始灰度图像。

下面再给出一个由第1个卷积层输出的特征图,它突出了输出的随机性。

调试CNN时需要能够熟练使用这些滤波器。截至本书撰写之时,TensorBoard尚未提供任何显示滤波器或特征图的内置支持。可利用tf.image_summary运算得到训 练后的滤波器和所生成的特征图的简单视图。为数据流图添加一个图像概要输出(image summary output)能够对所使用的滤波器和通过将它们运用于输入图像而得到 的特征图获得整体性的了解。
一个值得一提的Jupyter Notebook扩展是TensorDebugger,它目前尚处在开发初期。该扩展拥有一种能够在迭代中以GIF动画形式查看滤波器变化的功能。
小结
卷积神经网络是一种非常有用的神经网络架构,在TensorFlow中实现这种架构只需要编写极少量的代码。虽然在设计时它们 对图像给予了关注,但CNN并不局限于图像这一种输入。卷积可运用于从音乐到医药的多个行业,且在不同行业中应用CNN的 方式都是类似的。目前,TensorFlow是为2D卷积设计的,但利用TensorFlow对高维输入进行卷积也是有可能的。
虽然CNN理论上可以运用于自然语言数据(文本),但它却并不是为这种类型的输入设计的。文本输入通常存储在 SparseTensor中,其中输入的大部分分量均为0。CNN是为使用稠密的输入设计的,其中的每个值都是重要的,且输入的大部分分 量都非0。使用文本数据非常有挑战性,而这正是下一章所要解决的问题。
循环神经网络与自然语言处理
在上一章中,我们学习了如何对静态图像进行分类。这是机器学习中很大的一个应用领域,但机器学习的研究内容绝不仅仅局限于此。本章将探讨序列模型(sequential model)。这些模型的强大之处在于借助它们可对序列输入进行分类或标记,生成文 本序列或将一个序列转换为另一个序列。
然而,我们在本章所要学习的内容与静态分类和回归并无任何不同。循环神经网络提供了一些构件,可以很好地切入全连接
层和卷积层的工具集。下面首先介绍相关基础知识。
循环神经网络简介
时序的世界
许多真实问题本质上都是序列化的(sequential)。自然语言处理(NLP)中几乎所有的问题都是序列化的。例如,段落是由句子构成的序列,而单词是字 符构成的序列。与之密切相关的是音视频片段,它们都是随时间变化的帧序列,甚至股票价格也仅在沿时间轴(如果有的话)进行分析时才有意义。
在所有这些应用中,观测的顺序非常重要。例如,句子“I had cleaned my car”可以修改为“I had my car cleaned”,含义就从原来的“我已经洗完车了”变为“我已 安排其他人洗完车”。在口语中,这种时序的依赖关系更为突出,因为一些单词含义相去甚远但发音却可能非常相近,如“wreck a nice beach”的发音与“recognize speech”非常相似,单词必须从语境中进行重构。
如果从这个视角审视前馈神经网络(包括卷积神经网络),便会发现它们的局限性非常大。那些网络都是在单次前馈中对到来的数据进行处理,且假定所
有的输入都是独立的,因此会将数据中蕴涵的许多模式丢失。虽然可以对输入进行长度填充,然后将整个序列送入网络,但这种做法并未很好地捕捉到序列的本质。
循环神经网络(recurrent neural network,RNN)是一类对时间显式建模的神经网络。用于构建RNN的神经元同样也接收来自其他神经元的加权输入。然 而,在RNN中,神经元既允许与更高的层建立连接,也允许与更低的层建立连接。RNN网络的这些隐含活性值会在同一序列的相邻输入之间被记忆。

自20世纪80年代以来,出现了RNN的各种变体,但均未获得广泛的应用,原因是那时的计算资源匮乏且训练中存在诸多难点,然而近年来情况已有改观。 随着一些重要架构的出现,如2006年提出的LSTM,RNN已经拥有了非常强大的应用。它们能够很好地完成许多领域的序列任务,如语音识别、语音合成、手 写连体字识别、时间序列预测、图像标题生成以及端到端的机器翻译等。
接下来,将首先深入探讨RNN及其优化方法,同时介绍必要的数学背景知识。之后,会介绍有助于克服标准RNN某些局限性的一些变种。当掌握了这些 工具,我们将深入介绍四种自然语言处理任务,并运用RNN解决其中的问题。我们将逐一介绍所有的步骤,包括用TensorFlow完成数据处理、模型设计、实现及训练。
近似任意程序
下面开始介绍RNN,并试着培养一些直觉。之前介绍过的前馈神经网络只能在固定长度的向量上工作。例如,它们可将28×28像素的图像映射为10个可能类别上的概率分布,且计算在固定的步数(即层的数目)内完成。相比之下,无论输入还是输出为可变长向量,或输入输出均为可变长向量,循环神经网络都可以应对。
RNN基本上是一个由神经元和连接权值构成的任意有向图。输入神经元(input neuron)拥有“到来”连接,因为它们的活性值是由输入数据设置的。输出神 经元(output neuron)也只是数据流图中的一组可从中读取预测结果的神经元。数据流图中的所有其他神经元都被称为隐含神经元(hidden neuron)。
RNN所执行的计算与普通的神经网络非常类似。在每个时间步,都会通过设置输入神经元而为网络提供输入序列的下一帧。相比于前馈网络,我们无法将 隐含活性值丢弃,因为它们还将作为下一个时间步的附加输入。RNN的当前隐含活性值被称为状态。在每个序列的最开始,我们通常会设置一个值为0的空状态。
FFNN和RNN的简化表示:

RNN的状态依赖于当前输入和上一个状态,而后者又依赖于更上一步的输入和状态。因此,状态与序列之前提供的所有输入都间接相关,从而可理解为工作记忆(working memory)。
可将神经网络与计算机程序做一类比。例如,假设希望从一幅包含手写文本的图像中识别字母,我们准备尝试通过编写一个使用变量、循环、分支语句的Python程序来解决该问题。不妨大胆尝试,但笔者认为要想让程序稳健地工作是极为困难的。
一个好消息是可选择另一种方式——依据样本数据训练一个RNN模型。正像我们通常会将中间信息保存在变量中一样,RNN也会学习将其中间信息保存
在自身的状态中。类似地,RNN的权值矩阵定义了它所执行的程序,决定了在隐含活性值中保存什么输入,以及如何将不同活性值整合为新的活性值和输出。
实际上,带有sigmoid激活函数的RNN已由Sch?fer和Zimmermann于2006年证明是图灵完备的(Turing-complete)。这意味着,当给定正确的权值时,RNN可 完成与任意计算程序相同的计算。然而这只是一个理论性质,因为当给定一项任务时,不存在找到完美权值的方法。尽管如此,利用梯度下降法仍然能够得到相当好的结果,相关内容将在下一节中进行介绍。
在开始探讨RNN的优化方法时,读者可能会疑惑,既然能够编写Python程序,为什么还需要RNN呢?可以这样理解,可能的权值矩阵构成的空间相比可能的C程序构成的空间要更加容易研究。
随时间反向传播
既然对于何为RNN以及为何其架构很酷已有了一些基本了解,下面来探讨如何找到一个“好”的权值矩阵,或如何对权值进行优化。对于前馈网络,最流行
的优化方法是基于梯度下降法。然而,如何在RNN这种动态系统中将误差反向传播并非那么显而易见。

优化RNN可采取这样一种技巧,即沿时间轴将其展开,之后就可使用与优化前馈网络相同的方式对RNN进行优化。例如,假设希望对一个长度为10的序 列进行处理。可将隐含神经元复制10次,并将它们的连接从一个副本跨连到相邻的另一个副本。这样便可将那些循环连接移除,而不更改计算的语义。经过上 述处理,便形成了一个前馈网络,且相邻时间步之间的权值都拥有相同的强度。按时间展开RNN不会使计算发生改变,只是切换为了另一个视图。
 这样,为计算误差相对于各权重值得梯度,便可对这个展开的RNN网络运用标准的反向传播算法。这种算法被称为随时间反向传播(Back-PropagationThroughTime,BPTT)。该算法将返回与时间相关的误差对每个权值(也包括那些联结 相邻副本的权值)的偏导。为保持联结权值相同,可采用普通的联结权值处理方法,即将它们的梯度相加。请注意,这种方式与卷积神经网络中处理卷积滤波器的方式等价。
这样,为计算误差相对于各权重值得梯度,便可对这个展开的RNN网络运用标准的反向传播算法。这种算法被称为随时间反向传播(Back-PropagationThroughTime,BPTT)。该算法将返回与时间相关的误差对每个权值(也包括那些联结 相邻副本的权值)的偏导。为保持联结权值相同,可采用普通的联结权值处理方法,即将它们的梯度相加。请注意,这种方式与卷积神经网络中处理卷积滤波器的方式等价。
序列的编码和解码
前面RNN的展开视图不但对优化十分有用,它还为RNN及其输入和输出数据的可视化提供了一种直观的方式。在开始具体实现之前,先快速了解一下RNN实现的到底是何种映射。序列任务往往有多种形式:有时,输入为一个序列,而输出为一个向量;或者反过来。对于这样的例子以及更复杂的情 形,RNN都能够处理。

序列标注(sequential labelling)其实在之前的小节中我们已经接触过了。在这种任务中,将一个序列作为输入,并训练网络为每帧数据产生正确的输出。因 此,基本上可以说序列标注完成的是一个序列到另一个序列的等长映射。
在序列分类(sequential classification)设置下,每个序列输入都对应一个类别标签。在这种设置下,可仅选择上一帧的输出训练RNN。在优化期间,更新权 值时,误差将流经所有的时间步以收集和集成每个时间步中的有用信息。
序列生成(sequential generation)与序列分类恰好相反,它所定义的问题是,给定一个类别标签,如何生成一些序列。为了生成序列,可将输出反馈给网络 作为下一步输入。这是合理的,因为实际输出通常都与这种神经网络的输出不同。例如,网络的输出可能是一个在所有类别上的概率分布,但我们仅会选择最 可能的那个类别。
在序列分类和序列生成任务中,可将单个向量视为信息的稠密表示。在前者中,为了对类别做出预测,需要将序列编码为一个稠密向量;在后者中,将稠
密向量解码为一个序列。
对于序列翻译(sequential translation)任务,可将这些方法进行整合。首先对一个域(如英语)中的序列进行编码,然后将最后的隐含活性值解码为另一个 域(如法语)中的一个序列。对于单个RNN模型,这是完全可行的,但当输入和输出在概念层次存在差异时,使用两个不同的RNN,并用第一个模型中最后 的活性值初始化第二个模型则是有意义的。使用单个网络时,需要在序列之后传入一个特殊符号作为输入,以通知网络何时停止编码,并开始解码。

最常见的情况下,会使用一种称为带有输出投影的RNN网络结构。这种RNN具有全连接的隐含单元,以及一些映射为这些隐含单元的输入和从这些隐含 单元映射得到的输出。看待这种模型的另一种方式是:这种RNN模型的所有隐含单元都为输出,而其上堆叠了另外一个前馈层。稍后将了解到,这正是我们用 TensorFlow实现RNN的方式,因为它既方便,又允许为隐含单元和输出单元指定不同的激活函数。
实现第一个循环神经网络
下面具体实现到目前为止所学习到的RNN知识点。TensorFlow支持RNN的各种变体,可从tf.nn.rnn_cell模块中找到这些变体的实现。借助tensorflow.models.rnn
中的tf.nn.dynamic_rnn()运算,TensorFlow还为我们实现了RNN动力学。 该函数还有一个版本,可向数据流图添加展开运算,而不使用环。然而,该版本会消耗更多的内存,而且没有实际的益处。因此,我们推荐使用较新的
dynamic_rnn()运算。
关于参数,dynamic_rnn()接收一个循环网络的定义以及若干输入序列构成的批数据。就目前而言,所有的序列都是等长的。该函数会向数据流图创建 RNN所需的计算,并返回保存了每个时间步的输出和隐含状态的两个张量。
import tensorflow as tf
from tensorflow.models.rnn import rnn_cell
from tensorflow.models.rnn import rnn
#输入数据的维数为batch_size*sequence_length*frame_size
#不希望限制批次的大小,将第1维的尺寸设为None
sequence_length = ...
frame_size = ...
data = tf.placeholder(tf.float32,[None,sequence_length,frame_size])
num_neurons = 200
network = rnn_cell.BasicRNNCell(num_neurons)
#为sequence_length步定义模拟RNN的运算
outputs,states = rnn.dynamic_rnn(network,data,dtype = tf.float32)
这样便完成了RNN的定义,并将它沿时间轴展开,我们只需加载一些数据,并选择一种TensorFlow提供的优化器,如tf.train.RMSPropOptimizer或 tf.train.AdamOptimizer训练网络即可。在本章后续小节中,我们还将看到更多利用RNN解决实际问题的例子。
梯度消失与梯度爆炸
在上一节中,我们定义了RNN,并将其沿时间轴展开,以对误差进行反向传播和运用梯度下降法。然而,这种模型的表现目前并不尽如人意,尤其是它无
法捕捉输入帧之间的长时依赖关系,而这种关系正是NLP任务所需要的。
下面给出一个示例任务,该任务涉及长时依赖性,要求RNN能够判别给定输入序列是否为给定语法的一部分。为完成该任务,网络必须记住其中含有许多
后续不相关的帧的序列的第一帧。对于到目前为止我们所接触的传统RNN模型,为什么这会是一个问题?

RNN之所以难于学习这种长时依赖关系,原因在于优化期间误差在网络中的传播方式。前文提到过,为了计算梯度,要将误差在展开后的RNN中传播。 对长序列而言,这种展开的网络的深度将会非常大,层数非常多。在每一层中,反向传播算法都会将来自网络上一层的误差乘以局部偏导。
如果大多数局部偏导都远小于1,则梯度每经过一层都会变小,且呈指数级衰减,从而最终消失。类似地,如果许多偏导都大于1,则会使梯度值急剧增大
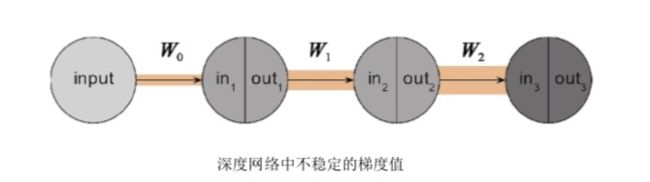
下面计算上图所示网络的梯度值。该网络的每层仅设置了一个隐节点,目的是帮助你更好地理解这个问题。将各个层的局部偏导
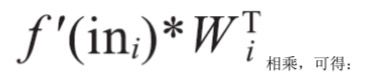
从上式可以看出,误差项中包含了作为相乘项的权值矩阵的转置。在这个示例网络中,权值矩阵仅有一个分量,因此可以比较容易地看出当大多数权值都
小于(或大于)1时,这个梯度值便会接近于0(或无穷大)。在一个权值矩阵为实数类型的较大规模的网络中,若权值矩阵的特征值小于(或大于)1时,也 会出现同样的问题。
实际上,在任何深度网络中,该问题都是存在的,而非只有循环神经网络中才有这样的问题。在RNN中,相邻时间步是联结在一起的,因此,这样的权值 的局部偏导要么都小于1,要么都大于1,原始(或展开的)RNN中每个权值都会向着相同的方向被缩放。因此,相比于前馈神经网络,梯度消失或梯度爆炸这 个问题在RNN中更为突出。
在许多问题中,都伴有很小或很大的梯度值。当梯度的各分量接近于0或无穷大时,训练分别会出现停滞或发散。此外,由于我们做的是数值优化,因 此,浮点精度也会对梯度值产生影响。该问题也被称为深度学习中的基本问题,在近年来已受到许多研究者的关注。目前最流行的解决方案是一种称为长短时 记忆网络(long-short term memory,LSTM)的RNN架构。下一节将对该架构进行探讨。
长短时记忆网络
LSTM是一种特殊形式的RNN,由Hochreiter和Schmidhuber于1997年提出,它是专为解决梯度消失和梯度爆炸问题而设计的。在学习长时依赖关系时它有着 卓越的表现,并成为RNN事实上的标准。自从该模型被提出后,人们相继提出了LSTM的若干变种,这些变种的实现已包含在TensorFlow中,相关内容将在本 节稍后加以强调。
为解决梯度消失和梯度爆炸问题,LSTM架构将RNN中的普通神经元替换为其内部拥有少量记忆的LSTM单元(LSTM Cell)。如同普通RNN,这些单元也 被联结在一起,但它们还拥有有助于记忆许多时间步中的误差的内部状态。
LSTM的窍门在于这种内部状态拥有一个固定权值为1的自连接,以及一个线性激活函数,因此其局部偏导始终为1。在反向传播阶段,这个所谓的常量误 差传输子(constant error carousel)能够在许多时间步中携带误差而不会发生梯度消失或梯度爆炸。
![]()
尽管内部状态的目的是随许多时间步传递误差,LSTM架构中负责学习的实际上是环绕门(surrounding gates),这些门都拥有一个非线性的激活函数(通常 为sigmoid)。在原始的LSTM单元中,有两种门:一种负责学习如何对到来的活性值进行缩放,而另一种负责学习如何对输出的活性值进行缩放。因此,这种 单元可学习何时包含或忽略新的输入,以及何时将它表示的特征传递给其他单元。一个单元的输入会送入使用不同权值的所有门中。
也可将循环神经网络视为一些“层”,因为它可以用作规模更大的网络架构的组成部分。例如,我们可首先将时间步送入若干卷积和池化层,然后用一个 LSTM层处理这些输出,并在位于最后的时间步LSTM活性值上添加一个softmax层。
TensorFlow为这样的LSTM网络提供了LSTMCell类,它可直接替换BasicRNNCell类,同时该类还提供了一些额外的开关。尽管该类名称从字面上看只有 LSTM单元,但实际上表示了一个完整的LSTM层。在后面的小节中,我们将学习如何将LSTM层与其他网络进行连接,以形成更大规模的网络。
另一种扩展是添加窥视孔连接(peepholeconnection),以使一些门能够看到单元的状态 。提出该变种的作者声称当任务中涉及精确的时间选择和间隔 时,使用窥视孔连接是有益的。TensorFlow的LSTM层支持窥视孔连接。可通过为LSTM层传入use_peepholes=True标记将窥视孔连接激活。
基于LSTM的基本思想,ChungJunyoung等于2014年提出了门限循环单元(GatedRecurrentUnit,GRU) 。与LSTM相比,GRU的架构更简单,而且只需更 少的计算量就可得到与LSTM非常相近的结果。GRU没有输出门,它将输入和遗忘门整合为一个单独的更新门(update gate)。
更新门决定了内部状态与候选活性值的融合比例。候选活性值是依据由重置门(reset gate)和新的输入确定的部分隐含状态计算得到的。TensorFlow的 [5]
GRU层对应GRUCell类,除了该层中的单元数目,它不含任何其他参数。如果希望进一步了解GRU,笔者推荐参阅Jozefowicz等发表的ICML’015文章 ,这篇文 章对循环单元架构进行了经验性的探索。

到目前为止,我们研究了带有全连接隐含单元的RNN。这是最一般的架构,因为这种网络能够学会在训练期间将不需要的权值置为0。不过,最常见的做 法是将两层或多层全连接的RNN相互堆叠。这仍可视为一个其连接拥有某种结构的RNN网络。由于信息只能在两层之间向上流动,与规模较大的全连接RNN 相比,多层RNN拥有的权值数目更少,而且有助于学习到更多的抽象特征。
词向量嵌入
本节将实现一个能够学习词向量的模型。对于各种NLP任务,这是一种表示词的强大方式。词向量嵌入这个话题近年来颇受关注,因为最近提出的方法已经可 以足够高效地处理大规模文本语料库。对于该任务,我们不打算使用RNN,但对于后续其他任务,我们都将依赖本节所介绍的内容和方法。如果你对词向量的概 念以及像word2vec这样的工具非常熟悉,但对于自己实现相关算法不感兴趣,可以放心地跳过这一节。
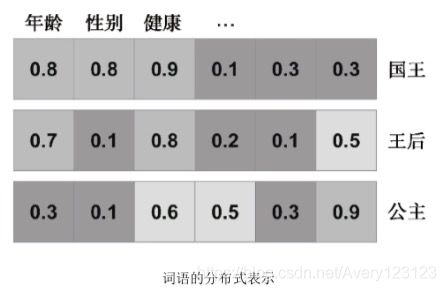
为何要将词表示为向量?最简单的方式是将词送入一个独热编码(one-hot encoding)的学习系统,即表示为一个长度为词汇表长度的向量,除该词语对应位置的元素为1外,其余元素均为0。这种方法有两个问题:首先,对于实际应用,这种表示方法会导致向量的维数很高,因为在自然语言中有许多不同的词语;其次, 独热编码表示无法刻画不同词语之间的语义关联(而这种关联是显然存在的)。

作为语义关联问题的一个解决方案,依据共生关系(co-occurrence)表示单词的思路由来已久。这种方法的基本思路是,遍历一个大规模文本语料库,针对每个单词,统计其在一定距离范围(例如5)内的周围词汇。然后,用附近词汇的规范化数量表示每个词语。这种方法背后的思想是在类似语境中使用的词语在语义上也是相似的。这样,便可运用PCA或类似的方法对出现向量(occurrence vector)降维,从而得到更稠密的表示。虽然这种方法具有很好的性能,但它要求我们追踪所有词汇的共生矩阵,即一个宽度和高度均为词汇表长度的方阵。
在2013年,Mikolov等提出了一种依据上下文计算词表示的实用有效的方法,相应的文章是Mikolov、Tomas等的《Efficient estimation of word representations in vector space》(arXiv preprint arXiv:1301.3781(2013))。他们的skip-gram模型从随机表示开始,并拥有一个试图依据当前词语预测一个上下文词语的简单分类器。误差 同时通过分类器权值和词的表示进行传播,我们需要对这两者进行调整以减少预测误差。研究发现,在大规模语料库上训练该模型可表示向量逼近压缩后的共生向 量。下面利用TensorFlow实现skip-gram模型。
准备维基百科语料库
在探讨skip-gram模型的细节之前,需要准备数据集。在本例中,我们将使用英文维基百科转储文件。默认的转储文件包含所有页面的完整修订历史,但从当前 页面版本中,我们已经能够获取到约100GB的充足数据。本练习对其他语言同样适用,可从维基百科下载站点https://dumps.wikimedia.org/backup-index.html 获取所有可 用转储文件的概况。
import bz2
import collections
import os
import re
class Wikipedia:
def __init__(self,url,cache_dir,vocabulary_size = 10000):
pass
def __iter__(self):
"""遍历表示为由词语索引构成的列表的页面"""
pass
def vocabulary_size(self):
pass
def encode(self,word):
"""获取一个字符串词语的词汇索引"""
pass
def decode(self,index):
""" 依据词汇索引返回字符串词语"""
pass
def _read_pages(self,url):
"""
从维基百科转储存文件提取单词,并将它们保存到页面文件
每个页面都包含一行由空格分隔的一行单词
"""
def _build_vocabulary(self,vocabulary_size):
"""
统计页面文件中的单词数,并将词汇表文件中出现频率最高的词语写入文件
"""
pass
def _tokenize(cls,page):
pass
为了以正确的格式表示数据,还需执行若干步骤。正如本书前文所讲的,数据收集和清洗是非常迫切和重要的任务。最终,我们决定遍历表示为独热编码词语
的维基页面。为此,需要完成下列步骤:
1)下载转储文件,提取页面及其中的词语。
2)统计词语的出现次数,构建一个由最常见词语构成的词汇表。
3)利用该词汇表对提取的页面进行编码。
要将整个语料库一次性放入主存是非常困难的,因此通过逐行读取文件,并立即将结果写入磁盘的方式对数据流执行这些操作。按照这种方式,在不同步骤之间保存了检查点,以避免程序崩溃时不得不重新开始。现在利用下面的类来实现维基百科数据的处理。在__init__()中,可利用文件存在性检查理解检查点逻辑。
def __init__(self,url,cache_dir,vocabulary_size = 10000):
self._cache_dir = os.path.expanduser(cache_dir)
self._pages_path = os.path.join(self._cache_dir,'pages.bz2')
self._vocabulary_path = os.path.join(self._cache_dir,'vocabulary.bz2')
if not os.path.isfile(self._pages_path):
print('Read pages')
self._read_pages(url)
if not os.path.isfile(self._vocabularty_path):
print('Build vocabulary')
with bz2.open(self._vocabulary_path,'rt') as vocabulary:
print('Read vocabulary')
self._vocadulary = [x.strip() for x in vocabulary]
self._indices = {
x:i for i,x in enumerate(self._vocabulary)}
def __iter__(self):
"""遍历表示为由词语索引构成的列表的页面"""
with bz2.open(self._pages_path,'rt') as pages:
for page in pages:
words = page.strip().split()
words = [self.encode(x) for x in words]
yield words
def vocabulary_size(size):
return len(self._vocabulary)
def encode(self,word):
"""获取一个字符串词语的词汇索引"""
return self._indices.get(word,0)
def decode(self,index):
""" 依据词汇索引返回字符串词语"""
return self._vocabulary[index]
你可能已经注意到,我们仍然必须为该类实现两个重要的函数。第一个是_read_pages(),它的功能是下载维基百科转储文件——一个经过压缩的XML文件, 并遍历各页面,从中提取移除格式后的纯文本。为了读取压缩的转储文件,需要使用bz2模块,它提供了一个open()函数,这个函数的工作方式与其标准版本类 似,但更关注压缩和解压缩,即使以流式传输文件也是如此。为节省磁盘空间,对于中间结果也应做压缩处理。用于提取词语的正则表达式仅捕捉任意的连续字母 序列以及一些单独出现的特殊字母。


在进行独热编码时,需要一个词汇表。之后,便可按照每个词在词汇表中的索引对其进行编码。为了将一些拼写错误或极不常见的词语移除,词汇表仅包含vocabulary_size–1个最常见的词语及一个用于标识所有不在词汇表中的词语的标记。这个标记也为我们提供了一个可用于未出现的单词的词向量。

由于提取了纯文本,并为各单词定义了编码,因此可动态地形成训练样本。这是非常有利的,因为要保存这些样本需要大量存储空间。由于大部分时间都用于
训练,所以这不会对性能造成太大影响。我们也希望将生成的样本组织到一些批数据中,以使训练更加高效。借助这个模型,能够使用大的批数据,因为分类器并不需要占用大量内存。
那么如何形成训练样本?前文曾介绍过,skip-gram模型会依据当前词语预测上下文词语。在遍历文本时,我们用当前词语作为数据,其周围的词语作为目标创 建训练样本。当上下文尺寸为R=5时,则可从每个单词生成2R=10个训练样本,其中R个词来自当前单词的左边,而将右边的R个单词作为目标值。然而,可能有 人认为对于语义上下文,距离较近的近邻比较远的近邻更为重要。因此,可以为每个单词从范围[1,D=10]中随机选择一个上下文尺寸,尽量少地创建具有较远上 下文词语的训练样本。

模型结构
至此,维基百科语料库已准备完毕,下面定义计算词向量的模型。

初始时,每个单词都被表示为一个随机向量。依据这种单词的中层表示,一个分类器会试图预测它的上下文单词之一的当前表示,然后我们对误差进行传播,
以对权值和输入单词的表示进行微调。因此,这里将tf.Variable用于词的表示。

这里使用了MomentumOptimizer进行模型的优化,虽然不够智能,但效率却非常高。该优化器能够很好地处理大规模维基百科语料库,从而实现skip-gram背后的思想,能够比那些智能的算法利用更多的数据。

现在,我们的模型唯一缺少的部分是分类器。这是成功的skip-gram模型的核心,下面来研究它的工作原理。
噪声对比分类器
对于skip-gram模型,有多种代价函数可选,其中有一种噪声对比估计损失(noise-contrastive estimation loss)已被证明具有优异的性能。理想情况下,我们希望预 测结果与目标尽可能地接近,而且与那些不是当前单词的目标词汇具有较远的距离。可以用softmax分类器对此进行建模,但并不希望每次都计算和训练词汇表中所 有单词的输出。可考虑的解决方案是总使用一些新的随机向量作为负样本,也称为对比样本。经过足够的训练迭代,这种方法可以近似softmax分类器,而且仅需要 十几个类别。TensorFlow为此提供了一个便捷的函数tf.nn.nce_loss。

训练模型
现在,语料库已准备好,模型的定义也完成了。下面给出整合所有功能的代码。训练结束后,可将最终的词向量写入另一个文件。下面的例子仅使用了维基百
科语料库的一个子集,它在普通CPU上训练时长约5个小时。要使用完整的语料库,可从下列链接获取:https://dumps.wikimedia.org/enwiki/20160501/enwiki-20160501- pages-meta-current.xml.bz2。
如你所见,我们利用了AttrDict类,它等价于Python的dict,两者的区别在于,前者可将键作为属性访问,如params.batch_size。更多细节请参考第8章。


经过约5个小时的训练,我们将得到由学习获得的、作为NumPy数组被保存的嵌入表示。虽然在后续章节中将使用该嵌入表示,实际上,如果不希望亲自完成 这些计算,完全可以。笔者为你提供了可在线获取的预训练词向量嵌入模型,并会在后文中需要使用该模型的地方给出下载链接
序列分类
序列分类的任务是为整个输入序列预测一个类别标签。在许多领域中,包括基因和金融领域,这样的问题都极为常见。自然语言处理中的一个突出例子是情绪分析,即从用户撰写的文字预测他对某个给定话题的态度。例如,可以预测提到选举中某位候选人的推文的情绪,并用它来预测选举结果。另一个例子是依据评论预测产品或电影的评分。在NLP社区,这已成为一项基准任务,因为评论中通常包含有数值评分,可以方便地作为目标值。
我们将使用一个来自国际电影数据库(International Movie Database)的影评数据集,该数据集的目标值是二元的——正面的和负面的。在该数据集中,任何只查 看单词是否出现的朴素方法都将失效,因为在语言中通常存在大量否定、反语和模糊性。我们将构建一个可对来自上一节的词向量进行操作的循环神经网络。这个 循环网络将逐个单词地查看每条评论。依据最后的那个单词的活性值,将训练一个用于预测整条评论的情绪的分类器。由于是按照端到端的方式训练模型,RNN将 从单词中收集那些对于最终分类最有价值的信息,并进行编码。
Imdb影评数据集
这个影评数据集是由斯坦福大学的人工智能实验室提供的:
http://ai.stanford.edu/~amaas/data/sentiment/ ,它是一个经过压缩的tar文档,其中正面的和负面的评论可从分列于两个文件夹中的文本文件中获取。我们对这些文本 进行了与上一节完全相同的处理:利用正则表达式提取纯文本,并将其中的字母全部转换为小写。


使用词向量嵌入
在词向量嵌入一节中,曾解释过,嵌入表示比独热编码的词语具有更丰富的语义。因此,如果使RNN工作在影评的被嵌入的而非独热编码的单词上,则有助于 RNN获得更好的性能。为此,可使用上一节中计算得到的词汇表和嵌入表示。相关的代码应当非常简单。我们仅利用词汇表确定单词的索引,并利用该索引找到正确的词向量。下面展示的这个类还会对序列进行填充,使它们都拥有相同的长度,以便将更容易地将多个影评数据批量送入网络。


序列标注模型
我们希望对文本序列所体现的情绪进行分类。由于这是一个有监督学习问题,所以为该模型传入两个占位符:一个用于输入数据data(或输入序列),另一个 用于目标值target(或情绪)。此外,还传入了包含配置参数(如循环层的尺寸、单元架构(LSTM、GRU等))的params对象,以及所要使用的优化器。下面具体 实现相关属性并对其进行详细讨论。


首先获取当前批数据中各序列的长度。该信息是必须要了解的,因为数据是以单个张量的形式到来的,各序列需要以最长的影评长度为准进行长度补0处理。 我们并不追踪每条影评的序列长度,而是在TensorFlow中动态计算。为了获取每个序列的长度,利用绝对值中的最大值对词向量进行缩减。对于零向量,所得到的 标量为0;而对任意实型词向量,对应的标量为一个大于0的实数。然后利用tf.sign()将这些值离散化为0或1,并将这些结果沿时间步相加,从而得到每个序列的长 度。最终得到的张量的长度与批数据容量相同,且以标量形式包含了每个序列的长度。

来自最后相关活性值的softmax层
对于预测,我们仍像往常一样定义一个RNN。不过,我们希望通过将一个softmax层堆叠到最后一个活性值之上,以实现对RNN的结构扩充。对于RNN,我们使 用params对象中定义的单元类型和单元数量。利用已定义的length属性仅向RNN提供批数据的至多length行。之后,获取每个序列的最后输出活性值,并将其送入一个 softmax层。如果读者一直在跟随本书学习,现在定义softmax层应当是轻而易举的事。
请注意,对于训练批数据中的每个序列,RNN最后的相关输出活性值都有一个不同的索引。这是因为每条影评的长度都不同。我们已经知道了每个序列的长度,那么如何利用它对最后的活性值进行选择?这里的问题在于希望在时间步这个维度上,也就是在批数据形状sequences×time_steps×word_vectors的第2个维度上建 立索引。

截至本书撰写之时,TensorFlow仅支持用tf.gather()沿第1维建立索引。因此,我们将输出活性值的形状sequences×time_steps×word_vectors的前两维扁平化 (flatten),并向其添加序列长度。实际上,我们只需添加length-1,这样便可选择最后的有效时间步。

现在即将能够用TensorFlow进行整个模型的端到端训练,将误差经过softmax层和所使用的RNN时间步反向传播。训练中唯一缺少的是一个代价函数。
梯度裁剪
对于序列分类问题,我们可使用任何于分类有意义的代价函数,因为模型的输出只是一个在可用的所有类别上的概率分布。在本例中,两个类别分别是正面情
绪和负面情绪。我们准备采用上一章介绍的标准交叉熵代价函数。
为将代价函数最小化,可使用配置中定义的优化器。但是,我们准备通过增加梯度裁剪(gradient clipping)对目前所学习到的结果进行改善。RNN训练难度较 大,而且如果不同超参数搭配不当,权值极容易发散。梯度裁剪的主要思想是将梯度值限制在一个合理的范围内。按照这种方式,便可对最大权值的更新进行限 制。


TensorFlow支持利用每个优化器实例提供的compute_gradients()函数进行推演。这样,就可以对梯度进行修改,并通过apply_gradients()函数应用权值的变 化。对于梯度裁剪,如果梯度分量小于-limit,则将它们设置为-limit;若梯度分量大于limit,则将它们设置为limit。唯一需要一点技巧的地方是TensorFlow中的导数可取 为None,表示某个变量与代价函数没有关系。虽然从数学上讲,这些导数应为零向量,但使用None却有利于内部的性能优化。对于那些情形,我们仅将None值传回。
训练模型
下面开始训练上一节中定义的模型。正如之前所说的,我们准备将影评逐个单词地送入循环神经网络,因此每个时间步都是一个由词向量构成的批数据。对上一节中的batched()函数进行改造,使其可查找词向量,并将所有的序列进行长度补齐。

现在就可轻松地开始训练模型了,具体步骤包括:定义超参数、加载数据集和词向量,并将模型运行在经过预处理的训练批数据上。


此时,模型能够成功训练不但取决于网络结构和超参数,而且也取决于词向量的质量。如果没有像上一节所描述的那样训练自己的词向量,可从实现了skip- [1] [2]
gram模型的word2vec项目 加载预训练的词向量,也可从与之非常类似的来自斯坦福NLP研究组的Glove模型 加载词向量。无论选择哪一种模型,都可从网上找 到Python加载器。
这样就拥有了这个模型,那么可以用它做哪些事?在Kaggle这个著名的主办数据科学挑战赛的网站上有一个开放学习竞赛,它采用的是与本节中完全相同的 IMDB影评数据。因此,如果你有兴趣将自己的预测结果与他人的进行比较,可在他们的测试集上运行该模型,并将结果上载至https://www.kaggle.com/c/word2vec-nlp- tutorial。
[1] https://code.google.com/archive/p/word2vec/
[2] http://nlp.stanford.edu/projects/glove/
序列标注
在上一节中,我们使用LSTM网络,并在最后的活性值之上堆叠一个softmax层,构建了一个序列分类模型。在此基础上,现在开始处理一个难度更大的问题
——序列标注(sequence labelling)。该设置问题与序列分类不同,因为它需要对输入序列的每一帧都预测一个类别。 例如,考虑手写文字识别。每个单词都是一个字母序列,我们当然可以单独对每个字母进行分类,但人类的语言具有很强的结构性,这一点是可以善加利的。如果查看一些手写体样本,会发现有些字符是很难单独识别的,如n、m和u。然而,依据其近邻的字母构成的上下文来识别,就会容易许多。在本节中,我 们将通过RNN来利用字母之间的依赖性,并构建一个比较稳健的OCR(Optical Character Recognition,光学字符识别)系统。
OCR数据集
作为一个序列标注问题的例子,我们先了解一下由MIT的口语系统研究组的Rob Kassel收集的,并由斯坦福大学人工智能实验室的Ben Taskar预处理的OCR数 据集。该数据集包含了大量单独的手写字母,每个样本对应一幅16×8像素的二值图像。这些字母被组合为一些序列,且每个序列都对应一个单词。整个数据集共 包含约6800个、长度至多为14的单词。
下面给出三个该OCR数据集中的序列样本。这几个单词分别为cafeteria、puzzlement和unexpected。这些单词的首字母并未包含在数据集中,因为它们都是大写 的。所有序列都被填充为最大长度14。为了简化工作量,该数据集中仅包含小写字母,这正是一些单词中不含首字母的原因。

该数据集可从http://ai.stanford.edu/~btaskar/ocr/ 上获取,它对应于一个用gzip压缩的、内容用Tab分隔的文本文件,该文件可利用Python的csv模块直接读取。该文 件中每行都表示该数据集中一个字母的属性,如ID号、标签、像素值、单词中下一个字母的ID号等。



首先对那些下一个字母的ID值进行排序,以便能够按照正确的顺序读取每个单词中的字母。然后继续收集字母,直到下一个ID对应的字段未被设置为止。出 现这种情况时,我们开始读取一个新的序列。读取完目标字母及其数据像素后,用零图像对序列进行填充,以使其能够纳入两个较大的包含目标字母和所有像素 数据的NumPy数组中。
时间步之间共享的softmax层
现在,数据和目标数组中都包含了序列,每个目标字母对应于一个图像帧。为了每帧数据获取一个预测结果的最简单的方法是对RNN进行扩展,在每个字母 的输出之上添加一个softmax分类器。这非常类似于上一节序列分类问题中所采用的模型,唯一的区别在于分类器是对每帧数据而非整个序列进行评估的。


现在进入预测部分,这是与序列分类模型存在主要差别的地方。要将一个softmax层添加到所有帧上有两种方法:或者为所有帧添加几个不同的分类器,或者 令所有帧共享同一个分类器。由于对第3个字母进行分类并不比对第8个字母分类难度更大,所以采取后一种方式是比较合理的。按照这种方式,分类器权值在训 练中被调整的次数更多,因为需要对单词中的每个字母进行训练。
要在TensorFlow中实现一个共享层,我们需要运用一点小技巧。一个全连接层的权值矩阵的维数始终为batch_sizein_sizeout_size,但现在有两个输入维 batch_size和sequence_steps,我们希望在这两个维度上对权值矩阵进行更新。
要解决这个问题,可以令这一层的输入(本例中文RNN的输出活性值)扁平为形状batch_sizesequence_stepsin_size。按照这种方式,对于权值矩阵而言,它看 起来就像是一个较大的批数据。当然,还必须对结果的形状进行调整,即反扁平化(unflatten)。

相比于序列分类,这里的代价和误差函数的变动都很小,即对序列中的每一帧,如今都有了一个预测-目标对,因此必须在相应的维度上进行平均。然 而,tf.reduce_mean()在这里无法使用,因为它要依据张量的长度(即序列的最大长度)进行归一化,而我们希望按照之前计算的实际序列长度进行归一化。因 此,可手工调用tf.reduce_sum()和一个除法运算来获得正确的均值。

与代价函数类似,我们也必须对误差函数进行调整。现在,tf.argmax()针对的是轴2而非轴1。然后,对各帧进行填充,并依据序列的实际长度计算均值。最后的tf.reduce_mean()对批数据中的所有单词取均值。

TensorFlow的自动导数计算的一大优点是可像对序列分类问题那样对该模型使用相同的优化运算,我们所要做的仅仅是将新的代价函数代入。从现在开始, 我们将对所有的RNN运用梯度裁剪,因为这种措施能够防止训练发散,同时不会产生任何负面影响。

训练模型
现在可将到目前为止介绍的所有部分整合到一起,开始训练模型。通过上一节的学习,相信读者对导入和配置参数已经非常熟悉。我们利用get_dataset()下 载手写体图像并进行预处理,这也正是将小写字母编码为独热编码向量的地方。经过编码之后,随机打乱数据的顺序,以便在划分训练集和测试集时得到一个无偏的结果。



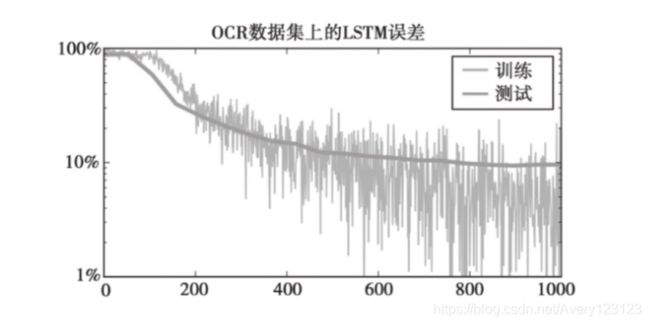
当用1000个单词训练之后,我们的模型在测试集上的错误率已降至约9%。
这个结果不算太差,但仍有提升的空间。 我们目前使用的模型与用于序列分类的模型非常相似。笔者是有意而为之的,目的是帮助读者了解为将已有模型用于解决新问题,应做何种修改。在另一个问题上的有效解决方案对于一个新问题也极有可能比预想的要有效。然而,我们完全可以做得更好!下一节将尝试利用一种更高级的循环神经网络架构改进现有结果。
双向RNN
如何对用RNN加softmax架构在OCR数据集上得到的结果进行改进?不妨重新审视一下使用RNN的动机。我们为OCR数据集选择这一架构的原因在于单词中的相邻字母之间存在依赖关系(或互信息)。RNN会将关于在同一单词之前全部输入的信息保存到隐含活性值中。
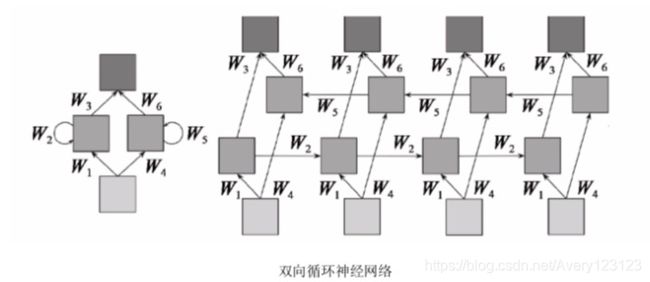
如果能够想到这一点,就会意识到在模型中循环连接对于前几个字母的分类是没有太大帮助的,因为网络尚无大量输入以从中推断出额外的信息。在序列分类任务中,这并不是一个问题,因为网络在决策之前能够看到所有的帧。在序列标注任务中,可利用双向RNN(bidirectional RNN)克服RNN的这个缺陷,这项技 术在若干分类任务中都保持着最高的水平。
双向RNN的思想非常简单。它共有两个RNN观测输入序列,一个按照通常的顺序从左端读取单词,而另一个按照相反的顺序从右端读取单词。这样,在每个 时间步,就可得到两个输出活性值。在将它们送入共享的softmax层之前,可将两者拼接在一起。利用这种架构,分类器便可从每个字母获取完整的单词信息。
那么如何用TensorFlow实现双向RNN?实际上TensorFlow中已有了一个实现版本——tf.model.rnn.bidirectional_rnn。但是,我们希望学习如何自行构建复杂模型, 因此下面来实现这种模型。笔者将引导你完成各个步骤。首先,将预测属性划分到两个函数中,以便眼下只关注较少的内容。

上面的_shared_softmax()函数的实现比较容易:在之前的预测属性中,我们已经有了相关代码。区别在于现在是从传入该函数的张量data推断输入尺寸。依 照这种方式,可在必要时复用其他架构的函数,然后可以利用相同的扁平化技巧在所有的时间步中共享同一个softmax层。

下面进入真正有趣的环节——实现双向RNN。如你所见,我们利用rnn.dynamic_rnn创建了两个RNN。前向网络对我们而言非常熟悉,但后向网络是全新的。
我们并不将数据送入后向RNN,而是首先将序列反转。这样做要比实现一个新的用于反向传递的RNN运算更加容易。TensorFlow提供了tf.reverse_sequence() 函数,它可帮助我们完成对所使用的帧数据中至多sequence_lengths帧的反转操作。请注意,在本书撰写之时,该函数要求sequence_lengths参数为int64类型的张量。

这里也使用了scope参数,为什么需要它?第3章曾解释过,数据流图中的节点是拥有名称的。scope是rnn_dynamic_cell所使用的变量scope的名称,其默认值为 RNN。现在由于我们有两个参数不同的RNN,所以它们需要有不同的域。
将反转的序列送入后向RNN后,我们再次将网络的输出反转,以与前向输出对齐。然后沿着RNN的神经元输出的维度将这两个张量拼接在一起,并将其返 回。例如,当批数据尺寸为50,每个RNN有300个隐藏单元,所有单词至多包含14个字母时,所得到张量的形状为50×14×600。非常酷,这样我们就亲手构建了自己的第一个由多个RNN组成的架构!下面来检查利用上一节的训练代码能够使这个模型达到何种性能。通过比较两个预测 误差图,可以看出,双向模型具有更优的性能。在接收1000个单词之后,它在测试集上对字母的识别错误率已经低至4%。
在未来的版本中,极有可能也支持该参数为int32类型 ,且只需传入self.length即可

总结一下,在本节中,我们学习了如何利用RNN完成序列标注任务,并了解了该任务与序列分类任务的差异,即我们希望得到一个能够接收RNN的输出并为 所有时间步所共享的分类器。
通过增加第二个从后向前访问序列的RNN,并将每个时间步的输出进行整合,模型的性能能够得到显著提升,这是因为在对每个字母进行分类时,整个序列 的信息都是可用的。
在下一节中,我们将介绍如何用非监督的方式训练RNN模型,以实现语言的学习。
预测编码
我们已经学习了如何利用RNN对影评中的情绪进行分类,以及如何识别手写单词。这些应用都是有监督的,即需要一个带标注信息的数据集。另外一种有趣的
学习设置是预测编码(predictive coding),目的是通过向RNN输入大量序列,训练它预测序列的下一帧的能力。
以文本为例,预测一个句子中下一个单词的似然被称为语言建模(language modelling)。为什么预测句子中的下一个单词是有用的?有一类应用被称为识别语 言。例如,假设希望构建一个手写文字识别器,目标是将手写文字图像转换为键入的文字。虽然可以尝试从输入图像恢复所有的单词,但如果能够预知下一个单词 的概率分布,无疑能够缩小候选单词的考虑范围。基本上,这便是盲目的形状识别与阅读的区别。
除了提升模型对涉及自然语言的任务的处理性能,为了生成文本,也可以依据网络所认为的下一个单词的分布进行抽样。训练结束后,可将一个种子单词
(seed word)送入RNN,然后观察它所预测的下一个单词。之后,将最可能的单词送回RNN作为接下来的输入,以观察它认为接下来应是什么。重复这个步骤,便 可生成与训练数据看上去非常类似的新内容。
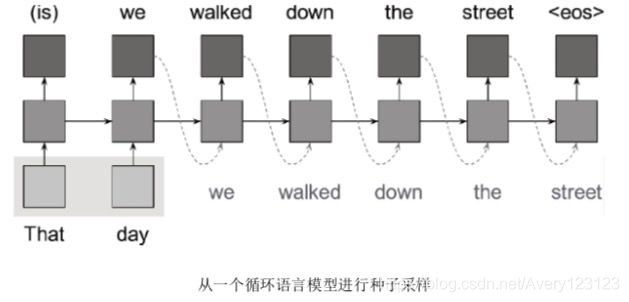
下面利用RNN构建一个预测编码语言模型。我们用稍多于26个独热编码字符表示字母、一些标点符号和空格,而不将词向量作为输入。
字符级语言建模
下面利用RNN构建一个预测编码语言模型。我们用稍多于26个独热编码字符表示字母、一些标点符号和空格,而不将词向量作为输入。
对于单词级的语言建模和字符级的语言建模,哪个方法更优尚不清楚。字符级的建模方法之美在于网络不仅能学会如何构词,还可以学会如何拼写。此外,采
用这种方法时,与尺寸为300的词向量或独热编码的单词相比,网络的输入维数更低。此外,还有一个好处,即不必再去考虑那些未知的单词,因为它们是由网络 已知的字母构成的。从理论上讲,这甚至允许网络发明一些新的单词。
Andrew Karpathy在2015年将RNN应用于字符级语言建模,并自动生成了一些令人惊叹的莎士比亚剧本、Linux内核和驱动代码以及包括正确的标记语法的维基百 科文章。这个项目的源码可从Github获取https://github.com/karpathy/char-rnn。 下面从机器学习文献的摘要上训练一个类似的模型,看看能否生成一些多少有一定合理 性的新摘要。
ArXiv摘要API
ArXiv.org是一个托管了来自计算机科学、数学、物理学和生物学等领域的许多研究论文的在线库。如果一直在追踪机器学习相关研究,可能对该网站早有耳 闻。幸运的是,这个平台提供了一个基于Web的可用于检索文献的API。下面来编写一个依据给定搜索查询,从ArXiv获取摘要的类。

在构造方法中,首先检查是否有之前的摘要转储文件可用。如果有,则直接使用,而无需再次调用ArXiv API。你可以想象更为复杂的检查已有文件与新类别、 新关键词是否匹配的逻辑,但就目前而言,执行新的查询时,将旧的转储文件删除或转移已经足够用了。如果没有转储文件可用,则调用_fetch_all()方法,并将 它所生成的行写入磁盘。

由于所感兴趣的是机器学习论文,所以只在Machine Learning、Neural and Evolutionary Computing和Optimization and Control三个类别内进行搜索。我们进一步限制只 返回那些元数据中包含单词neural、network或deep的结果,这样可以获取到约7MB的文本,这样的数据量对于训练一个简单的RNN语言模型已经足够大了。尽管使 用更多的数据通常会得到更好的结果,但我们并不希望在看到结果之前用数小时等待训练结束。你尽可以使用更多的搜索查询,并用更多的数据来训练模型。
_fetch_all()方法基本上完成的是分页功能。每次查询时,这个API仅返回一定数量的摘要,我们可指定一个偏移量,用于获取比如第2页、第3页的结果。可以 看到,我们能为下一个函数_fetch_page()传入一个指定了页面尺寸的参数。理论上,可以将页面尺寸设为一个很大的数,并尝试一次性得到全部结果。然而,实 际上这种做法会严重影响查询的效率。页面的获取容错性更强,而且更重要的是,不会为ArXiv API增加过大的负载。

这里完成了实际的抓取,结果为XML格式,利用流行而强大的BeautifulSoup库来提取摘要。如果尚未安装该库,可通过执行命令sudo-H pip3 install beautifulsoup4来 安装它。BeautifulSoup会为我们解析XML结果,这样便可遍历那些感兴趣的标签。首先查看对应于文章的标签,并从其内部读取包含摘要文本的标 签。

数据预处理


预测编码模型
现在已介绍了整个流程:定义了任务,编写了一个解析器用于获取数据集,下面利用TensorFlow实现神经网络模型。由于对于预测编码而言,需要尝试预测输
入序列中的下一个字符,所以模型只有一个输入,即构造方法的sequence参数。
此外,构造方法接收一个参数对象,用于修改重要的选项,并使实验可复现。第3个参数initial=None是循环连接层的初始内部活性值。虽然希望TensorFlow将隐 状态初始化为零张量,但今后在需要从所学习到的语言模型进行采样时定义它会更加方便。



在上面的示例代码中,可以看到我们的模型所要实现的大致功能。如果初看上去觉得难以理解,请不必担心,与上一章模型相比,我们只是希望更多地突出这
个模型的某些价值。
从数据处理开始。前面提到过,这个模型只接收一个序列块作为输入。首先,我们利用它构造输入数据和目标序列,这是引入时域差的地方,因为在时间步t, 模型应有st作为输入,st+1作为输出。获取数据或目标的一种简便方法是对所提供的序列进行切片处理,并将第一帧或最后一帧分别切除。
切片运算是通过tf.slice()实现的,该函数的参数包括要切片的序列、一个包含各维起始索引的元组以及一个包含各维大小的元组。sizes-1意味着保持那个维度上从起始索引到终止索引的所有元素不变。由于希望对帧数据进行切片,所以只需关心第2维。

我们还为目标序列定义了两个前面已经讨论过的属性:mask是一个尺寸为batch_size×max_length的张量,其分量非0即1,具体取哪个值取决于相关帧是否被使 用。为得到每个序列的长度,属性length沿时间轴对mask求和。
请注意,mask和length属性对于数据序列也是合法的,因为从概念上讲,它们与目标序列的长度相同。然而,我们并不在数据序列上计算这两个属性,因为它仍 然包含着并不需要的最后一帧,而对它是没有下一个字母可预测的。将数据张量的最后一帧切除,但除了主要包含填充的帧外,它并不包含大多数序列实际上的最 后一帧。这也正是下面用mask对代价函数进行掩膜处理的原因。
下面定义由一个循环神经网络和一个共享的softmax层构成的实际网络,具体方法与上一节序列标注任务中使用的结构类似。这里不再展示用于共享的softmax层 的代码(可从上一节找到相关代码)。

上述神经网络代码中新增的部分是我们希望同时获得的预测和最后的循环活性值。在此之前,仅返回预测值,但最后的活性值可使我们更有效地生成一些序
列。由于仅希望为循环神经网络构建一次数据流图,因此有一个属性forward用于返回由那两个张量构成的元组,而prediction和state的目的仅仅是便于外部访问。
模型的下一部分是代价函数和评价函数。在每个时间步,模型都会从词汇表中预测下一个字母。这是一个分类问题,我们相应地采用交叉熵代价函数,也可以很容易地计算字符预测错误率。
logprob属性是新增的,它刻画了模型在对数空间为正确的下一个字母所分配的概率。基本上,可以认为这是变换到对数空间并取均值后的负交叉熵。将结果变 换回线性空间,便会得到所谓的混淆度(perplexity),这是一种用于评价语言模型性能的常见度量。

对于完美的模型而言,混淆度为1,而始终对每个类别都输出相同概率的模型的混淆度为n。只要模型为下一个字母分配一个零概率,混淆度甚至会变为无穷 大。为防止这种极端情况出现,可将预测概率箝位在一个很小的正数和1之间。

上述三个属性都会在所有序列的各帧上取平均。对于固定长度序列,结果将为一个tf.reduce_mean(),但在处理变长序列时,必须格外小心。首先,通过与掩 膜相乘,屏蔽掉填充的帧。然后,沿着帧尺寸进行聚合。由于上述这三个函数都与目标值做了乘法,每帧只有一个元素集,我们利用tf.reduce_sum()函数将各帧聚 合为一个标量。
接下来,希望利用序列的实际长度对每个序列中的各帧取平均。为了避免在空序列时除数为0,我们使用每个序列长度的最大值和1。最后,利用 tf.reduce_mean()对批数据中的样本取平均。
下面直接开始训练模型。请注意,我们并未定义optimize运算,它始终与之前本章在序列分类或序列标签任务中所使用的运算一致。
训练模型
在对语言模型采样之前,必须将已经构建好的模块进行整合,包括数据集、预处理步骤和网络模型。下面编写一个对这些步骤进行整合的类,将新引入的混淆
度度量打印出来,并周期性地将训练进展保存下来。这个检查点不但对于以后继续训练非常有用,而且还便于加载模型以用于采样(稍后将进行)。





构造方法、call()、_optimization()和_evaluation()都比较容易理解。我们加载数据集,为数据流图定义输入,在经过预处理的数据集上训练模型,并 追踪对数几率,在相邻两次训练epoch之间的评价时间上使用它们计算并打印混淆度。
在_init_or_load_session()中,引入了一个tf.train.Saver(),用于将数据流图中所有tf.Variable()的当前值保存到检查点文件中。实际的点检查(checkpointing) 是在_evalution()内完成的,在这里我们创建这个类并寻找已有的检查点文件以便加载。tf.train.get_checkpoint_state()会从检查点文件所在目录中查找TensorFlow的 元数据文件。在本书撰写之时,它只包含最新生成的检查点文件。
检查点文件是通过一个可指定的数字(在本例中为epoch数)预先准备。在加载检查点文件时,利用Python的正则表达式包re提取epoch数。点检查的逻辑实现 后,便可开始训练。下面是具体的配置:

为了运行这段代码,可调用Training(get_params())()。在笔者的笔记本电脑上,完成20个epoch需要大约1小时的时间。在训练过程中,模型一共看到了20 epochs200 batches100 examples*50 characters=20M个字母。

从上图可以看出,模型在混淆度约为1.5/字母时收敛,这意味着利用这个模型时,每个字母只需1.5位,从而可实现文本的压缩。 如果使用单词级的语言模型,则需要依据单词数而非字符数取平均。作为一种粗略的估计,可以将它乘以每个单词中的平均字符数。
生成相似序列
完成上述所有工作后,便可利用训练好的模型生成新的序列。我们将编写一个功能与Training类相似的较小的类,实现从磁盘加载最新的模型检查点,并定义一
些占位符,以将数据输入数据流图。当然,这次并不训练模型,只是用它生成新数据。

在构造方法中,我们创建了一个预处理类的实例,后面利用它将当前生成的序列转化为一个NumPy向量,以输入数据流图。这时的占位符sequence对每批数据 只预留了一个序列的空间,因为不希望每次生成多个序列。
这里序列的长度被设为2,下面做一解释。前面介绍过,我们的模型将除最后的字符外的所有字符作为输入,而将除首字符外的所有字符作为目标。我们将当 前文本最后的字符和作为序列的任意第二个字符输入到模型中,网络将为第一个字符预测一个结果,将第二个字符用作目标值,但由于并不是训练模型,因此它将 被忽略。
你可能会对只将当前文本最后的字符传入网络感到疑惑。这里采用的技巧是准备获取循环神经网络最后的活性值,并用它对网络下一次运行时的状态进行初始
化。为此,需要利用模型的初始状态参数。对于使用过的GRUCell,该状态是一个尺寸为rnn_layers*rnn_units的向量。

call()函数定义了用于采样文本序列的逻辑。我们从一个采样种子开始,每次预测一个字符,并总是将当前文本送入网络。使用相同的预处理类将当前文 本转换为填充后的NumPy块,然后将它们送入网络。由于在批数据中只有一个序列和一个输出帧,因此只关心索引[0,0]处的预测结果。之后,利用后面将要介绍 的_sample()函数对softmax输出进行采样。
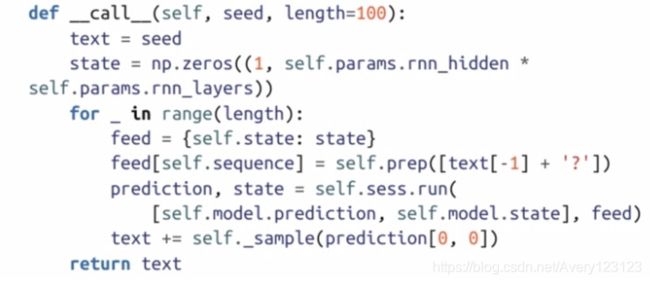
那么如何对网络输出进行采样?前文曾提到过,可选取序列最优的预测,并将其作为下一帧传入网络来生成序列。实际上,并非只选择最可能的下一帧,而是
也从RNN输出的概率分布中随机抽样。按照这种方式,那些具有高输出概率的单词更可能被选中,但输出概率低的单词也是有可能被选中的。这样就可得到更多动 态生成的序列。否则,可能是一次又一次地生成相同的平均句子。
要手工控制这个生成过程的有效性有一种简单的机制。例如,如果总是随机选择下一个单词(并将网络输出完全忽略),将得到非常新且独一无二的句子,但
它们可能会没有任何意义。如果总是选择将网络最可能的输出作为下一个单词,则将得到大量虽常见但无意义的单词,如the、a等。
对这种行为进行控制的方式是引入一个温度参数T。利用该参数使softmax层的输出分布预测更相似或更为不同。这样会分别导致生成更有趣但有随机性的序
列,以及更多合理但乏味的序列。其工作方式是在线性空间对输出进行缩放,然后将它们变换至指数空间并再次归一化:

由于网络已经输出了一个softmax分布,则可通过运用自然对数将其撤销。我们不必将归一化操作撤销,因为会再次将结果归一化。之后,将每个值除以所选择 的温度值,并重新应用softmax函数。

下面通过调用Sampling(get_params())(‘We’,500))运行上述代码,使网络生成一段新的摘要。虽然你一定能够看出这段文字绝非出自人手,但网络从样 本中学习到的结果还是让人感到吃惊。

我们并未告知RNN什么是空间,但它却捕捉到了数据内部的统计依赖性,在所生成的文本中相应地放置了空格。即使在一些网络自己生成的并不存在的单词之 间,空格的安排看上去也非常合理。此外,那些单词中的元音和辅音的搭配都很合理,这是从样例文本中学习到的另一种抽象特征。