【深度学习】【MobileNet】Mobile神经网络结构简介及基于TensorFlow2.x的结构实现
MobileNet
- 为什么写这篇文章
- 引言
- 深度可分离卷积
- Mobile神经网络结构
- 将Mobile神经网络轻量化
- 参考文献
- 未完待续
为什么写这篇文章
最近在研究 U N e t UNet UNet在语义分割中的应用,该 U N e t UNet UNet的编码部分是基于 M o b i l e N e t MobileNet MobileNet实现的,因而打算通过本文进行总结式学习。文章参考了 M o b i l e N e t MobileNet MobileNet的原论文以及各种通过其他途径获得的文献,均会在文末给出出处。本文算是个人的理解与这些文献的融合阐述,在此感谢这些文献的作者让我得到了提升。
引言
目前的研究总结来看分为两个方向:一是对训练好的复杂模型进行压缩得到小模型;二是直接设计小模型并进行训练。不管如何,其目标在保持模型性能(accuracy)的前提下降低模型大小(parameters size),同时提升模型速度(speed, low latency)。
MobileNet属于后者,其是Google提出的一种小巧而高效的CNN模型,其在accuracy和latency之间做了折中。
深度可分离卷积
MobileNet的基本单元是深度可分离卷积(depthwise separable convolution),这种结构之前已经被使用在Inception模型中。深度可分离卷积是一种可分解卷积操作(factorized convolutions),其可以分解为两个更小的操作:depthwise convolution和pointwise convolution。
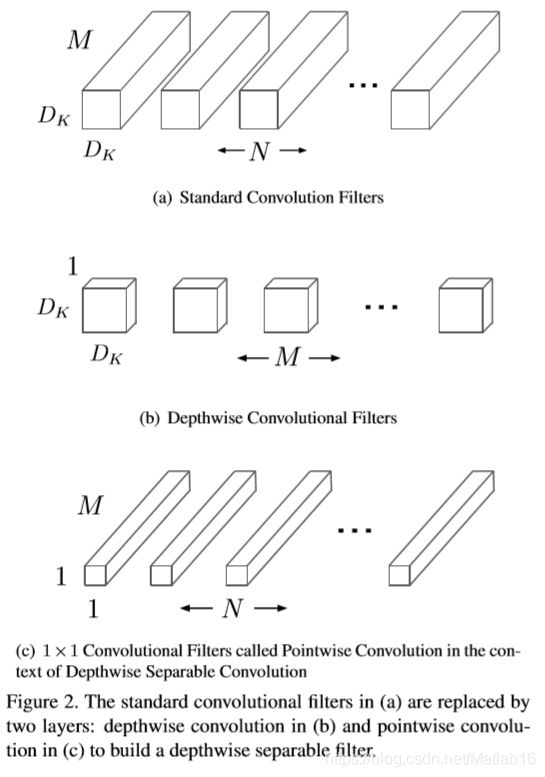
Depthwise convolution和标准卷积不同,对于标准卷积其卷积核是用在所有的输入通道上(input channels),而depthwise convolution针对每个输入通道采用不同的卷积核,就是说一个卷积核对应一个输入通道。所以说depthwise convolution的depth便是指输入通道的深度,它是基于这一深度的级别。而pointwise convolution则只是普通的卷积,只不过它采用1x1的卷积核。原论文MobileNets: Efficient Convolutional Neural Networks for Mobile Vision Applications的Figure 2中清晰地展示了这两种操作。这里再附上更直观的阐述:
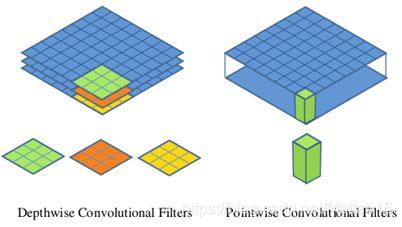
对于深度可分离卷积,其首先是采用depthwise convolution对不同输入通道分别进行卷积,然后采用pointwise convolution将上面的输出再进行结合,这种分步操作的整体效果和一个标准卷积相差不大,但会大大减少计算量和模型参数量。
关于深度可分离卷积在计算量上与标准卷积的差别,原论文给出了详细的论述。这里只做简单分析。假定输入特征图大小是 D F × D F × M D_F×D_F×M DF×DF×M ,而输出特征图大小是 D F × D F × N D_F×D_F×N DF×DF×N ,其中 D F D_F DF是特征图的宽和高(这里假定两者是相同的),而 M M M指的是通道数或者叫深度(channels or depth)(这里也假定输入与输出特征图(宽和高)是一致的)。采用的卷积核大小尽管是特例,但是不影响下面分析的一般性。对于标准的卷积 D K × D K D_K×D_K DK×DK,其计算量将是:
D K × D K × M × N × D F × D F D_K×D_K×M×N×D_F×D_F DK×DK×M×N×DF×DF
而对于depthwise convolution其计算量为 D K × D K × M × D F × D F D_K×D_K×M×D_F×D_F DK×DK×M×DF×DF ,pointwise convolution计算量是: M × N × D F × D F M×N×D_F×D_F M×N×DF×DF,所以深度可分离卷积总计算量是:
D K × D K × M × D F × D F + M × N × D F × D F D_K×D_K×M×D_F×D_F+M×N×D_F×D_F DK×DK×M×DF×DF+M×N×DF×DF
将二者进行比值运算可以得到:
D K × D K × M × D F × D F + M × N × D F × D F D K × D K × M × N × D F × D F = 1 N + 1 D K 2 \frac{D_K×D_K×M×D_F×D_F+M×N×D_F×D_F}{D_K×D_K×M×N×D_F×D_F}=\frac{1}{N}+\frac{1}{D_K^2} DK×DK×M×N×DF×DFDK×DK×M×DF×DF+M×N×DF×DF=N1+DK21
可见,相比于标准卷积,深度可分离卷积可使模型参数量下降许多。
Mobile神经网络结构
“
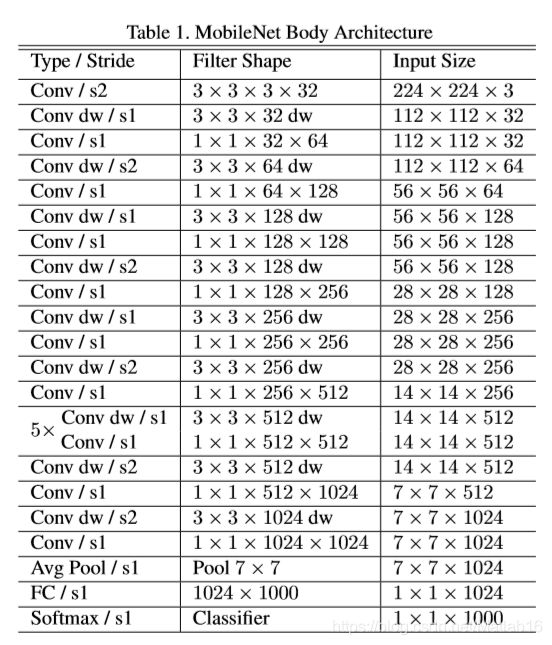
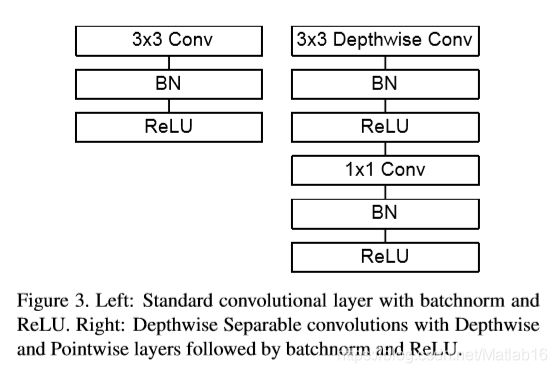
The MobileNet structure is built on depthwise separable convolutions as mentioned in the previous section except for the first layer which is a full convolution. By defining the network in such simple terms we are able to easily explore network topologies to find a good network. The MobileNet architecture is defined in Table 1. All layers are followed by a batchnorm[13] and ReLU nonlinearity with the exception of the final fully connected layer which has no nonlinearity and feeds into a softmax layer for classification. Figure 3 contrasts a layer with regular convolutions, batchnorm and ReLU nonlinearity to the factorized layer with depthwise convolution, 1×1 pointwise convolution as well as batchnorm and ReLU after each convolutional layer. Down sampling is handled with strided convolution in the depthwise convolutions as well as in the first layer. A final average pooling reduces the spatial resolution to 1 before the fully connected layer. Counting depthwise and pointwise convolutions as separate layers, MobileNet has 28 layers.
MobileNet的网络结构建立在上一节提到的深度可分离卷积之上,但网络在第一层是全卷积层。基于这种简单的规则对网络进行定义,我们可以轻松地对网络拓扑结构进行探索,找到一个性能优良的网络。MobileNet架构可参见 Table 1。最后一层全连接网络没有非线性激活函数,并且该网络层的输入将馈入softmax函数进行分类,除此之外,对于每一层网络,其后都伴有一个BatchNormalization和ReLU激活函数。Figure 3将基于标准卷积、BatchNormalization和ReLU激活函数的网络层结构 与 基于每个卷积层之后都具有depthwise卷积、1×1pointwise卷积以及BatchNormalization和ReLU激活函数的因子分解网络层结构进行了对比。下采样在depthwise卷积和第一层网络层中均使用带步长的卷积处理方式。在全连接层前,最后一层平均池化层将空间分辨率降低到1。如果将depthwise卷积和pointwise卷积计算视为单独的层,那么MobileNet的网络结构中含有28层。
”
“
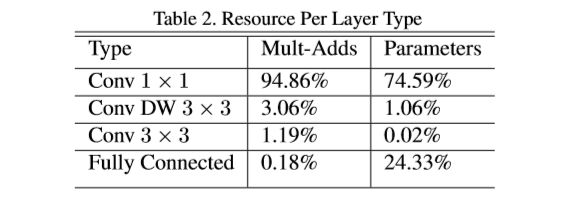
It is not enough to simply define networks in terms of a small number of Mult-Adds. It‘s also important to make sure these operations can be efficiently implementable. For instance unstructured sparse matrix operations are not typically faster than dense matrix operations until a very high level of sparsity. Our model structure puts nearly all of the computation into dense 1×1 convolutions. This can be implemented with highly optimized general matrix multiply (GEMM) functions. Often convolutions are implemented by a GEMM but require an initial reordering in memory called im2col in order to map it to a GEMM. For instance, this approach is used in the popular Caffe package [15]. 1×1 convolutions do not require this reordering in memory and can be implemented directly with GEMM which is one of the most optimized numerical linear algebra algorithms. MobileNet spends 95% of it’s computation time in 1 × 1 convolutions which also has 75% of the parameters as can be seen in Table 2. Nearly all of the additional parameters are in the fully connected layer.
简单用轻量的Mult-Adds来定义网络是不够的。同样重要的是,要确保这些操作能够有效地实施。例如,非结构化稀疏矩阵的运算通常不会比稠密矩阵的运算快,除非稀疏度非常高。我们的模型结构将几乎所有的计算都投入了稠密的1×1卷积中。这可以通过高度优化的广义矩阵乘法(GEMM)函数来实现。卷积通常由GEMM实现,但需要在内存中进行一个名为im2col的初始化重排序,以便将其映射到GEMM。举例来讲,这种方法在当下流行的Caffe库中便有使用[15]。1×1卷积并不需要在内存中重排序就可以直接用GEMM算法实现,而GEMM算法也是数值线性代数中最优化的算法之一。MobileNet将95%的计算时间花在1×1卷积上,其中便囊括了整个网络75%的参数,如Table 2中所示。几乎所有额外的参数都在全连接层中。
”
“
MobileNet models were trained in TensorFlow [1] using RMSprop[33] with a synchronous gradient descent similar to Inception V3 [31]. However, contrary to training large models we use less regularization and data augmentation techniques because small models have less trouble with overfitting. When training MobileNets we do not use side heads or label smoothing and additionally reduce the amount image of distortions by limiting the size of small crops that are used in large Inception training [31]. Additionally, we found that it was important to put very little or no weight decay (L2 regularization) on the depthwise filters since their are so few parameters in them. For the ImageNet benchmarks in the next section all models were trained with same training parameters regardless of the size of the model.
MobileNet模型在TensorFlow[1]中使用基于同步梯度下降的RMSprop[33]进行训练,这与Inception V3[31]相类似。然而,与训练大规模模型相反,我们使用较少的正则化和数据增强技术,因为轻量级模型并不容易产生过拟合。在训练MobileNets时,我们并不使用side head或label smoothing,我们通过限制大规模模型在训练初始阶段中使用的小批量的大小来减少图像失真的数量[31]。此外,我们发现在depthwise滤波器上设置极其小的权重或不设置权重衰减(L2正则化),对于模型训练是很重要的,因为它们的参数非常少。对于下一节中的ImageNet基准测试,将抛开模型规模这一因素,而对所有模型都使用相同的训练参数进行训练。
”
————MobileNets: Efficient Convolutional Neural Networks for Mobile Vision Applications
将Mobile神经网络轻量化
尽管基本的MobileNet的模型规模已经较小,但在某些应用领域中可能会需要规模更小的模型。这就需要在对网络进一步轻量化。为此,将引入参数 α \alpha α,称它为宽度乘子(width multiplier),并且其取值范围为 ( 0 , 1 ] (0,1] (0,1]。宽度乘子的作用是对网络的每一层均匀地进行轻量化。假设当前给定一神经网络层,设其原本图像的输入通道数为 M M M,那么在宽度乘子的作用下,经过轻量化后的图像输入通道数将变为 α M \alpha M αM。与此同理,原本图像的输出通道数为 N N N,最终变为 α N \alpha N αN。据此,带宽度乘子的深度可分离卷积的计算量就变为
D K × D K × α M × D F × D F + α M × α N × D F × D F D_K×D_K×\alpha M×D_F×D_F+\alpha M×\alpha N×D_F×D_F DK×DK×αM×DF×DF+αM×αN×DF×DF
通常情况下,宽度乘子常取 0.25 , 0.5 , 0.75 , 1 0.25,0.5,0.75,1 0.25,0.5,0.75,1。当宽度乘子取 1 1 1时实际上就是最普通的MobileNet。需要注意的是,当将宽度乘子用于减小模型规模时,被宽度乘子重新定义的网络需要重新从头开始训练。
除了宽度乘子,原论文中还引入了第二个超参数来减少神经网络的计算量—— ρ \rho ρ,也叫分辨率乘子(resolution multiplier),其范围也是 ( 0 , 1 ] (0,1] (0,1]。之前的宽度乘子(要注意虽然叫“宽度”乘子,但它实际上并不作用于图像或者叫特征图的宽度)是作用于图像通道数,而分辨率乘子是作用于特征图的大小( D F D_F DF)。对于 ρ \rho ρ的设置,通常并不像宽度乘子那样显示地设为某一具体常数,而是隐式地将所设置的 ρ \rho ρ满足 ρ D F \rho D_F ρDF等于 224 , 128 , 192 , 160 224,128,192,160 224,128,192,160等一些常见的特征图大小。
经过两种超参数的作用,最终,轻量化的深度可分离卷积的计算量就为:
D K × D K × α M × ρ D F × ρ D F + α M × α N × ρ D F × ρ D F D_K×D_K×\alpha M×\rho D_F×\rho D_F+\alpha M×\alpha N×\rho D_F×\rho D_F DK×DK×αM×ρDF×ρDF+αM×αN×ρDF×ρDF
对以上所描述的轻量化技巧,其在实验中的轻量化效果可参看Table 3。

参考文献
[1] CNN模型之MobileNet
[2] MobileNets: Efficient Convolutional Neural Networks for Mobile Vision Applications