《神经网络与深度学习》-深度生成模型
深度生成模型
-
- 1. 概率生成模型
-
- 1.1 密度估计
- 1.2 生成样本
- 1.3 应用于监督学习
- 2. 变分自编码器
-
- 2.1 含隐变量的生成模型
- 2.2 推断网络
-
- 2.2.1 推断网络的目标
- 2.3 生成网络
-
- 2.3.1 生成网络的目标
- 2.4 模型汇总
- 2.5 再参数化
- 2.6 训练
- 3. 生成对抗网络
-
- 3.1 显式密度模型和隐式密度模型
- 3.2 网络分解
-
- 3.2.1 判别网络
- 3.2.2 生成网络
- 3.3 训练
- 3.4 一个生成对抗网络的具体实现:DCGAN
- 3.5 模型分析
-
- 3.5.1 训练稳定性
- 3.5.2 模型坍塌
- 3.6 改进模型
-
- 3.6.1 W-GAN
概率生成模型(Probabilistic Generative Model)简称 生成模型,指一系列用于 随机生成可观测数据的模型。假设在连续或离散的高维空间 X X X中,存在一个随机向量 X X X 服从一个未知的数据分布 p r ( x ) , x ∈ X p_r(\pmb{x}),x \in X pr(xxx),x∈X。生成模型根据一些可观测的样本 x ( 1 ) , ⋯ , x ( N ) \pmb{x}^{(1)},\cdots,\pmb{x}^{(N)} xxx(1),⋯,xxx(N)来学习一个参数化模型 p θ ( x ) p_{\theta}(\pmb{x}) pθ(xxx)来近似未知分布 p r ( x ) p_{r}(\pmb{x}) pr(xxx),并且可以用这个模型生成一些样本,使得生成样本和真实样本尽可能地相似。生成模型包括两基本功能: 概率密度估计和 生成样本(即 采样)。下图以手写数字图像为例,给出生成模型的两功能:左图表示手写数字图像的真实分布 p r ( x ) p_{r}(\pmb{x}) pr(xxx)以及从中采样的真实样本,右图表示估计出了分布 p θ ( x ) p_{\theta}(\pmb{x}) pθ(xxx)以及从中采样的生成样本。

生成模型可用来建模不同的数据:如图像、文本、声音。但对于高维空间中的复杂分布,密度估计和生成样本都不容易实现:一是高维随机向量难以建模,需通过一些条件独立性来简化模型,而是给定一个已建模的复杂分布,也缺乏有效的采样方法。
深度生成模型是利用深度神经网络可以近似任意函数的能力,来建模一个复杂分布 p r ( x ) p_{r}(\pmb{x}) pr(xxx),或直接生成符合分布 p r ( x ) p_{r}(\pmb{x}) pr(xxx)的样本。
本节先介绍概率生成模型的基本概念,然后介绍两种深度生成模型:变分自编码器和生成对抗网络
1. 概率生成模型
生成模型有两个基本功能:密度估计和生成样本
1.1 密度估计
给定一组数据 D = { x ( n ) } n = 1 N D=\{\pmb{x}^{(n)}\}_{n=1}^{N} D={ xxx(n)}n=1N,假设它们都是独立地从相同的概率密度函数为 p r ( x ) p_{r}(\pmb{x}) pr(xxx)的未知分布中产生,密度估计(Density Estimation)是根据数据集D来估计其概率密度函数 p θ ( x ) p_{\theta}(\pmb{x}) pθ(xxx)
密度估计是一类无监督学习问题,如在手写体数字图像识别中的密度估计问题中,将图像表示为一个随机向量 X \pmb{X} XXX,每一维都表示一个像素值,假设手写体数字图像都服从一个未知的分布 p θ ( x ) p_{\theta}(\pmb{x}) pθ(xxx),希望通过一些观测样本来估计其分布。
但手写体数字图像中不同像素之间存在复杂的依赖关系(比如相邻像素的颜色一般是相似的),很难用一个明确的图模型来描述依赖关系,所以直接建模 p θ ( x ) p_{\theta}(\pmb{x}) pθ(xxx)比较困难。
故,通过引入隐变量 z \pmb{z} zzz来简化模型,这样概率密度估计问题转化为估计变量 ( x , z ) (\pmb{x},\pmb{z}) (xxx,zzz)的两个局部条件概率 p θ ( z ) p_{\theta}(\pmb{z}) pθ(zzz)和 p θ ( x ∣ z ) p_{\theta}(\pmb{x}|\pmb{z}) pθ(xxx∣zzz).一般为了简化模型,假设隐变量 z \pmb{z} zzz的先验分布为标准高斯分布 N ( 0 , I ) N(0,\pmb{I}) N(0,III)。隐变量 z \pmb{z} zzz的每一维之间都是独立的,在这个假设下,先验分布 z ; θ \pmb{z;\theta} z;θz;θz;θ中没有参数,因此,密度估计的重点是估计条件分布 p ( x ∣ z ; θ ) p(\pmb{x}|\pmb{z};\theta) p(xxx∣zzz;θ).
如果要建模含隐变量的分布,需利用EM算法来进行密度估计,在EM算法中,需要估计条件分布 p ( x ∣ z ; θ ) p(\pmb{x}|\pmb{z};\theta) p(xxx∣zzz;θ)以及近似后验分布 p ( z ∣ x ; θ ) p(\pmb{z}|\pmb{x};\theta) p(zzz∣xxx;θ).当这两个分布比较复杂时,可以用神经网络来进行建模,这就是变分自编码器的思想。
1.2 生成样本
生成样本就是给定一个概率密度函数为 p θ ( x ) p_{\theta}(\pmb{x}) pθ(xxx)的分布,生成一些服从这个分布的样本,也称为“采样”。
对于上图中的图模型,在得到两个变量的局部条件概率 p θ ( z ) p_{\theta}(\pmb{z}) pθ(zzz)和 p θ ( x ∣ z ) p_{\theta}(\pmb{x}|\pmb{z}) pθ(xxx∣zzz)之后,我们就可以生成数据 x \pmb{x} xxx,具体过程可以分为两步进行:
- 根据隐变量的先验分布 p θ ( z ) p_{\theta}(\pmb{z}) pθ(zzz)进行采样,得到样本 z \pmb{z} zzz
- 根据条件分布 p θ ( x ∣ z ) p_{\theta}(\pmb{x}|\pmb{z}) pθ(xxx∣zzz)进行采样,得到样本 x \pmb{x} xxx
为便于采样,通常 p θ ( x ∣ z ) p_{\theta}(\pmb{x}|\pmb{z}) pθ(xxx∣zzz)不能太过复杂。因此,另一种生成样本的思想是从一个简单分布 p ( z ) , z ∈ Z p(\pmb{z}),z \in Z p(zzz),z∈Z(比如标准正太分布)中采集一个样本 z \pmb{z} zzz,并利用一个深度神经网络 g : Z → X g:Z \to X g:Z→X使得 g ( z ) g(\pmb{z}) g(zzz)服从 p r ( x ) p_r(\pmb{x}) pr(xxx),这样,我们就可以避免密度估计问题,并有效降低生成样本的难度,即生成对抗网络的思想。
1.3 应用于监督学习
除了生成样本外,生成模型也可用于监督学习。监督学习的目标是建模样本 x \pmb{x} xxx和输出标签 y y y 之间的条件概率分布 p ( y ∣ x ) p(y|\pmb{x}) p(y∣xxx),根据贝叶斯公式:
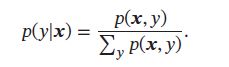
我们可以将监督学习问题转换为联合概率分布 p ( x , y ) p(\pmb{x},y) p(xxx,y)的密度估计问题
上图是带标签的生成模型的图模型表示,可以用于监督学习,在监督学习中,典型的生成模型有朴素贝叶斯分类器、隐马尔科夫模型。
判别模型 和生成模型相对应的另一类监督学习模型是判别模型(Discriminative Model)。判别模型直接建模条件概率分布 p ( y ∣ x ) p(y|\pmb{x}) p(y∣xxx),并不建模其联合概率分布 p ( x , y ) p(\pmb{x},y) p(xxx,y)。常见的判别模型有 Logistic回归、支持向量机、神经网络等。由生成模型可以得到判别模型,由判别模型得不到生成模型。
2. 变分自编码器
2.1 含隐变量的生成模型
假设一个生成模型中包含隐变量,即有部分变量时不可观测的,其中观测变量 X \pmb{X} XXX是一个高维空间 X X X中的随机向量,隐变量 Z \pmb{Z} ZZZ是一个相对低维空间 Z Z Z中的随机向量。
这个生成模型的联合概率密度函数可以分解为:
![]()
其中 p ( z ; θ ) p(\pmb{z};\theta) p(zzz;θ)为隐变量 z \pmb{z} zzz先验分布的概率密度函数, p ( x ∣ z ; θ ) p(\pmb{x}|\pmb{z};\theta) p(xxx∣zzz;θ)为已知 z \pmb{z} zzz时观测变量 x \pmb{x} xxx的条件概率密度函数, θ \theta θ表示两个密度函数的参数。一般情况下,我们可以假设 p ( z ; θ ) p(\pmb{z};\theta) p(zzz;θ)和 p ( x ∣ z ; θ ) p(\pmb{x}|\pmb{z};\theta) p(xxx∣zzz;θ)为某种参数化的分布族,比如正太分布,这些分布的形式已知,只是参数 θ \theta θ未知,可以通过最大化似然来进行估计。
给定一个样本 x \pmb{x} xxx,其对数边际似然 log p ( x ; θ ) \log p(\pmb{x};\theta) logp(xxx;θ)可以分解为:

其中 q ( z ; ϕ ) q(z;\phi) q(z;ϕ)是额外引入的变分密度函数,其参数为 ϕ \phi ϕ, E L B O ( q , x ; θ , ϕ ) ELBO(q,\pmb{x};\theta,\phi) ELBO(q,xxx;θ,ϕ)为证据下界:
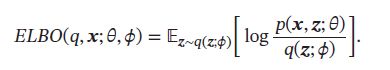
最大化对数边际似然 log p ( x ; θ ) \log p(\pmb{x};\theta) logp(xxx;θ)可以用EM算法来求解,在EM算法的每次迭代中,具体可以分为两步:
- E步:固定 θ \theta θ,寻找一个密度函数 q ( z ; ϕ ) q(z;\phi) q(z;ϕ)使其等于或接近于后验密度函数 p ( z ∣ x ; θ ) p(\pmb{z}|\pmb{x};\theta) p(zzz∣xxx;θ);
- M步:固定 q ( z ; ϕ ) q(z;\phi) q(z;ϕ),寻找 θ \theta θ来最大化 E L B O ( q , x ; θ , ϕ ) ELBO(q,\pmb{x};\theta,\phi) ELBO(q,xxx;θ,ϕ)
不断重复上述两步骤,直到收敛。
在EM算法的每次迭代中,理论上最优的 q ( z ; ϕ ) q(z;\phi) q(z;ϕ)为隐变量的后验概率密度函数 p ( z ∣ x ; θ ) p(\pmb{z}|\pmb{x};\theta) p(zzz∣xxx;θ):

后验概率密度函数 p ( z ∣ x ; θ ) p(z|\pmb{x};\theta) p(z∣xxx;θ)的计算是一个统计推断问题,涉及积分计算。当隐变量 z \pmb{z} zzz是有限的一维离散变量时,计算起来容易。但通常,这个后验概率难计算。通常需要通过变分推断来近似估计,在变分推断中,为降低复杂度,常会选择一些比较简单的分布 q ( z ; ϕ ) q(z;\phi) q(z;ϕ)来近似推断 p ( z ∣ x ; θ ) p(\pmb{z}|\pmb{x};\theta) p(zzz∣xxx;θ),当 p ( z ∣ x ; θ ) p(z|x;\theta) p(z∣x;θ)比较复杂时,近似效果不佳。此外,概率密度函数 p ( x ∣ z ; θ ) p(\pmb{x}|z;\theta) p(xxx∣z;θ)一般也比较复杂,很难直接用已知的分布族函数来进行建模。
变分自编码器(Variational AutoEncoder,VAE)是一种深度生成模型,其思想是利用神经网络来分别建模两个复杂的条件概率密度函数。
- 用神经网络来估计变分分布 q ( z ; ϕ ) q(z;\phi) q(z;ϕ),称为推断网络。理论上 q ( z ; ϕ ) q(z;\phi) q(z;ϕ)可以不依赖 x \pmb{x} xxx,但由于 q ( z ; ϕ ) q(z;\phi) q(z;ϕ)的目标是近似后验分布 p ( z ∣ x ; θ ) p(\pmb{z}|\pmb{x};\theta) p(zzz∣xxx;θ),其和 x \pmb{x} xxx相关,因此变分密度函数一般写为 q ( z ∣ x ; ϕ ) q(\pmb{z}|\pmb{x};\phi) q(zzz∣xxx;ϕ)。推断网络的输入为 x \pmb{x} xxx,输出为变分分布 q ( z ∣ x ; ϕ ) q(\pmb{z}|\pmb{x};\phi) q(zzz∣xxx;ϕ)
- 用神经网络来估计概率分布 p ( x ∣ z ; θ ) p(\pmb{x}|\pmb{z};\theta) p(xxx∣zzz;θ),称为生成网络。生成网络的输入为 z \pmb{z} zzz,输出为概率密度 p ( x ∣ z ; θ ) p(\pmb{x}|\pmb{z};\theta) p(xxx∣zzz;θ)
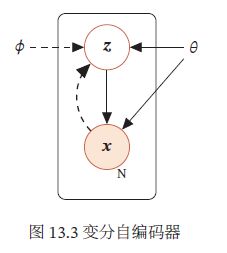
将推断网络和生成网络合并就得到了变分自编码器的整个网络结构,如图,其中实线表示网络计算操作,虚线表示采样操作:
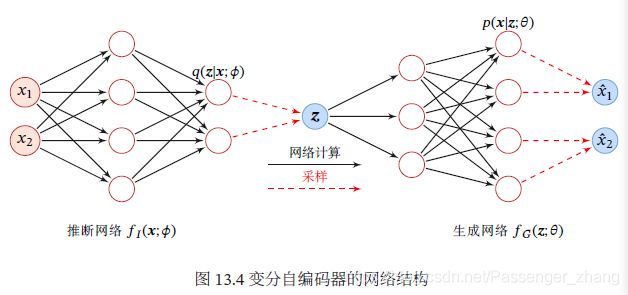
变分自编码器的名字因其网络结构和自编码器类似。推断网络可以看做是编码器,将可观测变量映射为隐变量。生成网络可以看做是解码器,将隐变量映射为可观测变量,但变分自编码器背后的原理和自编码器完全不同。变分自编码器中的编码器和解码器的输出为分布(或分布的参数),而不是确定的编码。
2.2 推断网络
简单起见,假设 q ( z ∣ x ; ϕ ) q(\pmb{z}|\pmb{x};\phi) q(zzz∣xxx;ϕ)是服从对角化协方差的高斯分布:
![]()
其中 μ I \mu_I μI和 σ I 2 \sigma_I^2 σI2是高斯分布的均值和方差,可以通过推断网络 f I ( x ; ϕ ) f_I(\pmb{x};\phi) fI(xxx;ϕ)来预测:

其中推断网络 f I ( x ; ϕ ) f_I(\pmb{x};\phi) fI(xxx;ϕ)可以是一般的全连接网络或卷积网络,比如一个两层的神经网络:
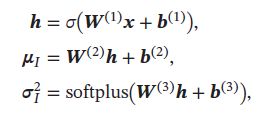
其中 ϕ \phi ϕ代表所有的网络参数 { W ( 1 ) , W ( 2 ) , W ( 3 ) , b ( 1 ) , b ( 2 ) , b ( 3 ) } \{\pmb{W}^{(1)},\pmb{W}^{(2)},\pmb{W}^{(3)},\pmb{b}^{(1)},\pmb{b}^{(2)},\pmb{b}^{(3)}\} { WWW(1),WWW(2),WWW(3),bbb(1),bbb(2),bbb(3)}, σ \sigma σ和softplus为激活函数,这里使用softplus激活函数是由于方差总是非负的。在实际中,也可用一个线性层(不需激活函数)来预测 log ( σ I 2 ) \log(\sigma_I^2) log(σI2)
2.2.1 推断网络的目标
推断网络的目标是使得 q ( z ∣ x ; θ ) q(\pmb{z}|\pmb{x};\theta) q(zzz∣xxx;θ)尽可能接近真实的后验 p ( z ∣ x ; θ ) p(z|\pmb{x};\theta) p(z∣xxx;θ),需要找到一组网络参数 ϕ ∗ \phi^* ϕ∗来最小化两个分布的KL散度,即:
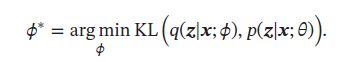
然而,直接计算上面的KL散度不行,因为 p ( z ∣ x ; θ ) p(z|\pmb{x};\theta) p(z∣xxx;θ)一般无法计算。传统方法是利用采样或者变分来近似推断。基于采样的方法效率低、估计不准确。故常用变分推断方法,即用简单的分布 q去近似复杂的分布 p ( z ∣ x ; θ ) p(z|\pmb{x};\theta) p(z∣xxx;θ)。但是,在深度生成模型中, p ( z ∣ x ; θ ) p(z|\pmb{x};\theta) p(z∣xxx;θ)常复杂,很难用简单分布去近似。因此需要一种间接计算方法。
根据公式:
![]()
可知,变分分布 q ( z ∣ x ; ϕ ) q(\pmb{z}|\pmb{x};\phi) q(zzz∣xxx;ϕ)与真实后验 p ( z ∣ x ; ϕ ) p(\pmb{z}|\pmb{x};\phi) p(zzz∣xxx;ϕ)的KL散度等于对数边际似然 log p ( x ; θ ) \log p(\pmb{x};\theta) logp(xxx;θ)与其下界 E L B O ( q , x ; θ , ϕ ) ELBO(q,\pmb{x};\theta,\phi) ELBO(q,xxx;θ,ϕ)的差,即:
![]()
因此,推断网络的目标函数可以转换为:

即推断网络的目标转换为寻找一组网络参数 ϕ ∗ \phi^* ϕ∗使得证据下界 E L B O ( q , x ; θ , ϕ ) ELBO(q,\pmb{x};\theta,\phi) ELBO(q,xxx;θ,ϕ)最大,这和变分推断中的转换类似。
2.3 生成网络
生成模型的联合分布 p ( x , z ; θ ) p(\pmb{x},\pmb{z};\theta) p(xxx,zzz;θ)可以分解为两部分:隐变量 z \pmb{z} zzz的先验分布 p ( z ; θ ) p(z;\theta) p(z;θ)和条件概率分布 p ( x ∣ z ; θ ) p(x|z;\theta) p(x∣z;θ)
先验分布 p ( z ; θ ) p(z;\theta) p(z;θ) 简单起见,假设隐变量 z \pmb{z} zzz的先验分布为各向同性的标准高斯分布 N ( z ∣ 0 , I ) N(\pmb{z}|0,I) N(zzz∣0,I)。隐变量z的每一维之间都是独立的
条件概率分布 p ( x ∣ z ; θ ) p(x|z;\theta) p(x∣z;θ) 条件概率分布 p ( x ∣ z ; θ ) p(\pmb{x}|\pmb{z};\theta) p(xxx∣zzz;θ)可以通过 生成网络来建模,为简单起见,同样用参数化的分布族来表示条件概率分布 p ( x ∣ z ; θ ) p(\pmb{x}|\pmb{z};\theta) p(xxx∣zzz;θ),这些分布族的参数可以用生成网络计算得到
根据变量 x \pmb{x} xxx的类型不同,可假设 p ( x ∣ z ; θ ) p(\pmb{x}|\pmb{z};\theta) p(xxx∣zzz;θ)服从不同的分布族:
-
如果 x ∈ { 0 , 1 } D \pmb{x}\in \{0,1\}^D xxx∈{ 0,1}D是D维的维二值的向量,可以假设 p ( x ∣ z ; θ ) p(\pmb{x}|\pmb{z};\theta) p(xxx∣zzz;θ)服从多变量的伯努利分布,即:

其中 y d ≜ p ( x d = 1 ∣ z ; θ ) y_d \triangleq p(x_d =1|z;\theta) yd≜p(xd=1∣z;θ)为第d维分布的参数,分布的参数 y = [ y 1 , ⋯ , y D ] T y=[y_1,\cdots,y_D]^T y=[y1,⋯,yD]T可以通过生成网络来预测 -
如果 x ∈ R D \pmb{x}\in \R^D xxx∈RD是D维的连续向量,可以假设为 p ( x ∣ z ; θ ) p(\pmb{x}|\pmb{z};\theta) p(xxx∣zzz;θ)服从对角化协方差的高斯分布,即:

其中 μ G ∈ R D \mu_G \in \R^D μG∈RD和 σ G ∈ R D \sigma_G \in \R^D σG∈RD同样可以用生成网络 f G ( z ; θ ) f_G(z;\theta) fG(z;θ)来预测
2.3.1 生成网络的目标
生成网络 f G ( z ; θ ) f_G(\pmb{z};\theta) fG(zzz;θ)的目标是找到一组网络参数 θ ∗ \theta^* θ∗来最大化 E L B O ( q , x ; θ , ϕ ) ELBO(q,\pmb{x};\theta,\phi) ELBO(q,xxx;θ,ϕ):

2.4 模型汇总
结合公式:

和:
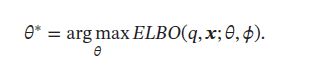
推断网络和生成网络的目标都为最大化证据下界 E L B O ( q , x ; θ , ϕ ) ELBO(q,\pmb{x};\theta,\phi) ELBO(q,xxx;θ,ϕ).因此,变分自编码器的总目标函数为:
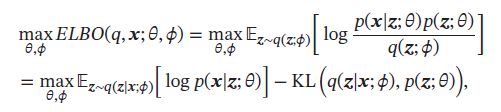
其中 p ( z ; θ ) p(\pmb{z};\theta) p(zzz;θ)为先验分布, θ \theta θ和 ϕ \phi ϕ分别表示生成网络和推断网络的参数。
从EM算法角度来看,变分自编码器优化推断网络和生成网络的过程可看做EM算法的E步和M步。但在变分自编码器中 ,两步的目标合二为一,都是最大化证据下界。此外,变分自编码器可看做神经网络和贝叶斯网络的混合体。贝叶斯网络中的节点可以看成一个随机变量;在变分自编码器中,仅仅将隐藏编码对应的节点看做随机变量,其他节点还是作为普通神经元。这样,编码器变成一个变分推断网络,而解码器看做将隐变量映射到观测变量的生成网络。
对于公式13.21:

- 第一项的期望 E [ ] E[] E[]可以通过采样的方式近似计算,对于每个样本 x \pmb{x} xxx,根据 q ( z ∣ x ; ϕ ) q(\pmb{z}|\pmb{x};\phi) q(zzz∣xxx;ϕ)采集M个 z ( m ) , 1 ≤ m ≤ M \pmb{z}^{(m)},1 \leq m \leq M zzz(m),1≤m≤M,有:

期望 E [ ] E[] E[]依赖于参数 ϕ \phi ϕ。但在上面的近似中,这个期望和 ϕ \phi ϕ无关。当使用梯度下降法来学习参数时,期望 E [ ] E[] E[]关于 ϕ \phi ϕ的梯度为0。这种情况是由于变量 z \pmb{z} zzz和参数 ϕ \phi ϕ之间不是直接的确定性关系,而是一种采样关系。这种情况可以通过两种方法解决:再参数化;梯度估计 - 第二项的KL散度通常可以直接计算,特别当 q ( z ∣ x ; ϕ ) q(\pmb{z}|\pmb{x};\phi) q(zzz∣xxx;ϕ)和 p ( z ; θ ) p(\pmb{z};\theta) p(zzz;θ)都是正太分布时,他们的KL散度可以直接计算出闭式解
给定D维空间中的两个正太分布 N ( μ 1 , ∑ 1 ) N(\mu_1,\sum_1) N(μ1,∑1)和 N ( μ 2 , ∑ 2 ) N(\mu_2,\sum_2) N(μ2,∑2),其KL散度为:

其中 t r ( ⋅ ) tr(\cdot) tr(⋅)表示矩阵的迹, ∣ ⋅ ∣ |\cdot| ∣⋅∣表示矩阵的行列式。
这样,当 p ( z ; θ ) = N ( z ; 0 , I ) p(\pmb{z};\theta)=N(\pmb{z};0,I) p(zzz;θ)=N(zzz;0,I)、 q ( z ∣ x ; ϕ ) = N ( z ; μ I , σ I 2 I ) q(\pmb{z}|\pmb{x};\phi)=N(\pmb{z};\mu_I,\sigma_I^2I) q(zzz∣xxx;ϕ)=N(zzz;μI,σI2I)时:

其中 μ I \mu_I μI和 σ I \sigma_I σI为推断网络 f I ( x ; ϕ ) f_I(\pmb{x};\phi) fI(xxx;ϕ)的输出。
2.5 再参数化
再参数化(Reparameterization)是将一个函数 f ( θ ) f(\theta) f(θ)的参数 θ \theta θ用另外一组参数表示 θ = g ( δ ) \theta=g(\delta) θ=g(δ),这样 f ( θ ) f(\theta) f(θ)就转为参数为 δ \delta δ的函数 f ( δ ) = f ( g ( δ ) ) f(\delta)=f(g(\delta)) f(δ)=f(g(δ)).再参数化通常用来将原始参数转化为另外一组具有特殊属性的参数,比如当 θ \theta θ为一个很大的矩阵时,可以使用两个低秩矩阵的乘积来再参数化,从而减少参数量。
在公式:
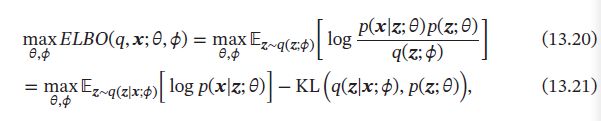
中,期望 E [ ] E[] E[]依赖于分布q的参数 ϕ \phi ϕ。但,由于随机变量 z \pmb{z} zzz采样自后验分布 q ( z ∣ x ; ϕ ) q(\pmb{z}|\pmb{x};\phi) q(zzz∣xxx;ϕ),他们之间是不确定性关系,故无法直接求解 z \pmb{z} zzz关于参数 ϕ \phi ϕ的导数,此时,可通过再参数化来将 z \pmb{z} zzz和 ϕ \phi ϕ之间随机性的采样关系转变为确定性函数关系。
引入一个分布为 p ( ϵ ) p(\epsilon) p(ϵ)的随机变量 ϵ \epsilon ϵ,期望 E [ ] E[] E[]可以重写为:
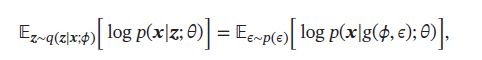
其中 z ≜ g ( ϕ , ϵ ) z \triangleq g(\phi,\epsilon) z≜g(ϕ,ϵ)为一个确定性函数。
假设 q ( z ∣ x ; ϕ ) q(\pmb{z}|\pmb{x};\phi) q(zzz∣xxx;ϕ)为正太分布 N ( μ I , σ I 2 I ) N(\mu_I,\sigma_I^2I) N(μI,σI2I),其中 { μ I , σ I } \{\mu_I,\sigma_I\} { μI,σI}是推断网络 f I ( x ; ϕ ) f_I(\pmb{x};\phi) fI(xxx;ϕ)的输出,起来于参数 ϕ \phi ϕ,可以通过下面方式来再参数化:
![]()
其中 ϵ \epsilon ϵ 服从 N ( 0 , I ) N(0,I) N(0,I)分布,这样 z \pmb{z} zzz和参数 ϕ \phi ϕ的关系从采样关系变为确定性关系,使得 z \pmb{z} zzz服从 q ( z ∣ x ; ϕ ) q(z|x;\phi) q(z∣x;ϕ)的随机性独立性与参数 ϕ \phi ϕ,从而可以求 z \pmb{z} zzz关于 ϕ \phi ϕ的导数。
2.6 训练
通过再参数化,变分自编码器可通过梯度下降来学习参数。
给定数据集 D = { x ( n ) } n = 1 N D=\{\pmb{x}^{(n)}\}_{n=1}^N D={ xxx(n)}n=1N,对于每个样本 x ( n ) \pmb{x}^{(n)} xxx(n),随机采样M个变量 ϵ ( n , m ) , 1 ≤ m ≤ M \epsilon^{(n,m)},1 \leq m \leq M ϵ(n,m),1≤m≤M,并通过公式:

计算 z ( n , m ) \pmb{z}^{(n,m)} zzz(n,m).变分自编码器的目标函数近似为:
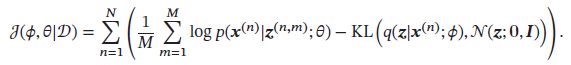
如果采用随机梯度方法,每次从数据中采集一个样本 x \pmb{x} xxx和一个对应的随机变量 ϵ \epsilon ϵ,并进一步假设 p ( x ∣ z ; θ ) p(\pmb{x}|\pmb{z};\theta) p(xxx∣zzz;θ)服从高斯分布 N ( x ∣ μ G , I ) N(\pmb{x}|\mu_G,I) N(xxx∣μG,I),其中 μ G = f G ( z ; θ ) \mu_G=f_G(\pmb{z;\theta}) μG=fG(z;θz;θz;θ)是生成网络的输出,目标函数可以简化为:
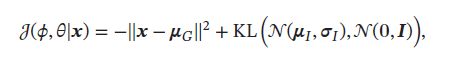
其中第一项可近似看做输入x的重构正确性,第二项可看做正则化项。类似自编码器,但内在机理不同。
变分自编码器的训练如图,空心矩形表示目标函数:

下图是在MNIST数据集上变分自编码器学习到的隐变量流形的可视化示例。图a是将训练集上每个样本x通过推断网络映射到2维的隐变量空间,图中每个点表示 E [ z ∣ x ] E[z|x] E[z∣x],不同颜色表示不同的数字;图b是2维的标准高斯分布上进行均匀采样得到不同的隐变量z,然后通过生成网络产生 E [ z ∣ x ] E[z|x] E[z∣x]

3. 生成对抗网络
3.1 显式密度模型和隐式密度模型
变分自编码器、深度信念网络等,都是显示地构建出样本的密度函数 p ( x ; θ ) p(\pmb{x};\theta) p(xxx;θ),并通过最大似然估计来求解参数,称为显示密度模型(Explicit Density Model)。变分自编码器的密度函数为 p ( x , z ; θ ) = p ( x ∣ z ; θ ) p ( z ; θ ) p(\pmb{x},\pmb{z};\theta)=p(\pmb{x}|\pmb{z};\theta)p(\pmb{z};\theta) p(xxx,zzz;θ)=p(xxx∣zzz;θ)p(zzz;θ)。虽然使用了神经网络来估计 p ( x ∣ z ; θ ) p(\pmb{x}|\pmb{z};\theta) p(xxx∣zzz;θ),但是依然假设 p ( x ∣ z ; θ ) p(\pmb{x}|\pmb{z};\theta) p(xxx∣zzz;θ)为一个参数分布族,而神经网络知识用来预测这个参数分布族的参数,这在一定程度上限制了神经网络的能力。
如果只想模型能生成符合数据分布 p r ( x ) p_r(\pmb{x}) pr(xxx)的样本,那么可以不显示地估计数据分布的密度函数。假设在低维空间Z中有一个简单容易采样的分布 p ( z ) p(z) p(z), p ( z ) p(z) p(z)通常为标准多元正太分布 N ( 0 , I ) N(0,I) N(0,I)。用神经网络构建一个映射函数 G : Z → X G:Z\to X G:Z→X称为生成网络,利用神经网络强大的拟合能力,使得 G ( z ) G(\pmb{z}) G(zzz)服从数据分布 p r ( x ) p_r(\pmb{x}) pr(xxx)。这种模型为隐式密度模型(Implicit Density Model),就是不显示地建模 p r ( x ) p_r(\pmb{x}) pr(xxx),而建模生成过程:

3.2 网络分解
3.2.1 判别网络
隐式密度模型一关键是如何确保生成网络产生的样本服从真实分布,既然不构建显示密度函数,则无法通过最大似然估计等方法来训练。
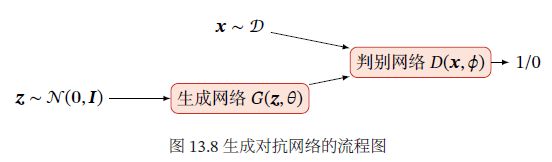
生成对抗网络(Generative Adversarial Networks,GAN)通过对抗训练的方式,使得生成网络产生的样本服从真实数据分布。在生成对抗网络中,有两个网络进行对抗训练:一是判别网络,其目标是尽量准确地判断一个样本时来自真实数据还是由生成网络生成;另一是生成网络,其目标是尽量生成判别网络无法区分来源的样本。这两个目标相反的网络不断进行交替训练,当最后收敛时,若判别网络无法判断出一个样本的来源,则等价于生成网络可以生成符合真实数据分布的样本。生成对抗网络流程图:
判别网络(Discriminator Network) D ( x ; ϕ ) D(\pmb{x};\phi) D(xxx;ϕ) 的目标是区分一个样本 x 是来自真实分布 p r ( x ) p_r(\pmb{x}) pr(xxx)还是来自生成模型 p θ ( x ) p_{\theta}(\pmb{x}) pθ(xxx),因此判别网络实际上是一个二分类的分类器。用 y = 1 y=1 y=1表示样本来自真实分布, y = 0 y=0 y=0表示样本来自生成模型,判别网络 D ( x ; ϕ ) D(\pmb{x};\phi) D(xxx;ϕ)的输出为 x \pmb{x} xxx即:
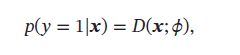
则样本来自生成模型的概率为 p ( y = 0 ∣ x ) = 1 − D ( x ; ϕ ) p(y=0|\pmb{x})=1-D(\pmb{x};\phi) p(y=0∣xxx)=1−D(xxx;ϕ)
给定样本 ( x , y ) (\pmb{x},y) (xxx,y), y = 1 , 0 y={1,0} y=1,0表示其来自于 p r ( x ) p_r(\pmb{x}) pr(xxx)还是 p θ ( x ) p_{\theta}(\pmb{x}) pθ(xxx),判别网络的目标函数为最小化交叉熵:

假设分布 p ( x ) p(\pmb{x}) p(xxx)是由分布 p r ( x ) p_r(\pmb{x}) pr(xxx)、 p θ ( x ) p_{\theta}(\pmb{x}) pθ(xxx)等比例混合而成,即 p ( x ) = 1 2 ( p r ( x ) + p θ ( x ) ) p(\pmb{x})=\frac{1}{2}(p_r(\pmb{x})+p_{\theta}(\pmb{x})) p(xxx)=21(pr(xxx)+pθ(xxx)),则上式等价于:
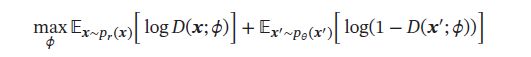
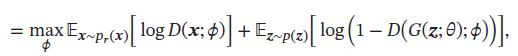
其中 θ \theta θ和 ϕ \phi ϕ分别是生成网络和判别网络的参数。
3.2.2 生成网络
生成网络(Generator Network)的目标刚好和判别网络相反,即让判别网络将自己生成的样本判别为真实样本:
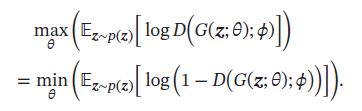
上面两目标函数等价,但实际训练中,常用前者,因为其梯度性质更好。函数 log ( x ) , x ∈ ( 0 , 1 ) \log(x),x \in (0,1) log(x),x∈(0,1)在x接近于1时的梯度要比接近0时的梯度小很多,接近饱和区间,这样,当判别网络D以很高的概率认为生成网络G产生的样本是假样本,即 ( 1 − D ( G ( z ; θ ) ; ϕ ) ) → 1 (1-D(G(z;\theta);\phi)) \to 1 (1−D(G(z;θ);ϕ))→1,这时目标函数关于 θ \theta θ的梯度反而很小,从而不利于优化。
3.3 训练
相比于单目标优化任务,生成对抗网络的两网络的优化目标刚好相反。故GAN的训练比较难,往往不稳定,通常,需要平衡两个网络的能力。对于判别网络,一开始的判别能力不能太强,否则难以提升生成网络的能力;但也不能太弱,否则针对它训练的生成网络不好。训练时,应用一些技巧,每次迭代时,判别网络比生成网络的能力强一些,但又不能太强。
GAN的训练流程如下,每次迭代时,判别网络更新K次,而生成网络更新一次,即首先要保证判别网络足够强才能开始训练生成网络。在实践中K是一个超参数,其取值一般取决于具体任务:

3.4 一个生成对抗网络的具体实现:DCGAN
GAN指一类采用对抗训练方式来进行学习的深度生成模型,其包含的判别网络和生成网络都可以根据不同的生成任务使用不同的结构。
深度卷积生成对抗网络(Deep Convolutional Generative Adversarial Network,DCGAN),在DCGAN中,判别网络是一个传统的卷积网络,但使用了带步长的卷积来实现下采样,不用最大池化;生成网络使用一个特殊的卷积网络,如图,使用微步卷积来生成 64 × 64 64 \times 64 64×64大小的图像。

DCGAN的主要优点是通过一些经验性的网络结构设计使得对抗训练更加稳定,比如:
- 使用带步长的卷积(在判别网络中)和微步卷积(在生成网络中)来代替池化操作,以免损失信息;
- 使用批量归一化
- 去除卷积层之后的全连接层
- 在生成网络中,除了最后一层使用Tanh激活函数外,其余层都使用了ReLU函数
- 在判别网络中,都用了LeakyReLU激活函数。
3.5 模型分析
将判别网络和生成网络合并,真个GAN的目标函数可看做最小化最大化游戏(Minimax Game):
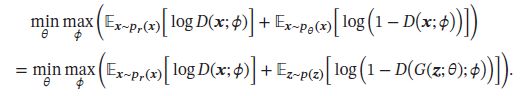
因为之前提到的生成网络梯度问题,这个最小化最大化形式的目标函数一般用来理论分析,而非实际训练的目标函数。
假设 p r ( x ) p_r(\pmb{x}) pr(xxx)、 p θ ( x ) p_{\theta}(\pmb{x}) pθ(xxx)已知,则最优的判别器为:

将最优的判别器 D ∗ ( x ) D^*(\pmb{x}) D∗(xxx)代入公式:

目标函数变为:
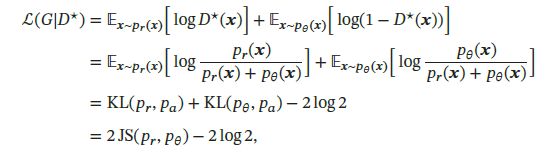
其中 J S ( ⋅ ) JS(\cdot) JS(⋅)为JS散度, p a ( x ) = 1 2 ( p r ( x ) + p θ ( x ) ) p_a(\pmb{x})=\frac{1}{2}(p_r(\pmb{x})+p_{\theta}(\pmb{x})) pa(xxx)=21(pr(xxx)+pθ(xxx))为一个平均分布。
在生成对抗网络中,当判别网络最优时,生成网络的优化目标是最小化真实分布 p r p_r pr和模型分布 p θ p_{\theta} pθ之间的JS散度。当两个分布相同时,JS散度为0,最优生成网络 G ∗ G^* G∗对应的损失为 L ( G ∗ ∣ D ∗ ) = − 2 log 2 L(G^*|D^*)=-2\log2 L(G∗∣D∗)=−2log2
3.5.1 训练稳定性
使用JS散度来训练GAN的一问题是,当l个分布无重叠时,他们的JS散度恒等于常数 log 2 \log2 log2,对生成网络来说,目标函数关于参数的梯度为0,即:
![]()
下图是GAN中梯度消失问题的示例。当真实分布 p r p_r pr和模型分布 p θ p_{\theta} pθ没有重叠时,最优的判别器 D ∗ D^* D∗对所有生成数据的输出都为0,即 D ∗ ( G ( z ; θ ) ) = 0 , ∀ z D^*(G(\pmb{z};\theta))=0,\forall z D∗(G(zzz;θ))=0,∀z,故生成网络的梯度消失。
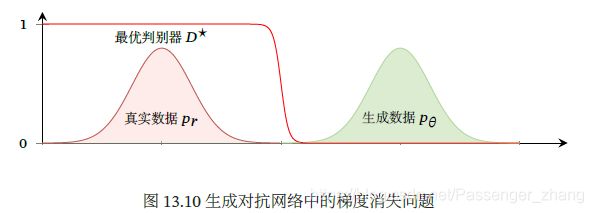
故实际训练中,不会讲判别网络训练到最优,只进行一步或多步梯度下降,使得生成网络的梯度依然存在,另外,判别网络也不能太差,否则生成网络的梯度为错误的梯度,但是如何在梯度消失和梯度错误之间取得平衡不易,这使得GAN训练时稳定性差。
3.5.2 模型坍塌
如使用公式:

作为生成网络的目标函数,将最优判别器 D ∗ D^* D∗代入,得到:

其中后两项和生成网络无关,故:

其中JS散度 J S ( p θ , p r ) ∈ [ 0 , log 2 ] JS(p_{\theta},p_r)\in [0,\log2] JS(pθ,pr)∈[0,log2]为有界函数,故生成网络的目标更多的是受逆向KL散度 K L ( p θ , p r ) KL(p_{\theta},p_r) KL(pθ,pr)影响,使得生成网络更倾向于生成一些“安全”的样本,从而造成模型坍塌(Model Collapse)问题
前向和逆向KL散度 因KL散度是一种非对称的散度,计算 p r p_r pr和 p θ p_{\theta} pθ之间的KL散度时,按顺序不同,有两种KL散度:前向KL散度(Forward KL divergence) K L ( p r , p θ ) KL(p_r,p_{\theta}) KL(pr,pθ)和逆向KL散度(Reverse KL divergence) K L ( p θ , p r ) KL(p_{\theta},p_r) KL(pθ,pr)。前向和逆向KL散度分别定义为:
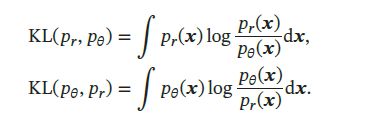
下图是数据真实分布为一个高斯分布,模型分布为一单高斯分布时,使用前向和逆向KL散度来进行模型优化的示例。黑色曲线为真实分布 p r p_r pr等高线,红色曲线为模型 p θ p_{\theta} pθ的等高线

前向KL散度中:
- p r ( x ) → 0 p_r(\pmb{x}) \to 0 pr(xxx)→0而 p θ ( x ) > 0 p_{\theta}(\pmb{x}) > 0 pθ(xxx)>0时, p r ( x ) log p r ( x ) p θ ( x ) → 0 p_r(\pmb{x})\log \frac{p_r(\pmb{x})}{p_{\theta}(\pmb{x})} \to 0 pr(xxx)logpθ(xxx)pr(xxx)→0 不管 p θ ( x ) p_{\theta}(\pmb{x}) pθ(xxx)如何取值,都对前向KL散度的计算没有贡献
- p r ( x ) > 0 p_r(\pmb{x}) > 0 pr(xxx)>0而 p θ ( x ) → 0 p_{\theta}(\pmb{x}) \to 0 pθ(xxx)→0时, p r ( x ) log p r ( x ) p θ ( x ) → ∞ p_r(\pmb{x})\log \frac{p_r(\pmb{x})}{p_{\theta}(\pmb{x})} \to \infty pr(xxx)logpθ(xxx)pr(xxx)→∞ ,前向KL散度变得非常大
故,前向KL散度会鼓励模型分布 p θ ( x ) p_{\theta}(\pmb{x}) pθ(xxx)尽可能覆盖所有真实分布 p r ( x ) > 0 p_r(\pmb{x}) > 0 pr(xxx)>0的点,而不用回避 p r ( x ) ≈ 0 p_r(\pmb{x}) \approx 0 pr(xxx)≈0的点
逆向KL散度中:
- p r ( x ) → 0 p_r(\pmb{x}) \to 0 pr(xxx)→0而 p θ ( x ) > 0 p_{\theta}(\pmb{x}) > 0 pθ(xxx)>0时, p r ( x ) log p r ( x ) p θ ( x ) → ∞ p_r(\pmb{x})\log \frac{p_r(\pmb{x})}{p_{\theta}(\pmb{x})} \to \infty pr(xxx)logpθ(xxx)pr(xxx)→∞, 即当 p θ ( x ) p_{\theta}(\pmb{x}) pθ(xxx)接近于0,而 p θ ( x ) p_{\theta}(\pmb{x}) pθ(xxx)有一定的密度时,逆向KL散度会变得非常大。
- p θ ( x ) → 0 p_{\theta}(\pmb{x}) \to 0 pθ(xxx)→0时,不管 p r ( x ) p_r(\pmb{x}) pr(xxx)如何取值, p r ( x ) log p r ( x ) p θ ( x ) → 0 p_r(\pmb{x})\log \frac{p_r(\pmb{x})}{p_{\theta}(\pmb{x})} \to 0 pr(xxx)logpθ(xxx)pr(xxx)→0
故,逆向KL散度会鼓励模型分布 p θ ( x ) p_{\theta}(\pmb{x}) pθ(xxx)尽可能避开所有真实分布 p r ( x ) ≈ 0 p_r(\pmb{x}) \approx 0 pr(xxx)≈0的点,而不用考虑是否覆盖所有真实分布 p r ( x ) > 0 p_r(\pmb{x}) > 0 pr(xxx)>0的点
3.6 改进模型
在GAN中,JS散度不适合衡量生成数据分布和真实数据分布的距离。由于通过优化交叉熵(JS散度)训练GAN会导致训练稳定性和模型坍塌问题,故要改进GAN,就要改变其损失函数。
3.6.1 W-GAN
W-GAN利用Wasserstein 距离代替JS散度来优化训练。
对于真实分布 p r p_r pr和模型分布 p θ p_{\theta} pθ,他们之间的1st-Wasserstein 距离:
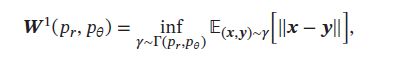
其中 T ( p r , p θ ) T(p_r,p_{\theta}) T(pr,pθ)是边际分布为 p r p_r pr和 p θ p_{\theta} pθ的所有恋歌分布集合。
当两个分布无重叠或重叠少,他们之间的KL散度为 + ∞ +\infty +∞,JS散度为 log 2 \log2 log2,并不随着两分布之间的距离变化
。而1st-Wasserstein 距离仍然可以衡量两个没有重叠分布之间的距离:

两分布 p r p_r pr和 p θ p_{\theta} pθ的1st-Wasserstein 距离通常难以直接计算,但有一个对偶形式,称为Kantorovich-Rubinstein 对偶定理:
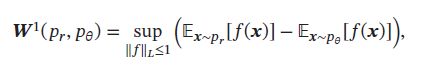
其中 f : R d → R f:\R^d \to \R f:Rd→R为 1-Lipschitz 函数,满足:

根据Kantorovich-Rubinstein 对偶定理,两个分布 p r p_r pr和 p θ p_{\theta} pθ的1st-Wasserstein 距离可转换为一个满足1-Lipschitz连续的函数在分布 p r p_r pr和 p θ p_{\theta} pθ下期望的差的上界。通常,1-Lipschitz连续的约束可以宽松为K-Lipschitz连续。这样,分布 p r p_r pr和 p θ p_{\theta} pθ之间的1st-Wasserstein 距离为:

评价网络 计算上述公式的上界不容易,根据神经网络的通用近似定理,可假设存在一个神经网络使得可以达到这个上界,令 f ( x ; ϕ ) f(\pmb{x};\phi) f(xxx;ϕ)为一个神经网络,假设存在参数集合 ϕ \pmb{\phi} ϕϕϕ,对于所有的 ϕ ∈ ϕ \phi \in \pmb{\phi} ϕ∈ϕϕϕ, f ( x ; ϕ ) f(\pmb{x};\phi) f(xxx;ϕ)为K-Lipschitz连续函数,上述公式中的上界可近似转换为:
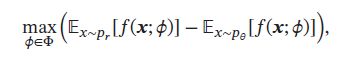
其中 f ( x ; ϕ ) f(\pmb{x};\phi) f(xxx;ϕ)称为评价网络(Critic Network).和标准GAN中的判别网络的值域为 [ 0 , 1 ] [0,1] [0,1]不同,评价网络 f ( x ; ϕ ) f(\pmb{x};\phi) f(xxx;ϕ)的最后一层为线性层,其值域没有限制。这样只需要找到一个网络 f ( x ; ϕ ) f(\pmb{x};\phi) f(xxx;ϕ)使其在两个分布 p r p_r pr和 p θ p_{\theta} pθ下的期望的差最大。即对于真实样本, f ( x ; ϕ ) f(\pmb{x};\phi) f(xxx;ϕ)的打分要尽可能高;对于模型生成的样本, f ( x ; ϕ ) f(\pmb{x};\phi) f(xxx;ϕ)的打分要尽可能低。
为了使得 f ( x ; ϕ ) f(\pmb{x};\phi) f(xxx;ϕ)满足K-Lipschitz 连续,一种近似的方法是限制参数的取值范围。因为神经网络为连续可导函数,满足K-Lipschitz 连续可以近似为其关于 x \pmb{x} xxx的偏导数的模 ∣ ∣ ∂ f ( x ; ϕ ) ∂ x ∣ ∣ ||\frac{\partial f(\pmb{x};\phi)}{\partial \pmb{x}}|| ∣∣∂xxx∂f(xxx;ϕ)∣∣小于某个上界。由于这个偏导数的大小一般和参数的取值范围相关,可以通过限制参数 ϕ \phi ϕ的取值范围来近似,令 ϕ ∈ [ − c , c ] \phi \in [-c,c] ϕ∈[−c,c],c为一个比较小的整数,比如0.01
生成网络 生成网络的目标是使得评价网络 f ( x ; ϕ ) f(\pmb{x};\phi) f(xxx;ϕ)对其生成样本的打分尽可能高,即:

因为 f ( x ; ϕ ) f(\pmb{x};\phi) f(xxx;ϕ)为不饱和函数,所以生成网络参数 θ \theta θ的梯度不会消失,理论上解决了GAN训练不稳定的问题,并且W-GAN中生成网络的目标函数不再是两个分布的比率,一定程度解决了模型坍塌问题。
和原始GAN相比,W-GAN的评价网络最后一层不使用Sigmoid函数,损失函数不取对数:
