WACV 2021 论文大盘点-图像与视频检索篇

本篇总结检索相关论文,包含视觉搜索、图像视频检索、跨域检索等。
值得关注的是由 Andrés Mafla 为一作的两篇检索类文章都入选了该会议,一篇是场景文本感知跨模态检索(StacMR)任务;一篇是融合多模态推理模块,结合文字和视觉特征对场景文本进行图像分类与检索,都取得了不错的成绩。
共计 9 篇。如有遗漏,欢迎补充。
下载包含这些论文的 WACV 2021 所有论文:
『WACV 2021 开幕,更偏重技术应用,附论文下载』
视觉搜索
Structured Visual Search via Composition-aware Learning
引入 composition-aware 学习概念,用于结构化图像搜索。
该方法由三部分组成:
Composition-aware transformation:计算输入和输出空间的变换
Composition-aware loss function:根据输入输出变换的差异更新网络参数
Composition-equivariant CNN:用于学习转换的骨干
并证明所提出方法在特征空间和数据空间都是有效的。在 MS-COCO 和 HICO-DET 两个大规模数据集上对所提出方法与具有竞争力技术相比,有相当大的改进。
作者 | Mert Kilickaya, Arnold W.M. Smeulders
单位 | 阿姆斯特丹大学
论文 | https://arxiv.org/abs/2010.14438

图像检索
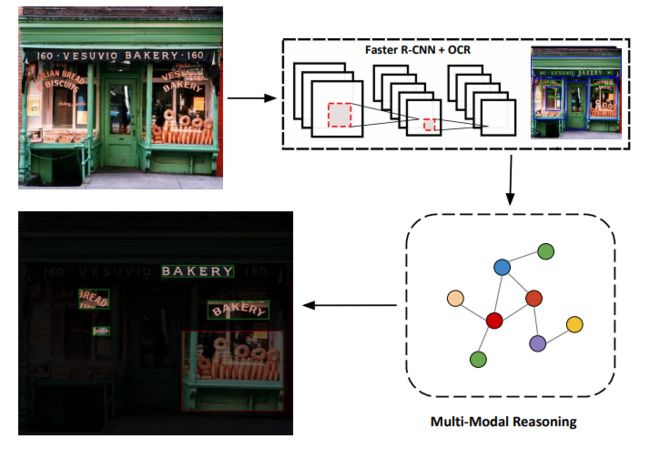
Multi-Modal Reasoning Graph for Scene-Text Based Fine-Grained Image Classification and Retrieval
本次研究中所提出的一种新架构,通过考虑图像的文本和视觉特征,在两个数据集中大大超越了以往最先进的结果,在细粒度分类上超过 5%,在图像检索上超过 10%。
设计一个完全的端到端可训练 pipeline,融合了多模态推理模块,结合文字和视觉特征,且不依赖于集合模型或预先计算的特征。
作者在论文中提供了详尽的实验,其中有对模型架构中不同模块的有效性的分析,以及场景文本对图像理解的综合模型的重要性的分析。
作者 | Andres Mafla, Sounak Dey, Ali Furkan Biten, Lluis Gomez, Dimosthenis Karatzas
单位 | cvc,uab
论文 | https://arxiv.org/abs/2009.09809
代码 | https://github.com/AndresPMD/GCN_classification
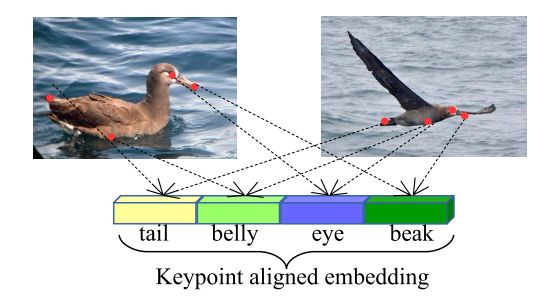
Keypoint-Aligned Embeddings for Image Retrieval and Re-Identification
由于形状的变形以及不同相机的视角,使得现有的人、车辆、动物重识别方法存在很大的类内差异。
作者在本次研究中,提出关键点对齐嵌入模型(KAE-Net),来学习姿势不变的图像嵌入。并证明可以通过重建姿势信息的辅助任务来学习姿势不变的嵌入。
KAE-Net 结构紧凑、通用,概念简单,在 CUB-200-2011、Cars196 和 VeRi-776 的基准数据集上实现了检索和重识别任务的最先进性能。
作者 | Olga Moskvyak, Frederic Maire, Feras Dayoub, Mahsa Baktashmotlagh
单位 | 昆士兰科技大学;昆士兰大学
论文 | https://arxiv.org/abs/2008.11368
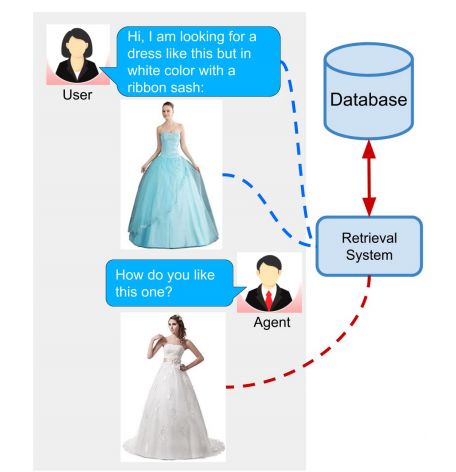
Compositional Learning of Image-Text Query for Image Retrieval
本次工作研究基于多模态(imagetext)查询的数据库图像检索问题。
所提出的 ComposeAE 模型以在 Fashion200k 上的 30.12% 和 MIT-States 上的 11.13% 的 Recall@10 指标的巨大优势优于 SOTA 方法 TIRG。对 SOTA 方法 TIRG进行了增强,以确保公平比较,并找出其局限性。
作者 | Muhammad Umer Anwaar, Egor Labintcev, Martin Kleinsteuber
单位 | 慕尼黑工业大学;Mercateo AG
论文 | https://arxiv.org/abs/2006.11149
代码 | https://anonymous.4open.science/r/d1babc3c-0e72-448a-8594-b618bae876dc/
前景图像检索
Fine-grained Foreground Retrieval via Teacher-Student Learning
前景图像检索是计算机视觉领域的一项具有挑战性的人物。它是给定一个具有边界框表示目标位置的背景场景图像,然后从给定类别中检索一组与背景在语义上兼容的前景目标图像。
作者在本次研究中将前景检索制定为一个自监督的域适应任务,其中源域由前景图像组成,目标域为背景图像。
具体来说,将预训练好的目标特征提取网络作为 teachers,训练一个 student 网络从背景图像中推理出兼容的前景特征。因此,前景和背景被有效地映射到一个共同的特征空间中,从而能够检索出该空间中最接近目标背景的前景。
不同目前最先进方法的是,所提出方法无需进行实例分割,因此可应用于不同的前景类别和背景场景类型,更接近实际应用的要求。
作者 | Zongze Wu, Dani Lischinski, Eli Shechtman
单位 | 伯来大学;Adobe Research
论文 |
https://openaccess.thecvf.com/content/WACV2021/papers/Wu_Fine-Grained_Foreground_Retrieval_via_Teacher-Student_Learning_WACV_2021_paper.pdf

跨域检索
StacMR: Scene-Text Aware Cross-Modal Retrieval
本文介绍了场景文本感知跨模态检索(StacMR)任务,并将场景文本作为跨模态检索的第三种模式进行研究。
作者 | Andrés Mafla, Rafael Sampaio de Rezende, Lluís Gómez, Diane Larlus, Dimosthenis Karatzas
单位 | 西班牙巴塞罗那自治大学;NAVER LABS Europe
论文 | https://arxiv.org/abs/2012.04329
代码 | https://github.com/AndresPMD/StacMR
主页 | https://europe.naverlabs.com/research/computer-vision/stacmr-scene-text-aware-cross-modal-retrieval/

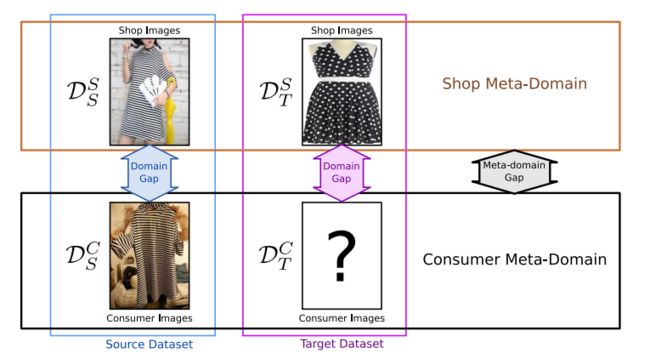
Unsupervised Meta-Domain Adaptation for Fashion Retrieval
作者 | Vivek Sharma, Naila Murray, Diane Larlus, Saquib Sarfraz, Rainer Stiefelhagen, Gabriela Csurka
单位 | KIT;NAVER LABS Europe;麻省理工学院;哈佛医学院
论文 |
https://openaccess.thecvf.com/content/WACV2021/papers/Sharma_Unsupervised_Meta-Domain_Adaptation_for_Fashion_Retrieval_WACV_2021_paper.pdf
视频片段检索
LoGAN: Latent Graph Co-Attention Network for Weakly-Supervised Video Moment Retrieval
提出一种全新的 latent co-attention 模型,可以显著改善视频与自然语言之间的 latent alignment,通过多级 coattention 机制,利用视频语言对的互补性,学习上下文的视觉语义表征。
还介绍一种新的 positional encodings 在视频特征中的应用,以学习时空感知的多模态表征。实验也证明该模型在性能上的大幅提升并不是因为简单地增加了参数数量,而是因为使用了这些 positional encodings。
所提出方法为未来在 latent coattention 模型上推理视频元素和自然语言模式之间直接关系的工作提供了有利参考。在 DiDeMo 和 Charades-St 两个数据集上实验结果明显优于当前最先进的(SOTA)弱监督方法。值得注意的是,在 DiDeMo 上,甚至比强监督 SOTA 方法的 Recall@1 精度提高了 11%。
作者 | Reuben Tan, Huijuan Xu, Kate Saenko, Bryan A. Plummer
单位 | 波士顿大学;伯克利
论文 | https://arxiv.org/abs/1909.13784
视频检索
Temporal Context Aggregation for Video Retrieval With Contrastive Learning
目前基于内容的视频检索的研究重点是需要更高层次的视频表征,来描述相关incidents, events 的长期语义依赖性。但现有的方法通常将视频的帧处理为单个图像或短片段,使得长期语义依赖性的建模变得困难。
在本次的工作任务中,作者提出视频表征学习框架:视频检索的时空上下文聚合(TCA),使用自注意力机制,融合了帧级特征之间的长期时间信息。
为了在视频检索数据集上进行训练,又提出一种监督式对比学习方法,该方法可以进行自动 Hard Negative Mining(难负例挖掘),并利用记忆库机制来增加负值样本的容量。
在 CC_WEB_VIDEO、FIVR-200K 和 EVVE等多个视频检索任务上的实验结果表明,与最先进的视频级特征方法相比,该方法具有显著的性能优势(在 FIVR-200K 上 的 mAP 约为 17%),并且与帧级特征相比,推理时间快了 22 倍,具有较强竞争力。
作者 | Jie Shao, Xin Wen, Bingchen Zhao, Xiangyang Xue
单位 | 复旦大学;同济大学;字节跳动
论文 | https://arxiv.org/abs/2008.01334

- END -
编辑:CV君
转载请联系本公众号授权

备注:检索

图像与视频检索交流群
图像检索、视频检索、视觉搜索、最近邻搜索等技术,
若已为CV君其他账号好友请直接私信。
OpenCV中文网
微信号 : iopencv
QQ群:805388940
微博/知乎:@我爱计算机视觉
网站:www.52cv.net

在看,让更多人看到 