Bert-实战
参考BERT fine-tune 终极实践教程
Bert 实战
bert在主要分为两个任务:一、训练
语言模型和预训练部分(run_pretraining.py),二、训练具体任务的fine-turning部分(run_classifier.py适用于分类情况/run_squad.py适用于问答情况)
一、 下载预训练模型, 预训练模型可以在google的开源界面找到,对于中文可以直接下载对应的中文预训练模型
打开预训练模型文件夹里面包含5个文件如图:
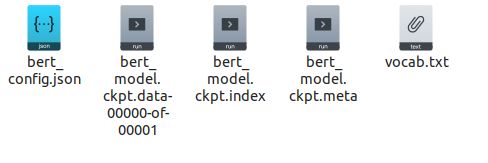
第一个json文件是训练时候可以调整的参数,之后的三个ckpt文件用于模型变量的载入,最后一个是训练中文文本使用的字典
二、修改processor部分
例如对于分类任务所在的run_classifier.py中,main函数预先写好了一些类型数据的processor方法比如:cola,mnli,mrpc

这里processor全部继承自DataProcessor类,包含的方法有获取单个输入的get_train_examples,get_dev_examples,get_test_examples(这三个函数几乎没有太大的区别,主要就是指定的文件的路径不同)分别会在main函数的FLAGS.do_train、FLAGS.do_eval、FLAGS.do_predict的时候调用 ,以及获取labels的get_labels。

对于get_***_examples,返回的是InputsExample类型的列表

InputsExample说是一个只有初始化的类,其中的guid参数是用来区分每个example的,按照guid的方式来定义,text_a则是另一串字符串,text_b则是另一串字符串,经过bert后续输入处理之后text_a与text_b将合并成[CLS]text_a[SEP]text_b[SEP]的形式传入模型。label参数也是字符串的形式,label的内容需要在get_labels范围之内

我们在定义自己的Processor时可以模仿官方给定的ColaProcess去实现其中的get_***_examples方法以及get_labels方法。
比如我们要实现句子相似度的二分类任务,文本内容如下:
1,你好,你好呀
0,你好,我觉得那样很帅
接下来编写自己新建的DataProcessor的get_train_examples方法:
def get_train_examples(self, data_dir):
file_path = os.path.join(data_dir, 'train.csv')
with open(file_path, 'r') as f:
reader = f.readlines()
examples = []
for index, line in enumerate(reader):
guid = 'train-%d'%index
split_line = line.strip().split(',')
text_a = tokenization.convert_to_unicode(split_line[1])
text_b = tokenization.convert_to_unicode(split_line[2])
label = split_line[0]
examples.append(InputExample(guid=guid, text_a=text_a,
text_b=text_b, label=label))
return examples
get_labels方法:
def get_labels(self):
return ['0','1']
get_test_examples 与 get_dev_examples 类似于如上的写法,对于get_test_examples随便传入labels,因为test时label不加入计算,到此,Processor的修改大致完成
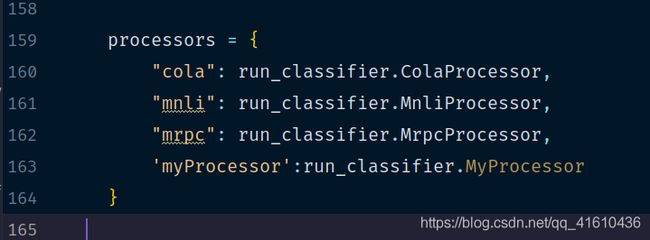
三、把自定义的Processor加入到processor中
四、启动fine-tuning
export BERT_BASE_DIR=/media/projects/bert/chinese_L-12_H-768_A-12 #全局变量 下载的预训练bert地址
export MY_DATASET=/media/projects/sim.data #全局变量 数据集所在地址
python run_classifier.py \
--task_name=mysim \ #自己添加processor在processors字典里的key名
--do_train=true \
--do_eval=true \
--dopredict=true \
--data_dir=$MY_DATASET \
--vocab_file=$BERT_BASE_DIR/vocab.txt \
--bert_config_file=$BERT_BASE_DIR/bert_config.json \
--init_checkpoint=$BERT_BASE_DIR/bert_model.ckpt \
--max_seq_length=128 \ #模型参数
--train_batch_size=32 \
--learning_rate=5e-5 \
--num_train_epochs=2.0 \
--output_dir=/media/projects/selfsim_output/ #模型输出路径
五、还发现了什么?
-
text_a与text_b实现拼接以及TFRocord化
数据在输入之后经过file_based_convert_examples_to_features添加上[CLS]以及[SEP],之后转化成TFRecord的形式

-
还有
create_model建立模型的时候,不仅创建了模型的主干的输出,还可以获得fine-tuning时候的loss结果

所以对fine-tuningg的结构有特定需求的话可以修改这部分,比如可以不只是让模型读第一位的logit而是可以读取每一位的logit。同时在这个函数里还可以修改output,把原先是获取每个句子的output,可以改为获取每个token的output,但是要做NER之类需要获取每个单词的embedding的时候需要注意开头的[CLS]和最后的[SEP]
-
由于使用的都是
tf.contrib.tpu.TPUEstimator,虽然gpu和tpu都可以用,如果想在gpu上更高效的运行,可以考虑换成tf.estimator.Estimator,同时代码里的tf.contrib.tpu.TPUEstimatorSpec也要换成tf.estimator.EstimatorSpec,相关参数也要做一些调整,具体操作可以可以看这里 -
添加打印过程的输出
if FLAGS.do_train:
train_file = os.path.join(FLAGS.output_dir, "train.tf_record")
file_based_convert_examples_to_features(
train_examples, label_list, FLAGS.max_seq_length, tokenizer, train_file)
tf.logging.info("***** Running training *****")
tf.logging.info(" Num examples = %d", len(train_examples))
tf.logging.info(" Batch size = %d", FLAGS.train_batch_size)
tf.logging.info(" Num steps = %d", num_train_steps)
train_input_fn = file_based_input_fn_builder(
input_file=train_file,
seq_length=FLAGS.max_seq_length,
is_training=True,
drop_remainder=True)
#todo 输出日志的同时可以打印loss
tensor_to_log = {
'train loss':"loss/Mean:0",'eval loss':'loss/Mean:0'}
logggin_hook = tf.train.LoggingTensorHook(tensors=tensor_to_log, every_n_iter=1)
estimator.train(input_fn=train_input_fn, max_steps=num_train_steps, hooks=[logggin_hook])
def metric_fn(per_example_loss, label_ids, logits, is_real_example):
predictions = tf.argmax(logits, axis=-1, output_type=tf.int32)
accuracy = tf.metrics.accuracy(
labels=label_ids, predictions=predictions, weights=is_real_example)
loss = tf.metrics.mean(values=per_example_loss, weights=is_real_example)
# todo 增加其他的指标
auc = tf.metrics.auc(labels=label_ids,predictions=predictions,weights=is_real_example)
precision = tf.metrics.precision(labels=label_ids,predictions=predictions,weights=is_real_example)
recall = tf.metrics.recall(labels=label_ids,predictions=predictions,weights=is_real_example)
return {
"eval_accuracy": accuracy,
"eval_loss": loss,
'eval_auc':auc,
'eval_precision':precision,
'eval_recall':recall,
}
- bert的学习率不适宜调的太大,官方是5e-5
- 建议使用官方的优化器,官方优化器学习率是动态调整的
- bert同下游任务训练需要不让bert模型参与训练当中,模型参数也需要进行冻结,参考这个链接的demo3
predict的时候一处adam的参数,可以是模型的大小变小很多,看这里
- 模型各个函数及类的介绍
- 对于模型的读取,查看模型的读取方法
- 更加详细的源码解读参考这里和这里
- modeling.py部分详细讲解请看这里
- 关于机器问答的实战看这里
- 大佬的bert的修改版AlBert开源代码
讯飞杯用bert进行中文机器阅读理解评测
更多实战链接