独家思维导图!让你秒懂李宏毅2020机器学习(一)
独家思维导图!让你秒懂李宏毅2020机器学习(一)
前言:博主为一名大二本科生,最近决心开始看李宏毅的深度学习系列课程,每学一个阶段决定写篇博客来归纳记录一下所学的东西,也希望自己的理解对大家有所帮助!
Introduction
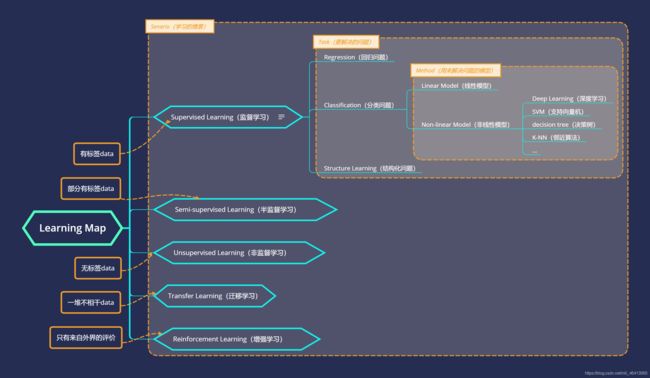
第一课的内容我用借鉴李宏毅老师ppt所画的一张图来总结(就不再过多赘述了)
Regression
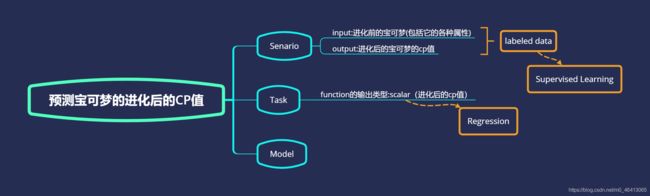
案例——预测宝可梦进化后的CP值
先与Introduction的部分回顾一下,确定
- Senario: Supervised Learining
- Task: Regresssion
- Model: 多种选择
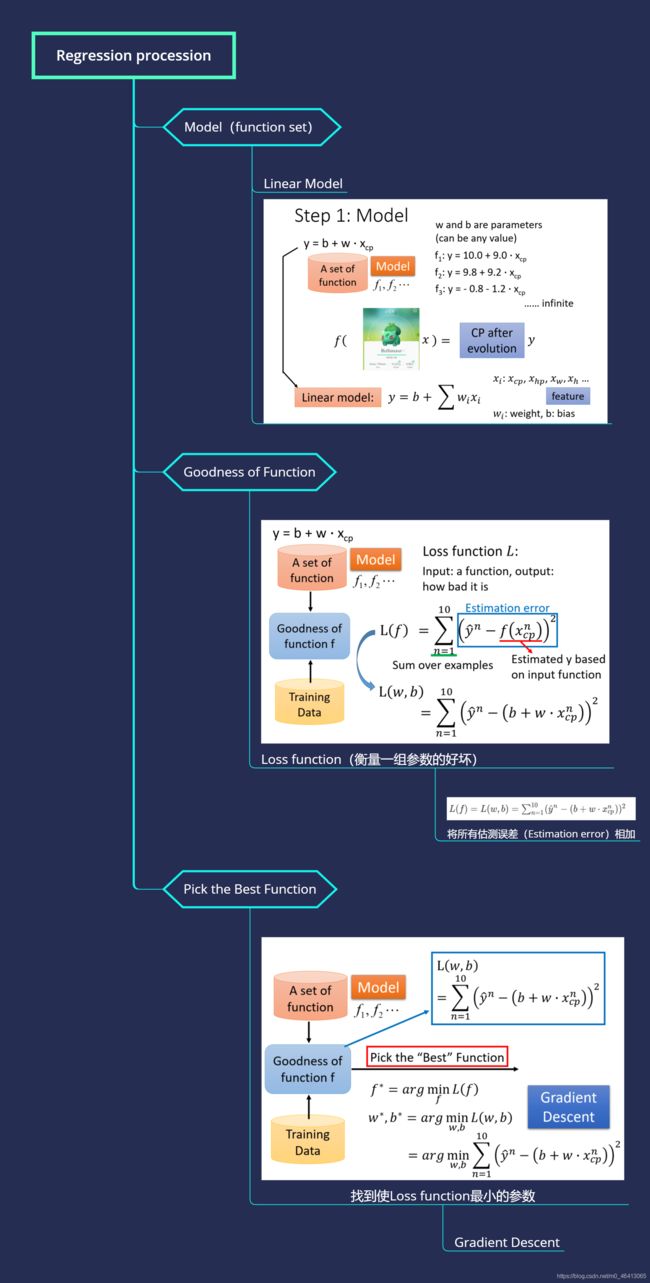
接下来用机器学习常见的三步来展现回归的过程:
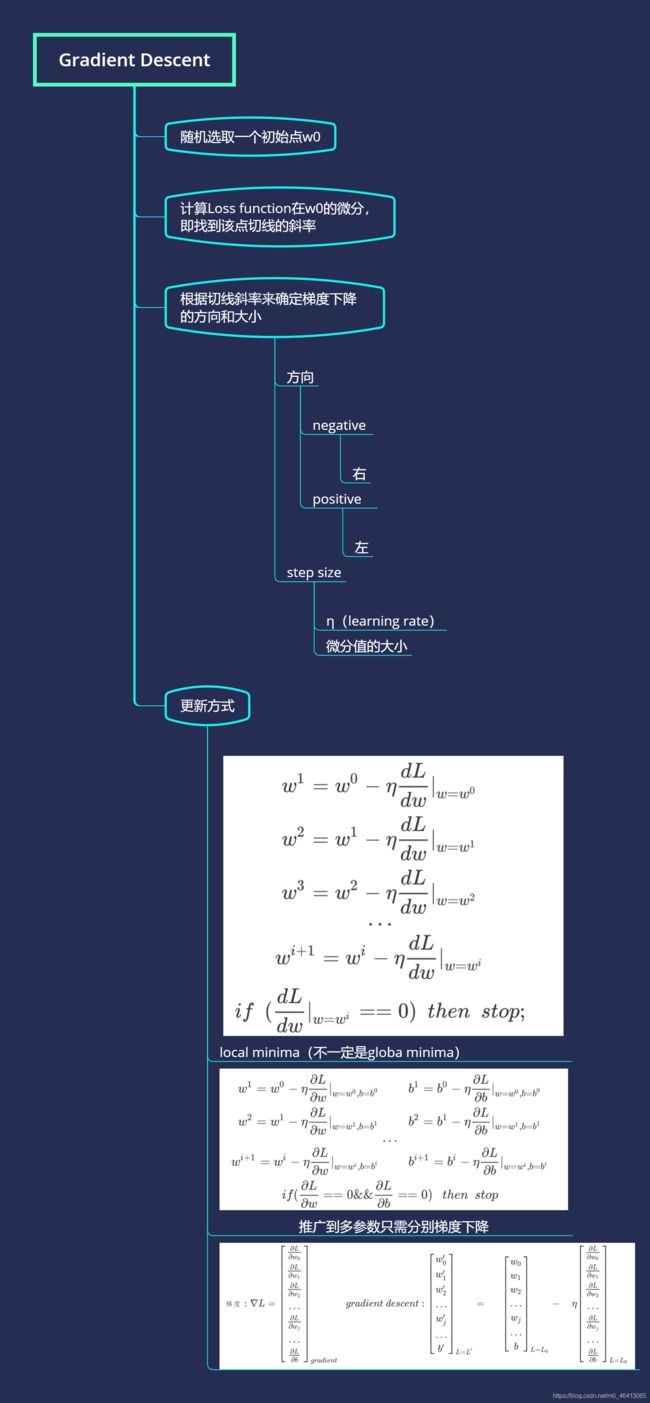
Gradient Descent
只要是可微分的,gradient descent都可以拿来寻找使Loss function最小的参数。
Gradient Descent的缺点
gradient descent有⼀个令⼈担⼼的地⽅,也就是我之前⼀直提到的,它每次迭代完毕,寻找到的梯度为0的点必然是极⼩值点,local minima;却不⼀定是最⼩值点,global minima
这会造成⼀个问题是说,如果loss function⻓得⽐较坑坑洼洼(极⼩值点⽐较多),⽽每次初始化 的取值⼜是随机的,这会造成每次gradient descent停下来的位置都可能是不同的极⼩值点;⽽且当遇到梯度⽐较平缓(gradient≈0)的时候,gradient descent也可能会效率低下甚⾄可能会stuck卡住;
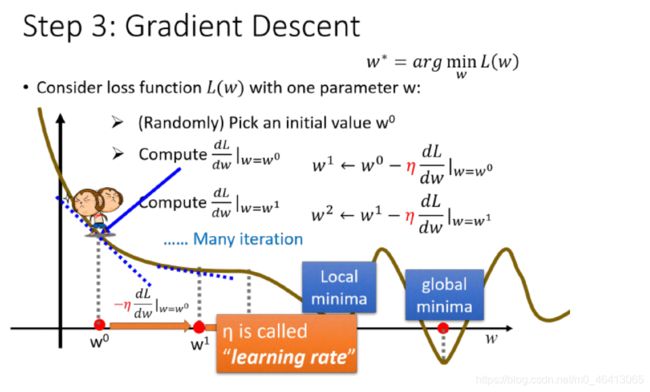
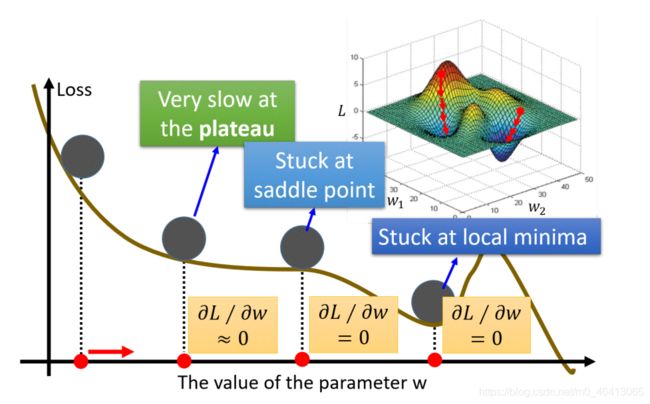
但是!在linear regression⾥,loss function实际上是convex的,是⼀个凸函数,是没有local optimal 局部最优解的,他只有⼀个global minima,visualize出来的图像就是从⾥到外⼀圈⼀圈包围起来的椭圆形的等⾼线(就像前⾯的等⾼线图),因此随便选⼀个起始点,根据gradient descent最终找出来的, 都会是同⼀组参数
关于η(learning rate)的讨论
learning rate的重要性:(引用李宏毅老师的例子)
gradient descent过程中,影响结果的⼀个很关键的因素就是learning rate的⼤⼩
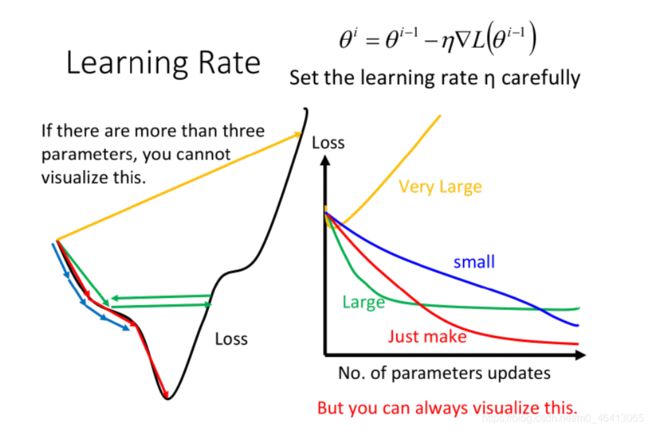
- 如果learning rate刚刚好,就可以像下图中红⾊线段⼀样顺利地到达到loss的最⼩值
- 如果learning rate太⼩的话,像下图中的蓝⾊线段,虽然最后能够⾛到local minimal的地⽅,但是它可能会⾛得⾮常慢,以⾄于你⽆法接受
- 如果learning rate太⼤,像下图中的绿⾊线段,它的步伐太⼤了,它永远没有办法⾛到特别低的地
⽅,可能永远在这个“⼭⾕”的⼝上振荡⽽⽆法⾛下去 - 如果learning rate⾮常⼤,就会像下图中的⻩⾊线段,⼀瞬间就⻜出去了,结果会造成update参数以后,loss反⽽会越来越⼤(这⼀点在上次的demo中有体会到,当lr过⼤的时候,每次更新loss 反⽽会变⼤)
Adaptive Learning rates
最基本、最简单的⼤原则是:learning rate通常是随着参数的update越来越⼩的
第一种常规想法:(t为updata的次数)
![]()
这种⽅法使所有参数以同样的⽅式同样的learning rate进⾏update,⽽最好的状况是每个参数都给他不同的learning rate去update
Adagrad

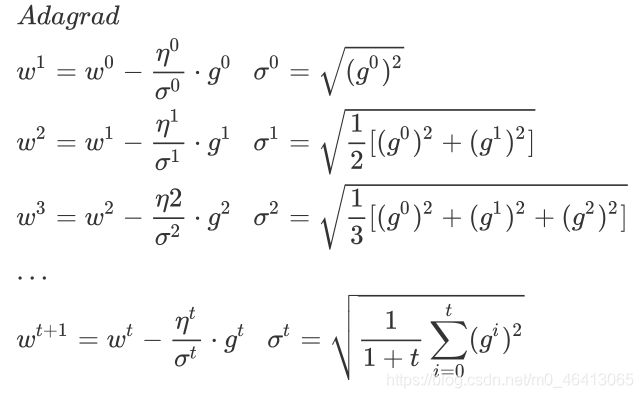
最终得到Adagrad表达式

p.s.解释表达式中一些矛盾的事情
我们在做gradient descent的时候,希望的是当梯度值即微分值越⼤的时候(此时斜率越⼤,还没有接近最低点)更新的步伐要更⼤⼀些,但Adagrad的表达式中,分⺟表⽰梯度越⼤步伐越⼤,分⼦却表⽰梯度越⼤步伐越⼩,两者似乎相互⽭盾
Adagrad要考虑的是,这个gradient有多surprise,即反差有多⼤,假设t=4的时候 与前⾯的gradient反差特别⼤,那么g^t与分母之间的⼤⼩反差就会⽐较⼤,它们的商就会把这⼀反差效果体现出来

gradient越⼤,离最低点越远这件事情在有多个参数的情况下是不⼀定成⽴的
如下图所⽰,w1和w2分别是loss function的两个参数,loss的值投影到该平⾯中以颜⾊深度表⽰⼤⼩,分别在w2和w1处垂直切⼀⼑(这样就只有另⼀个参数的gradient会变化),对应的情况为右边的两条 曲线,可以看出,⽐起a点,c点距离最低点更近,但是它的gradient却越⼤
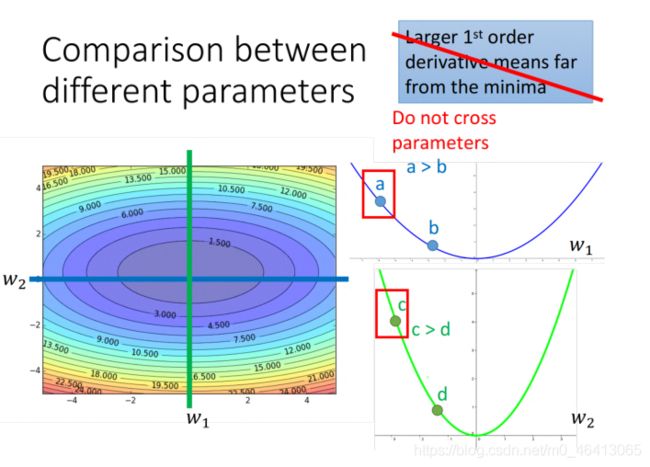
实际上,对于⼀个⼆次函数 来说,最⼩值点的x=-b/2a,⽽对于任意⼀点x0 ,它迈出最好的步伐⻓度是|x0+b/2a|=|2ax0+b/2a| (这样就⼀步迈到最⼩值点了),联系该函数的⼀阶导数y’=2ax+b和⼆阶导数y’’=2a ,可以发现最好的步伐⻓度是 |y’/y’’| ,也就是说他不仅跟⼀阶导数(gradient)有关,还跟⼆阶导数有关,因此我们可以通过这种⽅法重新⽐较上⾯的a和c点,就可以得到⽐较正确的答案。
在Adagrad表达式中,gt为一阶导,分母反应二阶导的大小,所以Adagrad想要做的事情就是,在不增加任何额外运算的前提下,想办法去估测⼆次微分的值
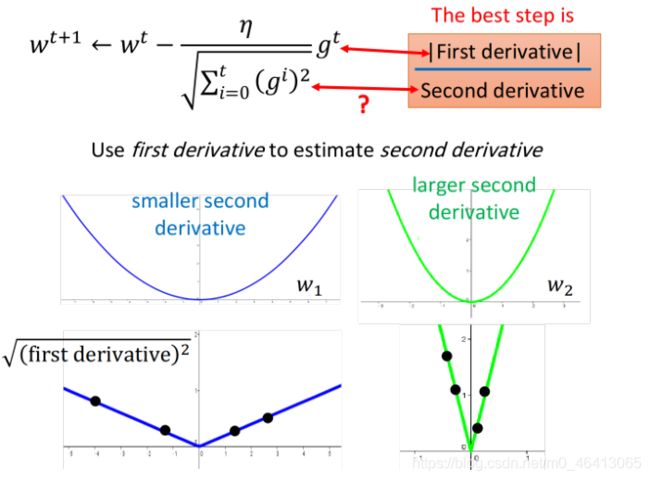
Stochastic Gradicent Descent
李老师还介绍了一种梯度下降的方法Stochastic Gradicent Descent:
随机梯度下降的⽅法可以让训练更快速,传统的gradient descent的思路是看完所有的样本点之后再构建loss function,然后去update参数;⽽stochastic gradient descent的做法是,看到⼀个样本点就update⼀次,因此它的loss function不是所有样本点的error平⽅和,⽽是这个随机样本点的error平⽅

stochastic gradient descent与传统gradient descent的效果对⽐如下:

后面李老师介绍了特征缩放在梯度下降的应用和梯度下降的数学原理,在这里就不多做赘述了。
然后我来重点总结下如何更好的回归拟合。
How can we do better?
我们有没有办法做得更好呢?这时就需要我们重新去设计model;如果仔细观察⼀下上图的data,就会发现在原先的cp值⽐较⼤和⽐较⼩的地⽅,预测值是相当不准的。
增加高次项
实际上,从结果来看,最终的function可能不是⼀条直线,可能是稍微更复杂⼀点的曲线,于是我们选择增加高次项来优化。
考虑2次的model
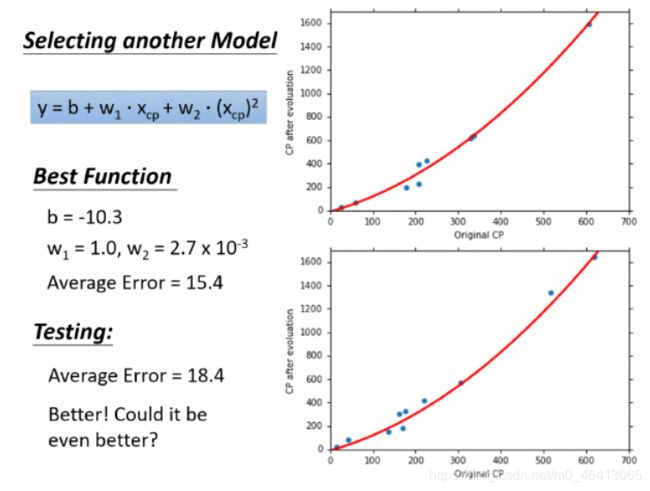
考虑3次的model

考虑4次的model
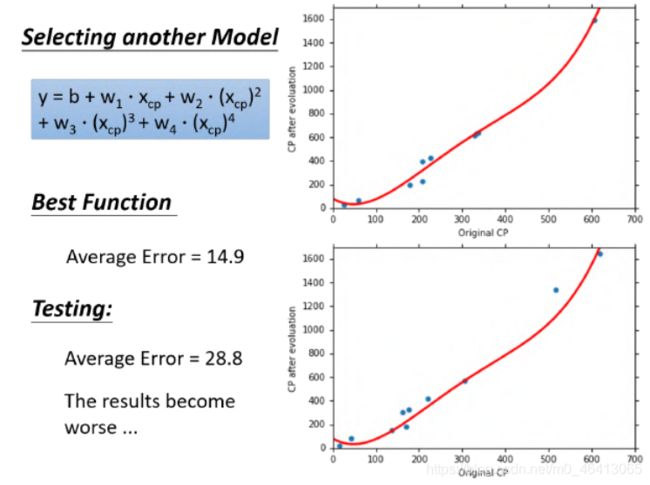
考虑5次的model
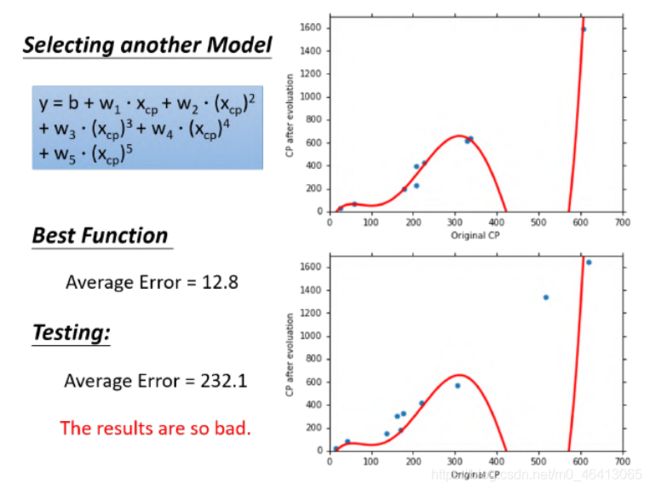
5个model的对⽐
这5个model的training data的表现:随着 的⾼次项的增加,对应的average error会不断地减⼩;实际上这件事情⾮常容易解释,实际上低次的式⼦是⾼次的式⼦的特殊情况(令⾼次项 对应的 为0,⾼次式就转化成低次式)也就是说,在gradient descent可以找到best function的前提下(多次式为Non-linear model,存在local optimal局部最优解,gradient descent不⼀定能找到global minima),function所包含的项的次数越⾼,越复杂,error在training data上的表现就会越来越⼩;但是,我们关⼼的不是model在training data上的error表现,⽽是model在testing data上的error表现在training data上,model越复杂,error就会越低;但是在testing data上,model复杂到⼀定程度之后,error⾮但不会减⼩,反⽽会暴增,在该例中,从含有 项的model开始往后的model, testing data上的error出现了⼤幅增⻓的现象,通常被称为overfitting过拟合

因此model不是越复杂越好,⽽是选择⼀个最适合的model,在本例中,3次的式⼦是最适合的model
上面提到增加高次项优化回归拟合,之后李老师又介绍了另一个优化的思路,增加新的input变量,即增加参数。
增加参数
这里李老师引入物种xs的影响

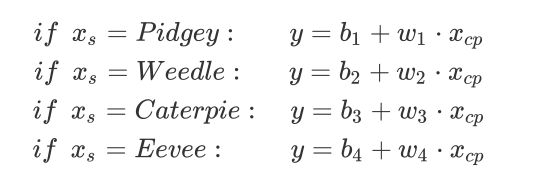
分别得到了改进后的在training data和testing data上测试的结果:
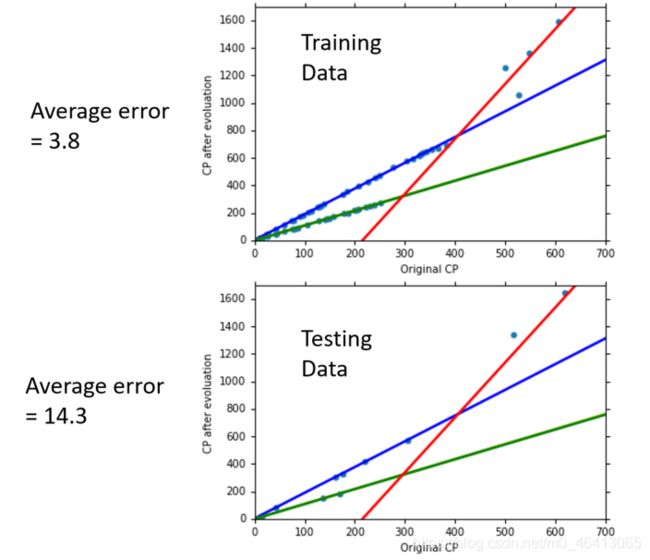
可以看出,结果比之前要稍微好一点。
那为什么不设计个超级无敌复杂的最终model呢?这样会不会更好呢?
考虑Hp值 、height值 、weight值的影响,设计出超复杂的model
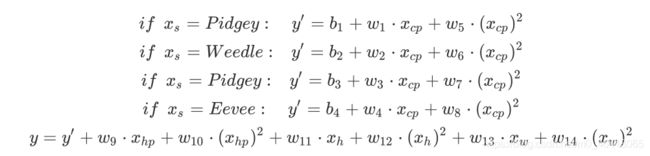
算出的training error=1.9,但是,testing error=102.3!这么复杂的model很⼤概率会发⽣overfitting(overfitting实际上是我们多使⽤了⼀些input的变量或是变量的⾼次项使曲线跟training data拟合的更好,但不幸的是这些项并不是实际情况下被使⽤的,于是这个model在testing data上会表现得很糟糕),overfitting就相当于是那个范围更⼤的⻙恩图,它包含了更多的函数更⼤的范围,代价就是在准确度上表现得更糟糕。
如果要更好的解释这个error,我们需要引入两种error。
Where does the error come from?
这里用思维导图说明:
怎么样?看了这个思维导图是不是一目了然呢?
也就是说我们的工作需要找到实际error最小的点,使bias和variance的大小达到平衡,得到表现最好的model。
在这里补充一下regularization和model selection
regulazation

regularization就是在原来的loss function的基础上加上了⼀项λ∑(wi) ,就是把这个model⾥⾯所有的wi的平⽅和⽤λ加权。其作用是我们期待wi越小甚至接近于0的function,即比较平滑的function。
如果我们有⼀个⽐较平滑的function,由于输出对输⼊是不敏感的,测试的时候,⼀些noises噪声对这个平滑的function的影响就会⽐较⼩,⽽给我们⼀个⽐较好的结果
我们喜欢⽐较平滑的function,因为它对noise不那么sensitive;但是我们⼜不喜欢太平滑的function,因为它就失去了对data拟合的能⼒;⽽function的平滑程度,就需要通过调整λ来决定。
就像下图中, 当λ=100时,在testing data上的error最⼩,因此我们选择λ=100。
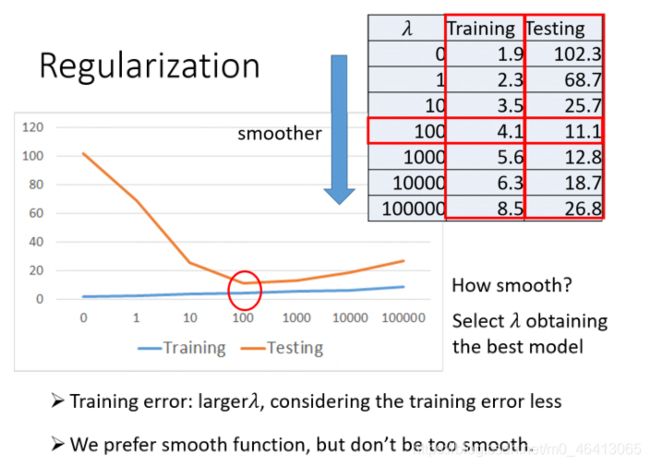
用刚刚bias和variance的几何意义来解释regularization的过程:

- 蓝⾊区域代表最初的情况,此时model⽐较复杂,function set的space范围⽐较⼤,包含了target
靶⼼,但由于data不够,⽐较分散,variance⽐较⼤。 - 红⾊区域代表进⾏regularization之后的情况,此时model的function set范围被缩⼩成只包含平滑的曲线,space减⼩,variance当然也跟着变⼩,但这个缩⼩后的space实际上并没有包含原先已经包含 的target靶⼼,因此该model的bias变⼤。
- 橙⾊区域代表增⼤regularization的weight的情况,增⼤weight实际上就是放⼤function set的space,慢慢调整⾄包含target靶⼼,此时该model的bias变⼩,⽽相较于⼀开始的case,由于限定了 曲线的平滑度(由weight控制平滑度的阈值),该model的variance也⽐较⼩。
实际上,通过regularization优化model的过程就是上述的1、2、3步骤,不断地调整regularization的weight,使model的bias和variance达到⼀个最佳平衡的状态(可以通过error来评价状态的好坏, weight需要慢慢调参)。
Model Selection
接下来我们来说model selection(这部分会有点绕,讲得不好还请多多包涵)

李老师指出了我们在选model时不应该做的事情:
即现在手头上有training set(训练集)和 testing set(测试集),我用训练集去训练3个不同的model得到三个 f1*,f2*,f3*,再用我手头上的测试集去测试这三个训练出来的function,找出Error最小的即认为他的model是最好的。
这样的理解是错误的!
原因在于我们⼿头上的testing set,只是是我们⾃⼰拿来衡量model好坏的testing set,而真正的testing set是我们还没有,他是未知的;而我们手头上的testing set有⾃⼰的⼀个bias(可以理解为⾃⼰的testing data跟实际的testing data会有⼀定的偏差存在)。
所以用我们手头上这个testing set来选择最好的model的时候,它在真正的testing set上不⻅得是最好的model,通常是⽐较差的,所以你实际得到的error是会⼤于你在⾃⼰的testing set上估测到的0.5。
那怎样做才是正确的呢?

把training set分成两组:
- training set(训练集) —— training model
- validation set(验证集) —— selecting model(not training model)
先用training set训练出三个model的function ,接下来看⼀下它们在validation set上的performance
假设现在model3的performance最好,那你可以直接把这个model3的结果拿来apply在testing data上,如果你担⼼现在把training set分成training和validation两部分,感觉training data变少的话,可以这样做:已经从validation决定model3是最好的model,那就定住model3不变(function的表达式不变),然后⽤全部的data在model3上⾯再训练⼀次(使⽤全部的data去更新model3表达式的参数)
这个时候,如果你把这个训练好的model的apply到public testing set上⾯,你可能会得到⼀个⼤于0.5的error,虽然这么做,你得到的error表⾯上看起来是⽐较⼤的,但是这个时候的error才能够真正反映你在private set上的error。
training data(训练集) -> ⾃⼰的testing data(测试集) -> 实际的testing data (该流程没有考虑⾃⼰的testing data的bias)
training set(部分训练集) -> validation set(部分验证集) -> ⾃⼰的testing data(测试集) -> 实际的testing data
(该流程使⽤⾃⼰的testing data和validation来模拟testing data的bias误差,可以真实地反映出在实际的data上出现的error)
N-flod Cross Validation
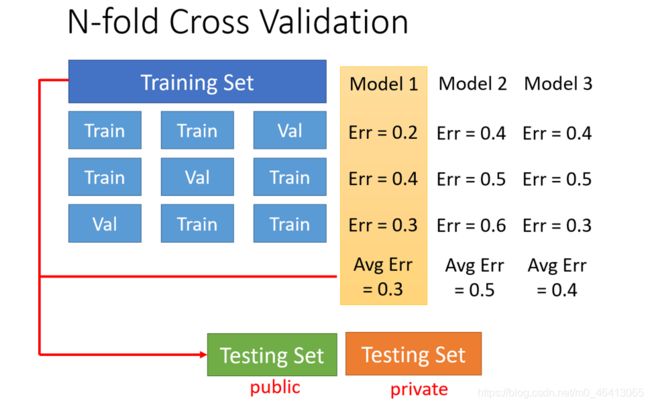
当然分training set有很多种不确定因素,为避免偶然性,可以分多次。
例如可以把training set分成三份,你每⼀次拿其中⼀份当做validation set,另外两份当training;分别在每个情境下都计算⼀下3个model的error,然后计算⼀下它的average error;然后你会发现在这三个情境下的average error,是model1最好。
然后接下来,你就把⽤整个完整的training data重新训练⼀遍model1的参数;然后再去testing data上test。
原则上是,如果你少去根据public testing set上的error调整model的话,那你在private testing set上⾯得到的error往往是⽐较接近public testing set上的error的。
总结来说就是选择model的时候呢,我们⼿头上的testing data与真实的testing data之间是存在偏差的,因此我们要将training data分成training set和validation set两部分,经过validation挑选出来的model再⽤全部的training data训练⼀遍参数,最后⽤testing data去测试error,这样得到的error是模拟过testing bias的error,与实际情况下的error会⽐较符合
好的,关于李老师机器学习中introduction和regression的部分到此讲完了,下篇讲classification。
我总结的顺序可能跟李老师上课时的不一样,我根据自己的理解融合了某些章节的内容并调整了顺序,同时,可能省略了一些推导,详情还是多看老师视频,看PPT回顾哟!