踩坑记录——记一次训练提交baseline全过程
目录
-
- 目的
- 背景
-
- 个人配置
- 赛题要求
- 本机跑通Baseline
-
- pytorch配置
- 准备环节
-
- 添加transformers和sklearn
- 数据文件及bert配置
- 模型训练过程
-
- 数据准备
- 训练
-
- 更改batch_size适配主机
- 生成结果
- 打包预测结果
- Docker提交
-
- Docker安装
- 本机Docker推送
-
- 走通的路
- 比赛提交
- 致谢
- 参考
目的
根据Datawhale大佬们提供的baseline训练模型,并通过docker的方式提交到天池比赛,获得自己的分数。对于新手来说,并没有看起来那么轻松,特此记录踩坑历程。感谢老师们的指点!
背景
个人配置
- 操作系统:windows10专业版(Tipis:家庭版装docker会有区别)
- 显卡:RTX3070
- 环境:pytorch1.7.1(GPU版)+ CUDA11.1 + Pycharm + windows版Docker
赛题要求
- 赛事信息:天池->全球人工智能技术创新大赛【热身赛二】
- Datawhale提供的baseline(特别感谢~):地址
Tips:之后将基于该baseline教程,详细叙述我的配置历程。
本机跑通Baseline
pytorch配置
- 关于windows版的Anaconda+Pytorch+Pycharm+Cuda配置可以看我之前总结的博客:地址
- 关于CuDNN的配置可以看我另一篇总结:地址
踩了许多坑的总结~
准备环节
git clone模型文件到本机,项目命名为tianchi-multi-task-nlp,运行环境为pytorch虚拟环境,编译器为Pycharm。
添加transformers和sklearn
pytorch虚拟环境中并没有这两项,我们需要使用pip安装一下。不过要注意一点,我们需要将这两个包安装到pytorch虚拟环境下,而不是直接在cmd中全局安装。
打开Anaconda->powershell prompt,我们通过powershell prompt进入pytorch虚拟环境。
conda activate <pytorch环境名称(自己命名)> #激活虚拟环境
pip install transformers #安装transformers
pip install sklearn #安装sklearn
安装结果如图:

数据文件及bert配置
下载中文预训练BERT模型bert-base-chinese,地址:https://huggingface.co/bert-base-chinese/tree/main

只需下载config.json、vocab.txt和pytorch_model.bin,把这三个文件放进tianchi-multi-task-nlp/bert_pretrain_model文件夹下。

下载比赛数据集,把三个数据集分别放进tianchi-multi-task-nlp/tianchi_datasets/数据集名字/下面:
- OCEMOTION/total.csv:http://tianchi-competition.oss-cn-hangzhou.aliyuncs.com/531841/OCEMOTION_train1128.csv
- OCEMOTION/test.csv: http://tianchi-competition.oss-cn-hangzhou.aliyuncs.com/531841/b/ocemotion_test_B.csv
- TNEWS/total.csv: http://tianchi-competition.oss-cn-hangzhou.aliyuncs.com/531841/TNEWS_train1128.csv
- TNEWS/test.csv: http://tianchi-competition.oss-cn-hangzhou.aliyuncs.com/531841/b/tnews_test_B.csv
- OCNLI/total.csv: http://tianchi-competition.oss-cn-hangzhou.aliyuncs.com/531841/OCNLI_train1128.csv
- OCNLI/test.csv: http://tianchi-competition.oss-cn-hangzhou.aliyuncs.com/531841/b/ocnli_test_B.csv
文件目录样例:
tianchi-multi-task-nlp/tianchi_datasets/OCNLI/total.csv
tianchi-multi-task-nlp/tianchi_datasets/OCNLI/test.csv
分别建立文件夹并重命名数据集即可~
模型训练过程
数据准备
分开训练集和验证集,默认验证集是各3000条数据,参数可以自己修改。
运行
generate_data.py文件
这里windows10系统可能会遇到一个问题:

可能是编码问题,解决方法就是在定位处添加:
,encoding='utf-8'
并且在所有.csv后缀(数据集文件)的后面都要添加该参数。

训练
更改batch_size适配主机
运行train.py文件来训练模型。初始设定:
train(epochs=20,batchSize=16, device='cuda:0', lr=0.0001, use_dtp=True, pretrained_model=pretrained_model, tokenizer_model=tokenizer_model, weighted_loss=True)
这里主要关注batchSize和epochs,因为bert很吃显存,所以我们要根据本机的配置对应调整模型参数。我的显卡是RTX3070 显存8G,结果遇到了问题:

经过查阅,我发现Stack Overflow上有一个问题比较有参考意义,结合目前情况,我选择只调小batchSize。
batchSize=8
结果一觉醒来,跑通模型~
此外,会保存验证集上平均f1分数最高的模型到./saved_best.pt。

生成结果
用训练好的模型./saved_best.pt生成结果:
运行
inference.py文件
打包预测结果
直接运行:
zip -r ./result.zip ./*.json
会遇到‘zip‘ 不是内部或外部命令,也不是可运行的程序 或批处理文件的报错。这是由于windows系统下并没有zip命令(Linux)。不过我们可以下载GnuWin32中exe文件,默认安装即可。注意,要记住安装路径,方便我们添加环境变量。

右键此电脑->属性->高级系统设置->环境变量,在系统变量中的Path添加GnuWin32\bin路径。
![]()
重启电脑,即可使用zip命令。

到此,在本机训练baseline的过程完毕。
Docker提交
再次强调,win10专业版和家庭版在安装Docker过程中区别很大,我的主机为win10专业版。此外,docker的命令行操作均在windows powershell运行,必要时以管理员身份运行。
Docker安装
直接去官网安装windows桌面版即可。在第一次运行Docker时,Hyper-V始终加载失败,我发现是由于我新配的主机未开虚拟化(到任务管理器的性能页面即可查询)由于本机是华硕主板,我需要在开机时按F2进入BIOS界面打开虚拟化。再次进入Docker之后,没有再遇到该问题。
第一次运行Docker,在测试hello-world镜像时候,windows powershell报错unable to find image。意思是Docker在本地没有找到hello-world镜像,也没有从docker仓库中拉取镜像。由于Docker服务器在国外(需要),因此我们在国内无法正常拉取镜像,所以需要我们为Docker设置国内阿里云的镜像加速器。
{
"registry-mirrors": ["https://alzgoonw.mirror.aliyuncs.com"]
}

重启后即可正常拉取hello-world镜像。
本机Docker推送
给出我使用的参考教程,仔细研读,会有收获。我也会给出我自己走通的路~
- 基本盘:Docker推送到阿里云教程
- 云端镜像仓库中的操作指南
- 比赛的容器镜像提交说明
注:涉及到一些个人仓库id的截图暂时不便放出,请谅解。可参考 基本盘:Docker推送到阿里云教程内的运行结果图。
走通的路
进入云端镜像仓库创建自己的镜像仓库和命名空间,进入自己创建的仓库,找到操作指南,里面有你想要的~
现在开始准备提交的文件夹(submission):

这里注意要把打包好的result.zip放到submission内,不然你可能会浪费一次比赛提交机会。这是由于比赛要求:

之后在windows powershell中进入(cd)到submission文件夹内,进行如下操作:\
- 登录
docker login --username=用户名 registry.cn-shenzhen.aliyuncs.com
注意:用户名在自创仓库的详情页下方的操作指南里有说明。
- 构建镜像
docker build -t registry.cn-shenzhen.aliyuncs.com/test_for_tianchi/test_for_tianchi_submit:1.0 .
注意:registry.~~~用自己仓库地址替换(到自创仓库的详情页查询)。地址后面的1.0为自己指定的版本号,用于区分每次build的镜像。最后的.是构建镜像的路径,不可以省掉。
- 推送镜像到仓库
docker tag [ImageId] registry.cn-shenzhen.aliyuncs.com/test_for_tianchi/test_for_tianchi_submit:1.0
docker push registry.cn-shenzhen.aliyuncs.com/test_for_tianchi/test_for_tianchi_submit:1.0
注意:ImageId在Docker桌面->左侧Images栏->镜像名列表-> 中;registry.~~~用自己仓库地址替换(到自创仓库的详情页查询),与上面的操作一致。
至此,Docker推送完成,接下来可以提交了。
比赛提交
提交界面如图:
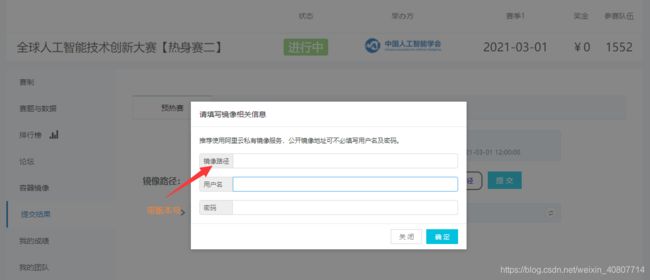
刚才我提到要将要把打包好的result.zip放到submission内,即与run.sh同目录。第一次提交我并没有这样做,于是提交之后无结果。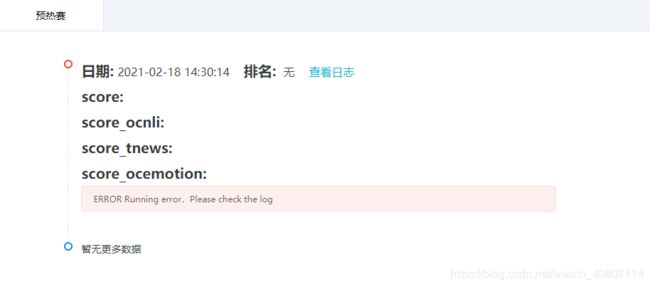
查看日志之后发现无法打开result文件:

这样浪费了两次机会。
此时,我发现赛题要求将result.zip与run.sh放于同一目录,尽管今天只剩下最后一次机会,我仍然选择相信自己的判断,于是重新构建了2.0版本,再次推送到镜像仓库。结果提交成功,有了baseline成绩,赶紧截图保存~
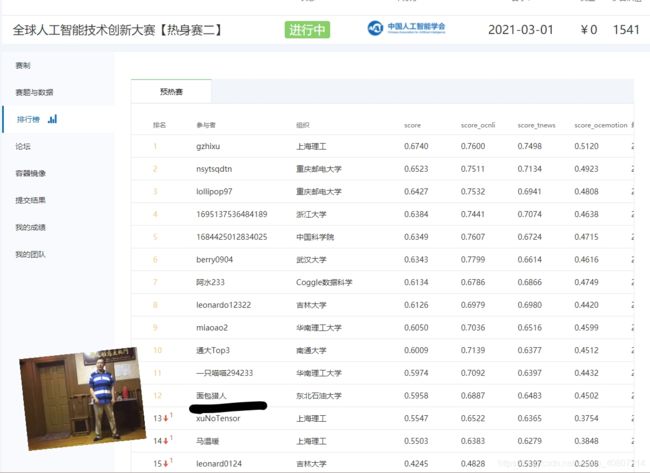
当然,优化之路才刚刚开始!
致谢
万分感谢Datawhale提供这次机会!
参考
- baseline
- 全球人工智能技术创新大赛【热身赛二】
- UnicodeDecodeError解决方案
- windows zip命令
- docker测试问题
- 基本盘:Docker推送到阿里云教程
- 云端镜像仓库中的操作指南
- 比赛的容器镜像提交说明
- windows版的Anaconda+Pytorch+Pycharm+Cuda配置
- CuDNN的配置