涨点神器!SoftPool:一种新的池化方法,带你起飞!
点击上方“CVer”,选择加"星标"置顶
重磅干货,第一时间送达
本文转载自:AI人工智能初学者

论文:https://arxiv.org/abs/2101.00440
项目代码链接:
https://github.com/alexandrosstergiou/SoftPool
本文提出了一种快速、高效的池化方法SoftPool,Softpool可以以指数加权方式累加激活。与一系列其他池化方法相比,SoftPool在下采样激活映射中保留了更多的信息,可以获得更好的分类精度。在ImageNet上,对于一系列流行的CNN架构,用SoftPool替换原来的池化操作可以带来1-2%的一致性精度提升。
作者单位:乌得勒支大学 华威大学
1 简介
通常卷积神经网络(CNNs)都会使用池化pool操作来减少Feature Map的尺寸。这个过程对于实现局部空间不变和增加后续卷积的感受野是至关重要的。因此池化pool操作应该尽量减少Feature Map映射中信息的丢失。同时,应该限制计算和内存开销。
为了满足这些需求,本文提出了一种快速、高效的池化方法SoftPool,softpool可以以指数加权方式累加激活。与一系列其他池化方法相比,SoftPool在下采样激活映射中保留了更多的信息。更精细的下采样导致更好的分类精度。在ImageNet上,对于一系列流行的CNN架构,用SoftPool替换原来的池化操作可以带来1-2%的一致性精度提升。SoftPool在视频数据集上的动作识别。同样,在计算负载和内存仍然有限的情况下,仅替换池化层依然可以提高精度。
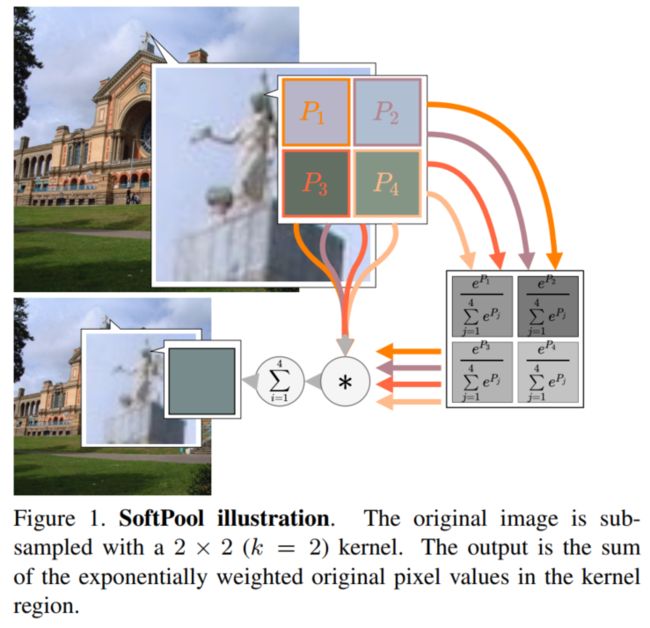
2 前人工作
2.1 Hand-crafted Pooling特征
下采样已被广泛应用于手工编码的特征提取方法之中,如Bag-of-Words和Bag-of-Features,在这些方法中图像被视为局部斑块的集合,通过pooling和encode为向量。该方法还与空间金字塔匹配相结合进行了研究,以保持空间信息。
后来的工作考虑了空间区域中最大SIFT特征的选择。脑池化主要与max-pooling的使用有关,因为生物学上类似max的皮层信号具有鲁棒性。Boureau等人研究了最大池化(Max Pooling)和平均池化(Avg Pooling)。Max-pooling已经被有效地应用并由不错的效果和性能。
2.2 Pooling in CNNs
传统上,池化的主要好处是创建了比原始版本小得多的表征,从而减少了计算需求,并支持创建更大、更深层次的网络架构。
下采样的池化方法
Average Pooling:区域平均值。
Max Pooling:区域最大值。
Stochastic Pooling:它使用一个核区域内激活的概率加权抽样。
Mix Pooling:基于最大池化和平均池化的混合池化。
Power average Pooling:基于平均和最大化的结合,幂平均(Lp)池化利用一个学习参数p来确定这两种方法的相对重要性;当p=1时,使用局部求和,而p为无穷大时,对应max-pooling。

网格采样的池化方法
S3 Pooling:对原始Feature Map网格中的行和列进行随机采样。
Preserving Pooling:使用平均池化,同时用高于平均值的值增强激活。
Local Importance Pooling:进一步评估了如何将学习到的权值作为一种基于子网络注意的机制来使用,该机制可用于汇集信息特征,同时丢弃无信息特征。

与前面描述的操作相比,一些池化方法有严格的架构或基于任务的标准,这些标准将它们的应用限制在特定的CNN架构和任务上:
Spatial Pyramid Pooling
ROI-Pool
ROI-align
上述大多数方法都是依赖于最大池化和平均池化的不同组合。而SoftPool的工作不是结合现有的方法,而是基于softmax加权方法来保留输入的基本属性,同时放大更大强度的特征激活。与max-pooling不同softpool是可微的。
因此,在反向传播过程中为每个输入获得一个梯度,这可能会提高训练效果。我们在上图中演示了SoftPool的效果。
其他以前的方法使用可训练的参数导致计算成本增加,直接影响较大网络的可用性。相比之下,SoftPool可以替代任何池化操作,包括最大池化和平均池化,而且计算和内存效率都很高。
3 SoftPool方法
从这里开始正式介绍SoftPool中信息的正向传播和反向传播。考虑activation map(a)中的 local region (R),其维数为C×H×W,通道数为C,通道高度为H,通道宽度为W。为了简化符号这里省略通道维数,并假设R是与考虑的二维空间区域的激活相对应的索引集。对于大小为k×k的池化kernel定义 。池化操作的输出为 ,对应的梯度用 表示。
3.1 Exponential maximum kernels
SoftPool受到Riesenhuber和Poggio的皮层神经模拟以及早期使用Boureau等人的手工编码特征的池化实验的影响。该方法以自然指数(e)为基础,保证了较大的激活值对输出的影响较大。
SoftPool是可微的,这意味着所有在局部邻域内的激活在反向传播期间将被分配至少一个最小梯度值。这与使用最大池化的方法相反。SoftPool利用激活区域内的最大近似R。每一个指数为 的激活 应用一个权重 ,该权重 计算为该激活的自然指数与邻域R内所有激活的自然指数之和的比值:

权重与相应的激活值一起用作非线性变换。较高的激活比较低的激活占更多的主导地位。因为大多数池化操作都是在高维的特征空间中执行的,突出显示具有更大效果的激活比简单地选择最大值是一种更平衡的方法。
在后一种情况下,丢弃大部分激活会带来丢失重要信息的风险。相反,平均池化中激活的贡献相等,可以显著降低整体区域特征强度。
SoftPool操作的输出值是通过对内核邻域R内所有加权激活的标准求和得到的:
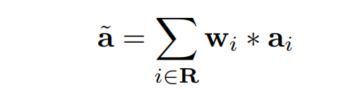
与其他基于最大池化和平均池化的方法相比,使用区域的softmax产生归一化结果,其概率分布与每个激活值相对于核区域的邻近激活值成比例。这与最大激活值选择或对内核区域的所有激活取平均形成了直接对比,而内核区域的输出激活是没有规则化的。因此是可微的。
Pytorch实现soft_pool2d如下:
def soft_pool2d(x, kernel_size=2, stride=None, force_inplace=False):
if x.is_cuda and not force_inplace:
return CUDA_SOFTPOOL2d.apply(x, kernel_size, stride)
kernel_size = _pair(kernel_size)
if stride is None:
stride = kernel_size
else:
stride = _pair(stride)
# Get input sizes
_, c, h, w = x.size()
# Create per-element exponential value sum : Tensor [b x 1 x h x w]
e_x = torch.sum(torch.exp(x),dim=1,keepdim=True)
# Apply mask to input and pool and calculate the exponential sum
# Tensor: [b x c x h x w] -> [b x c x h' x w']
return F.avg_pool2d(x.mul(e_x), kernel_size, stride=stride).mul_(sum(kernel_size)).div_(F.avg_pool2d(e_x, kernel_size, stride=stride).mul_(sum(kernel_size)))
3.2 Gradient calculation
完整的向前和向后信息流下图所示:
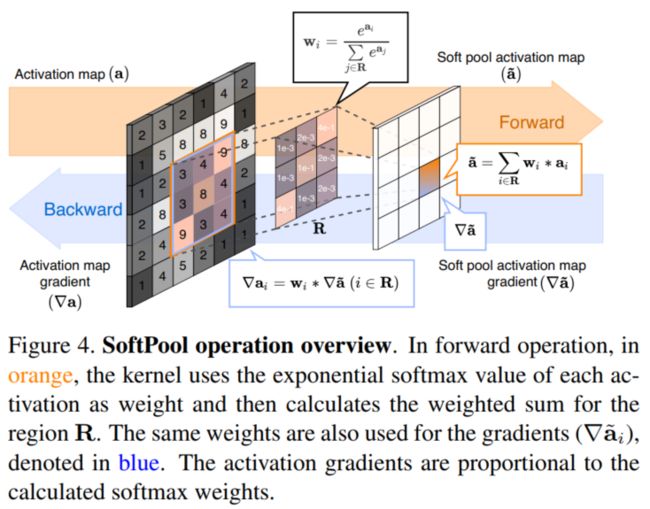
在训练的更新阶段,所有网络参数的梯度都是根据在上一层计算的误差导数进行更新的。当在整个网络体系结构中反向传播时,这会创建一个更新链。在SoftPool中,梯度更新与前向传播过程中计算的权重成比例。这对应于较小激活的梯度更新小于实质性激活的梯度更新。
Softmax与max或随机池化不同,Softmax是可微的。因此,在反向传播期间,一个最小的非零权值将被分配给一个核区域内的每一个激活。这样就可以计算出该区域每一次激活的梯度。
在SoftPool实现中使用了给定精度级别有限范围的可能值,保留了softmax的可微性质,通过给定每个类型使用的比特数分配一个较低的算术限制。这可以防止算术下溢。也为内核值和最终求和中使用的生成的激活值实现了这种机制。
3.3 Feature preservation
Sub-Sampling的一个整体目标是在保持输入的代表性特征的同时最小化整体分辨率。创建原始输入的无代表性的下采样可能对整个模型的性能有负面影响,因此输入的表示可能对任务也会有负面影响。
目前广泛使用的池化技术在某些情况下可能是无效的。Avg Pooling降低了该区域内所有激活的效果,而Max Pooling仅选择该区域内单个激活最高的激活。
SoftPool的作用介于这两种池化方法之间,因为该区域的所有激活都对最终输出有贡献,而较高的激活比较低的激活占主导地位。该方法可以平衡Avg Pooling和Max Pooling的影响,同时利用两者的有利属性。
下图显示了SoftPool可以保留的详细级别的示例,即使在图像被大量抽样的情况下颜色与原始图像保持一致。

3.4 Spatio-temporal kernels
CNN也被扩展到使用3D输入来表示额外的维度,如深度和时间。为了适应这些输入,可以通过在内核中包含一个额外的维度对SoftPool进行扩展;对于一个具有 维度的输入激活映射 ,以T为时间范围,将二维空间核区域R转换为三维时空区域,其中三维空间在时间维度上运行。
产生的输出现在包含压缩的时空信息。通过增加维度,所需的池化属性(如有限的信息丢失、可微函数以及较低的计算和内存开销)变得更加重要。Pytorch实现soft_pool3d如下:
def soft_pool3d(x, kernel_size=2, stride=None, force_inplace=False):
if x.is_cuda and not force_inplace:
return CUDA_SOFTPOOL3d.apply(x, kernel_size, stride)
kernel_size = _triple(kernel_size)
if stride is None:
stride = kernel_size
else:
stride = _triple(stride)
# Get input sizes
_, c, d, h, w = x.size()
# Create per-element exponential value sum : Tensor [b x 1 x d x h x w]
e_x = torch.sum(torch.exp(x),dim=1,keepdim=True)
# Apply mask to input and pool and calculate the exponential sum
# Tensor: [b x c x d x h x w] -> [b x c x d' x h' x w']
return F.avg_pool3d(x.mul(e_x), kernel_size, stride=stride).mul_(sum(kernel_size)).div_(F.avg_pool3d(e_x, kernel_size, stride=stride).mul_(sum(kernel_size)))
4 实验结果
4.1 ImageNet-1K分类
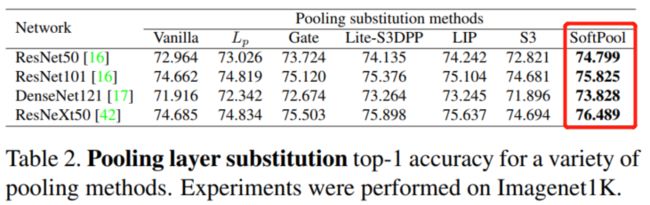
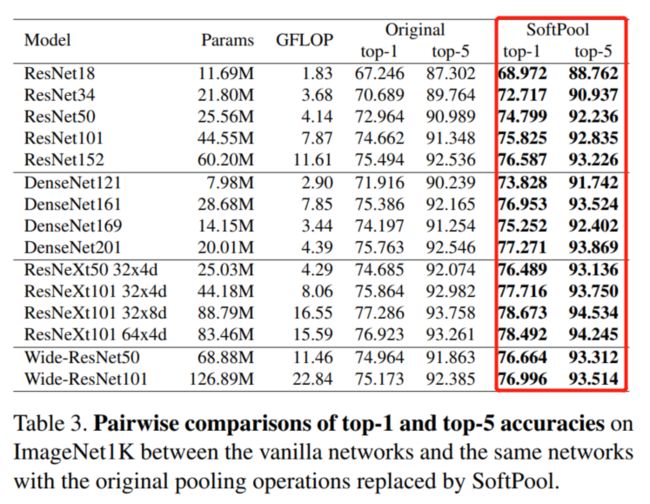
通过上表可以看出,直接在Backbone的基础上把池化方法替换为SotfPool,效果有明显的提升。
4.2 视频分类实验
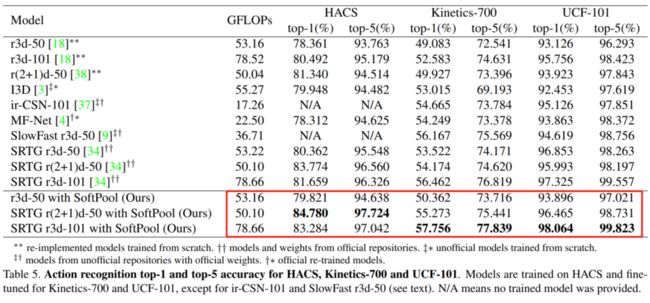
可以看出即使是3D CNN Model中SoftPool依然有效。
5 参考
[1].Refining activation downsampling with SoftPool
[2].https://github.com/alexandrosstergiou/SoftPool
SoftPool下载
后台回复:SoftPool,即可下载上述论文PDF和源代码
CV资源下载
后台回复:CVPR2020,即可下载代码开源的论文合集
后台回复:ECCV2020,即可下载代码开源的论文合集
后台回复:YOLO,即可下载YOLOv4论文和代码
后台回复:Trasnformer综述,即可下载两个最新的视觉Transformer综述PDF,肝起来!
重磅!CVer-细分垂直交流群成立
扫码添加CVer助手,可申请加入CVer-细分垂直方向 微信交流群,也可申请加入CVer大群,细分方向已涵盖:目标检测、图像分割、目标跟踪、人脸检测&识别、OCR、姿态估计、超分辨率、SLAM、医疗影像、Re-ID、GAN、NAS、深度估计、自动驾驶、强化学习、车道线检测、模型剪枝&压缩、去噪、去雾、去雨、风格迁移、遥感图像、行为识别、视频理解、图像融合、图像检索、论文投稿&交流、Transformer、PyTorch和TensorFlow等群。
一定要备注:研究方向+地点+学校/公司+昵称(如目标检测+上海+上交+卡卡),根据格式备注,才能通过且邀请进群

▲长按加微信群

▲长按关注CVer公众号
整理不易,请给CVer点赞和在看!