分享几道LeetCode中的MySQL题目解法
导读
最近刷完了LeetCode中的所有数据库题目,深深感到有些题目还是非常有深度和代表性的,而且比较贴合实际应用场景,特此发文以作分享。


文章来源:小数志
作者:luanhz
注:本文一共5道题目,难度由易到难。如果能很快写出查询SQL语句,说明你的SQL水平已经很高了!
550. 游戏玩法分析IV
首先来一道中等难度的题目作为开胃菜,但算得上是比较典型的题目。
题目描述:

预期结果:

这是一道典型的次日留存用户分析题,题目难度级别是中等,在该问题之前还有玩法分析的I、II和III题,但相对简单。
解决此问题的关键在于:
查询出每个用户的首次登录日期
在首次登录日期的基础上,查询用户次日登录情况
查询首次登录日期相对简单,仅需按用户分组、查询其最早的日期即为首次登录日期;而直接查询次日登录情况则并不容易:因为要首先知道首次登录日期,然后根据该日期+1查找每个用户是否登录。如果我们试图直接尝试这样的思路,那么毫无疑问会将题目变得复杂,而简单直观的办法是用关联查询。
具体如下:
查询各用户首次登录日期:
1SELECT player_id, min( event_date ) AS login
2FROM activity
3GROUP BY player_id
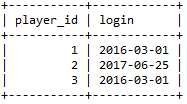
用户首次登录日期查询结果
用首次登录日期与原表左连接,连接条件为用户相同、且日期相差1天。因为可能存在用户不满足连续两天登录的情况,所以这里需要用左连接。
1SELECT
2 round( avg( a.event_date IS NOT NULL ), 2 ) fraction
3FROM
4 ( SELECT player_id, min( event_date ) AS login FROM activity GROUP BY player_id ) p
5 LEFT JOIN activity a
6 ON p.player_id = a.player_id AND datediff( a.event_date, p.login ) =1
这里在两表关联的基础上,统计用户次日登录比例时用到了一个小技巧,即直接用avg()聚合函数查询用户次日是否登录的bool结果均值(等价于True=1和False=0的均值),可避免两次count再相除的繁琐。
1097. 游戏玩法分析V
接下来这道题目是游戏玩法分析系列的第五题,难度是困难级别。但实际上分析思路与前一题类似。
题目表述:

预期结果:

应该讲,两道题目非常相似,均为统计次日用户登录情况,只是前一题中定义首日为登录,这一题定义首日为安装,但仍然是统计次日留存比例,而且是按日统计的留存比例。
毫无疑问,思路仍然是先查找用户的首日信息,进而通过左连接查询次日登录情况,再根据日期分组聚合统计即可。
直接给出最终的SQL查询语句:
1SELECT
2 t1.install_dt,
3 count( t1.player_id ) installs,
4 round( avg( t2.player_id IS NOT NULL ), 2 ) Day1_retention
5FROM
6 ( SELECT player_id, min( event_date ) AS install_dt FROM activity GROUP BY player_id ) t1
7 LEFT JOIN activity t2
8 ON t1.player_id = t2.player_id AND datediff( t2.event_date, t1.install_dt ) = 1
9GROUP BY
10 t1.install_dt
1205. 每月交易II
这虽然标签是一道难度中等的题目,但个人在最初看到题目时感到非常棘手,看过题解后不禁感叹其中技巧之强大。
题目描述:
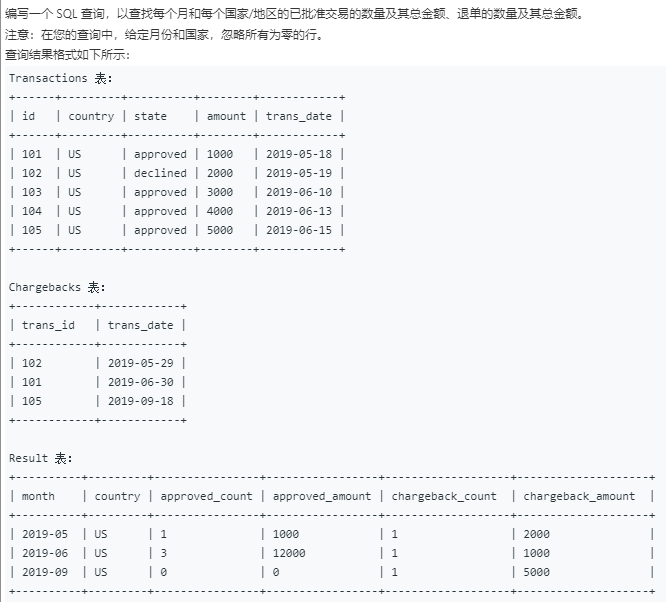
图大字小,点击查看细节
题目的难点在于交易的成交日期和退单日期是不同的,而统计时要区分日期统计。这就意味着查询对象应该是两表的"full join"结果,而这在MySQL中并不支持。所以,需要考虑用union汇总两表的中间结果。为了在汇总过程中不至于使两类交易混淆,还要增加一个列信息,即该交易是成交还是退单。
首先,通过union汇总所有交易:
1SELECT DATE_FORMAT( c.trans_date, '%Y-%m' ) MONTH, country, amount, 'chargeback' type
2FROM transactions t JOIN chargebacks c ON t.id = c.trans_id
3UNION ALL
4SELECT DATE_FORMAT( trans_date, '%Y-%m' ) MONTH, country, amount, 'approved' type
5FROM transactions WHERE state = 'approved'
其中union的前者是通过两表关联查询退单的交易信息,并增加交易类型字段type值均为退单;后者是简单的查询成交的交易信息。查询结果如下:
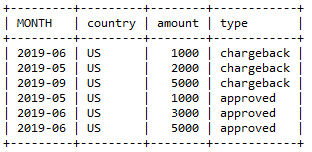
在此基础上,为了得到目标查询结果就相对简单得多,实际上是一个列转行的问题,常见的就是万年不变学生成绩表中列转行的例子,具体可自行查询了解。
1SELECT MONTH, country,
2 sum( type = 'approved' ) approved_count,
3 sum( ( type = 'approved' ) * amount ) approved_amount,
4 sum( type = 'chargeback' ) chargeback_count,
5 sum( ( type = 'chargeback' ) * amount ) chargeback_amount
6FROM
7 ( SELECT DATE_FORMAT( c.trans_date, '%Y-%m' ) MONTH, country, amount, 'chargeback' type
8 FROM transactions t JOIN chargebacks c ON t.id = c.trans_id
9 UNION ALL
10 SELECT DATE_FORMAT( trans_date, '%Y-%m' ) MONTH, country, amount, 'approved' type
11 FROM transactions WHERE state = 'approved'
12 ) tmp
13GROUP BY MONTH, country
1127. 用户购买平台
这又是一道困难级别的题目,也是属于统计业务信息类题目。
表信息描述:

问题描述:
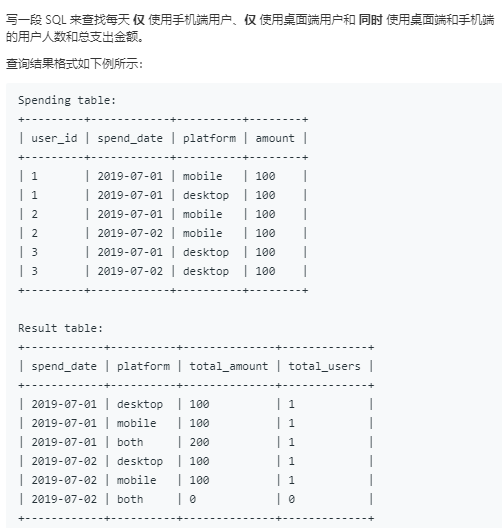
该题目看起来似乎是不难的,因为表中用户id、消费日期和平台是联合主键,所以每个用户在每个日期中最多有两条交易记录,此时对应查询目标结果中的both,否则就是单一的平台。但有很多细节需要考虑。
首先,直觉是要进行分组统计,目标是得到每个用户、每个消费日期的交易记录数目及平台,其中交易记录数目=2时,平台为both;否则平台为相应的desktop或mobile。得到这一查询结果并不难,仅需按用户和消费日期分组聚合并判断记录条目选择平台字段即可:
1SELECT user_id, spend_date,
2 IF(count( platform ) > 1, 'both', platform ) platform,
3 sum( amount ) total
4FROM spending
5GROUP BY user_id, spend_date
得到查询结果:

在此基础上,由于最终目标是要查询每个交易日的用户数和交易总额,所以意味着对该结果进一步按消费日期进行分组聚合。但实际上,如果简单的这样分组统计必然会存在有些交易日不是所有平台都有结果。而题目要求的是每个交易日的三种平台结果都要求显示,即使结果是0!
为此,我们还需先给查询结果“搭个框架”,即筛选出所有交易日期和3种交易平台的框架,然后再根据前面查询的结果进行填充。为了搭这个框架,日期可以从原表中提取不重复日期信息,而平台则可通过临时表的方式"手动构建"。虽然对于这一需求个人并未想到什么好的方法,但还是提供一个样例SQL语句:
1SELECT DISTINCT spend_date, tt.platform
2FROM spending, ( SELECT 'desktop' AS platform UNION SELECT 'mobile' UNION SELECT 'both' ) tt
得到的结果即为查询目标中的“框架”:
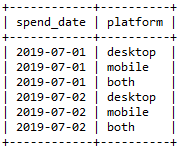
进而,将两部分结果进行左连接,并对数据加以判断填充即可。完整SQL语句:
1SELECT t1.spend_date, t1.platform,
2 ifnull( sum( total ), 0 ) total_amount,
3 count( user_id ) total_users
4FROM
5 ( SELECT DISTINCT spend_date, tt.platform
6 FROM spending, ( SELECT 'desktop' AS platform UNION SELECT 'mobile' UNION SELECT 'both' ) tt ) t1
7 LEFT JOIN
8 ( SELECT user_id, spend_date,
9 IF(count( platform ) > 1, 'both', platform ) platform,
10 sum( amount ) total
11 FROM spending
12 GROUP BY user_id, spend_date
13 ) t2 using(spend_date)
14 AND t1.platform = t2.platform
15GROUP BY t1.spend_date, t1.platform
1336. 每次访问交易次数
个人认为,本题是当前LeetCode平台中数据库题目最难的一道,而且由于测试样例考虑了各种极端情况,所以进一步增加了处理的棘手程度。
题目描述:

预期结果:
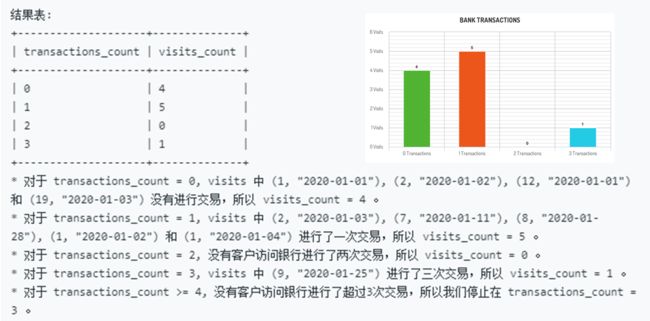
当然,条形图不是SQL查询结果
可能这道题理解起来并不难,但难在处理很多细节。主体是统计用户的交易行为:即统计有多少次来访中完成了0次、1次、2次交易等等,也就意味着最终肯定是按照每次来访的交易次数进行分组聚合。自然想法是要统计数据库中用户在每次来访中各进行交易的次数,考虑到存在用户是来了之后但未进行实质交易的,还要将来访表和交易表进行左连接查询:
1select v.user_id, v.visit_date, count(t.amount) cnt
2from visits v left join transactions t on v.user_id=t.user_id and v.visit_date=t.transaction_date
3group by v.user_id, v.visit_date
得到查询结果:
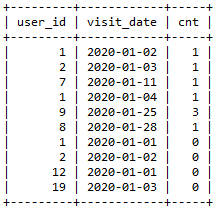
有了这个结果,其实已经很接近最终目标了:表中有4个0次、5个1次和1个3次,这些都刚好是目标查询结果中的信息。唯独欠缺的就是0个2次,因为查询目标是要将次数连续显示。
如果看过前一题的分析思路的话,那么可能会想到本题其实也需要这样的一个"结果框架":即先把目标查询结果中的交易次数列出来。但又与上一题不同的是,上一题中的框架信息(即交易日期和交易平台)可以从已知表得到,但本题的框架信息(交易次数)却需要在先知道交易信息数据的基础上才知道最大的交易次数是多少。
换个思路:实际上这个框架只需要一列信息,即交易次数,更准确的说是最大交易次数。
首先我们先解决交易次数的问题。需要得到的交易次数是一串连续的数字信息,这个在其他编程语言中非常容易的问题在SQL中却并不简单,如果把它想成是表的编号的话,那么或许可以借助自定义变量的方法实现。但自定义变量又需要"依附"一个表才得以更新编号。为了更新得到可能的最大编号,我们选择交易表(transactions)作为这个"依附"表,确保即使是transactions表中的所有记录均由单用户的单次来访产生时,也能生成这个最大的交易次数。自定义变量生成编号的方法可参考一文解决所有MySQL分类排名问题一文。
查询SQL语句:
1SELECT @id:=@id+1 as cnt
2from transactions, (select @id:=-1)i
SQL语句中自定义变量@id初值为-1,确保生成的cnt信息是从0开始的连续编号,以此生成的编号作为框架与最初得到的含有交易次数信息的表进行左连接,似乎就可以得到完整的结果。
这个想法其实是没问题的,但缺少一种特殊情况:如果transactions表为空,此时意味着可能存在多次来访,但每次的交易次数都是0。而恰巧就是这个0也不能由transaction表依附生成。解决这个问题的方法有多种,比如我们可以将visits表和transactions表union后的结果作为依附表来生成编号,但那样未免有些牛刀杀鸡。考虑到transaction表无法解决的情况仅限于表为空、交易次数均为0的这种特殊情形,我们仅需简单的将上述结果union一个特殊的0确保生成的编号框架永不为空即可。同时设置@id从1开始计数。
考虑特殊情况后的SQL语句:
1select 0 as cnt 2 union
3select @id:=@id+1 as cnt
4from transactions, (select @id:=0)i
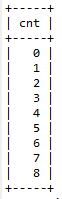
有了这个临时表作为框架,再与最初得到表左连接,就可以得到包含所有可能交易次数的完整统计,SQL语句为:
1select
2 cast(cnt as unsigned) transactions_count , count(user_id) visits_count
3from
4 (select 0 as cnt union
5 SELECT @id:=@id+1 as cnt
6 from transactions, (select @id:=0)i) t1
7left join
8 (select v.user_id, v.visit_date, count(t.amount) cnt
9 from visits v left join transactions t on v.user_id=t.user_id and v.visit_date=t.transaction_date
10 group by v.user_id, v.visit_date) t2
11 using(cnt)
12group by cnt
得到查询结果:

至此,我们离最终目标仅差一步:过滤掉最大交易次数以后的无用信息。为实现这一目标,简单的加一个where条件限制cnt范围即可:
1select
2 cast(cnt as unsigned) transactions_count , count(user_id) visits_count
3from
4 (select 0 as cnt union
5 SELECT @id:=@id+1 as cnt
6 from transactions, (select @id:=0)i) t1
7left join
8 (select v.user_id, v.visit_date, count(t.amount) cnt
9 from visits v left join transactions t on v.user_id=t.user_id and v.visit_date=t.transaction_date
10 group by v.user_id, v.visit_date) t2
11 using(cnt)
12where cnt<=ifnull((select count(*) cnt
13 from transactions
14 group by user_id, transaction_date
15 order by cnt desc LIMIT 1), 0)
16group by cnt
其中cnt后面的判断条件增加ifnull判断是为了考虑transaction表为空的特殊情形,如果不加ifnull则可能导致整个查询结果为null。
最后,给出最终的查询结果:

结果简单,过程不易
以上就是LeetCode中5道比较具有代表性的题目,值得细细品味其中的分析思路和处理流程,相信多半会收益颇丰。当然,行文仅做参考。
觉得不够?
来,这里还有60道牛客网SQL训练题详解
一、牛客网数据库SQL实战详细剖析(1-10)
二、牛客网数据库SQL实战详细剖析(11-20)
三、牛客网数据库SQL实战详细剖析(21-30)
四、牛客网数据库SQL实战详细剖析(31-40)
五、牛客网数据库SQL实战详细剖析(41-50)
六、牛客网数据库SQL实战详细剖析(51-60)(更新完结)
如果你觉得文章不错的话,分享、收藏、在看、留言666是对老表的最大支持。

老表Pro已经满了
所以大家加老表Max吧
每日留言
说说你最近遇到的一个编程问题?
或者新学的一个小技巧?
(字数不少于15字)
留言赠书
部分书籍参与京东每满100减50活动

完整Python基础知识要点
Python小知识 | 这些技能你不会?(一)
Python小知识 | 这些技能你不会?(二)
Python小知识 | 这些技能你不会?(三)
Python小知识 | 这些技能你不会?(四)
近期推荐阅读:
【1】整理了我开始分享学习笔记到现在超过250篇优质文章,涵盖数据分析、爬虫、机器学习等方面,别再说不知道该从哪开始,实战哪里找了
【2】【终篇】Pandas中文官方文档:基础用法6(含1-5)
好文章,我在看❤️