量化金融分析AQF(6):金融数据处理(tushare同时获取多只股价信息、累积收益、每日收益、return分布、股价相关性)
目录
一、获得金融数据
1.3 同时获取多只股价信息
二. 金融数据可视化
2.1 数据透视表 pivot :
三、金融初级计算
3.1 计算每日收益
3.3.1 将NaN值替换为0:
3.2 计算累积收益
四、分析return分布
4.1 直方图
4.2 QQ-Plots
五. 股价相关性
可能用到的库:
import pandas as pd
import numpy as np
import datetime
import matplotlib.pyplot as plt
import seaborn
import tushare as ts
%matplotlib inline
import warnings; warnings.simplefilter('ignore') #忽略可能会出现的警告信息,警告并不是错误,可以忽略;一、获得金融数据
1.1 tushare获取单个对象数据
#获得中信证券的股价信息
zxzq = ts.get_k_data('600030', start = '2019-01-01', end = '2019-03-01')
zxzq.head()
1.2 tushare pro 获取单个对象数据
ts.set_token('你注册的token')
pro = ts.pro_api()
df = pro.daily(ts_code='600030.SH', start_date='20190101', end_date='20190301')
df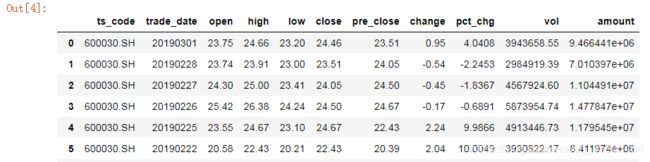
不知道tushare pro的token,可以看我上篇博客量化金融分析AQF(5):金融数据获取、清洗、整理和存储(Yahoo、Tushare)
1.3 同时获取多只股价信息
编写函数同时获得多只股票的数据:
以后有需要直接复制(只需修改时间):
def multiple_stocks(tickers):
def data(ticker):
stocks = ts.get_k_data(ticker,start = '2019-01-01', end = '2019-03-01') #定义了stocks这个daraFrame;
stocks.set_index('date',inplace = True)
stocks.index = pd.to_datetime(stocks.index) #要把日期时间parse成python支持的datetime格式,不然很多python层面的操作无法完成;
return stocks #返回的是进行完处理的stcoks这个DataFrame;
datas = map(data, tickers)
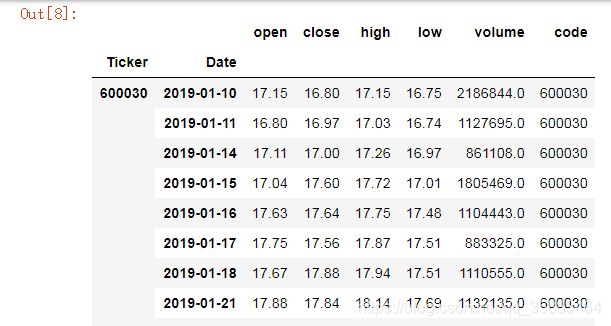
return pd.concat(datas, keys=tickers, names=['Ticker','Date']) #multiple_stocks函数返回的是拼接后的大DataFrame获得以下三只股票数据:
tickers = ['600030', '000001','600426']
all_stocks = multiple_stocks(tickers)
all_stocks如果报错,是tushare数据库问题,可以重启iPython
二. 金融数据可视化
2.1 数据透视表 pivot :
close_price = all_stocks[['close']].reset_index() #重置索引,让索引重新回到默认的0开始;
close_price.head()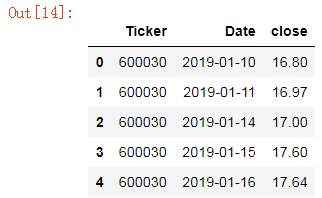
把所有的股价信息显示在一张表格里;数据透视表;
daily_close = close_price.pivot(index = 'Date',
columns = 'Ticker',
values= 'close')
daily_close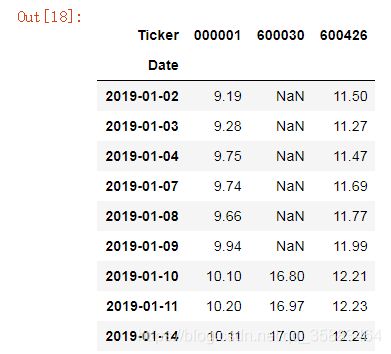
daily_close['600030'].plot(figsize=(8,6))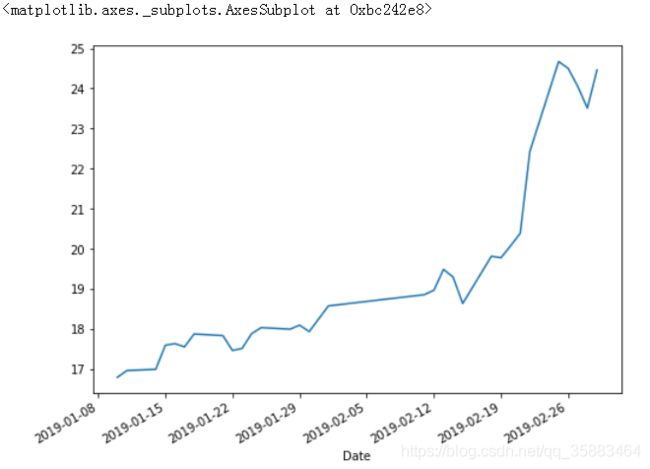
三、金融初级计算
3.1 计算每日收益
用shift方法:
price_change = daily_close / daily_close.shift(1) - 1
daily_close['yes_day'] = daily_close['000001'].shift(1)
price_change.ix[:,0:4].head()
用.pct_change() 方法:
使用详情:http://pandas.pydata.org/pandas-docs/stable/reference/api/pandas.DataFrame.pct_change.html
简单的说,就是计算变化率:(后一个值-前一个值)/前一个值
price_change2 = daily_close.pct_change()
price_change2.ix[:,:].head()
3.3.1 将NaN值替换为0:
price_change2.fillna(0, inplace=True) # 把nan用0代替
price_change2.ix[:5,:]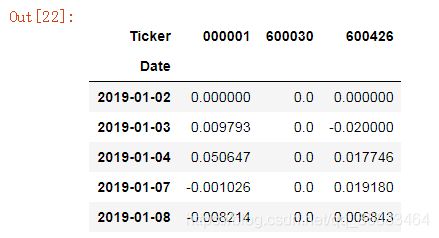
3.2 计算累积收益
cum_daily_return = (1 + price_change2).cumprod() # 按列累乘
cum_daily_return.head()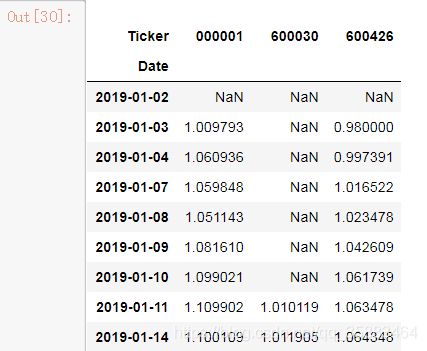
cum_daily_return.plot(figsize=(8,6))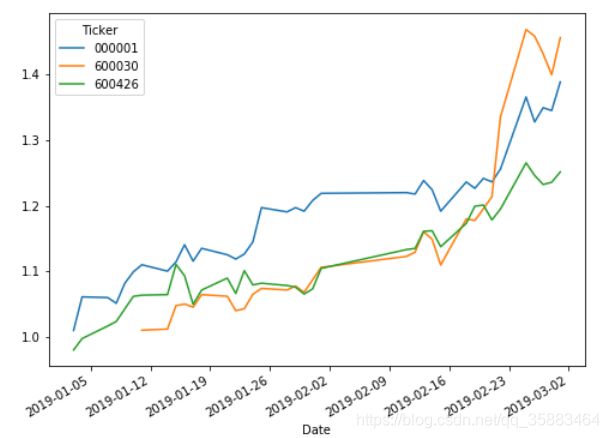
四、分析return分布
4.1 直方图
zxzq = price_change['600030']
zxzq.describe(percentiles=[0.025, 0.5, 0.975]) # 自定义设置百分位数
# 画出所有股票的股价分布:
price_change.hist(bins=20, sharex=True, figsize=(12,8));
4.2 QQ-Plots
分位数图示法(Quantile Quantile Plot,简称 Q-Q 图)
统计学里Q-Q图(Q代表分位数)是一个概率图,用图形的方式比较两个概率分布,把他们的两个分位数放在一起比较。首先选好分位数间隔。图上的点(x,y)反映出其中一个第二个分布(y坐标)的分位数和与之对应的第一分布(x坐标)的相同分位数。因此,这条线是一条以分位数间隔为参数的曲线。如果两个分布相似,则该Q-Q图趋近于落在y=x线上。如果两分布线性相关,则点在Q-Q图上趋近于落在一条直线上,但不一定在y=x线上。Q-Q图可以用来可在分布的位置-尺度范畴上可视化的评估参数。
从定义中可以看出Q-Q图主要用于检验数据分布的相似性,如果要利用Q-Q图来对数据进行正态分布的检验,则可以令x轴为正态分布的分位数,y轴为样本分位数,如果这两者构成的点分布在一条直线上,就证明样本数据与正态分布存在线性相关性,即服从正态分布。
官网:https://www.baidu.com/link?url=WUrNbvBdoy4qoLdu4g_FKzutEx2UnsXCKbeaCPWZB4zL68YuePvvLc81jSyYEc0-NcJVEgYTanaonlSIRwu-9zpSs8QLKuAybX18B_jVnBYfjlmB8Wmknwf090X4Wj9g&wd=&eqid=8fcdbda300051405000000065c920852
使用QQ图来验证股价retun分布:
import scipy.stats as stats
fig = plt.figure(figsize=(7,5)) # 创建图对象
ax = fig.add_subplot(111) # 1个子图
stats.probplot(zxzq, dist='norm', plot=ax) #stats.probplot()用来绘制QQ图;dist='norm':拟合标准正态分布;plot=ax:要画的图
plt.show()
当QQ图图像趋近于y=x的斜线时,说明2者相似性很高,从上图可以看出中信证券趋近于正太分布。
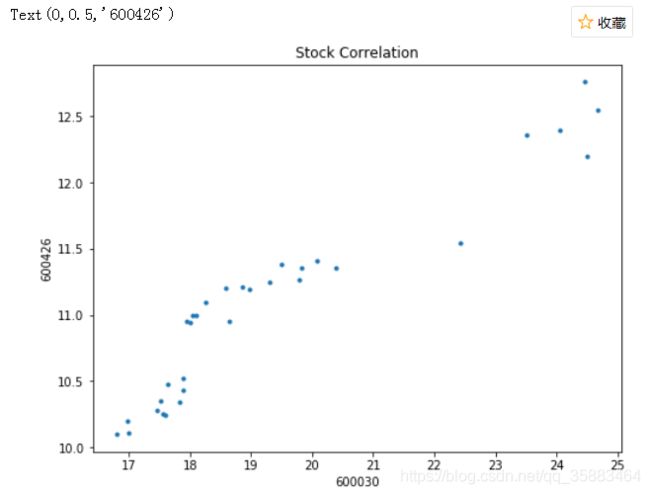
五. 股价相关性
测试数据准备:
获得指数数据:
hs300 = ts.get_k_data('hs300',start = '2016-01-01', end = '2017-07-01')
hs300.set_index('date', inplace = True) 设置索引为date
hs300.index = pd.to_datetime(hs300.index) 设置date为时间序列
hs300.head()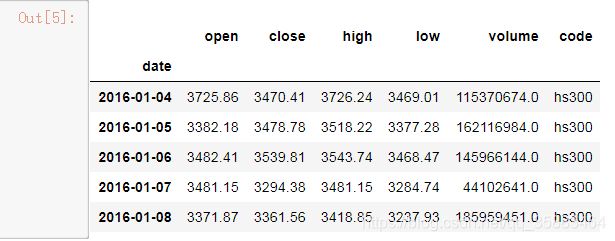
计算沪深300指数收益:
hs300_return = hs300['close'].pct_change().fillna(0) # 第一个值本来是nan,改为0
hs300_return.head()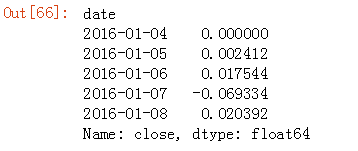
使用同样的方法:(使用上面的一次获取多个股票信息的函数)表格命名为price_change2

把沪深300的收益拼接到前面得到的大表price_change2中
return_all = pd.concat([hs300_return, price_change2], axis=1)
return_all.rename(columns={'close': 'hs300'}, inplace=True)
return_all.fillna(0, inplace=True)
return_all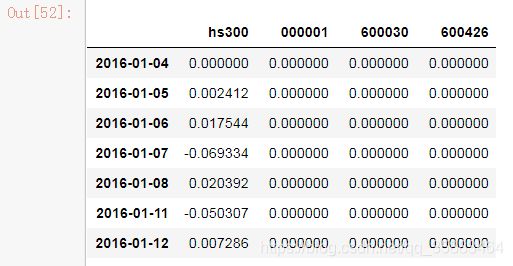
这里没有获取2016年的000001、600030、600426.所有都是0
计算累积收益:
cumreturn_all = (1 + return_all).cumprod()
cumreturn_all.head()累积收益作图:
cumreturn_all[['hs300', '600030', '600426']].plot(figsize=(8,6));
计算相关性:
corrs = return_all.corr() # 相关性矩阵查看其它股票与hs300的相关性:
corrs.loc['hs300']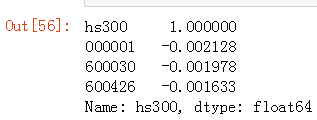
热力图查看:
fig = plt.figure(figsize=(8,6))
seaborn.heatmap(corrs)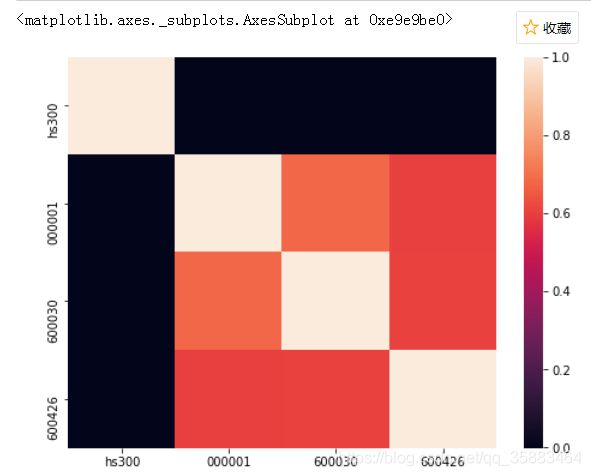
或者用散点图查看相关性: