浅谈 Knowledge-Injected BERTs

作者丨张成蹊
学校丨北京大学硕士生 / 字节跳动AI-Lab实习生
研究方向丨自然语言处理、命名实体识别
序
在当下的 NLP 领域,BERT 是一个绕不过的话题。
自从 2018 年底横空出世以来,它以势不可挡的态势横扫了整个 GLUE 榜单,将基准推进到 80% 的水平线,在 SQuAD1.1 中全部指标超越人类水平。在使用其预训练的参数后,几乎所有的下游任务都获得了相当的增益(当然,大量参数随之带来的也有运算效率的下降),自此开创了大语料无监督任务的预训练模型时代,自成一个山门,史称 Bertology。
从任务本身来看,BERT 本质上是一个通用的语言模型(Language Representation Model),在进行预训练时,我们希望它能够学习到词表中每个词的向量表示,即对我们平时所接触的自然语言进行编码(encode),使之转化成模型能理解的语言。
这样的设定本身存在一个小问题:通过模型编码之后的语言向量,人类无法理解,那如何才能确保模型正确地学到我们希望的知识?一个解决方案是,我们将模型的输出映射到原来的词表,然后将概率最大的单词作为模型的预测结果。如果这个单词就是与我们模型的输入一致,即意味着模型确实知道了这个单词的含义。
BERT 将上述解决方案巧妙地实现为一个完形填空的过程,即随机遮住一些单词,只给模型上下文信息,让模型去预测这些单词的表示。此外,为了让模型对句子之间的段落关系有更好的理解,我们也可以让它去尝试预测两个句子之间的关系:是否连续——我们只需要留出一个 token 的空位来进行这个二分类训练就可以。
这些设计保证了模型能够同时建模句子内部的词法信息与外部的关系信息,而输入的数据本身除了一个预先定义好的词表外,不需要任何多余的监督信号,所以能在大量语料上进行预训练。合理的任务设计+大量语料的支持,让 BERT 有了超越同侪的效果。
随着对任务理解的加深,有些人开始提出了这样的问题:
“如果完型填空任务中遮住的不是一个单词,而是一个短语,是不是 BERT 就能够更好的对短语进行辨析?如果我们增加可以学习到更多知识的任务,BERT 会不会变得更好?——如果我们设计一些任务不停地训练它,让它一直学习下去呢?”
从直觉上来说,如果我们遮住一个短语(phrase),而非一个单词(word),即便 BERT 在大部分任务中并没有变好,我们也有理由相信它会在一些需要短语知识的任务中变好(比如 NER);而如果我们增加更多的任务,尝试给它灌输更多的知识(并且它的复杂度本身又足以支撑它在诸多任务的填鸭式教育中不会头昏)的话,它将同时编码更多方面的信息。
上面的思路似乎值得一试,然而大部分的想法都需要外部知识的支持。例如:如果我们在一个句子的随机位置遮住一个随机长度的短语,这个短语大部分情况下不会具有值得学习的实质性意义(虽然 SpanBERT [1] 就是这么做的)——而如果我们有办法将结构化的信息注入到大量的原始语料中去,我们就能知道哪些短语是有意义的了,以此就可以进行更多的探索性实验。
这也是本文将关注的重点:将外部知识注入到预训练语言模型中。具体而言,我将探讨下面三个问题:
-
我们可以把哪些信息引入到 BERT 的预训练语料中,以使 BERT 在某些或者全部的任务上有更好的表现?
-
如何根据这些信息的内容,针对性地设计有意义又易于实现的预训练任务?
-
这些信息的加入是否能带来我们预期的模型提升?
值得注意的是,本文仅探讨(至少在建模预期上)着眼于对通用 NLP 任务提升的 paper。在 arXiv 上也有相当一部分的 paper 尝试了将结构化的知识注入到 BERT 中,随后进行一些特定领域的应用(大部分基于 Commonsense 的 QA 任务,少部分的文档分类或药品推荐任务),有感兴趣的读者可以自行搜索阅读。
我将默认读者已经对 BERT 的结构与任务具有一定的了解,不花时间介绍相关的背景知识。对于想了解这些知识的同学,我觉得 BERT 的原文 [2]、 BERT 中的核心结构:Transformer [3],以及 Transformer 的图形化解读 [4] 这三个资料值得一读。
Knowledge Enhanced BERTs
Overview
正如上文所说,如果要对 BERT 进行改动,最易于尝试的方法就是将 mask 这个行为从 token level 提升到 phrase level,SpanBERT [1] 就进行了这样的一次尝试。鉴于此,尽管 SpanBERT 中并没有使用到任何外部的知识,我也会对它的预训练策略进行简单的论述——而在了解 SpanBERT 的思路以后,对于一些殊途同归的实体mask策略(如 WKLM / ERNIE-baidu / ERNIE-thu 等)就更容易理解了。
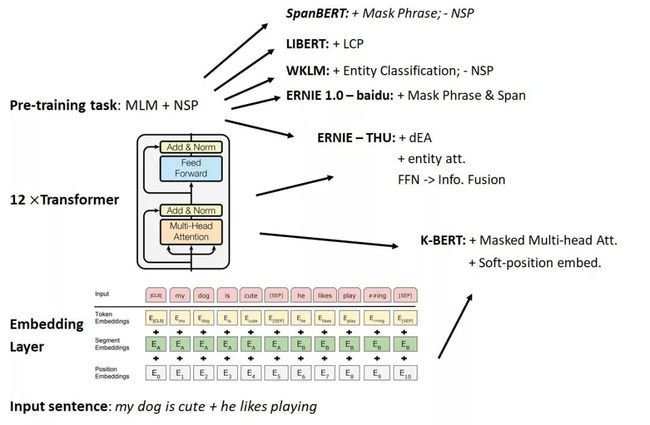
▲ 图1. Knowledge-injected BERTs的思路简图
我总结了大部分模型在进行知识注入时所采用的策略(见图 1),它们或多或少地修改了传统 BERT 的任务与结构。
其中,大部分的 paper 旨在修改模型的预训练任务:与传统BERT的预训练策略不同的是,现在我们能够根据手头上已有的外部知识,来更加精确地选择我们的 mask 目标——也就是特定的实体了(WKLM [5] / ERNIE-baidu [6]);此外,我们也能人工设计一些预训练任务,来针对性地提高 BERT 在词法、语法或句法方面的表现(LIBERT [7])。
ERNIE-thu [8] 做得更深一步,在增加一项预训练目标的基础上修改了部分的模型结构,将其中一半的 transformer 层用来同时编码 token 与实体,并注入实体信息到所对齐的 token 上。
K-BERT [9] 在输入的 embedding 上做了尝试:它直接使用知识库中的信息扩展了原有的输入,然后使用 soft-position 来对齐插入单词与原有单词之间的距离。由于在绝对位置上,插入的单词仍然影响到了整体的 self-attention 计算,所以 K-BERT 也修改了部分的模型结构,以纠正这个负面影响。
最后,尽管没有出现在图中,ERNIE2.0-baidu [10] 将预训练任务数量扩展到了 7 个,然后采用多任务序贯训练模式,来保证模型在所有任务上都有很好的效果。截止本文写作之时(2020.01.20),ERNIE2.0 仍然居于 GLUE benchmark 榜首,紧随其后的是前几天阿里达摩院的 Alice v2。
下面,我将按我个人的理解对这些模型进行简单的归类,然后通过循序渐进的方式来详细说明这些模型提出的思路与采用的训练模式。希望大家在看过总结之后,能够根据自己想完成的任务设计更具针对性的预训练 task。
毕竟,无论是否要用到外部的知识,设计一个数据友好、功能有效的策略,总比调参或组件的堆叠更有成就感一些。相信如果 Bi-LSTM 看到我们所做的努力,也会在天上给我们竖起一个大拇指吧。
一次简单的试探:SpanBERT
遥记得两个月前参加实习生面试的时候,现在的 leader 提出了一个有趣的问题:现在假设你有预训练一个 BERT 的能力,你觉得可以做出什么样的调整,来提升预训练以后的模型在 NER 任务上的效果?
我当时紧皱眉头,思索片刻,犹豫了一会儿后回答:我觉得可以把 mask 策略从 token level 改成 entity level,这样模型能更好的学到实体的表示,相信会对 NER 任务有提升。
leader 说:哦,这个啊,这个不是已经做过了吗。
(年幼无知的)我:???
诚然,如果说要对 BERT 进行改进,最容易想到的就是修改 mask 的策略,SpanBERT 的思路也非常简单:
1. 随机选择一个长度,这个长度是从一个几何分布中采样出来的;几何分布保证了采样出来的长度更倾向于短而非很长;
2. 随机在句子中选择一个起始点,将从这个起始点开始的、指定长度的 token(subword 在这里不算做一个独立的 token)序列全部 mask 掉;
3. 重复 1、2两 个步骤,直到任务设定的需要 mask 的数量够了为止。
与 BERT 相同,SpanBERT 也总共 mask 每个句子中 15% 的 token。在这 15% 的 token(span) 中,每个 span 有 80% 的概率被直接替换成 [MASK],10% 的概率被其他随机的 span 替换,最后 10% 的概率保留原词不变。
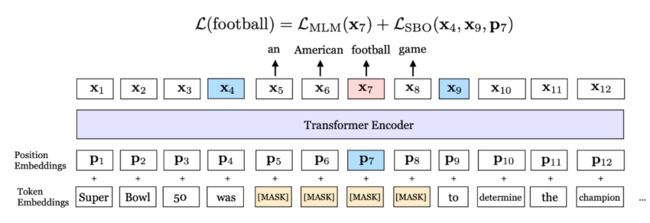
▲ 图2. SpanBERT中一次mask的示例
上图是这种 mask 策略的一个简单示例:在这里,我们随机选择到了一个长度为 4 的 span,选择起始位置在 an 处,因此我们 mask 的内容就是:an American football game;我们将这四个单词 mask 住,然后让模型通过前后文+当前单词表示来尝试复原每个单词。具体操作如下:
在尝试复原单词 football 时:使用了当前单词的输出 x_7 来尝试复原 football 在词表中的下标(这也就是传统 BERT 中的 MLM 任务);除此以外,SpanBERT 的作者提出了一个叫 Span Boundary Objective (SBO) 的任务,即使用当前 span 的前后各一个单词的表示,以及当前待预测单词的位置下标来复原当前单词。
与传统的 BERT 复原单个 token 的预期不同,作者希望通过人为的设定,能够赋予模型通过上下文来复原整个 span 的能力——当然,精确到 span 中每个具体的 token 时,我们还需要加入当前 token 的位置信息,这就是整个 SBO 任务设计的初衷。
通过预期的设定,作者也得到了想要的结果:SpanBERT 在 GLUE 的所有实体相关任务上相对传统 BERT 有更好的表现:

▲ 图3. SpanBERT的结果。作者在很多数据集上做了比较,在此只截取了部分GLUE数据集上的结果
可以看到,SpanBERT 在 QNLI 和 RTE 两个数据上有非常显著的提升,此外在 SQuAD1.1 和 2.0 也有明显的提升(不在图中)。作者认为 SpanBERT 在 QA 任务上的提升是因为同时聚合了 token level 和 phrase level 的信息。
篇幅所限(以及作者太懒),对其他比较实验有兴趣的同学,可以去查看原文的第五部分,里面对 QA / Conreference Resolution / Relation Extraction 三类数据集与 GLUE 都做了详细的评测。另外,作者还在文中详细论证了 NSP 任务在预训练任务中的有效性,得到移除 NSP 任务能使模型学得更好的结论,由于与本文核心主题无关,在此不进行详述。
Entity信息的使用:WKLM & ERNIE1.0-baidu
说完 SpanBERT,让我们认识它另外两个孪生兄弟:WKLM 与 ERNIE1.0-baidu。与前者不同,后面两位兄弟都正式使用了知识库中的 entity 信息,虽然他们的预训练任务的设计与训练目标有所不同,但将他们合在一起讲,能更好的加深对 mask entity 这一策略的印象。
话说回来,其实在 SpanBERT 中也已经对 mask entity 这一想法进行了简单尝试(当然,作者首先使用了一个现成的 entity 抽取工具来抽取句子中的 entity,详请参阅原文的 Ablation Test 部分),但是并没有 work。
对于这个结果,私以为是预训练的任务 objective 设计与这个任务并不 match(换句话说就是相性不合)导致的,可能造成这种情况的原因是:SBO 中只使用了 entity 前后各一个 token,以及其中各个 token 的位置信息来预测当前 token,对于随机截取的 span,这个目标设计会 work,因为在绝大多数情况下我们截断了很多有意义的信息,所以前(后)的那个 token 将对预测 span 中的 token 提供很大的信息量。而对于本身封装了一个很强信息的命名实体来说,前后的 token 就无法提供那么多信息了,导致这个预训练任务结果不好。
举例来说:
怎么会这样呢,明明是我先来的。
这个句子中,如果我们将我先识别成了一个人名,并将它 mask 掉之后,是和先 这两个 token 并不能给模型重新复原出我这个 entity 提供很好的信息。其实直觉上来讲,是的后面一般有更大的可能性是我,相对还好一些,而先这个 token,对于复原任务着实不会提供什么帮助。
而如果我们采用 SpanBERT 中的随机 mask,mask 掉了我先之后,前后的单词反而对这个 span 的关联性增强了,对于复原其中的每个 token 就能提供更多的信息。
所以,在 WKLM 与 ERNIE1.0 中,由于使用了外部的知识库,可以采用更多不同的预训练任务的定义方式:
WKLM主要采取的是同类替换的思路,以期增强模型对于事实知识的建模:具体来说,对于某个 entity,我们使用与它同类型的另一个 entity 来替换它,这样就能构造一个在语法上正确,但是在事实上错误的负样本——当然,原始句子是正样本。作为训练目标,我们让模型来判断每个 entity 是否被替换,这样模型就能够学到因果事实。一个替换的样本如下图所示:
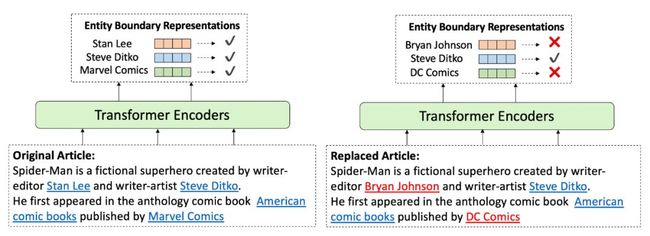
▲ 图4. WKLM构造负样本的一个示例
为了实现这个训练目标,作者定义了增加了一个预训练的二分类任务,即对于每个 entity 的输出,模型需要判断这个 entity 是否被经过替换。当然,传统 BERT 中的 MLM 任务仍然被保留了下来以建模上下文的关系,但是 token 的 mask 只会在 entity 以外进行,并且 mask 的概率从 15% 减小到了 5%。
此外,我们需要准备对应的数据以保证训练任务顺利进行。
-
找到句子中的实体:在 English Wikipedia 中本身已经存在了实体的 anchor link;我们通过 link 找到这个实体以及实体所有的别名,并通过字符串匹配将文本中所有的别名也识别出来,都视作 entity。
-
构造负样本:如上文所说,每个原始句子我们都通过替换与原始 entity 相同类型的另一个 entity 来构造对应的负样本。正负样本的比例是 1:10;此外,作者限定在不会出现两个连续的 entity 同时被 mask 的情况,以此来减少虽然两个 entity 都被替换了,但是替换完以后的两个 entity 所构造的新句子正好符合事实的情况。
在使用外部 entity linking 工具的情况下,该预训练过程可以不仅局限在 English Wikipedia 数据上,所以这个方法也具有很强的扩展性。
作者在 QA 与 entity typing 的数据集上进行了测试,并对 MLM 进行了 ablation test,事实证明了模型的有效性(For detail,请查阅原文第三部分)。
ERNIE1.0-baidu 采用的思路是多阶段学习,请首先容我吐槽一下这个名字,因为清华和华为诺亚实验室联合发表的另一篇 paper 也叫 ERNIE(所以我管它叫 ERNIE-thu),从 ELMo 到 BERT 到 ERNIE,使用芝麻街人名作为模型名字属实是种新常态。
在知道了 SpanBERT 和 WKLM 的预训练思路之后,我们可以来这样总结 ERNIE-baidu 的设计思路:集百家之长。ERNIE-baidu 的预训练分为了三个阶段:
1. Basic-Level Masking:和传统 BERT 一样,以 15% 的概率来 mask 句子中的 token;
2. Phrase-Level Masking: 和 SpanBERT 一样随机 mask 一些 phrase,不同的是 ERNIE 中使用了外部工具来辅助识别句子中的 phrase,然后 mask 整个 phrase,最后通过模型的输出来复原 phrase 中的每一个 token;
3. Entity-Level Masking: 与 WKLM 相似,随机 mask 了 entity。相较于上个阶段的 phrase,entity 是一种具体的存在,所以会保有句子中更多更重要的信息。
在依次通过三个阶段的学习过程之后,模型同时具有了词级别的表示能力,短语级别的表示能力与实体级别的表示能力,把更丰富的语法知识集成到了模型中。
如此来看,ERNIE-baidu 主要是在预训练的任务上做了增强。为了进一步增强模型在 QA 上的效果,ERNIE 修改了传统 BERT 中的 segment embedding,将它原有的标识上下两个句子的功能转换为了标识 Query-Response 的功能;在此设定上,就能够允许模型 encode 多阶段的对话信息(如 QRQ、QRR、QQR 等),以期在 QA 任务上有更好的表现。
作者在语言推理:XNLI、语义相似度:LCQMC、NER:MSRA-NER、情感分析:ChnSentiCorp 与检索式 QA:NLPCC-DBQA 五个任务上进行了效果的测试。
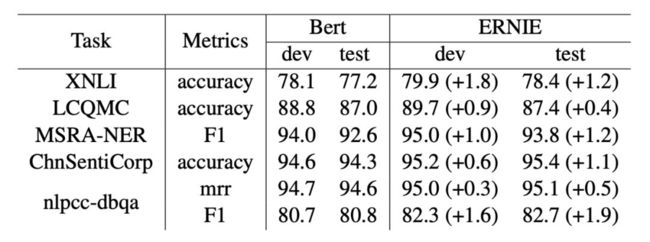
▲ 图5. ERNIE-baidu实验结果
结果表明,相对于传统的 BERT,ERNIE 在五个任务上都有一定的提升,其中在语言推理、NER、情感分析与 QA 上提升相对比较显著,而在计算语义相似度的任务上提升相对不够明显。
私以为这与预定义的训练目标有着比较直接的关系,因为尽管我们预期的目标是提升模型在语义上的理解,但是实际上 mask entity 这种形式并不能非常直观的提升模型对于语义的认知(正如我在面试中所理解的那样,如果 mask entity,直接加强的是模型通过上下文来对短语进行完形填空的能力,我们可以通过定义预训练的任务来将这种能力不直观地转换到其他目标上)。
读者可以通过在 AAAI-20 上发表的 SemBERT [11] 来进一步了解如何通过设计预训练任务的方式来直接地提升模型在语法上面的结果,在此不再赘述。
词法层面的直接加强:LIBERT
现在,让我们抛开所有的 entity mask 策略到一边,重新审视上面引出的问题:
如何借助外部已有的知识,通过设计预训练任务的方式,来直观地加入一些词法、语法、句法信息到模型中呢?
作为开阔思路的甜点,我们来简单了解下 Linguistically-informed BERT (LIBERT) 是如何做的。
除了 English Wikipidea 之外,我们可以在一些其他的知识库中获得另外的信息,比如:
-
从 WordNet 与 Roget's Thesaurus 中能够获得同义词对,如:car & automobile.
-
从 WordNet 中能获得上下位词对,如:car & vehicle.
LIBERT 通过以下步骤来生成额外的训练样本:
1. 首先,选择一个静态的词向量生成方法,在给定样本后能够产生词的向量表示;使用这个静态的词向量,目的是为了使得我们能够直观地衡量两个词之间的词义距离(如文中使用的最直接的cos相似度方法);
2. 我们将同义词对与上下位词对都视为正例,将所有的词对划分为指定大小的 batch;
3. 对于给定的正例词对 ![]() ,我们首先找它所在 batch 的所有
,我们首先找它所在 batch 的所有 ![]() 中,与当前
中,与当前 ![]() 相似度最高的词
相似度最高的词 ![]() ,以此构造一个负样本对
,以此构造一个负样本对 ![]() ;使用同样的方法能够对于
;使用同样的方法能够对于 ![]() 也生成一个负样本;综上,对于每个正样本,我们能够产生两个负样本。
也生成一个负样本;综上,对于每个正样本,我们能够产生两个负样本。
4. 直接将词对中两个词合在一起作为一个句子,并在中间插入一个 [SEP] 符号,前面的词使用 segment id=0 来标识,后面的使用 1 来标识。

▲ 图6. 通过近义词对构造的最终输入形式
值得一提的是,我个人对于第四步的构造方法持比较强烈的怀疑态度,虽然模型最终结果证明了其有效性,但我认为使用 segment id(一个传统 BERT 中来表示上下句子的符号)来标识不同的词会给原来的训练任务造成负面的影响;此外,手动构造的输入也有太短的普遍情况。总的来说,这样构造的输入并不能与原来预训练的输入等量齐观。我也期待看过此文的同学阐述自己对这个任务独特的理解。
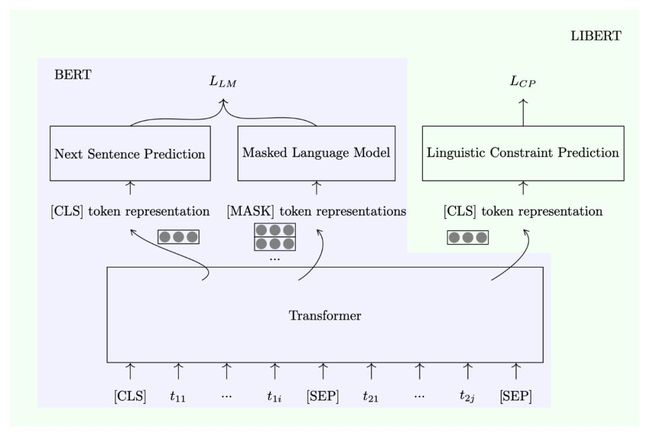
▲ 图7. LIBERT模型结构
模型的预训练目标是在原本的 MLM 与 NSP 任务上增加了一个任务:Linguistic Constraint Prediction (LCP),即一个二分类标签,在做线性变换后通过 softmax 来判断输入的词对中的两个词是否具有有效的词法关系(即近义词或上下位词)。作者在 GLUE 上测试了预训练后的模型。
值得思考的一点是,鉴于语法本身包含了词法与句法两个层面,如果我们想要提升模型在整个语法上的理解,我们也可以构造一些从各种层面对模型有益的任务。ERNIE2.0 在这方面做了许多有用的探索,我会在全文末对它进行简单阐述。
模型结构的百花齐放:K-BERT与ERNIE-thu
通过上面的了解,我们已经对外部知识所能起到的作用,以及如何基于此设计合适的预训练任务有了充分的了解。接下来,K-BERT 与 ERNIE-thu 将给我们以结构上的启发:如何通过修改模型结构,以更匹配我们所想要指定的预训练任务呢?
ERNIE-thu 给出了一种思路:将 entity 的信息在模型训练时注入到所对齐的 token 中。
具体来说,ERNIE-thu 保留了传统 BERT 中前 6 层 transformer 来建模 token 的上下文信息,并将之后的六层改成了下图的结构:
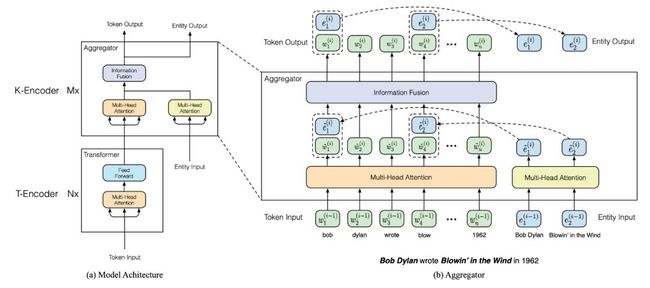
▲ 图8. ERNIE-thu模型结构,使用右侧的Aggregator替换了原来的BERT后6层transformer
想要把 entity 信息注入到原有 token 中,需要解决三个问题:
-
如何从句子中提取出一个 entity,并将其与句子中的 token 对齐?
-
在增强 token 信息时,如何提取出 entity 中蕴含的信息?
-
如何具体实现这个增强?
首先,提取 entity 的途径有许多,上文已经介绍了基于 Wiki 的 anchor link 与外部的 NER 工具,ERNIE-thu 中使用了前者进行实体的提取与对齐。值得注意的是,如图中所示,作者仅将 entity 与其第一个 token 进行对齐,也即 entity 中的信息只会与这个 token 发生直接的交互。
为了简单直接地获得 entity 中所包含的信息,作者使用了一个知识图谱的 embedding 工具:TransE [12] 来通过原始的知识图谱就获得 entity 的向量表示,随后作者在模型预训练过程中控制这个表示不变,来进行信息的交互。这样做的目的是可以直观地观察到仅仅将 entity 的信息注入到原始文本中,将对模型产生什么影响。
在训练过程中,句子及其对应的 entity 将同时放入上图的 Aggregator 中,entity 随后将通过一个 Multi-Head Attention(下称 MHA)来建模所有 entity 之间的关系信息,随后与前面对齐的 token(当然也过了一个 MHA),共同喂到一个 Information Fusion 层(从模型结构上来看,这个 Fusion 层替换了 Transformer 中原来的 FFN)。
Information Fusion 实现了这样的一个功能:
当普通的 token(没有 entity 信息直接注入)进入该组件后,将直接通过一个 FFN 输出;
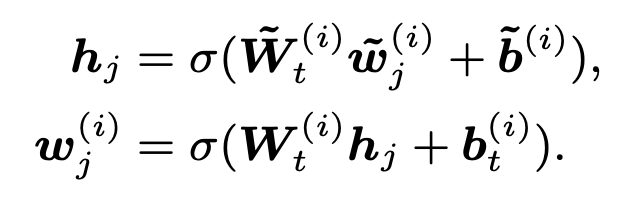
▲ 图9. 普通token在Information Fusion层做的变换,本质上就是一个FFN变换
当有信息注入 token 时,做如下变换:
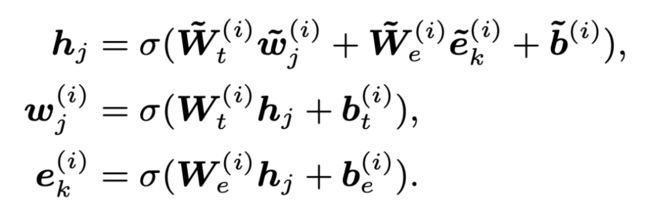
▲ 图10. Enhance token embed. with entity embed.
对于有 entity 信息注入的 token 来说,该层主要目的是将 entity 信息与 token 信息通过矩阵变换求和,获得一个集成所有信息的向量,随后根据这个向量来重新生成 token 与 entity 的分布。
最后,作者将变换后输出的 entity embedding 经过 softmax 之后,映射到输入句子所有的 entity 中的一个(至于为什么不映射到整个知识图谱的 entity 空间中,作者说是因为这个空间对于 softmax 这个操作来说太大了——尽管如此,个人认为这个设定仍是一个值得商榷的点)。
作者在 Entity Typing、Relation Classification 与 GLUE benchmark 中测试了模型的结果,发现在前两个任务中有十分明显的提升,而在 GLUE 上也与传统的 BERT 不相上下。
K-BERT 从模型的输入出发,将输入的句子进行了巧妙的重新排列,来实现了注入外部知识的目的。
对于一个已经做完知识图谱对齐的句子输入,K-BERT 所做的事情不可谓不简单粗暴:它直接将与当前实体 e 相关的知识 ![]() 加入到 e 的后头,就像下图里做的那样:
加入到 e 的后头,就像下图里做的那样:
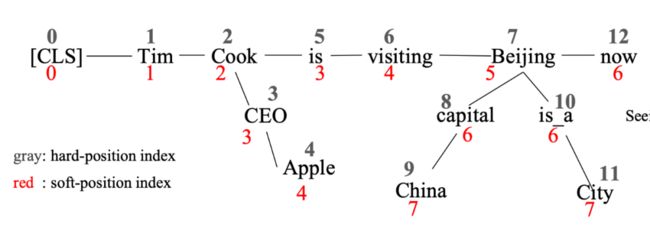
▲ 图11. K-BERT的输入
当然,这样的做法会带来两个很严重的问题:
1. 首先,外部的关系(诸如:CEO、Apple、is_a、City 等)的表示会严重影响原有句子的分布,加入了很多无关的信息,导致模型学习效果变差;
2. 其次,在做 MHA 的时候,插入的一些 token 影响了原本句子之间的位置关系,比如原来 Cook 与 is 之间的距离差为 1,现在变成了 3(因为插入了 CEO 与 Apple)。
K-BERT 做了两个十分巧妙的变换,解决了上述两个问题:
首先,除了传统 BERT 中的 positonal encoding 方法(对应于上图的 hard-position encoding)以外,作者提出了另一种编码模式 soft-position encoding,即上图红色标识的数字。这种编码体系的好处在于允许 token 出现在同一位置,保持了原有 token 之间的位置信息不变。可以看到,这种编码体系下,Cook 与 is 之间的距离仍然保持为 1;
其次,尽管我们使用 soft-position encoding 的方式保持了相对位置不变,但是喂到 BERT 模型中做 MHA 时,在绝对位置上 Apple 仍然影响了 is 的信息,因此作者提出了可视矩阵(Visible Matrix),控制了相关的知识之间的相互影响,而避免了知识对原有句子的分布产生影响(作者在文章中管这种影响叫 Knowledge Noise)。
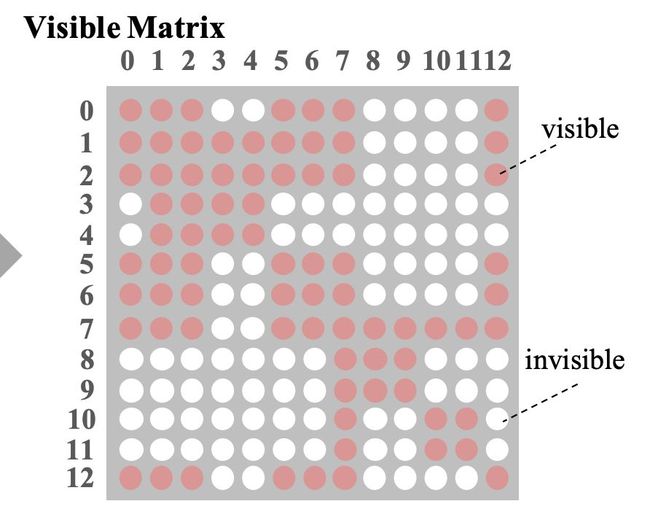
▲ 图12. 图11中的输入所对应的可视矩阵:红点表示相互可视,白点表示不可视
从另一个角度上来考虑,这种做法本质上还是在对齐 entity-relation 与原有句子中的 token,只是 ERNIE-thu 将 entity 对齐到了 entity 所在的第一个 token 中,而 K-BERT 将外部知识对齐到了整个 entity 之上。
可以预见地,加入了可视矩阵之后,我们需要将原有的 MHA 修改为支持 mask 的形式,也即作者文中所提出的 Masked Multi-Head Attention。
最后,作者 XNLI、LCQMC 等多个数据集上进行对比实验,证明了模型结构的有效性。作者也进行了详细的 Ablation Test,论证了所加入的 soft-position 以及可视矩阵的效果。
最后之前:ERNIE2.0-baidu
ERNIE2.0 实属预训练任务定义之王者,大力出奇迹之践行者。百度毫不吝啬地在文中提出了高达7种预训练任务,涵盖了单词级别的大小写识别、频率识别与 entity mask(即 ERNIE1.0-baidu),结构级别的句子重排序任务、句间距离预测任务,语义级别的修辞关系与检索相关度任务,目前仍霸榜 GLUE benchmark。
为了很好地平衡所有预训练任务之间的关系,不让模型遗忘训练顺序靠前的任务,作者也提出了多阶段多任务 warm-up 式(我的个人称法)训练过程。
不过有点遗憾的是,作者在文中并没有给出 Ablation 实验,来一一比较所有的预训练任务之间的有效性。
References
[1] https://arxiv.org/abs/1907.10529
[2] https://arxiv.org/abs/1810.04805
[3] https://arxiv.org/abs/1706.03762
[4] https://jalammar.github.io/illustrated-transformer/
[5] https://arxiv.org/abs/1912.09637
[6] https://arxiv.org/abs/1904.09223
[7] https://arxiv.org/abs/1909.02339
[8] https://arxiv.org/abs/1905.07129
[9] https://arxiv.org/abs/1909.07606
[10] https://arxiv.org/abs/1907.12412
[11] https://arxiv.org/abs/1909.02209
[12] http://papers.nips.cc/paper/5071-translating-embeddings-for-modeling-multi-rela

点击以下标题查看更多期内容:
-
AAAI 2020 | 语义感知BERT(SemBERT)
-
从Word2Vec到BERT
-
任务导向型对话系统:对话管理模型研究最新进展
-
后BERT时代的那些NLP预训练模型
-
BERT的成功是否依赖于虚假相关的统计线索?
-
从三大顶会论文看百变Self-Attention
关于PaperWeekly
PaperWeekly 是一个推荐、解读、讨论、报道人工智能前沿论文成果的学术平台。如果你研究或从事 AI 领域,欢迎在公众号后台点击「交流群」,小助手将把你带入 PaperWeekly 的交流群里。
▽ 点击 | 阅读原文 | 获取最新论文推荐