咖啡汪笔记 —— 微服务架构下如何保证事务的一致性(InfoQ公开课)
Hello, 大家好!
我是不作死就不会死,智商不在线,但颜值超有品的拆家队大队长 ——咖啡汪
一只不是在戏精,就是在戏精路上的极品二哈
前几天在 InfoQ 公开课上看到了自己感兴趣的东西,所以便简单做了下记录
附上原视频链接:
微服务架构下如何保证事务的一致性 | InfoQ 公开课
讲师:梁桂钊
视频链接:https://www.infoq.cn/video/K7pDdIP5ZvqY9aAbf5vY

前言
课程目录,你能了解到什么:
什么是分布式事务?
分布式事务用的多吗?
二阶段提交协议/三阶段提交协议,为什么业务上用的不多?
二阶段提交协议/三阶段提交协议,使用案例有哪些?
CAP 理论有哪些误区?
TCC 模式,有哪些借鉴?
补偿模式,在哪些场景下会使用?
可靠事件模式,是否引入消息队列,就可以了?
可靠事件模式,反向消息也存在消息丢失,如何考虑?
可靠事件模式,如果我们采用广播模式,怎么办?
如何设计一个可复用的分布式事务解决组件?
RocketMQ分布式事务模式,是否可靠?
开篇有益
快来随本汪一起看看吧
1. 单体服务的性能没有微服务好,是不一定对的。
微服务化后,整个调用链路会变得非常的长,原来的一次 RPC 调用会变成多次 RPC 调用,网络上的性能损耗就增加了。
比如说异地多活,他最大的挑战其实就是网络时延,机房内部调用是 1~2 毫秒的延时,同城跨机房一般是十几毫秒,跨省市比如杭州到上海之前的数据大概是 30~50 毫秒之间,那么之前的项目是厦门到新加坡,极端情况下是会有 100~200 毫秒的延时,网络时延的堆积,会对性能产生很大的影响。
微服务的本质是牺牲网络调用的性能,来对机器的资源进行压榨。
2.跨服务之间数据的一致性问题,也就是分布式事务。
3.从本地事务到分布式事务的演进
思考:什么是分布式事务,为什么会需要分布式事务?
单体服务之下,程序经常被部署在单个物理机,数据库也是一个,可以使用数据库的ACID 原子性,一致性,隔离性,持久性来保证数据的一致。
瓶颈:CPU, 内存,磁盘IO, 网络带宽这些都是硬件的资源瓶颈。
但每个数据库仍可以保证自己的 ACID
重点:分表,通过哈希取模,把它分成1024张表,但他们在一个库下,仍可以通过ACID 保证强一致性。通过时间取模,像退款,物流,日志,我们根据时间周期,按年,按季度来分,只要他在统一个库下,他数据库的基本特性都是可以用的。
分库不一样,各个库之间是不感知的。
概念:分布式事务是保证不同数据库中数据一致性的解决方案。

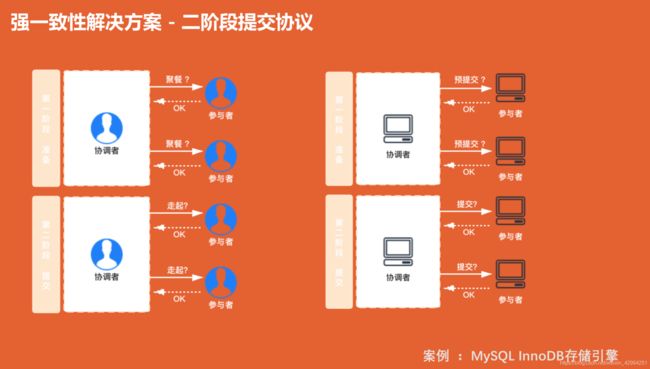
4.强一致性解决方案 - 二阶段提交协议
两个阶段:第一阶段准备;第二阶段提交
两个角色: 一个协调者,负责任务的协调;一个参与者,负责具体的参与执行的。
简单例子助理解:
团队聚餐,共10个人,愿意去的回1,大家给出各自的答复。大家都回复1,再决定是否开始走。
真实例子:
协调者询问参与者是否预提交?全部参与者都回复预提交成功,才可以发起正式提交;有一个参与者回复预提交失败,则协调者回复全部参与者,执行回滚,该次提交失败;
注意:这有一个问题!
二阶段提交是同步等待的,假如有参与者一直联系不上,或者有参与者一直不回复,这个过程就会很长,甚至是死等待。同步就导致他非常耗时。
使用场景:Mysql InnoDB 存储引擎就是用的二阶段提交协议。他的 binlog(二进制日志) 和 (事务日志)redolog就是用的二阶段提交协议来保证一致性的。
具体执行过程:我们现在更新一条数据,他会先执行一个 redolog , 就是一个预提交状态,然后写出 一个binlog ,并写入磁盘,正式提交,更新完成。数据库中有协调者来完成。
为什么数据库中用,实际业务中用不到呢?
重要的问题是我们在微服务中,是禁止 DB 直连的,就经常要跨服务调用,这样就好存在网络时延,甚至会请求失败,二阶段提交协议,由于是同步的,碰上网络抖动或其他故障,就容易失败,所以微服务中一般不会使用到他。
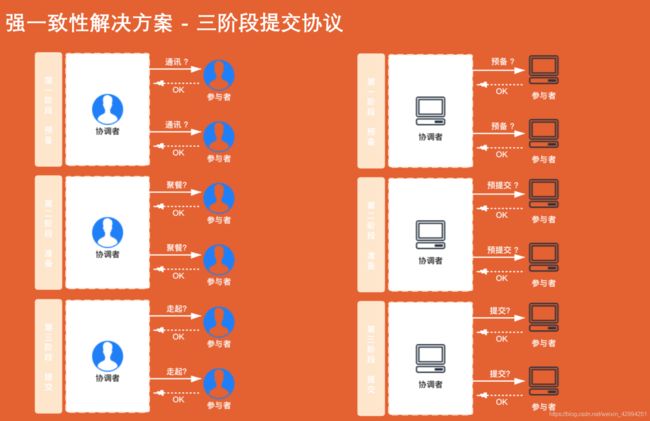
5.强一致性解决方案-三阶段提交协议
三阶段提交协议是二阶段提交协议的一个改良版本。
三阶段采取了超时机制来解决同步问题,他加入了预备阶段,在执行任务的早期第二阶段准备,第三阶段提交之前,尽可能地发现问题
超时机制是一个默认机制,但仍有问题,比如说:我超时默认提交成功,但是这个服务实际是出现了异常,其他服务发生回滚,那么这样的情况下,还是会出现数据不一致。
所以即使使用了二阶段、三阶段提交,还是需要数据补偿的,需要最终一致性方案来兜底。这是不用他们的一个原因。
6.最终一致性解决方案 -CAP
(1)CAP 理论
无法三个都满足,但必须三个选两个满足,分区容错性是最基本的要求,
如果我们选择了一致性和分区容错性,那么网络问题就会导致不可用。
如果我们选择了可用性和分区一致性,那么数据同步过程就可能存在数据不一致。
(2)BASE 理论
在分布式系统中,允许损失一部分的一致性,通过一段时间的修复来保证数据的最终一致。
(3)传统的 CAP 理论并不完全正确
1) CAP 中的一致性和我们 ACID 里的一致性不一样,一致性 = 可线性化
方法A操作之后B操作,那么B操作的结果来看的话,认为A操作的结果是完成的。看起来数据只有一份,但是可以有多个数据副本。
2)CAP 的可用性和我们微服务的可用性不完全一样,因为我们微服务的可用性,一般会通过 SLA 来衡量
eg: 我们有两个数据中心,当两个机房的网络中断时,我们采用一致性和可用性,我们把另一个数据中心的服务给关闭掉,所有的读写都在一个中心,然后把用户的流量切到这个数据中心。这不就以为着网络中断就一定会造成系统停服!
多个数据中心,通过异步的方案,binlog 进行数据同步,很多时候不是因为网络的故障而是因为网络的延迟,绝大部分都是网络延迟导致了数据的不一致。


7.最终一致性解决方案 - TCC
三个:尝试,提交和撤销。
try尝试会做资源的检测和预留。
confirm 执行业务的提交操作。
cancel进行资源的回滚和补偿。
基本没用过,因为他对业务代码有一定的侵入性。他是个同步的方案,且会导致业务代码因引入这三个方法而变得不简洁。但是 TCC 仍有一些框架。
用到的话,要注意 TCC 的一些异常情况:
1)空回滚 在 try 操作下没有执行,就调用了第二阶段 cancel 撤销, 假如服务宕机了或网络异常,没有执行 try ,故障恢复之后,他会执行一个回滚。
2)幂等 多次提交,导致脏数据记录。
3)悬挂cancel 的操作比 try 快,先执行 cancel ,后执行 try,
场景如下: try 超时重试,导致 try 的执行周期比较晚,会在比较晚的节点执行。
解决方法: 我们引入一个事务表。我们把每一个 try, confirm, cancel 的操作都记录下来。
比如我们在调用 cancel 时,发现没有调用 try ,那么我们就不调用 cancel 方法了。
幂等也是这样,执行时先查看是否执行过,执行过了的我们就不执行了。
但是,会有一个并发安全的问题需要注意。

8.最终一致性解决方案 - 补偿机制
重试机制:固定时间,固定次数,比如 RocketMQ, 他默认是重试 3 次,但他最多可以重试 16 次。
为什么要有固定时间,因为 CPU 执行速度非常快,不设置重试时间,可能一秒内 16 次就都重试完了,增加了系统负载,意义也不大,1秒,3秒,7秒,1分钟,2分钟,1小时,2小时。
更新修复:自我修正,减少瞬时压力几十万条,可以用调度器;几千万条,就需要分时段,在每一个用户请求环节,分散瞬时压力。就内容分发场景,点赞,评论等社交场景,增加冗余表,把数据冗余出来。
自我修正:数据一致保证,不用定时任务,用户去请求文章,判断他的请求的周期是否超过更新时间,比如说超过24小时,异步刷新数据。只要有一个用户去请求,那么就会触发数据的刷新,这样其他用户就可以看到最新数据。但如果一直没有用户请求,这个数据不更新也没有什么关系。
定时机制:定时重试,定时核对。
数据核对:微服务下,DB 禁止直连,调接口时数据量特别大,接口会有限流,超过5000 接口就限流了,在加上网络抖动,这时数据请求就很不稳定。通过接口调用数百万数据非常不现实,所以一般会在这个域,通过同步机制,binlog -> kafka -> 事件广播 通过监听事件,把数据写到自己的域内。

9.最终一致性解决方案 - 可靠事件机制
如果采用自动应答机制,消息一定会丢失。

场景1:
服务 A 向服务 B 发送消息, 服务 B 收到之后自动应答,就告诉消息队列我已经收到消息了,你把持久化消息清除掉吧。结果 B 在进行消息消费的时候失败了,此时 服务B 已经无法重新获取消息了。 所以我们一定要开启手动应答,手动 ACK.
场景2:
双11 大促,把消息全部填过了,再通过 MQ 做一个消息的积压,然后慢慢地把消息消费掉。 但这个过程中有一个问题,服务 B 无法及时把消息消费掉,如果说周期特别长,比如说 RocketMQ 超过了两个小时,那么消息就会被记录到 MQ 的死信队列里去,那么这些消息就需要人工干预才能处理了。这些消息即时不丢,也不会重试了。对于服务 B 而言,这些消息看起来就已经丢了,因为我们没办法再消费了。
流程: 服务 A 将数据存入数据库中,然后把消息标识为待发送状态,紧接着服务 A 投递消息到消息队列,服务 B 消费消息成功,返回一个 ACK ; 同时服务 B 再往另一个消息队列中发送一个消息,服务 A 收到这个消息之后,在去数据库将数据设置成完成状态。

定时任务,扫描未投递成功的消息进行重新投递,3~ 5次之后,如果还没有投递成功,就需要进行人工干预了。
幂等性:单库建一个唯一索引,根据幂等字段来保证唯一性。幂等的核心,就是保证资源的唯一性。
数据量特别大,就需要分库分表,一般常见的方式有两种:
- 先查后插,需要注意到并发安全性问题,一主多子,一个主订单多个子订单,一般情况下多个子订单是同时创建的,那么这种情况下,就会有并发安全问题。我们需要加分布式锁来解决临界状态的并发安全问题。但需要注意一个问题,分布式锁有一个过期时间,比如 30 分钟,但比如我们重试的周期超过了 30 分钟,锁失效掉了,就还会出现并发安全问题。或加入状态机,通过状态机的状态约束,状态流转来保证唯一性。
业务场景:
我们是一个买家,我们在淘宝买了一个商品,然后觉得他不好,我们就去发起一个退款。那么退款,这个工单就会以售后工单的形式流转到买家,买家的客服就会去看这个单子,去看下单子的订单,定价信息,交易信息,退款理由,退款金额,看你个各种评论,各种风控,看完没问题,就把钱给你退 了。钱就到账了。
退款和自动化退款。自动化退款,基于强规则,退款规则,订单规则,比如7天无理由的,订单小于100 的,就自动退掉了。
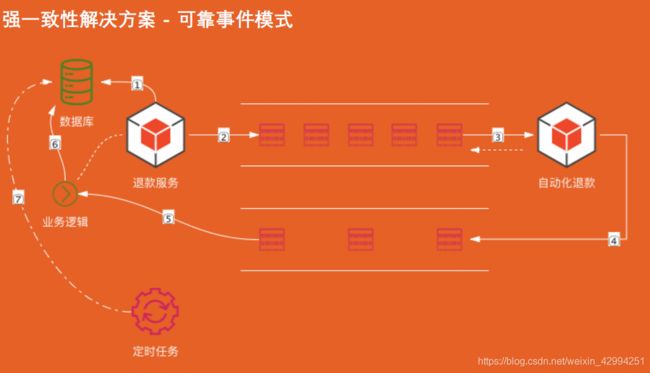
流程:用户发起退款服务后,退款服务会先写入本地数据库,然后持久化这笔退款,接着发送消息投递到消息队列。退款服务无需同步等待退款结果,他就可以继续做其他事情。退款成功后,自动化系统将退款成功的消息推入另一个消息队列,退款服务收到消息后,就会把该退款单设置成完成状态。
定时任务去数据库扫描未完成的退款工单,进行重试,最后失败的就需要进行人工干预了。
通过两个消息队列,正反向投递,保证消息的投递成功。
10.最终一致性解决方案 - RocketMQ 模式
这里有一个非常巧妙的设计,大家可以去学习一下。它其实是用来解决生产者发送消息与本地事务的原子性问题。换句话说,本地事务执行不成功,则不会发送消息。但有一个问题,本地事务执行成功,MQ 不一定能执行成功。本地事务就需要回滚。RocketMQ 实际上解决了这个问题,也是我们需要去学习的一点。
半投递状态机制。RocketMQ 先发送一个预执行消息到队列,去测试一下 MQ 的连通性,但是此时消息不执行。接着再去执行本地事务,本地事务执行成功后,在对预执行消息就行执行。如果 本地事务执行失败了,那么我们就需要对 RocketMQ 队列中的消息给删除掉。
需要注意:消息发到了 MQ ,但是由于一些限流,或者是服务的不可用,导致消息无法正常消费掉,或消息进入了死信队列,实际上我们的下游,还是不知道的。他是不可靠的,还是需要补偿模式保证最终一致性。

(免责声明:咖啡汪译文博客目的在于传递更多信息,不代表本人的观点和立场。文章内容仅供参考。)