深度学习与围棋:神经网络入门
本文主要内容
- 介绍人工神经网络的基础知识。
- 指导神经网络学习如何识别手写数字。
- 组合多个层来创建神经网络。
- 理解神经网络从数据中学习的原理。
- 从零开始实现一个简单的神经网络。
本章介绍人工神经网络(Artificial Neural Network,ANN)的核心概念。这类算法对现代深度学习至关重要。人工神经网络的历史可以追溯到20世纪40年代早期。历经数十年,它在许多领域的应用都取得了巨大成功,但其基本思想都保留了下来。
人工神经网络的核心理念,是从神经科学中汲取灵感,创造出一类与人们猜想的大脑工作方式类似的算法。其中特别地,我们采用神经元(neuron)的概念来作为人工神经网络的基础构件。多个神经元组合为不同的层(layer),不同层之间以特定的方式彼此连接(connect),从而组织成一个网络(network)。给定输入数据,神经元可以通过各层之间的连接逐层传输信息。如果信号足够强,我们说神经元会被激活(activate)。这样数据通过网络层层传播,到达最后一层,即输出层,并得到预测(prediction)结果。然后我们可以把这些预测与期望输出(expected output)进行比较,以计算预测的误差(error),神经网络可以利用它来进行学习,并改进未来的预测。
虽然由大脑结构启发的类比很有用,但我们不想在这里过度强调它。我们确实对大脑的视觉皮层知之甚多,但这种类比有时会产生误导,甚至引发错误的理解。我们认为最好将人工神经网络看作是试图揭示生物体的学习机制的指导原则,就像飞机利用了空气动力学原理,但并不会完全复制鸟类的功能。
为了使本章内容更为具体,我们提供了一个从零开始实现的基本神经网络。我们将应用这个神经网络来解决一个光学字符识别(Optical Character Recognition,OCR)领域的问题,即让计算机预测图像中的手写数字是哪一个。
在我们的OCR数据集中,每个图像都由像素网格组成,因此必须分析像素之间的空间关系才能确定它所代表的数字。围棋等众多棋类游戏也是在网格上下棋的,也必须考虑棋盘上的空间关系才能选择良好的动作。因此我们可能会期待OCR的机器学习技术也能够应用到围棋之类的游戏中。事实证明,它们确实有效。第6章至第8章将介绍如何把这些方法应用于围棋游戏。
本章会尽量少涉及数学内容。如果读者对线性代数、微积分和概率论的基础知识不够熟悉,或者想要一些简短实用的温习材料,我们建议先阅读附录A。此外,附录B对神经网络学习过程中比较困难的部分(即反向传播算法)有详细的数学介绍。如果读者已经对神经网络有所了解,但还从未实现过神经网络代码,我们建议你立即跳到5.5节。如果你已熟悉神经网络的实现,请直接进入第6章,了解如何用神经网络来预测第4章中生成的棋局中的动作。
5.1 一个简单的用例:手写数字分类
在详细介绍神经网络之前,让我们先认识一个具体用例。在本章中,我们将构建一个可以良好地预测手写数字图像的应用,其准确率约为95%。值得注意的是,只需将图像的像素值发送给神经网络就可完成所有操作,这个算法能够自己学会如何抽取数字的结构信息。
要实现这个目标,我们将采用改进版美国国家标准与技术研究所(Modified National Institute of Standards and Technology,MNIST)手写数字数据集。这是一个经过深入研究的数据集,它在深度学习领域的地位相当于果蝇在生物研究界的地位。
在本章中,我们将使用NumPy库来处理底层数学运算。NumPy是Python机器学习和科学计算的行业标准,本书的其余部分也都会使用它。在尝试运行本章的代码示例之前,读者应当先通过惯用的包管理器来安装NumPy。例如,如果使用的是pip,可以在shell里运行pip install numpy来安装它;如果使用的是Conda,可以运行conda install numpy。
5.1.1 MNIST手写数字数据集
MNIST数据集由60 000个图像组成,所有图像尺寸均为28像素 × 28像素。图5-1展示了这个数据集的几个样本示例。对人类来说,识别出示例中的大多数图像都是小菜一碟。例如,人可以轻松地读出第一行的数字7、5、3、9、3、0等,但数据集中也有少数图像连人类都难以判断。例如,图 5-1 中第5行的第4张图片,很难分辨到底是4还是9。

图5-1 取自MNIST手写数字数据集的一些样本。这是光学字符识别领域中经过充分研究的一个数据集
MNIST中每个图像都带有标签注释,其内容是一个0~9的数字,用来表示图像所描绘的真实数字值。
在查看具体数据之前,需要先加载它。这套数据可以在本书的GitHub代码库中找到,放在文件夹dlgo/nn中名为mnist.pkl.gz的文件里。
这个文件夹还包含了本章将要编写的全部代码。但和以往一样,我们建议读者按照本章的内容流程从零开始编写代码。当然,你也可以尝试直接运行GitHub代码库中的代码。
5.1.2 MNIST数据的预处理
由于这个数据集中的标签是0~9的整数,我们可以使用一种称为独热编码(one-hot encoding)的技术将标签值转换为长度为10的向量,如代码清单5-1所示。例如,数字1可以转换为一个长度为10的向量,其中槽位1的值为1,而其他9个槽位的值都是0。独热编码是一种很有用的表示方式,它在各种机器学习场景中都有广泛应用。用向量中的第一个槽位来表示标签1,这种方式可以让神经网络之类的算法更容易区分不同的标签。使用独热编码,数字2表示为[0,0,1,0,0,0,0,0,0,0]。
代码清单5-1 用独热编码对MNIST标签进行编码
import six.moves.cPickle as pickle
import gzip
import numpy as np
def encode_label(j): ⇽--- 将索引编码为长度为10的向量
e = np.zeros((10, 1))
e[j] = 1.0
return e独热编码的优点是每个数字都有自己的槽位,这样就可以使用神经网络为单个输入图像输出每个槽位的概率(probability),这在之后的计算中很有用处。
检查文件mnist.pkl.gz的内容,我们可以发现它包含了3个可用的数据池:训练数据、验证数据和测试数据。回忆第1章,我们使用训练数据来训练或拟合机器学习算法,使用测试数据来评估算法的学习效果。验证数据可用于调整和验证算法的配置,在本章中可以先忽略。
MNIST数据集中的图像是二维的,高度和宽度均为28像素。图像数据可以加载成维度为784(即28×28)的特征向量(feature vector)。这里我们完全丢弃了图像结构,只把像素作为向量。这个向量的每个值可以取0或1,其中0表示白色,1表示黑色,如代码清单5-2所示。
代码清单5-2 将MNIST数据转换变形并加载训练数据与测试数据
def shape_data(data):
features = [np.reshape(x, (784, 1)) for x in data[0]] ⇽--- 将输入图像展平成维度为784的特征向量
labels = [encode_label(y) for y in data[1]] ⇽--- 所有的标签都用独热编码进行编码
return zip(features, labels) ⇽--- 创建特征标签对
def load_data():
with gzip.open('mnist.pkl.gz', 'rb') as f:
train_data, validation_data, test_data = pickle.load(f) ⇽--- 解压并加载MNIST数据,得到3个数据集
return shape_data(train_data), shape_data(test_data) ⇽--- 忽略验证数据,将其他两个数据集转换变形这样我们就得到了一个表示MNIST数据集的简单形式:特征和标签都被编码为向量。接下来的任务是设计一种机制来学习如何准确地将特征映射到标签上。具体而言,我们需要设计一种算法来学习训练数据的特征与标签,并根据测试数据给出的特征预测出对应的标签。
我们在下一节可以看到,神经网络可以很好地完成这项工作。我们先讨论一种简单的方法来揭示这类应用所需要解决的共同问题。识别数字对人类来说是一项相对简单的任务,但我们很难精确地解释人们如何做到这一点,也很难解释我们是如何了解到我们所知的。这种现象,即知道如何做,却无法解释清楚为什么知道,被称为波拉尼悖论(Polanyi’s paradox)。这一点导致我们想向计算机明确描述如何解决这个问题变得特别困难。
在这个应用中扮演关键角色的重要问题是模式识别(pattern recognition),即每个手写数字都有着和它的数字原型有关的特征。例如,0大致是椭圆形的;又如,在许多国家中1用一条简单的竖线表示。根据这些简单的特征逻辑,我们可以通过相互比较手写数字,对手写数字进行粗略地分类:给定一个数字8的图像,那么与其他数字相比,它应该更接近于8的平均图像。代码清单5-3中的average_digit函数可以计算一个数字的平均图像。
代码清单5-3 计算相同数字的所有图形的平均值
import numpy as np
from dlgo.nn.load_mnist import load_data
from dlgo.nn.layers import sigmoid_double
def average_digit(data, digit): ⇽--- 为数据集中所有代表指定数字的样本计算平均值
filtered_data = [x[0] for x in data if np.argmax(x[1]) == digit]
filtered_array = np.asarray(filtered_data)
return np.average(filtered_array, axis=0)
train, test = load_data()
avg_eight = average_digit(train, 8) ⇽--- 把数字8的平均值作为一个简单模型的参数,用来检测数字8训练集中的数字8的平均图像是什么样的?图5-2给出了答案。

图5-2 这是MNIST训练集中的手写数字8的平均图像。通常来说,将数百个不同图像取平均值,会得到一堆无法识别的斑点,但本例中的这个平均图像看起来仍然非常像数字8
由于手写的数字个体之间的差距可能很大,因此平均图像会显得有点儿模糊。图中的情况确实符合这个预期,但它的形状仍然能明显看出是数字8。也许我们可以利用它来识别数据集中的其他数字8?代码清单5-4中的代码可以用来计算数字8的平均图像,并展示出图5-2所示的图像。
代码清单5-4 计算并展示训练集中数字8的平均图像
from matplotlib import pyplot as plt
img = (np.reshape(avg_eight, (28, 28)))
plt.imshow(img)
plt.show()MNIST的训练集中数字8的平均值avg_eight包含了数字8在图像中如何呈现的大量相关信息。可以使用avg_eight作为一个简单模型的参数来判断某个表示数字的输入向量x是否为8。在神经网络的场景中,我们在讨论参数的时候,经常说权重,这时候就可以把avg_eight当作权重来用。
为方便起见,可以将这个向量进行转置并得到W = np.transpose(avg_eight)。然后计算W和x的点积,它会将W和x的像素值逐对相乘,并将所有784个结果值相加。如果我们的想法是正确的,并且如果x确实是数字8,那么x的像素在与W相同的地方应该有差不多的色调值。相反,如果x不是数字8,那么它与W的重叠就会比较少。让我们用几个例子检验这个假设,如代码清单5-5所示。
代码清单5-5 使用点积计算一个数字图像与权重的接近程度
x_3 = train[2][0] ⇽--- 下标为2的训练样本是数字4
x_18 = train[17][0] ⇽--- 下标为17的训练样本是数字8
W = np.transpose(avg_eight)
np.dot(W, x_3) ⇽--- 这一项的计算结果是20.1
np.dot(W, x_18) ⇽--- 这一项的计算结果要大得多,约为54.2我们选取两个MNIST样本,其中一个代表数字4,另一个代表数字8,并计算它们与权重W的点积。可以看到,数字8的点积结果为54.2,远远高于数字4的点积结果20.1。看起来我们走对路了。那么,点积结果是多少的时候应当判断为数字8呢?理论上两个向量的点积可以算出任意实数值。我们可以把点积的输出值进行转换(transform)并映射到输出范围为[0, 1]的某个值,然后就可以试着设置一个如0.5这样的判断阈值,对于高于阈值的结果就可以判定为数字8了。
要进行转换,可以使用sigmoid函数。sigmoid函数通常用σ来表示。对于一个实数x,sigmoid函数定义如下:
![]()
图5-3展示了这个函数的大致形状,读者可以有一些直观感受。
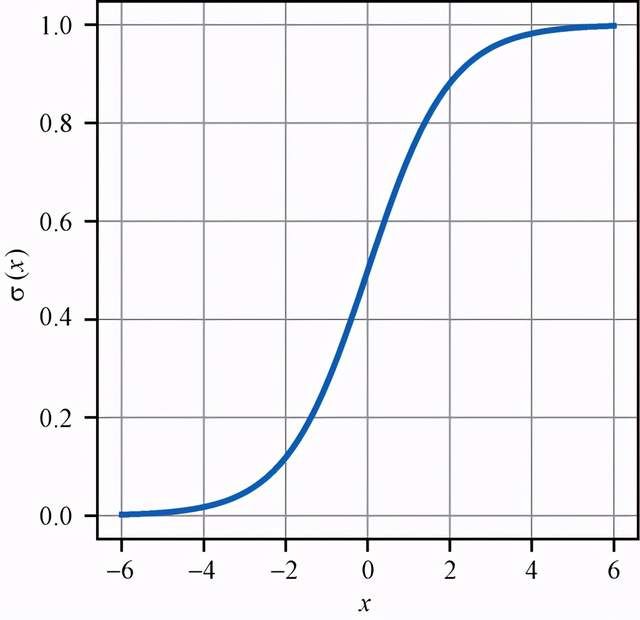
图5-3 绘制sigmoid函数的图形。sigmoid函数将实数值映射到[0, 1]的范围内。在0附近, 它的斜率相当陡峭;而随着参数值正向增大或负向减小,曲线逐渐变得平缓
接下来,在将sigmoid函数应用到点积的输出之前,让我们先在Python中编写sigmoid函数,如代码清单5-6所示。
代码清单5-6 为double类型和向量类型的数据实现简单的sigmoid函数
def sigmoid_double(x):
return 1.0 / (1.0 + np.exp(-x))
def sigmoid(z):
return np.vectorize(sigmoid_double)(z)注意,首先要写一个接收double类型参数的函数sigmoid_double,然后再利用它来实现针对向量值的sigmoid函数,这个函数会在本章中多次应用。在实际计算之前请注意,2的sigmoid函数结果已经非常接近1,因此对于先前计算的两个样本,sigmoid(54.2)和sigmoid(20.1),就几乎无法区分了。要解决这个问题,可以将点积的输出朝0偏移(shifting)。我们把执行一次这样的偏移操作称为应用一个偏差项(bias term),通常写作b。从样本中可以计算出,偏差项的一个比较理想的估计值是b = −45。有了权重和偏差项,现在就可以按照代码清单5-7所示的方法来计算模型的预测值(prediction)了。
代码清单5-7 使用点积和sigmoid函数,根据权重与偏差计算出预测值
def predict(x, W, b): ⇽--- 通过对np.dot(W, x)+b的输出应用sigmoid函数来计算出一个简单预测值
return sigmoid_double(np.dot(W, x) + b)
b = -45 ⇽--- 根据之前计算过的示例,将偏差项设置为−45
print(predict(x_3, W, b)) ⇽--- 这个数字4的示例,其预测值接近0
print(predict(x_18, W, b)) ⇽--- 这个数字8的示例,其预测值是0.96。看来这个启发式规则是有效果的从上面两个示例x_3和x_18中,我们得到了令人满意的结果。前者的预测值几乎为0,而后者的预测值接近于1。我们把这个将W的输入向量x映射到σ(Wx + b)并得到与x维度相同的向量的过程,称为对率回归(logistic regression)。图5-4展示了这个算法用于维度为4的向量的示例。
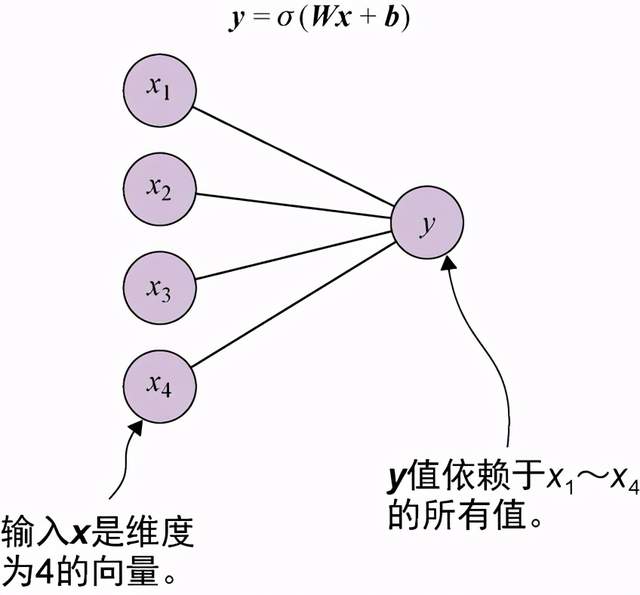
图5-4 对率回归的示例,将维度为4的输入向量x映射到0~1的输出值y。本图表明输出y依赖于输入向量x中的所有4个值
为了更好地了解这个过程的工作效果,让我们用它来计算所有训练样本和测试样本的预测值。如前所述,我们可以定义一个截断点,或决策阈值(decision threshold),用来决定预测值是否算作数字8。我们可以选择准确率(accuracy)作为评估指标。准确率就是所有的预测结果中预测正确的比率,如代码清单5-8所示。
代码清单5-8 评估使用了决策阈值的模型预测
def evaluate(data, digit, threshold, W, b): ⇽--- 作为评估指标,我们可以选择准确率,即所有预测结果中预测正确的比率
total_samples = 1.0 * len(data)
correct_predictions = 0
for x in data:
if predict(x[0], W, b) > threshold and np.argmax(x[1]) == digit: ⇽--- 将数字8的实例预测为8,是一次正确的预测
correct_predictions += 1
if predict(x[0], W, b) <= threshold and np.argmax(x[1]) != digit: ⇽--- 如果预测值低于设定的阈值,并且样本也确实不是数字8,那么这也是一次正确的预测
correct_predictions += 1
return correct_predictions / total_samples让我们使用这个评估函数来评估3个数据集的预测质量:训练集、测试集和测试集中所有数字8的集合。和前面一样,这里将决策阈值设为0.5,权重为W,偏差项为b,如代码清单5-9所示。
代码清单5-9 计算3个数据集的预测准确率
evaluate(data=train, digit=8, threshold=0.5, W=W, b=b) ⇽--- 这个简单模型在训练数据上的准确率为78%(0.7814)
evaluate(data=test, digit=8, threshold=0.5, W=W, b=b) ⇽--- 在测试数据上的准确率稍低,为77%(0.774 9)
eight_test = [x for x in test if np.argmax(x[1]) == 8]
evaluate(data=eight_test, digit=8, threshold=0.5, W=W, b=b) ⇽--- 只对测试集中的数字8的集合进行评估,则准确率仅为67%(0.666 3)可以看到,使用训练集的准确率最高,约为78%。这并不奇怪,因为我们的模型就是通过在训练集上调校(calibrate)而得出的。但是对训练集进行评估是没有意义的,因为这样做无法得知算法的泛用效果(generalize),即对没有见过的数据集的执行效果。在测试数据上的表现接近于在训练数据上的表现,准确率约为77%。而最后一个准确率最值得注意:在所有数字8的测试集中,我们只达到了约66%的准确率,这相当于每遇到3个新数字8我们只能猜对其中2个。这个结果作为一个基线还可以接受,但远远不是能够达到的最好结果。那么到底哪里出了问题呢?又有哪些地方可以做得更好?
- 模型现在只能区分特定数字(此处为数字8)与其他所有数字。由于训练集和测试集中每个数字的图像数量分布是均衡的(balanced),数字8的样本大约只占10%。因此,只要用一个始终预测数字为0的简单模型,我们就能得到约90%的准确率。在分析解决分类问题的时候,需要特别注意这种分类不均衡(class imbalance)的情况。考虑到这一点,模型在测试数据集上77%的准确率就不再显得优秀了。我们需要定义一个可以准确预测全部10个数字的模型。
- 模型参数相当小。对于有数千种不同风格的手写图像集合,我们采用的权重集大小却只和单个图像相同。想要用这么小的模型来捕获这么多样的手写风格变化是不现实的。必须找到一类算法,它们可以有效地使用更多参数来捕获数据中的可能变化。
- 对于某个给定的预测值,我们只简单地选取了一个阈值来判定该数字是否为8,而并没有使用预测的具体值来评估模型的质量。例如,一个预测值为0.95的正确预测,肯定比预测值为0.51的预测结果更有说服力。必须找到合适的形式来表示预测值与真实输出之间的接近程度。
- 这个模型的参数是通过直觉的引导制作而出的。虽然作为第一次尝试这可能是一个不错的结果,但机器学习真正的优势在于不需要把人们对数据的想法强加到算法中,而是让算法自己去数据中学习。每当模型做出正确预测时,都需要强化这种行为,而每当输出是错误的时候,也需要相应地调整模型。换句话说,需要设计一种能够根据训练数据的预测效果来更新模型参数的机制。
虽然我们对这个简单的应用和前面构建的朴素模型只进行了简短而粗略的讨论,但读者应当已经能感觉到神经网络的很多特征了。在5.2节中,我们会利用本节示例所建立的直觉,通过逐一解决上面提到的4个问题来正式进入神经网络话题的探讨。
5.2 神经网络基础
我们应当如何改进OCR模型呢?前面的介绍已经有所暗示,神经网络可以在这类任务上做得非常出色,远远比我们制作的模型要好得多。但制作的模型能够帮助我们理解构建神经网络的关键概念。本节就用神经网络的语言来重新描述5.1节介绍的模型。
5.2.1 将对率回归描述为简单的神经网络
在5.1节中,我们实现了用于二元分类(binary classification)的对率回归算法。简而言之,我们用一个特征向量x来表示一个数据样本,作为算法的输入,接着将它乘以权重矩阵W,然后再添加偏差项b。要得到一个0~1的预测值y,可以对它应用sigmoid函数:y = σ(Wx + b)。
这里需要注意几点。首先特征向量x可以看成是神经元(有时称为一个单元,即unit)的集合,它通过W和b与y相连。这个关系我们已经在图5-4中看到了。另外,sigmoid可以看作一个激活函数,因为这个函数接收Wx + b的计算结果,并将它映射到[0, 1]。如果将结果这样解释:当结果值接近1时,表示神经元y被激活;当结果值接近0时,则表示神经元不被激活,那么我们可以把这个算法设置看作是人工神经网络的一个简单示例。
5.2.2 具有多个输出维度的神经网络
在5.1节的用例中,我们将手写数字的识别问题简化为一个二元分类问题:区分数字8与其他数字。但是我们真正感兴趣的是预测所有10个分类,每个分类代表1个数字。从形式上说,要实现这一点并不困难,只要改变y、W和b所表示的内容即可。换句话说,需要变更模型的输出、权重与偏差项。
首先,我们把y改为维度为10的向量:每个维度的值代表其中一个数字的可能性。
接下来让我们相应地调整权重和偏差项。W之前是一个长度为784的向量,现在我们可以将它改为尺寸为(10, 784)的矩阵。这样就可以对W和输入向量x进行矩阵乘法,即Wx,其结果将是维度为10的向量。接着如果将偏差项设为维度为10的向量,就可以将其与Wx相加了。最后请注意,对于一个向量z,我们可以通过对它的每一个元素应用sigmoid函数来计算整个向量的sigmoid值:

图5-5展示了这个稍作修改的设置,示例中有4个输入神经元和2个输出神经元。
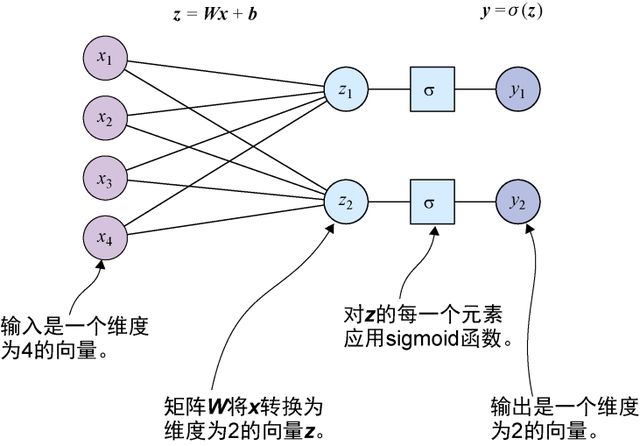
图5-5 在这个简单的神经网络中,4个输入神经元连接到2个输出神经元:先将输入向量与一个2 × 4的矩阵相乘,再与一个二维的偏差项相加,最后对得出结果的每个元素应用sigmoid函数,从而得到输出
那么我们的更改有什么用呢?之前我们是将输入向量x映射到一个单值y,而现在输出y变成了一个向量。这样我们就可以多次进行这种向量到向量的转换,从而构建出一个更复杂的神经网络,我们称之为前馈网络(feed-forward network)。
5.3 前馈网络
让我们快速回顾一下我们在5.2节中所做的工作。用更抽象的话来说,我们执行了以下两个步骤。
(1)我们从一个输入神经元向量x开始,并对它应用了一个简单的变换,即z = Wx + b。在线性代数的语言中,这种变换称为仿射线性变换(affine linear transformation)。为简化描述,这里我们用z作为中间变量来代替变换的结果。
(2)我们应用了一个激活函数,即sigmoid函数y = σ(z)来获得输出神经元y。应用σ的结果可以给出y的激活程度。
前馈网络的关键理念在于这个过程可以迭代重复应用,从而可以多次应用上面描述的两个步骤组成的简单构建块。这些构建块就是我们所谓的层。改用这个术语的话,我们可以说:通过堆叠(stack)许多层来组成的一个多层神经网络(multilayer neural network)。下面我们修改前面的例子,再多引入一层。现在需要执行以下两个步骤。
(1)从输入向量x开始,计算z1 = W1x + b1。
(2)从中间结果z1开始,可以计算输出结果y,公式为y = W2z1 + b2。
注意,此处使用上标来表示向量所在的层,用下标来表示向量或矩阵中的位置。图5-6展示了一个包含两层而不是单层的网络示例。
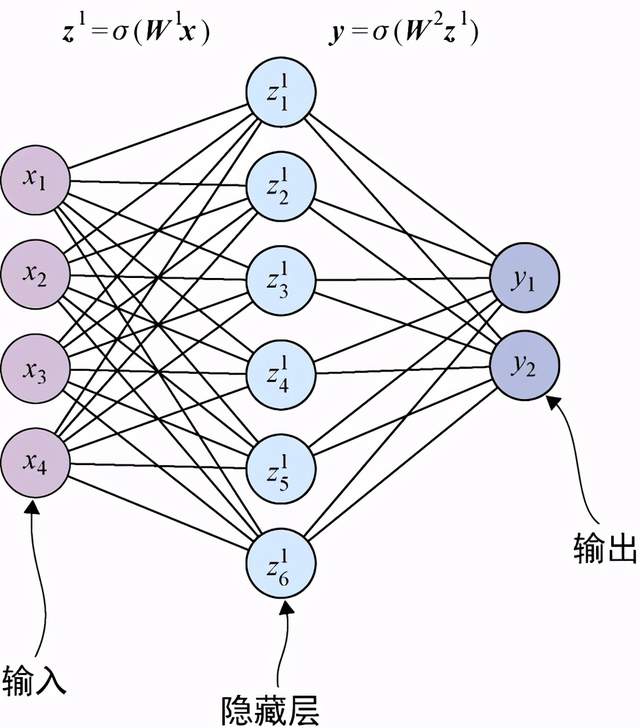
图5-6 一个两层人工神经网络。输入神经元x连接到一组中间单元z,后者再连接到输出神经元y
此时有一点已经很明显了:堆叠的层数并没有特定的限制。我们可以堆叠很多层。此外,激活函数也不必总是用sigmoid函数。实际上可供选择的激活函数非常多,我们将在第6章介绍其中的几个。我们将网络中所有层中的函数按顺序应用于一个或多个数据点的过程,称为一个前向传递(forward pass)。之所以称为前向传递,是因为在这个过程中,数据总是按照输入到输出的方向(在图5-6中即从左到右)向前流动而从不回退。
采用这几个术语,我们可以用图5-7来表示一个包含3层的普通前馈网络。
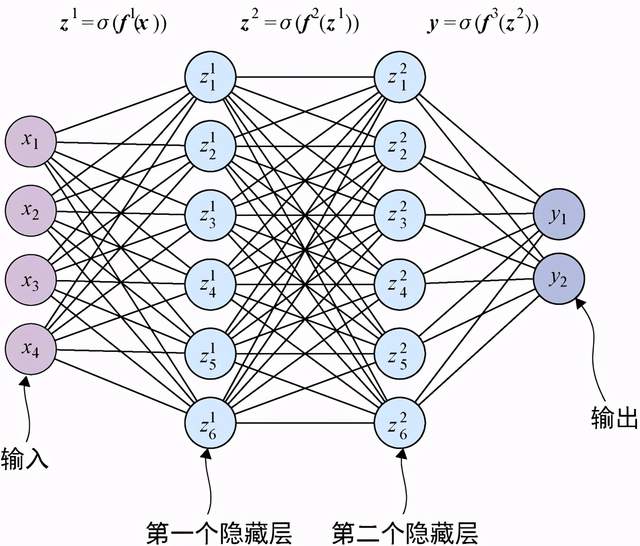
图5-7 3层前馈神经网络。在定义神经网络时,层数没有限制,每层的神经元数量也没有限制
回顾一下我们到目前为止所学的知识。把前面提到过的所有概念集合到一起,列成一个简明的列表。
- 顺序神经网络是一种将特征(或输入神经元)x映射到预测(或输出神经元)y的结构。我们可以按照顺序逐个堆叠一层层简单函数来构建顺序神经网络。
- 神经网络的每一层都是一个将给定输入映射到输出的公式。用一批数据计算一层的输出的过程,称为一趟前向传递。类似地,要计算整个顺序神经网络的前向传递,可以从输入向量开始按顺序计算每一层的前向传递来完成。
- sigmoid函数是一个激活函数,它接受实值神经元的向量并对它们进行激活,即映射到范围[0, 1]里的一个值。我们把接近1的数值算作激活。
- 给定权重矩阵W和偏差项b,应用仿射线性变换Wx + b来构成神经网络的一层。这一层通常称为稠密层(dense layer)或全连接层(fully connected layer)。后面我们将统一用稠密层来称呼它。
- 根据实现的不同,稠密层可以内嵌激活函数,也可以不内嵌。前者的意思是,可以把σ(Wx + b)整体作为单独的一层,而不仅仅是其中的仿射线性变换。后者的意思是,也可以把激活函数看作独立于稠密层之外的单独一层。在之后的实现中,我们采用后者。总的来说,在分析如何将函数进行拆分并重组为逻辑单元的过程中,是否将激活函数内嵌到稠密层中其实并没有本质区别,只是角度不同而已。
- 前馈神经网络是由稠密层和激活函数所组成的顺序网络。出于历史原因,这种架构也称为多层感知机(multilayer perceptron,MLP)。但本书并没有足够空间来讨论这个命名的历史。
- 所有既不是输入又不是输出的神经元都称为隐藏单元(hidden unit)。相对应地,输入和输出神经元称为可见单元(visible unit)。这么称呼是因为隐藏单元是属于网络内部的,而可见的单元则是从网络外直接可观察的。这么说似乎有点儿牵强,因为我们通常都能够访问神经网络系统的任何部分,但了解这个术语并没有坏处。同理,输入和输出之间的层称为隐藏层,所有超过两层的顺序网络都至少有一个隐藏层。
- 如果不做特殊说明,我们统一用x代表网络的输入,用y代表网络的输出;有时候会用上标来表示正在处理的样本。
堆叠许多层而构建的、具有大量隐藏层的大型网络,称为深度神经网络(deep neural network),由此才有了深度学习这个说法。
非顺序神经网络
在这个阶段,读者只需要关注顺序神经网络。这种网络的所有层可以形成一个序列。在顺序神经网络中,从输入开始,每个后续的(隐藏)层都恰好有一个前导和一个后继,最后以输出层结束。对于将深度学习应用于围棋这个需求,顺序神经网络就足以涵盖所有需要了。
通常来说,神经网络理论也允许任意非顺序的体系结构。例如,在某些应用中,将两层的输出连接或相加(这样会合并之前的两层或多层)也是有道理的。在这种情况下,多个输入将会合并,最后只得到一个输出。
而在其他应用中,将一个输入拆分成多个输出也可能很有用。总而言之,层可以具有多个输入和输出。我们将在第11章和第12章分别介绍多输入和多输出网络。
具有l层的多层感知机的配置可以通过权重集(W = W1,…, Wl)、(偏差集b = b1,…, bl),以及为每一层选择的激活函数集来完全描述。但我们仍然缺少一个学习数据以及更新参数的重要素材——损失函数,以及如何优化它。
本文截选自《深度学习与围棋》

这是一本深入浅出且极富趣味的深度学习入门书。本书选取深度学**年来最重大的突破之一 AlphaGo,将其背后的技术和原理娓娓道来,并配合一套基于 BetaGo 的开源代码,带领读者从零开始一步步实现自己的“AlphaGo”。本书侧重实践,深入浅出,庖丁解牛般地将深度学习和AlphaGo这样深奥的话题变得平易近人、触手可及,内容非常精彩。
全书共分为3个部分:第一部分介绍机器学习和围棋的基础知识,并构建一个最简围棋机器人,作为后面章节内容的基础;第二部分分层次深入介绍AlphaGo背后的机器学习和深度学习技术,包括树搜索、神经网络、深度学习机器人和强化学习,以及强化学习的几个高级技巧,包括策略梯度、价值评估方法、演员-评价方法 3 类技术;第三部分将前面两部分准备好的知识集成到一起,并最终引导读者实现自己的AlphaGo,以及改进版AlphaGo Zero。读完本书之后,读者会对深度学习这个学科以及AlphaGo的技术细节有非常全面的了解,为进一步深入钻研AI理论、拓展AI应用打下良好基础。
本书不要求读者对AI或围棋有任何了解,只需要了解基本的Python语法以及基础的线性代数和微积分知识。