.pkl文件_用pathlib进行Python中的文件路径处理
本文介绍Python中的文件路径处理方法,从字符串连接、os.path.join()到Python3中处理文件路径的简单方法:pathlib。
1. 通过字符串连接
import pandas as pdparent_path = 'parent_path/'target_path = 'target_path/'target_file = 'target.csv'full_path = parent_path + target_path + target_filedf = pd.read_csv(full_path)这样的方法很简陋,跨平台可能会出现问题,所以不推荐使用。因为在linux和Windows上路径的分隔符是不一样的。比如下面代码在Windows上运行OK,但是在Linux或者Mac上就会报错。
import pandas as pdparent_path = 'parent_path\\'target_path = 'target_path\\'target_file = 'target.csv'full_path = parent_path + target_path + target_filedf = pd.read_csv(full_path)2. os.path.join()
这是在Python中常用的一种路径拼接方式,支持跨平台。缺点就是语法较为冗长,对于多个路径的拼接,需要把每个路径的字符串传入os.path.join(),这样也不够直观。
import pandas as pdimport os parent_path = 'parent_path'target_path = 'target_path'target_file = 'target.csv'full_path = os.path.join(parent_path,target_path,target_file)df = pd.read_csv(full_path)3. pathlib
Python 3.4引入了更好的路径处理方式:pathlib!支持不同的操作系统。我们只需要新建一个Path()对象,将路径或者文件传入,然后用/将它们连接即可,pathlib会帮我们做系统判断。
import pandas as pdfrom pathlib import Pathfull_path = Path(a)/b/cdf = pd.read_csv(full_path)是不是特别简洁?相比于os.path.join()更加直观。而且也不需要反复的写os.path.join()了。
更多的用法:
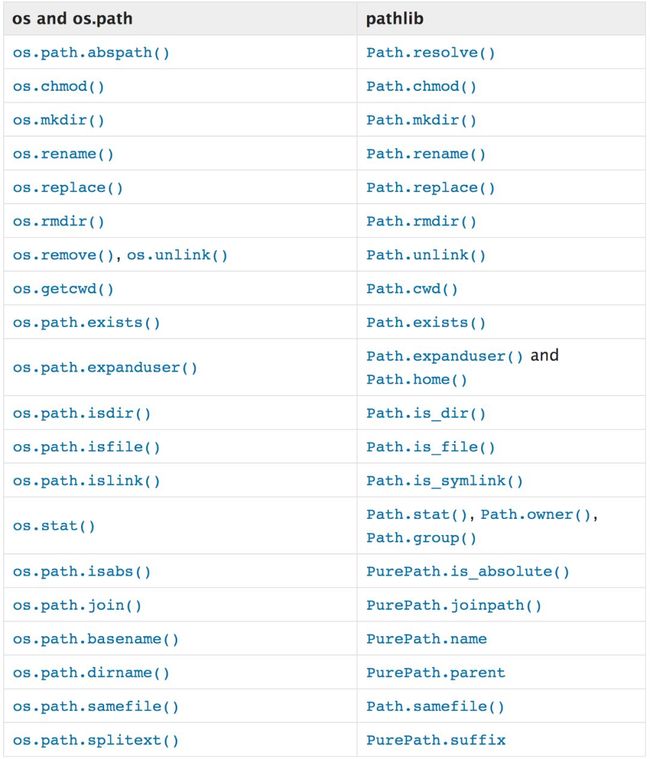
from pathlib import Path# 当前工作路径:Path.cwd()# PosixPath('/Users/test')# home路径Path.home()# PosixPath('/Users/test')# 列出当前目录的子目录:p = Path('.')[x for x in p.iterdir() if x.is_dir()]p.iterdir() # 当路径指向一个目录时,产生该路径下的对象的路径# 将路径绝对化p.resolve()# 列出当前目录下所有的`csv`文件:list(p.glob('**/*.csv'))# 查看路径是否存在a = Path('data/data2/Iris.csv')a.exists() # Trueb = Path('data/data2/NoIris.csv')b.exists() # False# 判断是否为文件夹a.is_dir() # Falsep.is_dir() # Truea.is_dir() # Truep.is_file() # False# 读取文件内容a.read_text()# 获取文件名和后缀print(a.name)# prints "Iris.csv"print(a.suffix)# prints ".csv"# 分离路径 a.parts # ('data', 'data2', 'Iris.csv')# 修改目录权限p.chmod(777)# 删除目录path_to_remove = Path('to_remove')path_to_remove.rmdir()pathlib与os的一些对应关系:
例子:获取MNIST data
from pathlib import Pathimport requestsimport pickleimport gzipDATA_PATH = Path("data")PATH = DATA_PATH / "mnist"PATH.mkdir(parents=True, exist_ok=True)URL = "http://deeplearning.net/data/mnist/"FILENAME = "mnist.pkl.gz"if not (PATH / FILENAME).exists(): content = requests.get(URL + FILENAME).content (PATH / FILENAME).open("wb").write(content)with gzip.open((PATH / FILENAME).as_posix(), "rb") as f: ((x_train, y_train), (x_valid, y_valid), _) = pickle.load(f, encoding="latin-1")References
[1] pathlib: https://docs.python.org/3/library/pathlib.html[2] Python 3's pathlib Module: Taming the File System: https://realpython.com/python-pathlib/[3] deal with paths: https://medium.com/@ageitgey/python-3-quick-tip-the-easy-way-to-deal-with-file-paths-on-windows-mac-and-linux-11a072b58d5f