用于视觉问答的关系感知图注意力网络模型《Relation-Aware Graph Attention Network for Visual Question Answering》
目录
一、文献摘要介绍
二、网络框架介绍
三、实验分析
四、结论
本文有点长,请耐心阅读,定会有收货。如有不足,欢迎交流, 另附:论文下载地址
一、文献摘要介绍
In order to answer semantically-complicated questions about an image, a Visual Question Answering (VQA) model needs to fully understand the visual scene in the image, especially the interactive dynamics between different objects. We propose a Relation-aware Graph Attention Network (ReGAT), which encodes each image into a graph and models multi-type inter-object relations via a graph attention mechanism, to learn question-adaptive relation representations. Two types of visual object relations are explored: (i) Explicit Relations that represent geometric positions and semantic interactions between objects; and (ii) Implicit Relations that capture the hidden dynamics between image regions. Experiments demonstrate that ReGAT outperforms prior state-of-the-art approaches on both VQA 2.0 and VQA-CP v2 datasets. We further show that ReGAT is compatible to existing VQA architectures, and can be used as a generic relation encoder to boost the model performance for VQA.
作者认为视觉问答模型需要完全理解图像中的视觉场景,尤其是不同对象之间的动态交互。为此提出了一种关系感知图注意力网络(ReGAT),该网络将每个图像编码成一个图,并通过图注意力机制对多种类型的对象间关系进行建模,以学习自适应问题的关系表示。实验表明,ReGAT优于现有的技术,并且可以用作通用的关系编码器以提高VQA的模型性能。
二、网络框架介绍
下图展示了作者提出的Relation-Aware Graph Attention Network(ReGAT)的整体流程,使用Faster R-CNN来检测一组目标区域,然后将这些区域级别的特征输入到不同的关系编码器中,以学习关系感知的问题自适应视觉特征,它将与问题表示法相结合来预测答案。
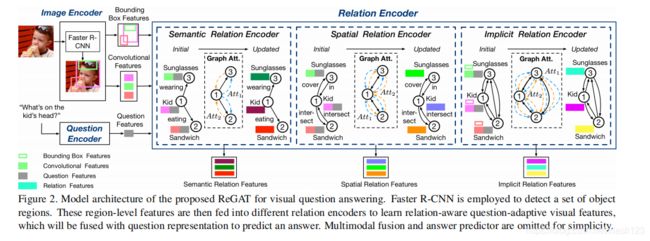
该模型同时考虑了显式关系(语义关系和空间关系)和隐式关系,提出的关系编码器,通过图注意力获取问题自适应对象之间的交互,得到的特征利用双线性多模态的融合方法进行融合,最后权衡显示关系和隐式关系的预测概率,以进行答案的预测。下面进行详细分析该框架。
2.1Graph Construction
1)Fully-connected Relation Graph
通过把图像中的每个物体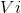 看作一个顶点,我们可以构造一个完全连通的无向图
看作一个顶点,我们可以构造一个完全连通的无向图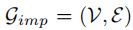 ,其中
,其中 是
是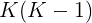 边的集合。每个边代表两个对象之间的隐式关系,它可以通过图的注意力分配给每个边的学习权重来反映。无需任何先验知识即可学习所有权重,我们将基于该图的关系编码器命名为
边的集合。每个边代表两个对象之间的隐式关系,它可以通过图的注意力分配给每个边的学习权重来反映。无需任何先验知识即可学习所有权重,我们将基于该图的关系编码器命名为![]() 隐式关系编码器。
隐式关系编码器。
2)Pruned Graph with Prior Knowledge
另一方面,如果顶点之间存在显式关系,则可以很容易地通过修剪不存在相应显示关系的边,将完全连通图![]() 转换为显式关系图。对于每对对象
转换为显式关系图。对于每对对象  ,
,  , 如果<-
, 如果<- ->是有效的关系,则从 到 创建一条边,边标签为。此外,我们为每个对象节点 指定一个自循环边,并将该边标记为与从 到 创建一条边标签相同。这样,图形变得稀疏,并且每个边对图像中的一个对象间(inter-object)关系的先验知识进行编码。我们将基于此图的关系编码器命名为显式关系编码器。
->是有效的关系,则从 到 创建一条边,边标签为。此外,我们为每个对象节点 指定一个自循环边,并将该边标记为与从 到 创建一条边标签相同。这样,图形变得稀疏,并且每个边对图像中的一个对象间(inter-object)关系的先验知识进行编码。我们将基于此图的关系编码器命名为显式关系编码器。
3)Spatial Graph
令![]() =
= ![]() 表示对象
表示对象![]() 相对于对象
相对于对象![]() 的相对几何位置的空间关系。为了构造空间图
的相对几何位置的空间关系。为了构造空间图![]() ,在给定两个对象区域建议
,在给定两个对象区域建议![]() 和
和![]() 的情况下,我们将
的情况下,我们将![]() 分为11个不同的类别(例如
分为11个不同的类别(例如![]() 在
在![]() 内(记为class 1),
内(记为class 1),![]() 在
在![]() 内(记为class 2)),如下图所示。
内(记为class 2)),如下图所示。
其中包括为彼此距离太远的对象保留的无关系类。请注意,由空间形成的边是对称的:即如果![]() 是有效的空间关系,那么必须存在有效的空间关系
是有效的空间关系,那么必须存在有效的空间关系![]() =
=![]() 。但是,两个谓词
。但是,两个谓词![]() 和
和![]() 是不同的。
是不同的。
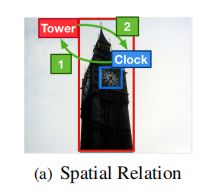
4)Semantic Graph
给定两个对象区域  和
和  , 目标是确定用哪个谓词
, 目标是确定用哪个谓词  表示这两个区域之间的语义关系
表示这两个区域之间的语义关系![]() 。在这里, 对象 (
。在这里, 对象 (![]() ) 和 对象 (
) 和 对象 (![]() ) 之间的关系是不可互换的,这意味着由语义关系形成的边是不对称的。例如:
) 之间的关系是不可互换的,这意味着由语义关系形成的边是不对称的。例如:
![]() 是有效的,但从bat到man是没有语义关系的,如下图所示。
是有效的,但从bat到man是没有语义关系的,如下图所示。
下面来分析一下如何建立语义关系的。创建一个分类模型,分类模型接受三个输入:主题(![]() )区域
)区域![]() 的特征向量、对象(
的特征向量、对象( )区域
)区域![]() 的特征向量和和区域级特征向量
的特征向量和和区域级特征向量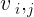 ,包含 和 的并集边界框。这三种特征都是从预先训练的目标检测模型中提取出来的,然后通过嵌入层进行变换。然后将嵌入的特征连接起来,并将其输入到分类层中,以在14个语义关系上产生Softmax概率,并附加一个无相关类。然后,使用经过训练的分类器来预测给定图像中任意一对对象区域之间的关系。
,包含 和 的并集边界框。这三种特征都是从预先训练的目标检测模型中提取出来的,然后通过嵌入层进行变换。然后将嵌入的特征连接起来,并将其输入到分类层中,以在14个语义关系上产生Softmax概率,并附加一个无相关类。然后,使用经过训练的分类器来预测给定图像中任意一对对象区域之间的关系。
2.2Relation Encoder
1)Question-adaptive Graph Attention
所提出的关系编码器设计用于编码图像中对象之间的动态关系。对于VQA任务,可能存在对不同问题类型有不同类型的有用关系。因此,在关系编码器的设计中,我们采用了一种问题自适应注意力机制,将问题中的语义信息注入到关系图中,以动态的方式给每个问题相关的关系,分配更高的权重。这是首先通过将嵌入 的问题与
的问题与 ![]() 个视觉特征
个视觉特征 ![]() 中的每一个进行串联在一起来实现的,表示为:
中的每一个进行串联在一起来实现的,表示为:
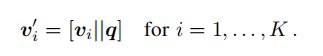
然后在顶点上执行自注意力,这会生成隐藏的关系特征![]() ,该特征描述目标对象及其邻近对象之间的关系。在此基础上,每个关系图都经过以下注意机制:
,该特征描述目标对象及其邻近对象之间的关系。在此基础上,每个关系图都经过以下注意机制:
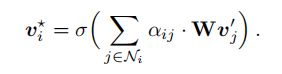
对于不同类型的关系图,注意系数![]() 的定义不同,投影矩阵
的定义不同,投影矩阵![]() 和对象 的邻域
和对象 的邻域![]() 也不同。
也不同。![]()
![]() 是一个像relu这样的非线性函数。为了稳定自我注意的学习过程,我们还扩展了上述图注意机制,采用多头部注意力机制(muti-head),其中执行了M个独立的注意力机制,并连接了它们的输出特征,从而得到以下输出特征表示:
是一个像relu这样的非线性函数。为了稳定自我注意的学习过程,我们还扩展了上述图注意机制,采用多头部注意力机制(muti-head),其中执行了M个独立的注意力机制,并连接了它们的输出特征,从而得到以下输出特征表示:
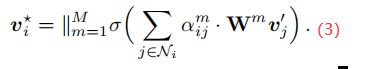
最后将 添加到原始视觉特征
添加到原始视觉特征![]() 中,以用作最终的关系感知特征。
中,以用作最终的关系感知特征。
代码如下:
# 图自我注意层 attention = softmax((Q*K^T)/sqrt(d)) V
class GraphSelfAttentionLayer(nn.Module):
def __init__(self, feat_dim, nongt_dim=20, pos_emb_dim=-1,
num_heads=16, dropout=[0.2, 0.5]):
""" Attetion module with vectorized version
Args:
position_embedding: [num_rois, nongt_dim, pos_emb_dim]
used in implicit relation用于隐式关系
pos_emb_dim: set as -1 if explicit relation
显式关系设为-1
nongt_dim: number of objects consider relations per image每个图像考虑关系的对象数 20
fc_dim: should be same as num_heads:应与num-heads相同
feat_dim: dimension of roi_feat 特征维数
num_heads: number of attention heads #头的数量 16
Returns:
output: [num_rois, ovr_feat_dim, output_dim]
"""
super(GraphSelfAttentionLayer, self).__init__()
# multi head
self.fc_dim = num_heads # 16
self.feat_dim = feat_dim # roi_feat的特征维数
self.dim = (feat_dim, feat_dim, feat_dim)
self.dim_group = (int(self.dim[0] / num_heads),
int(self.dim[1] / num_heads),
int(self.dim[2] / num_heads))
self.num_heads = num_heads # 多头 16
self.pos_emb_dim = pos_emb_dim # 位置嵌入维度
if self.pos_emb_dim > 0:
self.pair_pos_fc1 = FCNet([pos_emb_dim, self.fc_dim], None, dropout[0])
self.query = FCNet([feat_dim, self.dim[0]], None, dropout[0]) # q
self.nongt_dim = nongt_dim # 每个图像考虑关系的对象数 20
self.key = FCNet([feat_dim, self.dim[1]], None, dropout[0]) # k
self.linear_out_ = weight_norm(
nn.Conv2d(in_channels=self.fc_dim * feat_dim,
out_channels=self.dim[2],
kernel_size=(1, 1),
groups=self.fc_dim), dim=None)
def forward(self, roi_feat, adj_matrix,
position_embedding, label_biases_att):
"""
Args:
roi_feat: [batch_size, N, feat_dim]
adj_matrix: [batch_size, N, nongt_dim]
position_embedding: [num_rois, nongt_dim, pos_emb_dim]
Returns:
output: [batch_size, num_rois, ovr_feat_dim, output_dim]
"""
batch_size = roi_feat.size(0) # 批处理
num_rois = roi_feat.size(1) # roi的数量
# [batch_size,nongt_dim, feat_dim]
nongt_roi_feat = roi_feat[:, :self.nongt_dim, :] # 特征
# [batch_size,num_rois, self.dim[0] = feat_dim]
q_data = self.query(roi_feat) # Q
# [batch_size,num_rois, num_heads, feat_dim /num_heads]
q_data_batch = q_data.view(batch_size, num_rois, self.num_heads,
self.dim_group[0]) # Q
# [batch_size,num_heads, num_rois, feat_dim /num_heads]
q_data_batch = torch.transpose(q_data_batch, 1, 2) # Q
# [batch_size,nongt_dim, self.dim[1] = feat_dim]
k_data = self.key(nongt_roi_feat) # K
# [batch_size,nongt_dim, num_heads, feat_dim /num_heads]
k_data_batch = k_data.view(batch_size, self.nongt_dim, self.num_heads,
self.dim_group[1]) # K
# [batch_size,num_heads, nongt_dim, feat_dim /num_heads]
k_data_batch = torch.transpose(k_data_batch, 1, 2) # K
# [batch_size,nongt_dim, feat_dim]
v_data = nongt_roi_feat # V
'''
公式 att = (Q*K^T)/sqrt(d)
'''
# [batch_size, num_heads, num_rois, nongt_dim]
# Q*K^T
aff = torch.matmul(q_data_batch, torch.transpose(k_data_batch, 2, 3)) # 转置
# aff_scale, [batch_size, num_heads, num_rois, nongt_dim]
aff_scale = (1.0 / math.sqrt(float(self.dim_group[1]))) * aff # (Q*K^T)/sqrt(d)
# aff_scale, [batch_size,num_rois,num_heads, nongt_dim]
aff_scale = torch.transpose(aff_scale, 1, 2)
weighted_aff = aff_scale # 已经获得了权重注意力
if position_embedding is not None and self.pos_emb_dim > 0:
# Adding goemetric features 添加集合特征
position_embedding = position_embedding.float() # 转换类型
# [batch_size,num_rois * nongt_dim, emb_dim]
position_embedding_reshape = position_embedding.view(
(batch_size, -1, self.pos_emb_dim)) # 返回一个有相同数据但大小不同的tensor
# position_feat_1, [batch_size,num_rois * nongt_dim, fc_dim]
position_feat_1 = self.pair_pos_fc1(position_embedding_reshape)
position_feat_1_relu = nn.functional.relu(position_feat_1)
# aff_weight, [batch_size,num_rois, nongt_dim, fc_dim]
aff_weight = position_feat_1_relu.view(
(batch_size, -1, self.nongt_dim, self.fc_dim))
# aff_weight, [batch_size,num_rois, fc_dim, nongt_dim]
aff_weight = torch.transpose(aff_weight, 2, 3)
thresh = torch.FloatTensor([1e-6]).cuda()
# weighted_aff, [batch_size,num_rois, fc_dim, nongt_dim]
threshold_aff = torch.max(aff_weight, thresh) # 最大
weighted_aff += torch.log(threshold_aff)
if adj_matrix is not None:
# weighted_aff_transposed, [batch_size,num_rois, nongt_dim, num_heads]
weighted_aff_transposed = torch.transpose(weighted_aff, 2, 3)
zero_vec = -9e15 * torch.ones_like(weighted_aff_transposed)
adj_matrix = adj_matrix.view(
adj_matrix.shape[0], adj_matrix.shape[1],
adj_matrix.shape[2], 1)
adj_matrix_expand = adj_matrix.expand(
(-1, -1, -1,
weighted_aff_transposed.shape[-1]))
weighted_aff_masked = torch.where(adj_matrix_expand > 0,
weighted_aff_transposed,
zero_vec)
weighted_aff_masked = weighted_aff_masked + \
label_biases_att.unsqueeze(3)
weighted_aff = torch.transpose(weighted_aff_masked, 2, 3)
# aff_softmax, [batch_size, num_rois, fc_dim, nongt_dim]
aff_softmax = nn.functional.softmax(weighted_aff, 3)
# aff_softmax_reshape, [batch_size, num_rois*fc_dim, nongt_dim]
aff_softmax_reshape = aff_softmax.view((batch_size, -1, self.nongt_dim))
# output_t, [batch_size, num_rois * fc_dim, feat_dim]
output_t = torch.matmul(aff_softmax_reshape, v_data)
# output_t, [batch_size*num_rois, fc_dim * feat_dim, 1, 1]
output_t = output_t.view((-1, self.fc_dim * self.feat_dim, 1, 1))
# linear_out, [batch_size*num_rois, dim[2], 1, 1]
linear_out = self.linear_out_(output_t)
output = linear_out.view((batch_size, num_rois, self.dim[2]))
return output
2)Implicit Relation
由于用于学习的隐式关系图是完全连接的,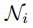 包含图像中的所有对象,包括对象 本身。我们设计的注意权重
包含图像中的所有对象,包括对象 本身。我们设计的注意权重![]() 不仅依赖于视觉特征权重
不仅依赖于视觉特征权重![]() ,而且还依赖于边框权重
,而且还依赖于边框权重 ,定义如下。
,定义如下。
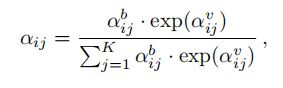
其中,![]() 表示视觉特征之间的相似性,由
表示视觉特征之间的相似性,由![]() 计算得到:
计算得到:
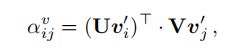
其中,![]() 是投影矩阵,
是投影矩阵,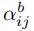 测量任意一对区域之间的相对几何位置:
测量任意一对区域之间的相对几何位置:
![]()
其中,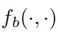 首先计算四维相对几何特征
首先计算四维相对几何特征![]() 然后通过计算不同波长的余弦函数和正弦函数,将其嵌入到
然后通过计算不同波长的余弦函数和正弦函数,将其嵌入到![]() 维特征中。
维特征中。![]()
![]() 将
将![]() 维特征转化为标量权重,进一步修剪为0。与我们在显式关系设置中对彼此之间距离太远的对象假定无关系不同,隐式关系的限制是通过w和零修剪操作来学习的。
维特征转化为标量权重,进一步修剪为0。与我们在显式关系设置中对彼此之间距离太远的对象假定无关系不同,隐式关系的限制是通过w和零修剪操作来学习的。
代码如下:
# 隐式关系编码
class ImplicitRelationEncoder(nn.Module):
def __init__(self, v_dim, q_dim, out_dim, dir_num, pos_emb_dim,
nongt_dim, num_heads=16, num_steps=1,
residual_connection=True, label_bias=True):
super(ImplicitRelationEncoder, self).__init__()
self.v_dim = v_dim
self.q_dim = q_dim
self.out_dim = out_dim
self.residual_connection = residual_connection
self.num_steps = num_steps
print("In ImplicitRelationEncoder, num of graph propogate steps:",
"%d, residual_connection: %s" % (self.num_steps,
self.residual_connection))
if self.v_dim != self.out_dim:
self.v_transform = FCNet([v_dim, out_dim])
else:
self.v_transform = None
in_dim = out_dim + q_dim
self.implicit_relation = GAT(dir_num, 1, in_dim, out_dim,
nongt_dim=nongt_dim,
label_bias=label_bias,
num_heads=num_heads,
pos_emb_dim=pos_emb_dim)
def forward(self, v, position_embedding, q):
"""
Args:
v: [batch_size, num_rois, v_dim]
q: [batch_size, q_dim]
position_embedding: [batch_size, num_rois, nongt_dim, emb_dim]
Returns:
output: [batch_size, num_rois, out_dim,3]
"""
# [batch_size, num_rois, num_rois, 1]
imp_adj_mat = Variable(
torch.ones(
v.size(0), v.size(1), v.size(1), 1)).to(v.device)
imp_v = self.v_transform(v) if self.v_transform else v
for i in range(self.num_steps):
v_cat_q = q_expand_v_cat(q, imp_v, mask=True)
imp_v_rel = self.implicit_relation.forward(v_cat_q,
imp_adj_mat,
position_embedding)
if self.residual_connection:
imp_v += imp_v_rel
else:
imp_v = imp_v_rel
return imp_v
3)Explicit Relation
首先考虑语义关系编码器。由于语义图![]() 中的边缘现在包含了标签信息,并且是定向的,所以我们在公式(3)中设计了3种的注意机制
中的边缘现在包含了标签信息,并且是定向的,所以我们在公式(3)中设计了3种的注意机制![]() ,使其对方向和标签都敏感,定义如下:
,使其对方向和标签都敏感,定义如下:

其中![]() 是矩阵,而
是矩阵,而![]() 是偏置项。
是偏置项。 根据每个边的方向性选择转换矩阵,
根据每个边的方向性选择转换矩阵,![]() 表示每一个边的标签。因此,在通过上述图关注机制对所有区域
表示每一个边的标签。因此,在通过上述图关注机制对所有区域![]() 进行编码之后,对被细化的区域级特征
进行编码之后,对被细化的区域级特征![]() 具有对象之间的先验语义关系。
具有对象之间的先验语义关系。
与图卷积网络相反,该图注意力机制有效地将不同权重分配给同一邻域的节点。结合问题自注意机制,学习到的注意力权重可以反映哪些关系与特定的问题相关。
代码如下:
# 显示关系编码
class ExplicitRelationEncoder(nn.Module):
def __init__(self, v_dim, q_dim, out_dim, dir_num, label_num,
nongt_dim=20, num_heads=16, num_steps=1,
residual_connection=True, label_bias=True):
super(ExplicitRelationEncoder, self).__init__()
self.v_dim = v_dim
self.q_dim = q_dim
self.out_dim = out_dim
self.num_steps = num_steps
self.residual_connection = residual_connection
print("In ExplicitRelationEncoder, num of graph propogation steps:",
"%d, residual_connection: %s" % (self.num_steps,
self.residual_connection))
if self.v_dim != self.out_dim:
self.v_transform = FCNet([v_dim, out_dim])
else:
self.v_transform = None
in_dim = out_dim + q_dim
self.explicit_relation = GAT(dir_num, label_num, in_dim, out_dim,
nongt_dim=nongt_dim,
num_heads=num_heads,
label_bias=label_bias,
pos_emb_dim=-1)
def forward(self, v, exp_adj_matrix, q):
"""
Args:
v: [batch_size, num_rois, v_dim]
q: [batch_size, q_dim]
exp_adj_matrix: [batch_size, num_rois, num_rois, num_labels]
Returns:
output: [batch_size, num_rois, out_dim]
"""
exp_v = self.v_transform(v) if self.v_transform else v
for i in range(self.num_steps):
v_cat_q = q_expand_v_cat(q, exp_v, mask=True)
exp_v_rel = self.explicit_relation.forward(v_cat_q, exp_adj_matrix)
if self.residual_connection:
exp_v += exp_v_rel
else:
exp_v = exp_v_rel
return exp_v
2.3 Multimodal Fusion and Answer Prediction
在获得关系感知的视觉特征后,我们希望通过多模型融合策略将问题信息 与每个视觉表示融合。由于我们的关系编码器保留了视觉特征的维数,所以它可以与现有的多模式融合方法结合起来学习联合表示![]() :
:
![]()
其中,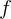 是一种多模态融合方法,
是一种多模态融合方法,![]() 是融合模型的可训练参数。
是融合模型的可训练参数。
对于答案预测器,我们采用两层多层感知器(MLP)作为分类器,以联合表示![]() 作为输入,采用二元交叉熵作为损失函数。在训练阶段,不同的关系编码器是独立的。在推理阶段,我们将三个图形关注网络与预测答案分布的加权和相结合,具体而言,最终答案分布是通过以下方法计算的:
作为输入,采用二元交叉熵作为损失函数。在训练阶段,不同的关系编码器是独立的。在推理阶段,我们将三个图形关注网络与预测答案分布的加权和相结合,具体而言,最终答案分布是通过以下方法计算的:
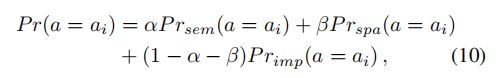
其中, 和
和 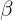 是权衡超参数,(0
是权衡超参数,(0 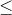 + 1 , 0 , 1),
+ 1 , 0 , 1),![]() 和
和![]() 分别表示从模型中分别训练的语义关系、空间关系和隐式关系预测的答案概率
分别表示从模型中分别训练的语义关系、空间关系和隐式关系预测的答案概率![]() 。
。
三、实验分析
作者在VQA 2.0和VQACP v2数据集分别进行了实验,下面对参数进行简单的介绍,标记化每个问题,并且每个单词使用600维词嵌入(包括300维GloVe词嵌入)进行词嵌入。嵌入单词的序列随后被输入GRU单元中,每次进入长度为14的词标记,少于14个单词的问题用零向量在最后填充。GRU中隐藏层的尺寸设置为1024。对于所有三个图注意网络,我们使用16个head的muti-head注意力机制。对于隐式关系,我们将嵌入的相对几何特征维数![]() 设为64。
设为64。
对于语义关系分类器,我们结合ResNet-101,从Faster R-CNN模型中提取具有已知边框的预先训练的目标检测特征。更具体地,特征是在从![]() 特征映射中池化
特征映射中池化![]() 之后的
之后的![]() 层的输出。Faster R-CNN模型训练了1600个选定的对象类和400个属性类,下面是进行试验和消融研究。
层的输出。Faster R-CNN模型训练了1600个选定的对象类和400个属性类,下面是进行试验和消融研究。
表1不同融合方法对VQA2.0验证集的性能。

表2 VQA-CP v2基准的模型精度。
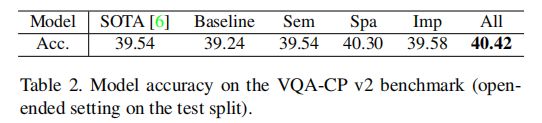
表3 VQA 2.0基准的模型精度。

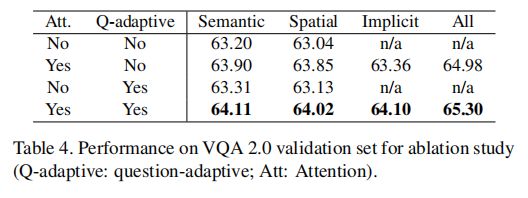
表4用于消融研究的VQA2.0验证集的性能研究。
下面是进行的一些可视化验证。为了更好地说明添加图注意和问题自适应机制的有效性,我们将完全ReGAT模型在单一关系设置下学习到的注意图与两个消融模型学习到的注意图进行了比较,如下图。

图5提供了不同类型的关系如何帮助提高性能的可视化示例。

四、结论
We have presented Relation-aware Graph Attention Network (ReGAT), a novel framework for visual question answering, to model multi-type object relations with question adaptive attention mechanism. ReGAT exploits two types of visual object relations: Explicit Relations and Implicit Relations, to learn a relation-aware region representation through graph attention. Our method achieves state-of-the-art results on both VQA 2.0 and VQA-CP v2 datasets. The proposed ReGAT model is compatible with generic VQA models. Comprehensive experiments on two VQA datasets show that our model can be infused into state-of-the-art VQA architectures in a plug-and-play fashion. For future work, we will investigate how to fuse the three relations more effectively and how to utilize each relation to solve specifific question types.
本文提出了一种面向关系感知的图注意力网络(ReGAT ),为视觉问题答疑提供了一种新的框架,并与问题自适应的注意机制建立了多类型对象关系模型,进行了复杂的语义和空间关系的编码,值得学习借鉴。