实时目标检测之屏幕按钮+脚本自动化
实时目标检测之屏幕按钮+脚本自动化
题目还没想好,就酱,是接上一篇文章的中部分。
碎碎念
上一篇 基于Qt ffmpeg开发跨平台安卓实时投屏软件 已经实现了电脑控制安卓屏幕,这一篇主要实现屏幕按钮的目标检测,脚本自动化主要看 按钮检测的效果,尚可,则继续做下一步。
参考早期的机器学习方法,一系列的裁剪转化二值化,从连通图里检测中圆形按钮应该不难,但是作为业余爱好,是想实现智能化的检测,让机器人能自动学习,而不是通过一系列trick、模板来勉强达到检测效果。原先的设想里,是想让算法通过检测屏幕按键+屏幕画面,依靠识别屏幕里面的奖励来达到自动推理效果。考虑了DeepMind里alphaGo、绝悟,希望打碎了能从中用些简化的算法,搜索的时候发现Atari、OpenAI Gym 等平台后台是提供资源值、英雄的基本信息的接口,并非直接的完全的学习。而AI游戏是抛去这些识别,主要实现的是其游戏最优化推理逻辑,而我只想实现最早的一步,通过神经网络进行自动目标检测,而不需要依赖对前期图像的预处理。从简单的算法做起吧,朋友推荐了YOLO,yolo已经从v1升级到V5,算法检测速度也能达到视频流的输出效果,本章主要记录pytorch训练自己数据集的过程,欢迎关注。
目录
实时目标检测之屏幕按钮+脚本自动化
碎碎念
一、YOLOv5介绍
二、环境搭建
2.1Cuda搭建
【配置GPU运算】win7 64位 + CUDA 10.1 + cuDNN v7.0.5 安装[ 第1步 ] 下载安装 CUDA 【怎么让那个GPU参与运算,这里告诉你】
下载CuDNN
tensorflow要求
2.2tensorflow 搭建
测试GPU计算能力+TensorFlow
2.3安装Pytorch
2.4验证Pytorch
三、YOLOv5
3.1代码下载
3.2安装requirements.txt
3.3test.py
3.4训练结果
3.5运行参数
3.6遇到问题:
1)RuntimeError: No such operator torchvision::nms
2) wandb.errors.error.UsageError: api_key not configured (no-tty). Run wandb login
3.7YOLO参考
四、利用YOLO5训练自己的数据
4.1labelme
4.2碎碎念
4.3数据预处理
4.4labelme json格式
4.5yolo格式(cx/img_w,cy/img_h,w/img_w,h/img_h,其中cx,cy为box中心点,w,h为box宽长,img_w,img_h为图片长宽)
4.6labelme标注文件转coco json,coco json转yolo txt格式,coco json转xml, labelme标注文件转分割,boxes转labelme json
4.7修改模型参数
4.8训练screem
4.9检测screem
一、YOLOv5介绍
pip install torch===1.7.0 torchvision===0.8.1 torchaudio===0.7.0 -f https://download.pytorch.org/whl/torch_stable.html通过netron可以直观查看网络结构,对网络的架构会有更清晰的认识。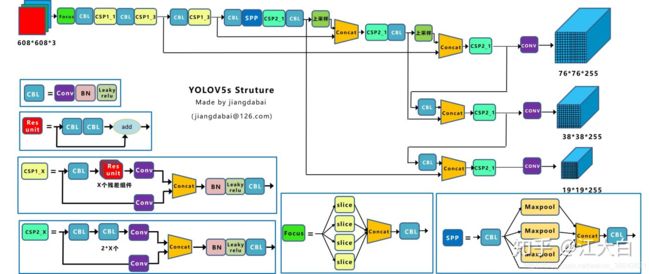
算法性能测试图: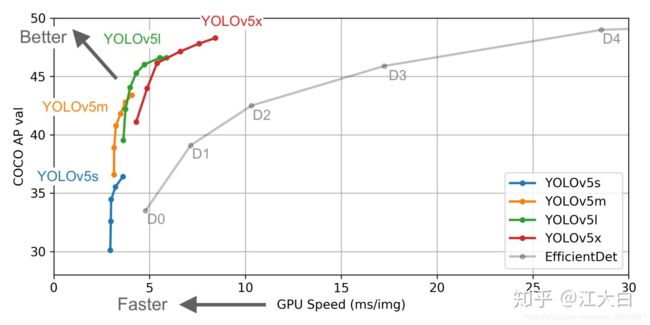
Yolov5s网络最小,速度最少,AP精度也最低。但如果检测的以大目标为主,追求速度,倒也是个不错的选择。
二、环境搭建
2.1Cuda搭建

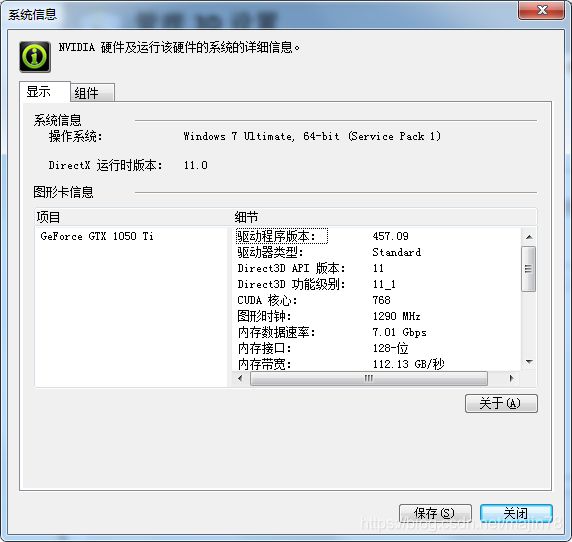
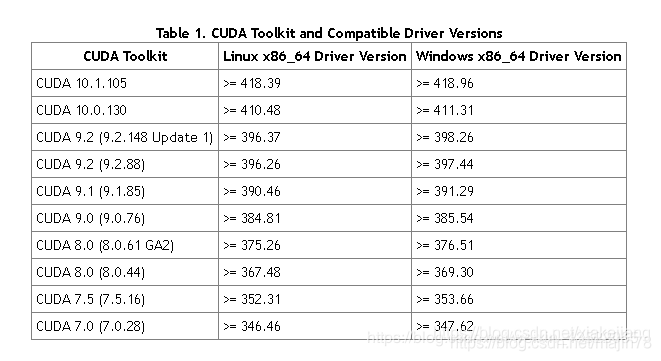
版本配置选择 cuda10.1 win7 64
https://blog.csdn.net/qq_23013309/article/details/103965619
【配置GPU运算】win7 64位 + CUDA 10.1 + cuDNN v7.0.5 安装[ 第1步 ] 下载安装 CUDA 【怎么让那个GPU参与运算,这里告诉你】
https://blog.csdn.net/wills798/article/details/89368687
下载CuDNN
官网 https://developer.nvidia.com/rdp/cudnn-download
1.与安装其他的软件类似
2.安装结束后将 ~/nvcc/bin(因为版本的不同可能在不同的地方) 目录添加到环境变量
3.在命令行下输入 nvcc -V, 出现下列信息说明Cuda安装成功
tensorflow要求
yolo v5要求python3.8 实际 上TensorFlow只支持至3.7 故安装3.7版本 ;)后期发现python3.8 也可以
官网https://tensorflow.google.cn/install/gpu
确保安装的 NVIDIA 软件包与上面列出的版本一致。特别是,如果没有 cuDNN64_7.dll 文件,TensorFlow 将无法加载。如需使用其他版本,请参阅在 Windows 下从源代码构建指南。
将 CUDA®、CUPTI 和 cuDNN 安装目录添加到 %PATH% 环境变量中。例如,如果 CUDA® 工具包安装到 C:\Program Files\NVIDIA GPU Computing Toolkit\CUDA\v10.1,并且 cuDNN 安装到 C:\tools\cuda,请更新 %PATH% 以匹配路径:
SET PATH=C:\Program Files\NVIDIA GPU Computing Toolkit\CUDA\v10.1\bin;%PATH%SET PATH=C:\Program Files\NVIDIA GPU Computing Toolkit\CUDA\v10.1\extras\CUPTI\lib64;%PATH%SET PATH=C:\Program Files\NVIDIA GPU Computing Toolkit\CUDA\v10.1\include;%PATH%SET PATH=C:\tools\cuda\bin;%PATH%
解压之后:
- 将 bin 文件夹下的 cudnn64_7.dll 复制到 CUDA安装路径的 bin 文件夹 目录下;
- 将 include 文件夹下的 cudnn.h 复制到 CUDA安装路径的 include 文件夹 目录下;
- 将 x64 文件夹下的 cudnn.lib 复制到 CUDA安装路径的 lib\x64 目录下。
按照自己的情况来,如下是我的解压和安装路径
cudnn64_7.dll 复制到C:\Program Files\NVIDIA GPU Computing Toolkit\CUDA\v10.1\bin;
cudnn.h 复制到C:\Program Files\NVIDIA GPU Computing Toolkit\CUDA\v10.1\include;
cudnn.lib 复制到C:\Program Files\NVIDIA GPU Computing Toolkit\CUDA\v10.1\lib\x64;
2.2tensorflow 搭建
测试GPU计算能力+TensorFlow
#!/usr/bin/python
# -*- coding: utf-8 -*-
"""
测试NVIDIA cuda。
"""
#import tensorflow as tf 是因为在新的Tensorflow 2.0版本中已经移除了Session这一模块,改换运行代码
import tensorflow.compat.v1 as tf
import numpy as np
import time
tf.disable_v2_behavior()
# 产生用于计算测试的数据
value = np.random.randn(5000, 1000)
a = tf.constant(value)
# 计算方式
b = a * a
# gpu
tic = time.time()
with tf.Session() as sess:
for i in range(1000):
sess.run(b)
toc = time.time()
t_cost = toc - tic
print(t_cost)
2.3安装Pytorch
官网 https://download.pytorch.org/whl/torch_stable.html 选择合适的版本
torch/torchvision 都需要安装

2.4验证Pytorch
#!/usr/bin/python
# -*- coding:utf-8 -*
import torch
import matplotlib
import numpy
import scipy
from torch.autograd import Variable
import torch.nn.functional as F
import matplotlib.pyplot as plt
import torchvision
x = torch.unsqueeze(torch.linspace(-1, 1, 100), dim=1)
y = x.pow(2) + 0.2 * torch.rand(x.size())
x, y = Variable(x), Variable(y)
# plt.scatter(x.data.numpy(),y.data.numpy())
# plt.show()
class Net(torch.nn.Module):
def __init__(self, n_features, n_hidden, n_output):
super(Net, self).__init__()
self.hidden = torch.nn.Linear(n_features, n_hidden)
self.predict = torch.nn.Linear(n_hidden, n_output)
def forward(self, x):
x = F.relu6(self.hidden(x))
x = self.predict(x)
return x
net = Net(1, 10, 1)
print(net)
plt.ion()
plt.show()
optimaizer = torch.optim.SGD(net.parameters(), lr=0.5)
loss_func = torch.nn.MSELoss()
for t in range(100):
prediction = net(x)
loss = loss_func(prediction, y)
optimaizer.zero_grad()
loss.backward()
optimaizer.step()
if t % 5 == 0:
plt.cla()
plt.scatter(x.data.numpy(), y.data.numpy())
plt.plot(x.data.numpy(), prediction.data.numpy(), 'r-', lw=5)
plt.text(0.5, 0, 'Loss=%.4f' % loss.data, fontdict={'size': 20, 'color': 'red'})
plt.pause(0.1)
plt.ioff()
plt.show()
能跑通,则环境没问题。
三、YOLOv5
3.1代码下载
https://github.com/ultralytics/yolov5
https://github.com/CVUsers/Smoke-Detect-by-YoloV5
3.2安装requirements.txt
conda install Cython
conda install matplotlib>=3.2.2
conda install numpy>=1.18.5
#conda install opencv-python>=4.1.2 没找到安装了opencv
#conda install opencv
conda install pillow
conda install PyYAML>=5.3
conda install scipy>=1.4.1
conda install tensorboard>=2.2
conda install tqdm>=4.41.0
#conda install torchvision>=0.7.0
conda install torchvision -c pytorch
pip install torch>=1.6.0 #这个用pip安装
3.3test.py

3.4训练结果
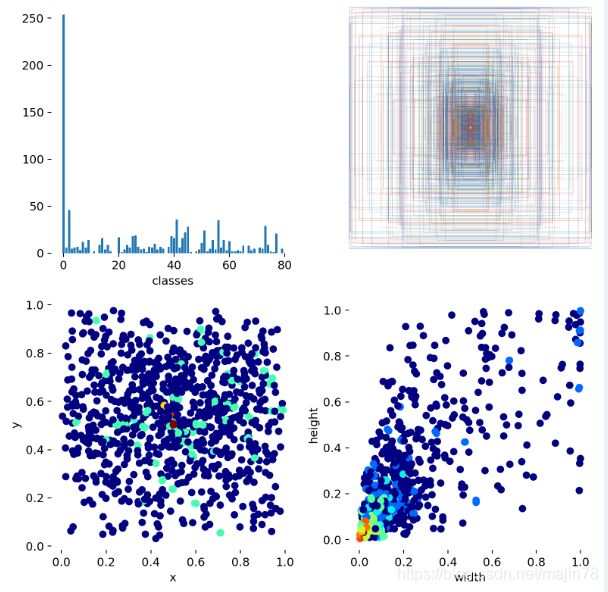

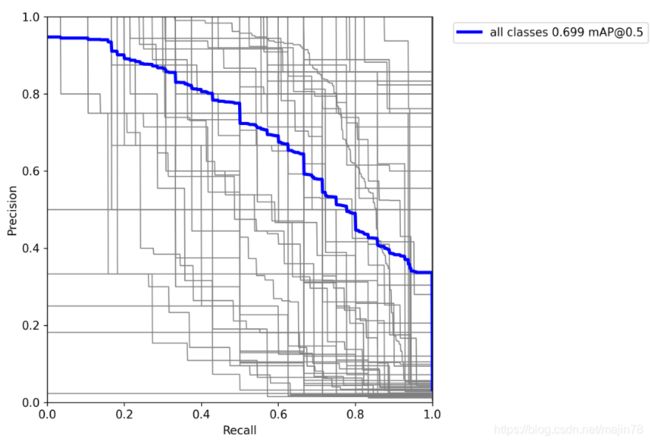
3.5运行参数
#python detect.py --source ./test/ --weights yolov5s.pt --conf 0.4

3.6遇到问题:
1)RuntimeError: No such operator torchvision::nms
由于 torch 与torchvision版本不对应导致的
ps:torch和torchvision的版本需要一致,否则会运行出现
RuntimeError: No such operator torchvision::nms
下面是下载的版本一致的whl文件,直接pip install torchvision会出现问题版本不一致
pytorch国外的源,直接在官网的安装命令会下载不下来。我们还是把轮子下下来安装:
https://download.pytorch.org/whl/torch_stable.html
pip install torch-1.7.0+cu101-cp37-cp37m-win_amd64.whl
pip install torchvision-0.8.0-cp37-cp37m-win_amd64.whl python 3.7版本
Using torch 1.7.0+cu101 CUDA:0 (GeForce GTX 1050 Ti, 4096MB)
torchvision-0.8.0
python 3.8 版本
torch-1.7.1+cu101-cp38-cp38-win_amd64.whl
torchvision-0.8.0-cp38-cp38-win_amd64.whl
2) wandb.errors.error.UsageError: api_key not configured (no-tty). Run wandb login
wandb初始化后,再注册下,
wandb initf1909b0ea9f0bxxxxxxxxxxxxxxx7e4f29998
按提示初始化后OK
3.7YOLO参考
https://blog.csdn.net/l7H9JA4/article/details/107947708?utm_medium=distribute.pc_relevant.none-task-blog-BlogCommendFromBaidu-1.control&depth_1-utm_source=distribute.pc_relevant.none-task-blog-BlogCommendFromBaidu-1.control
四、利用YOLO5训练自己的数据
python detect.py #检测inference\images文件夹下的所有图片
python .\detect.py --source .\inference\images\bus.jpg # 检测某一张图片
python .\detect.py --source .\road.mp4 # 检测某一视频
python .\detect.py --source 0 # 调用摄像头4.1labelme
https://github.com/wkentaro/labelme/releases/download/v4.5.6/Labelme.exe
下载速度忒慢
4.2碎碎念
思维构想:大哥没文化,大哥也不爱说话,打工人打工魂,打工人干饭得用盆,打工人手冷,打工人浇水得用盆。
工作流程:
操作流程1:app进入(图标ico识别)=>界面图标检测,判断是否为app=>找到水桶盆=>浇水
4.3数据预处理
labelme标注的文件转yolo txt
4.4labelme json格式
"points": [ # 边缘是由点构成,将这些点连在一起就是对象的边缘多边形 [ 165.90909090909093, # 第一个点 x 坐标 36.909090909090935 # 第一个点 y 坐标

4.5yolo格式(cx/img_w,cy/img_h,w/img_w,h/img_h,其中cx,cy为box中心点,w,h为box宽长,img_w,img_h为图片长宽)
yolo txt
txt中的五个值,分别对应类,x.y的中心点,长宽

4.6labelme标注文件转coco json,coco json转yolo txt格式,coco json转xml, labelme标注文件转分割,boxes转labelme json

4.7修改模型参数
1)coco.yaml
nc 种类,train and val data 数据 names 分类的名称
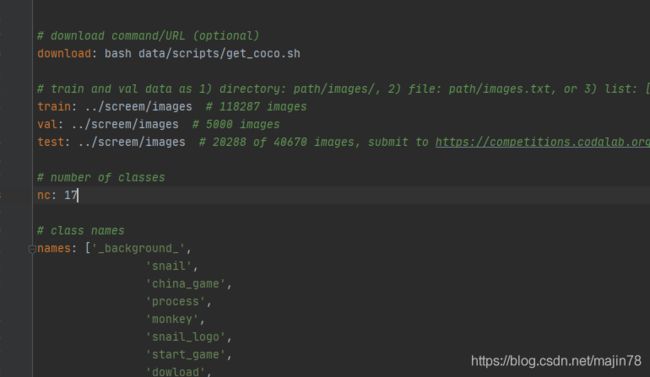
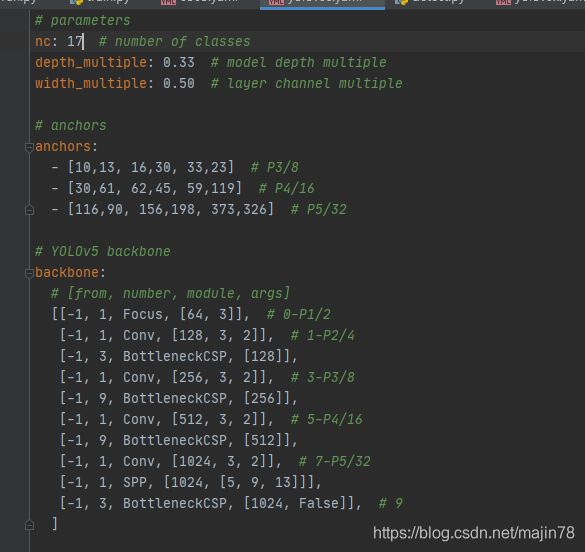
2)yolo5s.yaml
修改nc分类种数
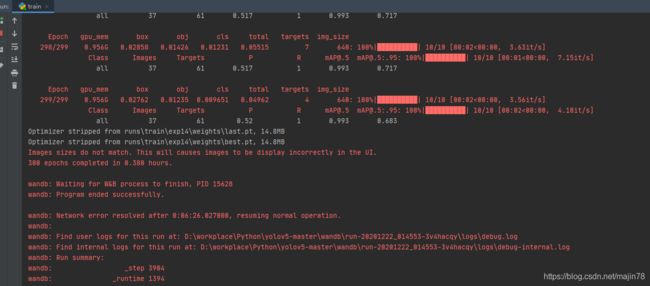
4.8训练screem
--source ./test/ --weights yolov5s.pt --conf 0.4
python train.py --img 640 --batch 16 --epochs 5 --data ./data/my-dataset.yaml --cfg ./models/yolov5s.yaml --weights ''
python train.py --data coco.yaml --cfg yolov5s.yaml --weights yolov5s.pt --batch-size 4
https://blog.csdn.net/qq_24889005/article/details/107802034?ops_request_misc=%25257B%252522request%25255Fid%252522%25253A%252522160857005916780277819561%252522%25252C%252522scm%252522%25253A%25252220140713.130102334..%252522%25257D&request_id=160857005916780277819561&biz_id=0&utm_medium=distribute.pc_search_result.none-task-blog-2~all~baidu_landing_v2~default-7-107802034.first_rank_v2_pc_rank_v29&utm_term=yolov5%20%E8%87%AA%E5%B7%B1
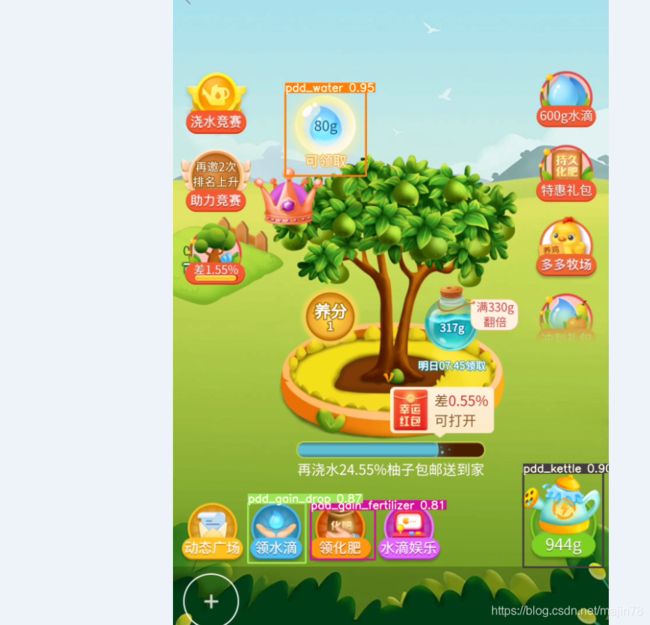
4.9检测screem
--source ./../screem/test --weights screem1.pt --conf 0.4
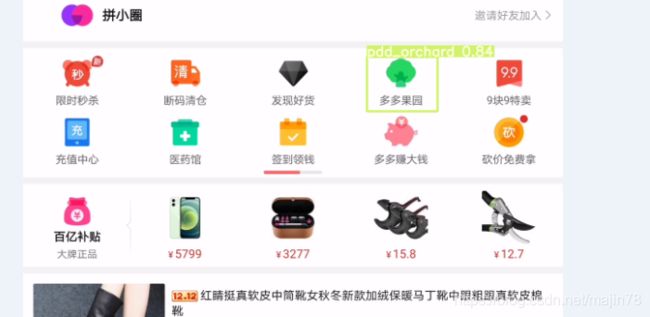
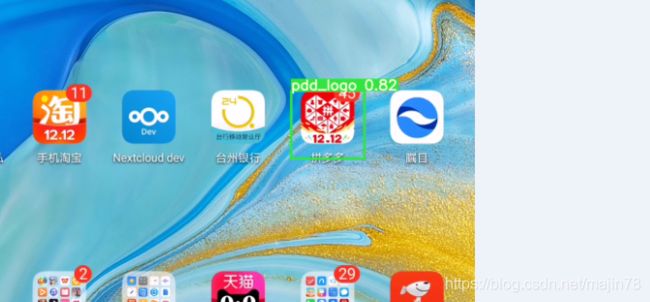

4.10检测screem 以服务模式部署
flask部署