前面我们提到,在防止缓存穿透的情况(缓存穿透是指,缓存和数据库都没有的数据,被大量请求,比如订单号不可能为-1,但是用户请求了大量订单号为-1的数据,由于数据不存在,缓存就也不会存在该数据,所有的请求都会直接穿透到数据库。),我们可以考虑使用布隆过滤器,来过滤掉绝对不存于集合中的元素。
布隆过滤器是什么呢?
布隆过滤器(Bloom Filter)是由布隆(Burton Howard Bloom)在1970年提出的,它实际上是由一个很长的二进制向量和一系列随机hash映射函数组成(说白了,就是用二进制数组存储数据的特征)。可以使用它来判断一个元素是否存在于集合中,它的优点在于查询效率高,空间小,缺点是存在一定的误差,以及我们想要剔除元素的时候,可能会相互影响。
也就是当一个元素被加入集合的时候,通过多个hash函数,将元素映射到位数组中的k个点,置为1。
为什么需要布隆过滤器?
一般情况下,我们想要判断是否存在某个元素,一开始考虑肯定是使用数组,但是使用数组的情况,查找的时候效率比较慢,要判断一个元素不存在于数组中,需要每次遍历完所有的元素。删除完一个元素后,还得把后面的其他元素往前面移动。

其实可以考虑使用hash表,如果有hash表来存储,将是以下的结构: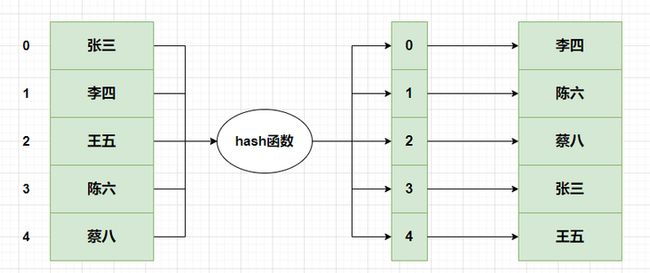
但是这种结构,虽然满足了大部分的需求,可能存在两点缺陷:
- 只有一个hash函数,其实两个元素hash到一块,也就是产生hash冲突的可能性,还是比较高的。虽然可以用拉链法(后面跟着一个链表)的方式解决,但是操作时间复杂度可能有所升高。
- 存储的时候,我们需要把元素引用给存储进去,要是上亿的数据,我们要将上亿的数据存储到一个hash表里面,不太建议这样操作。
对于上面存在的缺陷,其实我们可以考虑,用多个hash函数来减少冲突(注意:冲突时不可以避免的,只能减少),用位来存储每一个hash值。这样既可以减少hash冲突,还可以减少存储空间。
假设有三个hash函数,那么不同的元素,都会使用三个hash函数,hash到三个位置上。
假设后面又来了一个张三,那么在hash的时候,同样会hash到以下位置,所有位都是1,我们就可以说张三已经存在在里面了。

那么有没有可能出现误判的情况呢?这是有可能的,比如现在只有张三,李四,王五,蔡八,hash映射值如下: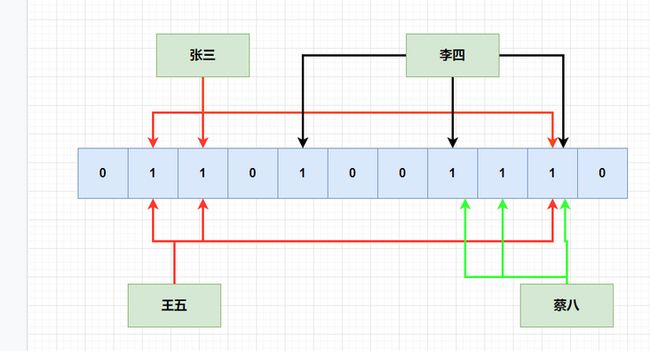
后面来了陈六,但是不凑巧的是,它hash的三个函数hash出来的位,刚刚好就是被别的元素hash之后,改成1了,判断它已经存在了,但是实际上,陈六之前是不存在的。
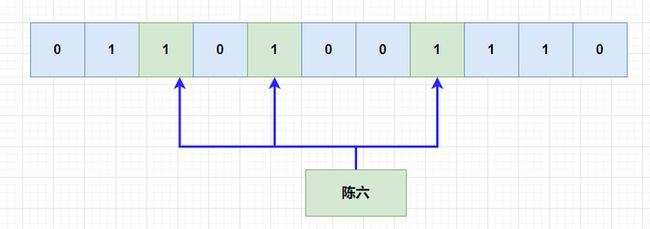
上面的情况,就是误判,布隆过滤器都会不可避免的出现误判。但是它有一个好处是,布隆过滤器,判断存在的元素,可能不存在,但是判断不存在的元素,一定不存在。,因为判断不存在说明至少有一位hash出来是对不上的。
也是由于会出现多个元素可能hash到一起,但有一个数据被踢出了集合,我们想把它映射的位,置为0,相当于删除该数据。这个时候,就会影响到其他的元素,可能会把别的元素映射的位,置为了0。这也就是为什么布隆过滤器不能删除的原因。
具体步骤
添加元素:
-
- 使用多个hash函数对元素item进行hash运算,得到多个hash值。
-
- 每一个hash值对bit位数组取模,得到位数组中的位置索引index。
-
- 如果index的位置不为1,那么就将该位置为1。
判断元素是否存在:
-
- 使用多个hash函数对元素item进行hash运算,得到多个hash值。
-
- 每一个hash值对bit位数组取模,得到位数组中的位置索引index。
-
- 如果index所处的位置都为1,说明元素可能已经存在了。
误判率推导
庆幸的是,布隆过滤器的误判率是可以预测的,由上面的分析,也可以得知,其实是与位数组的大小,以及hash函数的个数等,这些都是息息相关的。
假设位数组的大小是m,我们一共有k个hash函数,那么每一个hash函数,进行hash的时候,只能hash到m位中的一个位置,所以没有被hash到的概率是:
$$1-\frac{1}{m}$$
k个hash函数都hash之后,该位还是没有被hash到1的概率是:
$$(1-\frac{1}{m})^k$$
如果我们插入了n个元素,也就是hash了n*k次,该位还是没有被hash成1的概率是:
$$(1-\frac{1}{m})^{kn}$$
那该位为1的概率就是:
$$1-(1-\frac{1}{m})^{kn}$$
如果需要检测某一个元素是不是在集合中,也就是该元素对应的k个hash元素hash出来的值,都需要设置为1。也就是该元素不存在,但是该元素对应的所有位都被hash成为1的概率是:
$${(1-(1-\frac{1}{m})^{kn})}^{k}\approx {(1-e^{-kn/m})}^k $$
可以大致看出,随着位数组大小m和hash函数个数的增加,其实概率会下降,随着插入的元素n的增加,概率会有所上升。
最后也可以通过自己期待的误判率P和期待添加的个数n,来大致计算出布隆过滤器的位数组的长度:
$$m=-(\frac{nInP}{(In2)^2})$$
上面就是误判率的大致计算方式,同时也提示我们,可以根据自己业务的数据量以及误判率,来调整我们的数组的大小。
布隆过滤器的作用
除了我们前面说的过滤爬虫恶意请求,还可以对一些URL进行去重,过滤海量数据里面的重复数据,过滤数据库里面不存在的id等等。
但是,即使有布隆过滤器,我们也不可能完全避免,或者彻底解决缓存穿透这个问题。只是相当于做了优化,将准确率提高。
很多的key-value数据库也会使用布隆过滤器来加快查询效率,因为全部挨个判断一遍,这个效率太低了。
【刷题笔记】
Github仓库地址: https://github.com/Damaer/cod...
笔记地址: https://damaer.github.io/code...
【作者简介】:
秦怀,公众号【秦怀杂货店】作者,技术之路不在一时,山高水长,纵使缓慢,驰而不息。个人写作方向:Java源码解析,JDBC,Mybatis,Spring,redis,分布式,剑指Offer,LeetCode等,认真写好每一篇文章,不喜欢标题党,不喜欢花里胡哨,大多写系列文章,不能保证我写的都完全正确,但是我保证所写的均经过实践或者查找资料。遗漏或者错误之处,还望指正。
平日时间宝贵,只能使用晚上以及周末时间学习写作,关注我,我们一起成长吧~