1 遇到问题
flink实时程序在线上环境上运行遇到一个很诡异的问题,flink使用eventtime读取kafka数据发现无法触发计算。
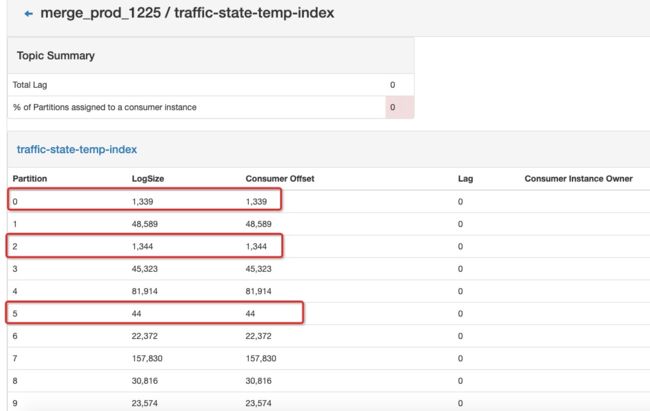
经过代码打印查看后发现十个并行度执行含有十个分区的kafka,有几个分区的watermark不更新,如图所示。

打开kafka监控,可以看到数据有严重的倾斜问题。如下图所示,10个分区中有三个分区数据量特别少,5号分区基本上没数据。
watermark的传递机制
当并行执行的情况下,如下图所示,每次接受的水印发送的水印都是最小的,木桶效应。但是,当某个分区始终无数据的时候,就不会更新该分区的watermark值,
那么窗口就一直不会被触发计算。这种现象在某些hash极端导致数据倾斜很普遍。

2 解决问题
2.1 更改并行度
把并行度改小,使得每个并行进程处理多个分区数据,同个并行的进程处理多分区数据就会使用最大的水印。
2.2 重写StreamSource
高于flink1.5低于1.11版本可以使用这种方法
仿照下面的代码开发一个StreamSource, 放到org.apache.flink.streaming.api.operators包下面,与业务代码一起打包:
/*
* Licensed to the Apache Software Foundation (ASF) under one or more
* contributor license agreements. See the NOTICE file distributed with
* this work for additional information regarding copyright ownership.
* The ASF licenses this file to You under the Apache License, Version 2.0
* (the "License"); you may not use this file except in compliance with
* the License. You may obtain a copy of the License at
*
* http://www.apache.org/licenses/LICENSE-2.0
*
* Unless required by applicable law or agreed to in writing, software
* distributed under the License is distributed on an "AS IS" BASIS,
* WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
* See the License for the specific language governing permissions and
* limitations under the License.
*/
package org.apache.flink.streaming.api.operators;
import org.apache.flink.annotation.Internal;
import org.apache.flink.configuration.Configuration;
import org.apache.flink.configuration.MetricOptions;
import org.apache.flink.runtime.jobgraph.OperatorID;
import org.apache.flink.streaming.api.TimeCharacteristic;
import org.apache.flink.streaming.api.functions.source.SourceFunction;
import org.apache.flink.streaming.api.watermark.Watermark;
import org.apache.flink.streaming.runtime.streamrecord.LatencyMarker;
import org.apache.flink.streaming.runtime.streamrecord.StreamRecord;
import org.apache.flink.streaming.runtime.streamstatus.StreamStatusMaintainer;
import org.apache.flink.streaming.runtime.tasks.OperatorChain;
import org.apache.flink.streaming.runtime.tasks.ProcessingTimeCallback;
import org.apache.flink.streaming.runtime.tasks.ProcessingTimeService;
import java.util.concurrent.ScheduledFuture;
/**
* {@link StreamOperator} for streaming sources.
*
* @param Type of the output elements
* @param Type of the source function of this stream source operator
*/
@Internal
public class StreamSource> extends AbstractUdfStreamOperator {
private static final long serialVersionUID = 1L;
private transient SourceFunction.SourceContext ctx;
private transient volatile boolean canceledOrStopped = false;
private transient volatile boolean hasSentMaxWatermark = false;
private final String SOURCE_IDLE_TIMEOUT_KEY = "source.idle.timeout.ms";
private long idleTimeout = -1;
@Override
public void open() throws Exception {
super.open();
idleTimeout = Long.valueOf(getRuntimeContext()
.getExecutionConfig()
.getGlobalJobParameters()
.toMap().getOrDefault(SOURCE_IDLE_TIMEOUT_KEY, "-1").trim());
if(idleTimeout != -1){
System.err.println(String.format("Enable idle checking .... [%d]ms", idleTimeout));
System.err.println(String.format("Enable idle checking .... [%d]ms", idleTimeout));
System.err.println(String.format("Enable idle checking .... [%d]ms", idleTimeout));
}
}
public StreamSource(SRC sourceFunction) {
super(sourceFunction);
this.chainingStrategy = ChainingStrategy.HEAD;
}
public void run(final Object lockingObject,
final StreamStatusMaintainer streamStatusMaintainer,
final OperatorChain operatorChain) throws Exception {
run(lockingObject, streamStatusMaintainer, output, operatorChain);
}
public void run(final Object lockingObject,
final StreamStatusMaintainer streamStatusMaintainer,
final Output> collector,
final OperatorChain operatorChain) throws Exception {
final TimeCharacteristic timeCharacteristic = getOperatorConfig().getTimeCharacteristic();
final Configuration configuration = this.getContainingTask().getEnvironment().getTaskManagerInfo().getConfiguration();
final long latencyTrackingInterval = getExecutionConfig().isLatencyTrackingConfigured()
? getExecutionConfig().getLatencyTrackingInterval()
: configuration.getLong(MetricOptions.LATENCY_INTERVAL);
LatencyMarksEmitter latencyEmitter = null;
if (latencyTrackingInterval > 0) {
latencyEmitter = new LatencyMarksEmitter<>(
getProcessingTimeService(),
collector,
latencyTrackingInterval,
this.getOperatorID(),
getRuntimeContext().getIndexOfThisSubtask());
}
final long watermarkInterval = getRuntimeContext().getExecutionConfig().getAutoWatermarkInterval();
this.ctx = StreamSourceContexts.getSourceContext(
timeCharacteristic,
getProcessingTimeService(),
lockingObject,
streamStatusMaintainer,
collector,
watermarkInterval,
idleTimeout);
try {
userFunction.run(ctx);
// if we get here, then the user function either exited after being done (finite source)
// or the function was canceled or stopped. For the finite source case, we should emit
// a final watermark that indicates that we reached the end of event-time, and end inputs
// of the operator chain
if (!isCanceledOrStopped()) {
// in theory, the subclasses of StreamSource may implement the BoundedOneInput interface,
// so we still need the following call to end the input
synchronized (lockingObject) {
operatorChain.endHeadOperatorInput(1);
}
}
} finally {
if (latencyEmitter != null) {
latencyEmitter.close();
}
}
}
public void advanceToEndOfEventTime() {
if (!hasSentMaxWatermark) {
ctx.emitWatermark(Watermark.MAX_WATERMARK);
hasSentMaxWatermark = true;
}
}
@Override
public void close() throws Exception {
try {
super.close();
if (!isCanceledOrStopped() && ctx != null) {
advanceToEndOfEventTime();
}
} finally {
// make sure that the context is closed in any case
if (ctx != null) {
ctx.close();
}
}
}
public void cancel() {
// important: marking the source as stopped has to happen before the function is stopped.
// the flag that tracks this status is volatile, so the memory model also guarantees
// the happens-before relationship
markCanceledOrStopped();
userFunction.cancel();
// the context may not be initialized if the source was never running.
if (ctx != null) {
ctx.close();
}
}
/**
* Marks this source as canceled or stopped.
*
* cannot be interpreted as the result of a finite source.
*/
protected void markCanceledOrStopped() {
this.canceledOrStopped = true;
}
/**
* Checks whether the source has been canceled or stopped.
* @return True, if the source is canceled or stopped, false is not.
*/
protected boolean isCanceledOrStopped() {
return canceledOrStopped;
}
private static class LatencyMarksEmitter {
private final ScheduledFuture latencyMarkTimer;
public LatencyMarksEmitter(
final ProcessingTimeService processingTimeService,
final Output> output,
long latencyTrackingInterval,
final OperatorID operatorId,
final int subtaskIndex) {
latencyMarkTimer = processingTimeService.scheduleAtFixedRate(
new ProcessingTimeCallback() {
@Override
public void onProcessingTime(long timestamp) throws Exception {
try {
// ProcessingTimeService callbacks are executed under the checkpointing lock
output.emitLatencyMarker(new LatencyMarker(processingTimeService.getCurrentProcessingTime(), operatorId, subtaskIndex));
} catch (Throwable t) {
// we catch the Throwables here so that we don't trigger the processing
// timer services async exception handler
LOG.warn("Error while emitting latency marker.", t);
}
}
},
0L,
latencyTrackingInterval);
}
public void close() {
latencyMarkTimer.cancel(true);
}
}
}
注意上面添加了一个配置idleTimeout的配置项,这个配置下默认-1,也就是不生效,那么只要配置了这个数值,指定的时间不来数据flink系统就认为这个Partition没数据了,那么计算Watermark的时候就不考虑他了,等他有数据再把他列入计算Watermark的范畴。
然后在初始化过程中加入如下语句

2.3 withIdleness
flink 1.11新增了支持watermark空闲检测
WatermarkStrategy.withIdleness()方法允许用户在配置的时间内(即超时时间内)没有记录到达时将一个流标记为空闲,从而进一步支持 Flink 正确处理多个并发之间的事件时间倾斜的问题,
并且避免了空闲的并发延迟整个系统的事件时间。通过将 Kafka 连接器迁移至新的接口(FLINK-17669),用户可以受益于针对单个并发的空闲检测。

修改后kafka数据倾斜问题就不影响了。
3 深入分析
知其然,知其所以然
3.1 重写StreamSource
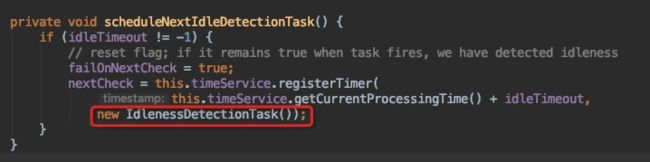
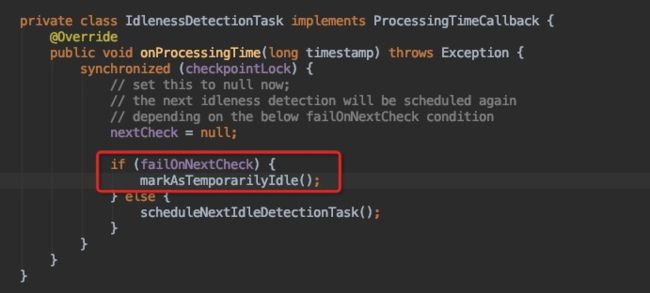
StreamSourceContexts.getSourceContext中,如果设置了idleTimeout,超时会发送idle标记,如下图所示。

3.2 withIdleness的实现原理
看一下1.11后flink是如何解决分区倾斜

如图所示,可以看到idle的触发,是一个动态的过程,当满足了idle条件就会触发idle使分区忽略,如果接受到数据就会重制为活跃分区。
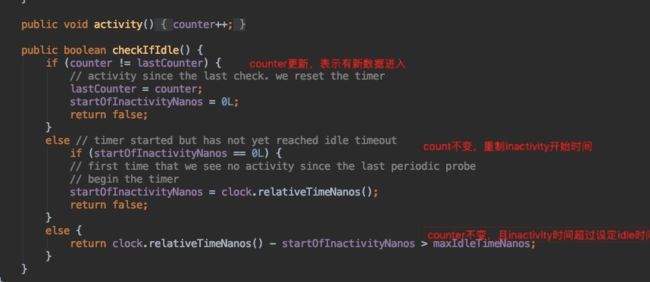
如图是idle条件的判断。
参考
数据倾斜参考
watermark实验