大师兄的Python学习笔记(二十三): 爬虫(四)
大师兄的Python学习笔记(二十五): 爬虫(六)
六、模拟浏览器爬取动态数据
- 随着反爬虫技术的进步,很多网站使用了各种各样的动态页面和数据加密方法,开发爬虫的成本越来越高。
- 与其花时间解析页面的反爬虫技术,不如直接模拟浏览器的行为爬取信息(就像在用鼠标点击)。
- 代价是速度会慢很多。
1. 使用Selenium
- Selenium是一个自动化测试工具包,可以让Python控制浏览器, 并模仿人操作的行为。
- 使用
pip install selenium或conda install selenium安装包。
1.1 配置工作
Selenium支持多种浏览器,比如Firefox、Edge、Chrome,还包括手机浏览器和无界面浏览器PhantomJS。
-
首先需要下载geckodriver 下载地址。

-
将解压后的geckodriver.exe放到浏览器文件夹下。

-
配置浏览器地址到操作系统环境变量。

重启Pycharm后,就可以控制浏览器了。
如果发生
selenium Message: permission denied错误,则需要使用管理员权限运行Pycharm。
1.2 控制浏览器
- 使用
selenium.webdriver.Firefox(profile=None)方法获得浏览起控制对象。 - 如果已经配置过浏览器环境变量,则无需填写浏览器位置。
- 根据浏览器不同,可以使用不同的方法初始化,比如
selenium.webdriver.Chrome()。
>>>from selenium import webdriver
>>>browser = webdriver.Firefox() # 获得火狐浏览器的模拟对象
>>>print(type(browser))
1.3 访问网页
- 使用
get(url)方法访问网页。
>>>from selenium import webdriver
>>>browser = webdriver.Firefox() # 获得火狐浏览器的模拟对象
>>>browser.get("https://www.baidu.com")
1.4 点击浏览器功能键
- 控制浏览器后,可以利用以下方法模拟点击浏览器功能键。
| 方法 | 按键 |
|---|---|
| browser.back() | 返回键 |
| browser.forward() | 前进键 |
| browser.refresh() | 刷新键 |
| browser.quit() | 关闭窗口 |
>>>from selenium import webdriver
>>>browser = webdriver.Firefox() # 获得火狐浏览器的模拟对象
>>>browser.get("https://www.baidu.com/")
>>>browser.quit()
1.5 元素定位
- Selenium支持多种元素定位方式:
| 属性 | 方法 |
|---|---|
| name定位 | find_element_by_name() |
| id定位 | find_element_by_id() |
| class定位 | find_element_by_class_name() |
| tag定位 | find_element_by_tag_name() |
| link定位 | find_element_by_link_text() |
| link模糊定位 | find_element_by_partial_link_text() |
| css选择器定位 | find_element_by_css_selector() |
| xpath定位 | find_element_by_xpath() |
>>>from selenium import webdriver
>>>browser = webdriver.Firefox() # 获得火狐浏览器的模拟对象
>>>browser.get("https://www.jd.com/")
>>>elem = browser.find_element_by_class_name('jd_container')
>>>print(elem)
- 也可以使用
find_element(by='id', value=None)函数定位节点,传入方法和值即可。
>>>from selenium import webdriver
>>>from selenium.webdriver.common.by import By
>>>browser = webdriver.Firefox() # 获得火狐浏览器的模拟对象
>>>browser.get("https://www.jd.com/")
>>>elem = browser.find_element(By.CLASS_NAME,'jd_container')
>>>print(elem)
- 如果要获得多个节点,则使用
find_elements(by='id', value=None)函数定位
>>>from selenium import webdriver
>>>from selenium.webdriver.common.by import By
>>>browser = webdriver.Firefox() # 获得火狐浏览器的模拟对象
>>>browser.get("https://www.jd.com/")
>>>elems = browser.find_elements(By.TAG_NAME,'div')
>>>print(len(elems))
453
1.6 元素操作
- Selenium可以使浏览器执行一些动作,比如:
1) 输入文字
- 使用
send_key()方法输入文字。- 使用
clear()方法清空文字。>>>from selenium import webdriver >>>from selenium.webdriver.common.by import By >>>browser = webdriver.Firefox() # 获得火狐浏览器的模拟对象 >>>browser.get("https://www.baidu.com/") >>>input = browser.find_element(By.CSS_SELECTOR,'.s_ipt') >>>input.send_keys('天问')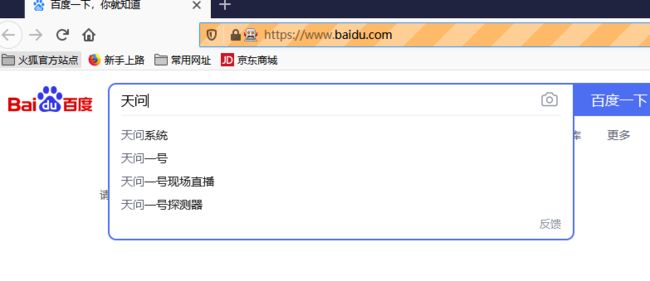
2) 提交表单
- 使用
submit()方法提交表单。>>>from selenium import webdriver >>>from selenium.webdriver.common.by import By >>>browser = webdriver.Firefox() # 获得火狐浏览器的模拟对象 >>>browser.get("https://www.baidu.com/") >>>input = browser.find_element(By.CSS_SELECTOR,'.s_ipt') >>>input.send_keys('天问') >>>input.submit()
3) 左键点击页面
- 使用
click()方法实现左键点击。>>>from selenium import webdriver >>>from selenium.webdriver.common.by import By >>>browser = webdriver.Firefox() # 获得火狐浏览器的模拟对象 >>>browser.get("https://www.baidu.com/") >>>input = browser.find_element(By.CSS_SELECTOR,'.s_ipt') # 找到搜索栏 >>>submit = browser.find_element(By.ID,'su') # 找到submit按键 >>>input.send_keys('天问') >>>submit.submit()
4) 发送特殊键
- 对于一些不能用字符串值输入的键,用
selenium.webdriver.common.keys模块的属性表示。
属性 键 Keys.Down, Keys.UP, Keys.LEFT, Keys.RIGHT 键盘箭头键 Keys.ENTER, Keys.RETURN 回车和换行键 Keys.HOME, Keys.END, Keys.PAGE_DOWN, Keys.PAGE_UP 小键盘home,end,down,up Keys.ESCAPE, Keys.BACK_SPACE, Keys.DELETE Esc, Backspace和Delete键 Keys.F1 - Keys.F12 F1-F12键 Keys.TAB tab键 >>>from selenium import webdriver >>>from selenium.webdriver.common.by import By >>>from selenium.webdriver.common.keys import Keys >>>browser = webdriver.Firefox() # 获得火狐浏览器的模拟对象 >>>browser.get("https://www.baidu.com/") >>>input = browser.find_element(By.CSS_SELECTOR,'.s_ipt') # 找到搜索栏 >>>input.send_keys('天问') >>>input.send_keys(Keys.BACK_SPACE) # 按一下backspace
1.7 动作链
- 动作链(ActionChains)可以在不指定目标节点的情况下实现动作。
- 动作链支持的动作比元素操作更丰富,包括:
| 方法 | 动作 |
|---|---|
| click(on_element=None) | 左键单击元素或当前位置 |
| click_and_hold(on_element=None) | 左键按住元素或当前位置 |
| context_click(on_element=None) | 右键单击元素或当前位置 |
| double_click(on_element=None) | 左键双击元素或当前位置 |
| drag_and_drop(source, target) | 拖拽元素到元素 |
| drag_and_drop_by_offset(source, xoffset, yoffset) | 拖拽元素到坐标 |
| key_down(value, element=None) | 按下某个键 |
| key_up(value, element=None) | 松开某个键 |
| move_by_offset(xoffset, yoffset) | 移动鼠标到坐标 |
| move_to_element(to_element) | 移动鼠标到元素 |
| move_to_element_with_offset(to_element, xoffset, yoffset) | 移动鼠标经过坐标到元素 |
| pause(seconds) | 暂停动作?秒 |
| perform() | 执行所有设置的动作 |
| release(on_element=None) | 抬起鼠标键 |
| reset_actions() | 清除已存储的动作 |
| send_keys(*keys_to_send) | 输入按键到当前元素 |
| send_keys_to_element(element, *keys_to_send) | 输入按键到指定元素 |
>>>from selenium import webdriver
>>>from selenium.webdriver import ActionChains
>>>browser = webdriver.Firefox() # 获得火狐浏览器的模拟对象
>>>browser.get("https://www.baidu.com/")
>>>elem = browser.find_element_by_tag_name('div')
>>>actions = ActionChains(browser)
>>>actions.context_click(elem)
>>>actions.perform()

1.8 执行页面JS
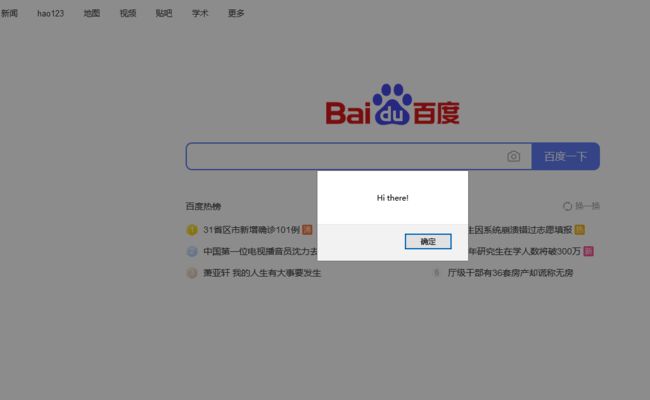
- 可以使用
execute_script()方法执行页面的JavaScript方法。
>>>from selenium import webdriver
>>>browser = webdriver.Firefox() # 获得火狐浏览器的模拟对象
>>>browser.get("https://www.baidu.com/")
>>>browser.execute_script('alert("Hi there!")')
1.9 获取元素的信息
- 在定位元素后,selenium也可以像bs4,pyquery一样获得元素的信息。
1) 获取属性
- 使用
get_attribute(name)方法获取元素属性。>>>from selenium import webdriver >>>from selenium.webdriver.common.by import By >>>browser = webdriver.Firefox() # 获得火狐浏览器的模拟对象 >>>browser.get("https://www.baidu.com/") >>>input = browser.find_element(By.CSS_SELECTOR,'.s_ipt') # 找到搜索栏 >>>print(input.get_attribute('class')) s_ipt2) 获取文本内容
- 使用
text属性获取文本内容。>>>from selenium import webdriver >>>from selenium.webdriver.common.by import By >>>browser = webdriver.Firefox() # 获得火狐浏览器的模拟对象 >>>browser.get("https://www.baidu.com/") >>>elem = browser.find_element(By.CLASS_NAME,'title-content-title') # 找到搜索栏 >>>print(elem.text) 31省区市新增确诊101例3) 获取其他属性
- 可以使用
id、location、tag_name、size获得对应属性。>>>from selenium import webdriver >>>from selenium.webdriver.common.by import By >>>browser = webdriver.Firefox() # 获得火狐浏览器的模拟对象 >>>browser.get("https://www.baidu.com/") >>>elem = browser.find_element(By.CLASS_NAME,'title-content-title') # 找到搜索栏 >>>print(elem.id) >>>print(elem.location) >>>print(elem.tag_name) >>>print(elem.size) 08152d64-0910-4d13-a779-d1413f215305 {'x': 343, 'y': 364} span {'height': 16.0, 'width': 152.0}
1.10 切换frame
- 使用
switch_to.frame(frame_reference)方法可以切换焦点到iframe。 - 不过现在用iframe的网站不多了。
>>>from selenium import webdriver
>>>from selenium.webdriver.common.by import By
>>>browser = webdriver.Firefox() # 获得火狐浏览器的模拟对象
>>>browser.get("https://www.runoob.com/try/try.php?filename=jqueryui-api-droppable")
>>>browser.switch_to.frame('iframeResult')
>>>print(browser.find_element_by_tag_name('div').id)
f22025d4-e23a-4fc8-b762-7afad154e487
1.11 延时操作
- 为了等待浏览器加载,有时需要进行延时操作。
1) implicity_wait(time_to_wait=0) 隐式等待
- 设置一个全局的等待时间,如果页面加载超过等待时间将报错。
>>>from selenium import webdriver >>>from selenium.common.exceptions import NoSuchElementException >>>browser = webdriver.Firefox() # 获得火狐浏览器的模拟对象 >>>browser.get("https://www.baidu.com") >>>browser.implicitly_wait(5) >>>try: >>> elem = browser.find_element_by_tag_name("not exist") >>>except NoSuchElementException as e: >>> print(e) Message: Unable to locate element: not exist2) WebDriverWait(driver, timeout, poll_frequency=0.5, ignored_exceptions=None) 显式等待
- 设定一个等待时间,如果指定元素加载时间超过等待时间将报错。
>>>from selenium import webdriver >>>from selenium.common.exceptions import TimeoutException >>>from selenium.webdriver.support.ui import WebDriverWait >>>from selenium.webdriver.support import expected_conditions as EC >>>from selenium.webdriver.common.by import By >>>browser = webdriver.Firefox() # 获得火狐浏览器的模拟对象 >>>browser.get("https://www.baidu.com") >>>wait = WebDriverWait(browser, 5) >>>try: >>> elem = wait.until(EC.presence_of_element_located((By.CLASS_NAME,'not exist'))) >>>except TimeoutException as e: >>> print(e) Message:3) time.sleep()
- 当然也可以使用
time.sleep(), 只是在等待时程序会被阻塞。
1.12 操作Cookies
1) 获取Cookies
- 使用
get_cookies()方法获取cookies。- 使用
get_cookie(name)方法获取指定cookie。>>>from selenium import webdriver >>>browser = webdriver.Firefox() # 获得火狐浏览器的模拟对象 >>>browser.get("https://www.baidu.com") >>>print(browser.get_cookies()) [{'name': 'BIDUPSID', 'value': 'BE5178FF29CB21C49CF5B5F9EBA5A178', 'path': '/', 'domain': '.baidu.com', 'secure': False, 'httpOnly': False, 'expiry': 3743553861}, {'name': 'PSTM', 'value': '1596070212', 'path': '/', 'domain': '.baidu.com', 'secure': False, 'httpOnly': False, 'expiry': 3743553861}, {'name': 'BAIDUID', 'value': 'BE5178FF29CB21C4CDCEFB0448819390:FG=1', 'path': '/', 'domain': '.baidu.com', 'secure': False, 'httpOnly': False, 'expiry': 1627606214}, {'name': 'BD_HOME', 'value': '1', 'path': '/', 'domain': 'www.baidu.com', 'secure': False, 'httpOnly': False}, {'name': 'H_PS_PSSID', 'value': '32294_1434_31670_32141_32045_32395_32429_32115_32436_32261', 'path': '/', 'domain': '.baidu.com', 'secure': False, 'httpOnly': False}, {'name': 'BD_UPN', 'value': '13314752', 'path': '/', 'domain': 'www.baidu.com', 'secure': False, 'httpOnly': False, 'expiry': 1596934215}]2) 增加Cookies
- 使用
add_cookie()方法添加Cookie。>>>from selenium import webdriver >>>browser = webdriver.Firefox() # 获得火狐浏览器的模拟对象 >>>browser.get("https://www.baidu.com") >>>cookie = { >>> 'name':'name', >>> 'domain':'www.baidu.com', >>> 'value':'superkmi' >>>} >>>browser.add_cookie(cookie) >>>print(browser.get_cookie('name')) {'name': 'name', 'value': 'superkmi', 'path': '/', 'domain': '.www.baidu.com', 'secure': False, 'httpOnly': False}3) 删除Cookies
- 使用
delete_all_cookies()方法删除所有cookies。- 使用
delete_cookie(name)方法删除指定cookie。>>>from selenium import webdriver >>>browser = webdriver.Firefox() # 获得火狐浏览器的模拟对象 >>>browser.get("https://www.baidu.com") >>>browser.delete_all_cookies() >>>print(browser.get_cookies()) []
1.13 切换选项卡
- 使用
switch_to.window(window_name)切换到不同的选项卡。 -
window_name可以通过browser的window_handles属性获得。
>>>from selenium import webdriver
>>>browser = webdriver.Firefox() # 获得火狐浏览器的模拟对象
>>>browser.get("https://www.baidu.com")
>>>browser.execute_script("window.open()") # 打开一个新的选项卡
>>>browser.switch_to.window(browser.window_handles[1]) # 切换到第二个选项卡
>>>browser.get("https://www.sina.com.cn")

1.14 异常处理
- Selenium的异常类存放在
selenium.common.exceptions,直接用try except语句处理即可。
>>>from selenium import webdriver
>>>from selenium.common.exceptions import InvalidArgumentException
>>>browser = webdriver.Firefox() # 获得火狐浏览器的模拟对象
>>>try:
>>> browser.get("not exist")
>>>except InvalidArgumentException as e:
>>> print(e.msg)
>>>Malformed URL: not exist is not a valid URL.
1.15 爬取京东商品案例
- 一个简单的案例,用于爬取京东商品数据。
>>>from selenium import webdriver
>>>from selenium.webdriver import ActionChains
>>>from selenium.webdriver.common.by import By
>>>from selenium.webdriver.common.keys import Keys
>>>from selenium.webdriver.support import expected_conditions as EC
>>>from selenium.webdriver.support.wait import WebDriverWait
>>>from selenium.common.exceptions import *
>>>from urllib import parse
>>>from pyquery import PyQuery as pq
>>>class jd_spider_sample():
>>> def __init__(self,kw,wait_time=10,page_num=1,target_page=10):
>>> self.url = "https://search.jd.com/Search?keyword="+parse.quote(kw)
>>> self.cur_page_num = page_num
>>> self.target_page = target_page
>>> self.browser = webdriver.Firefox()
>>> self.browser.implicitly_wait(wait_time)
>>> self.wait = WebDriverWait(self.browser,wait_time)
>>> self.products = []
>>> self.get_pages()
>>> def get_pages(self):
>>> # 遍历搜索页面
>>> try:
>>> self.browser.get(self.url)
>>> # 模拟翻页
>>> while self.cur_page_num < self.target_page:
>>> self.wait.until_not(
>>> EC.presence_of_element_located((By.CSS_SELECTOR, '.loading-style1'))) # 等loading标签消失
>>> actions = ActionChains(self.browser)
>>> actions.send_keys(Keys.RIGHT) # 京东按右键就可以翻页
>>> actions.perform()
>>> self.get_page_data(self.browser.page_source) # 获取页面html代码
>>> self.cur_page_num += 1
>>> except TimeoutException as e:
>>> print(e.msg)
>>> def get_page_data(self,page):
>>> # 解析html代码
>>> data = pq(page)
>>> items = data('.gl-item-presell .gl-i-wrap').items()
>>> for item in items:
>>> product = {
>>> 'name':item.find('.p-name em').text().replace('\n',''),
>>> 'price': float(item.find('.p-price i').text()),
>>> 'score':float(item.find('.buy-score>em').text()) if item.find('.buy-score>em').text() else 0,
>>> 'comment':item.find('.p-commit a').text(),
>>> 'shop':item.find('.p-shop a').text(),
>>> 'img': item.find('.p-img a img').attr('src'),
>>> 'link': item.find('.p-img>a').attr('href')
>>> }
>>> self.products.append(product)
>>> def show_result(self):
>>> # 按价格和评分排序后打印
>>> result = self.products
>>> result.sort(key=lambda k:(k.get("price"),k.get("score")),reverse=True) # 重新排序
>>> for i,data in enumerate(result):
>>> print(f"{i+1}. {data.get('name')} \n价格:{data.get('price')}元 \n评分:{data.get('score')} \n网店:{data.get('shop')} "
>>> f"\n评论数:{data.get('comment')} \n图片:{data.get('img')} \n链接:{data.get('link')}\n")
>>>if __name__ == '__main__':
>>> spider = jd_spider_sample("电视",page_num=1)
>>> spider.show_result()
1. 线下同款 索尼(SONY)KD-75X9500H 75英寸 4K超高清 HDR 液晶平板电视全面屏 X1旗舰版图像芯片 全阵列背光
价格:18999.0元
评分:10.0
网店:SONY京东自营官方旗舰店
评论数:1.3万+
图片://img13.360buyimg.com/n7/jfs/t1/84754/28/18878/271674/5e97d93bE4e2687ed/87c81d5a826be8fe.jpg
链接://item.jd.com/100006893993.html
2. 线下同款 索尼(SONY)KD-85X9000H 85英寸 4K HDR超高清液晶电视X1图像芯片 专业游戏模式 AI智能语音 安卓9.0
价格:18999.0元
评分:0
网店:SONY京东自营官方旗舰店
评论数:3300+
图片://img10.360buyimg.com/n7/jfs/t1/116422/5/5653/255413/5eb4f436Ed44fd99a/c16b76f7607ee776.jpg
链接://item.jd.com/100013149730.html
3. 京品家电 索尼(SONY)京品家电 KD-75X9100H 75英寸 4K超高清 全面屏AI智能电视X1图像芯片 专业游戏 4K 120帧输入
价格:13499.0元
评分:9.2
网店:SONY京东自营官方旗舰店
评论数:1.3万+
图片://img12.360buyimg.com/n7/jfs/t1/139273/34/1300/327463/5ef17810E06b3f939/7746df18780abb9f.jpg
链接://item.jd.com/100007346967.html
4. 海信(Hisense)85E7F 85英寸4K超高清 超薄全面屏 AI语音 液晶海信电视机
价格:12999.0元
评分:0
网店:海信电视旗舰店
评论数:70+
图片://img10.360buyimg.com/n7/jfs/t1/135769/10/5756/221595/5f2372b0Ebb8d3bdb/29c4052cfdf9b922.jpg
链接://item.jd.com/67420158670.html
5. 线下同款 索尼(SONY)KD-65X9500H 65英寸 4K超高清 HDR 液晶平板电视全面屏 X1旗舰版图像芯片
价格:10999.0元
评分:5.9
网店:SONY京东自营官方旗舰店
评论数:4.3万+
图片://img13.360buyimg.com/n7/jfs/t1/121400/2/1594/291493/5ebe0db6E80c2591d/db85a5f81c219fc3.jpg
链接://item.jd.com/100013299648.html
6. 线下同款 索尼(SONY)KD-75X8000H 75英寸 4K超高清 HDR 液晶平板电视智能家居 安卓9.0系统
价格:8699.0元
评分:9.2
网店:SONY京东自营官方旗舰店
评论数:1.3万+
图片://img14.360buyimg.com/n7/jfs/t1/144869/17/2804/353725/5f0bd9d5E4f38befc/d556a3325dadce46.jpg
链接://item.jd.com/100012583754.html
7. 海信(Hisense)75E7F 75英寸 4K 2+32GB AI声控 MEMC防抖 超薄悬浮全面屏 超高色域 教育 液晶电视机
价格:8599.0元
评分:10.0
网店:海信京东自营旗舰店
评论数:3万+
图片://img14.360buyimg.com/n7/jfs/t1/130726/16/5262/154818/5f1abefdEf302bbf7/e6d18b6db90936e4.jpg
链接://item.jd.com/100011529794.html
8. 线下同款 三星(SAMSUNG)65英寸Q70 QLED量子点 4K超高清 全阵列背光 HDR 教育资源液晶电视QA65Q70RAJXXZ 线下同款
价格:8589.0元
评分:10.0
网店:三星家电京东自营旗舰店
评论数:4.3万+
图片://img11.360buyimg.com/n7/jfs/t1/142358/13/2904/177046/5f0ea27fE9b39fa10/61c51ad9001a5f1d.jpg
链接://item.jd.com/100003314751.html
9. 线下同款 索尼(SONY)KD-55X9500H 55英寸 4K超高清 HDR 液晶平板电视全面屏 X1旗舰版图像芯片 全阵列背光
价格:6999.0元
评分:9.9
网店:SONY京东自营官方旗舰店
评论数:7万+
图片://img11.360buyimg.com/n7/jfs/t1/110787/25/4063/271674/5e97d57bEf3e65721/21607ee25e95d4bd.jpg
链接://item.jd.com/100006893991.html
10. 创维(SKYWORTH)65J9000 65英寸 4K超高清 智慧屏 防蓝光护眼 远场语音 超薄全面屏 教育电视2+32G内存
价格:6999.0元
评分:9.1
网店:创维电视京东自营旗舰店
评论数:2500+
图片://img11.360buyimg.com/n7/jfs/t1/142757/39/3939/146459/5f200f26Ee4e71929/b906384ce1e135a5.jpg
链接://item.jd.com/100006423611.html
... ...
2. 使用Splash
- Splash是一个类似于Selenium的轻量级自动化浏览器。
- 与Selenium相比,Splash是异步的。
- Splash带有HTTP API。
- Splash对接了Python中的Twisted和QT库。
2.1 实现功能
- 异步方式处理多个网页渲染过程;
- 获取渲染后的页面的源代码或截图;
- 通过关闭图片渲染或者使用Adblock(屏蔽广告)规则来加快页面渲染速度;
- 可执行特定的JavaScript脚本;
- 可通过Lua脚本来控制页面渲染过程;
- 获取渲染的详细过程并通过HAR(HTTP Archive)格式呈现。
2.2 安装和配置
此处仅以Win10专业版为例。
第一步: 安装Python的scrapy-splash包:
pip install scrapy-splash第二步: 下载Docker Windows版并安装。
-
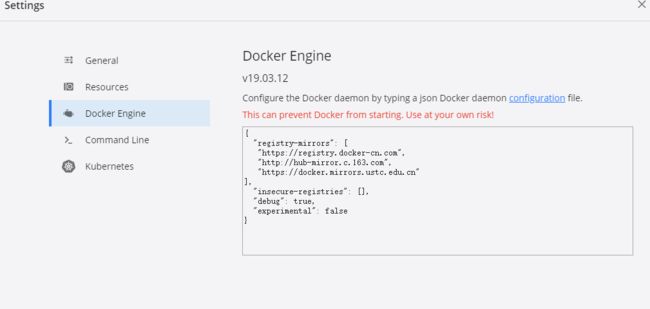
第三步:如果在国内,则需要配置镜像,点击docker->settings->Docker Engine, 配置如下
第四步:拉取镜像: 在cmd控制台输入
docker pull scrapinghub/splash第五步: 启动Splash: 在cmd控制台输入
docker run -p 8050:8050 -p 5023:5023 scrapinghub/splash-
第六步: 测试服务是否开启,如果服务正常开启,可以在本地访问Splash主页,如下图:

-
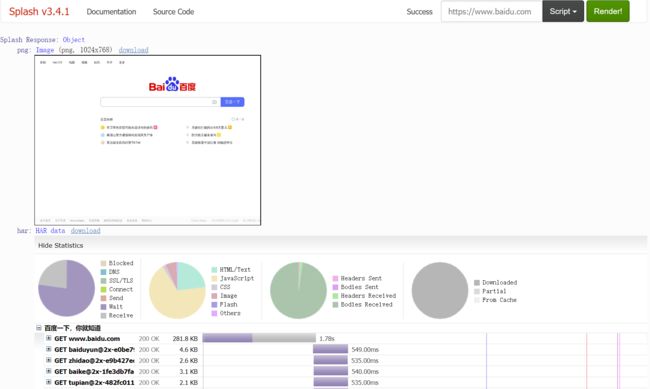
尝试用Splash渲染https://www.baidu.com,结果如下:
2.3 使用Python获取渲染页面
- 可以使用链接+参数的方式调用Splash API。
1) render.html
- 用于获取JavaScript渲染页面的HTML代码。
- 可以使用的参数:
参数 是否必选 类型 描述 url 必选 string 需要渲染页面的url timeout 可选 float 渲染页面超时时间 proxy 可选 string 代理服务器地址 wait 可选 float 等待页面渲染的时间 images 可选 integer 是否下载图片,默认为1 js_source 可选 string 用户自定义JavaScript代码,在页面渲染前执行 >>>import requests >>>url = 'http://localhost:8050/render.html?wait=0.5&timeout=90.0&url=https://www.baidu.com' >>>response = requests.get(url) >>>print(response.status_code) 2002) render.png
- 获得网页截图。
- 通过width和height参数指定截图的宽和高。
- 返回二进制图片数据。
>>>import requests >>>import os >>>url = 'http://localhost:8050/render.png?wait=0.5&timeout=90.0&url=https://www.baidu.com&width1024&768' >>>response = requests.get(url) >>>with open("sample.png","wb") as f: >>> f.write(response.content) >>>os.system("sample.png")
3) render.jpeg
- 与
render.png类似,但返回的是jpeg图片。- 增加了参数quality,用来设置图片质量。
>>>import requests >>>url = 'http://localhost:8050/render.jpeg?wait=0.5&timeout=90.0&quality=75&url=https://www.baidu.com&width1024&768' >>>response = requests.get(url) >>>print(response.status_code) 2004) render.HAR
- 获取页面加载的HAR数据。
>>>import requests >>>from pprint import pprint >>>url = 'http://localhost:8050/render.har?wait=0.5&timeout=90.0&url=https://www.baidu.com&width1024&768' >>>response = requests.get(url) >>>pprint(response.text) ('{"log": {"version": "1.2", "creator": {"name": "Splash", "version": ' '"3.4.1"}, "browser": {"name": "QWebKit", "version": "602.1", "comment": ' '"PyQt 5.13.1, Qt 5.13.1"}, "entries": [{"_splash_processing_state": ' '"finished", "startedDateTime": "2020-08-05T01:26:33.874870Z", "request": ' '{"method": "GET", "url": "https://www.baidu.com/", "httpVersion": ' '"HTTP/1.1", "cookies": [], "queryString": [], "headers": [{"name": ' ... ...5) render.json
- 以json格式返回相应的请求数据。
>>>import requests >>>from pprint import pprint >>>url = 'http://localhost:8050/render.json?>>>>wait=0.5&timeout=90.0&url=https://www.baidu.com&width1024&768' >>>response = requests.get(url) >>>pprint(response.text) ('{"url": "https://www.baidu.com/", "requestedUrl": "https://www.baidu.com/", ' '"geometry": [0, 0, 1024, 768], "title": ' '"\\u767e\\u5ea6\\u4e00\\u4e0b\\uff0c\\u4f60\\u5c31\\u77e5\\u9053"}')6) execute
- 用于执行LUA脚本。
>>>import requests >>>from urllib.parse import quote >>>lua_code = ''' >>> function main(splash) >>> return 'Hello World!' >>> end >>>''' >>>url = 'http://localhost:8050/execute?lua_source='+quote(lua_code) >>>response = requests.get(url) >>>print(response.text) Hello World!
参考资料
- https://blog.csdn.net/u010138758/article/details/80152151 J-Ombudsman
- https://www.cnblogs.com/zhuluqing/p/8832205.html moisiet
- https://www.runoob.com 菜鸟教程
- http://www.tulingxueyuan.com/ 北京图灵学院
- http://www.imooc.com/article/19184?block_id=tuijian_wz#child_5_1 两点水
- https://blog.csdn.net/weixin_44213550/article/details/91346411 python老菜鸟
- https://realpython.com/python-string-formatting/ Dan Bader
- https://www.liaoxuefeng.com/ 廖雪峰
- https://blog.csdn.net/Gnewocean/article/details/85319590 新海说
- https://www.cnblogs.com/Nicholas0707/p/9021672.html Nicholas
- https://www.cnblogs.com/dalaoban/p/9331113.html 超天大圣
- https://blog.csdn.net/zhubao124/article/details/81662775 zhubao124
- https://blog.csdn.net/z59d8m6e40/article/details/72871485 z59d8m6e40
- https://www.jianshu.com/p/2b04f5eb5785 MR_ChanHwang
- 《Python学习手册》Mark Lutz
- 《Python编程 从入门到实践》Eric Matthes
- 《Python3网络爬虫开发实战》崔庆才
本文作者:大师兄(superkmi)