论文:

论文题目:《Multi-Interest Network with Dynamic Routing for Recommendation at Tmall》
论文地址:https://arxiv.org/pdf/1904.08030v1.pdf
前面讲的论文大部分都是关于排序的算法,mind作为天猫商城召回阶段的算法,还是很值得阅读的。
一 、背景
主流的推荐系统一般都分为matching(召回)和rangking(排序)两个阶段,不管在哪个阶段,都要学习和表示用户的兴趣向量。因此,最关键的能力是为任一阶段建模并得到能代表用户兴趣的向量。现有的大多数基于深度学习的模型都将一个用户表示为一个向量,如YoutubeDNN那篇论文,不足以捕获用户兴趣的不断变化的特点。基于以上原因,天猫提出了Mind方法,通过不同的视角来解决这个问题,并且用不同的向量来表示从用户不同方面的兴趣。
天猫商城也是分为了召回和排序两个阶段,召回阶段的主要目标就是从亿级别的商品库中筛选出千级别的候选物品给排序阶段使用。在天猫场景下,用户每天都要与成百上千的商品发生交互,用户的兴趣表现得多种多样。如下图所示,不同的用户之间兴趣不相同,同时同一个用户也会表现出多样的兴趣:

现在主流的召回阶段用到的召回算法要么是基于协同过滤的算法,要么是基于embedding召回的方法,但是这两个方法都有缺陷。协同过滤算法有着稀疏性和计算存储瓶颈方面的缺点,embedding的向量召回方法也有着几个缺点,一个是单一的向量无法准确表达出用户多种多样的兴趣,除非把这个向量长度变得特别大,还有一个就是,只有一个embedding会造成一定的头部效应,召回的结果往往是比较热门领域的商品(头部问题),对于较为小众领域的商品,召回能力不足,也就是更容易造成马太效应。
正如我们在第一段话中阐述的那样,如果单个兴趣向量没法做到将所有的用户兴趣点覆盖,那么就多搞几个向量,几个向量同时来表示用户的兴趣点不就行了吗?事实证明这么做确实是可以的,而且天猫也通过这种方法大大提高了召回的效果。
二 、模型
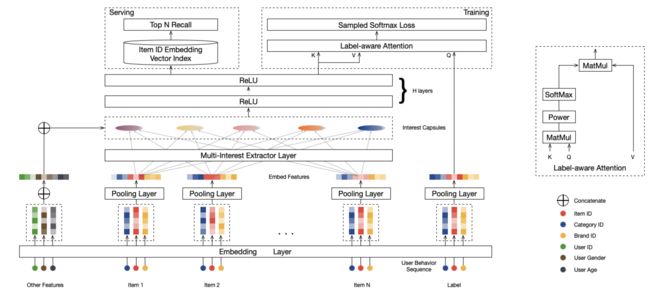
简单的先来看一下这个模型的架构,还是浓浓的阿里味,不管是item还是user在生成属于自己的向量的时候都会加上side information,这也是跟din,dien中一样传承下来的东西。整个模型关键的部分就在于这个Multi-Interest Extractor Layer层,后面我们就重点来讲一下这个层。
2.1 问题概述
召回阶段的目标是对于每个用户u∈U的请求,从亿级的商品池I中,选择成百上千的符合用户兴趣的商品候选集。每条样本可以表示成三元组(Iu,Pu,Fi),其中Iu是用户u历史交互过的商品集合,Pu是用户画像信息,比如年龄和性别,Fi是目标商品的特征,如商品ID、商品品类ID。
那么MIND的核心任务是将用户相关的特征转换成一系列的用户兴趣向量:
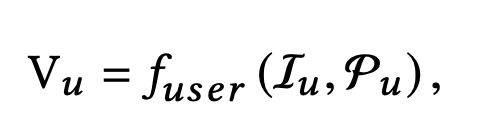
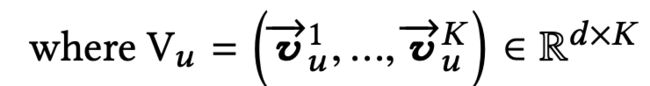
接下来就是item的embedding了:
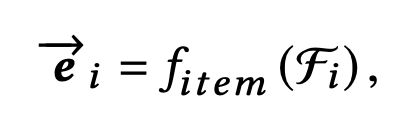
说白了f函数就是个embedding+pooling层。
我们有了用户的兴趣向量和物品向量e后,就可以通过如下的score公式计算得到topN的商品候选集:
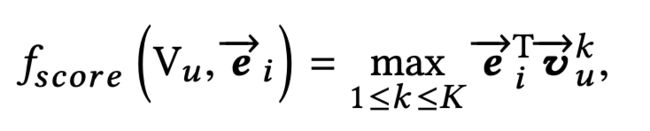
这个score的计算过程过其实是对这K个向量分别计算出一个分数然后取最大对那个。有了每个用户的兴趣向量后,我们就能对所有对item求一个分数,这样直接取topN就可以得到N个候选物品了。
2.2 Embedding Layer
这一层跟我们之前介绍的论文din,dien中的操作是类似的。在user embedding中,输入部分包括user_id,还包括gender,city等用户画像信息,分别做完embedding后直接concat起来就得到用户的embedding。跟user侧不同的item embedding则是采用pooling操作来得到item embedding,将商品ID、品牌ID、店铺ID分别做embedding后再用avg pooling。
2.3 Multi-Interest Extractor Layer
这部分就是整个mind最关键的地方了,下面会进行详细讲解。
我们认为,通过一个表示向量表示用户兴趣可能是捕获用户的多种兴趣的瓶颈,因为我们必须将与用户的多种兴趣相关的所有信息压缩到一个表示向量中。 因此,关于用户的不同兴趣的所有信息混合在一起,从而导致在匹配阶段的项目检索不准确。所以,mind采用了多个兴趣向量来表示用户的不同兴趣。 通过这种方式,可以在召回阶段分别考虑用户的不同兴趣,从而可以针对兴趣的各个方面进行更准确的检索。
Multi-Interest Extractor Layer,借鉴的是Hiton提出的胶囊网络。有关胶囊网络,下面的图可以帮助你快速理解(源于知乎:https://zhuanlan.zhihu.com/p/68897114):
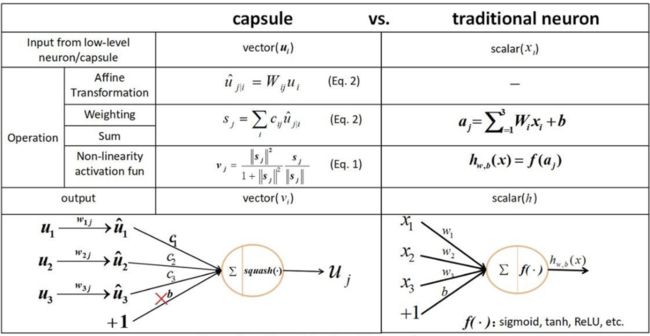
可以看到,胶囊网络和传统的神经网络较为类似。传统神经网络输入一堆标量,首先对这堆标量进行加权求和,然后通过非线性的激活函数得到一个标量输出。而对胶囊网络来说,这里输入的是一堆向量,这里的计算是一个迭代的过程,每次对输入的向量,先进行仿射变换,然后进行加权求和,最后用非线性的squash操作得到输出向量,可以看到胶囊网络的的输入跟输出还是跟传统DNN不一样的。
但是,针对图像数据提出的原始路由算法不能直接应用于处理用户行为数据。 因此,我们提出了“行为到兴趣(B2I)”动态路由,用于将用户的行为自适应地汇总到兴趣表示向量中,这与原始路由算法在三个方面有所不同。
1.共享双向线性映射矩阵
在胶囊网络中,每一个输入向量和输出向量之间都有一个单独的双向映射矩阵,但是MIND中,仿射矩阵只有一个,所有向量之间共享同一个仿射矩阵。
主要原因:一方面,用户行为的长度是可变的,天猫用户的行为范围是几十到几百,因此固定双线性映射矩阵的使用是可推广的,同时也减少了大量的参数。 另一方面,我们希望兴趣胶囊位于相同的向量空间中,但是不同的双线性映射矩阵会将兴趣胶囊映射到不同的向量空间中。因此,映射的逻辑变成了:
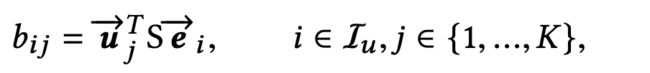
其中ei是用户行为中的item i的embedding,uj是兴趣胶囊j的向量。
2. 随机初始化胶囊网络的权值
在原始的胶囊网络中,映射矩阵是初始化为0的,但是这样会导致几个问题。将路由对数初始化为零将导致相同的初始兴趣胶囊。从而,随后的迭代将陷入一种情况,在这种情况下,不同的关注点胶囊始终保持相同。这跟我们的意图是不一致的,我们希望生成不同的用户兴趣向量。因此,我们在初始化的时候,让胶囊网络中权重的初始化由全部设置为0变为基于正太分布的初始化。
这里随机初始化的是bij而不是S,也就是胶囊映射逻辑矩阵,S是双向映射矩阵,不要搞混了。
3. 动态的用户兴趣数量
由于不同用户拥有的兴趣胶囊数量可能不同,因此我们引入了启发式规则,用于针对不同用户自适应地调整K的值。 具体来说,用户u的K值由下式计算:

动态的调整会让那些兴趣点较少的用户节省一部分计算和存储资源。
整个Multi-Interest Extractor Layer的计算过程如下:

看到这里我有个疑惑,在于算法的第7点,我们的是用正太分布初始化的矩阵跟双向仿射变化后的向量相加的结果,这一点我在论文中并没有得到很好的理解,也就是说,本来是全零的,现在是用标准正态分布初始化后在去跟双向映射完的向量叠加吗?
还有一个疑问就是,针对每一个j,我们利用所有的behavior的i计算得到一个向量uj,其实感觉应该就是在bij的计算上是不同的,只有bij的计算不同才会产生不同的wij,这样的话也就是说每一轮的bij都是有上一轮的结果来生成的意思?
关于这两点我还是没能搞清楚,以我现在已有的知识来看,每次生成uj后都会利用整个uj去生成下一个bij,跟dcn里面的cross network有点类似,但是说不上来是为什么这么做,可能是这样计算保持来序列计算的特性。
从图中我们也可以清楚的看出来,通过Multi-Interest Extractor Layer,我们得到了多个用户向量表示。接下来,每个向量与用户画像embedding进行拼接,经过两层全连接层(激活函数为Relu)得到多个用户兴趣向量表示。每个兴趣向量表征用户某一方面的兴趣。
2.4 Label-aware Attention Layer

我们在前面获得了多个用户的兴趣向量,那么该如何知道这些兴趣向量中哪些是重要的,哪些是可以忽视的呢?这时候attention就派上了用场,正如我们在din中对用户历史行为中的每个item计算weight一样,我们在这个地方也构建一个一个attention网络,用来计算不同兴趣点的weight。
看一下上面的attention网络在结合一下整个mind的模型结构不难得出,这个attention网络的q是候选item的embedding,k,v都是用户的兴趣向量。
attention的计算公式为:

其中,除了计算vu跟ei的内积意外,mind还对这个内积进行了指数运算,这个p值起到了一个平滑对作用,到p接近0的时候,所有的weight是相近的,意味着每个兴趣点都会被关注到。到p大于1的时候,有些weight就会变得很大,而有些就会变得很小,相当于加强了跟candidate item强相关的兴趣点的权值,削弱了弱相关兴趣点的权值,此时更类似于一种hard attention,即直接选择attention score最大的那个向量。实验也证明了,hard attention的方法收敛得更快。
2.5 Training and Serving
通过label attention网络,我们得到了代表用户u的兴趣向量,有了这个向量,我们就可以计算用户u点击item i的概率了,计算方式如下:
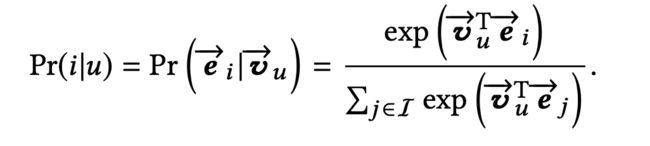
目标函数为:
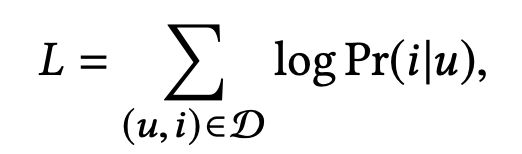
这个L不是损失函数,可以理解为极大似然函数,我们的目标就是让这个东西最大。
当然,在一个具有亿级别item的网站中,我们是不会采用原始的softmax操作的,跟在skip gram中的sample softmax类似,mind也采用了sample softmax的做法,大大减少了运算量。
而在serving阶段,只需要计算用户的多个兴趣向量,然后每个兴趣向量通过最近邻方法(如局部敏感哈希LSH)来得到最相似的候选商品集合。我们只需要输入用户的历史序列和画像信息,就可以得到用户的兴趣向量,所以当用户产生了一个新的交互行为,MIND也是可以实时响应得到用户新的兴趣向量。这里相当于把label attention舍弃掉了,直接用剩下的部分来得到用户的兴趣向量。
serving阶段跟training阶段对于用户的兴趣向量的处理是不一样的,在serving阶段,由于我们有多个兴趣向量,所以score的计算方式就变成了取最大的那个:
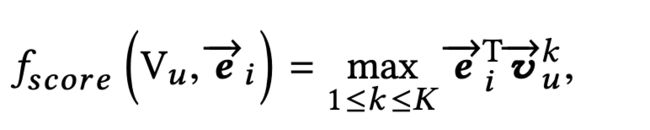
三、实验
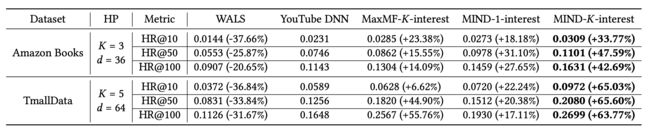
mind选择了跟他比较相近的YoutubeDNN进行对比,对比结果如下:
此外,论文还提到了DIN,在获得用户的不同兴趣方面,MIND和DIN具有相似的目标。 但是,这两种方法在实现目标的方式和适用性方面有所不同。 为了处理多样化的兴趣,DIN在item级别应用了注意力机制,而MIND使用动态路由生成兴趣,并在兴趣级别考虑了多样性。 此外,DIN着重于排名阶段,因为它处理成千或者万级别的item,但是MIND取消了推断用户表示和衡量user-item兼容性的过程,从而使其在匹配阶段适用于数十亿个项目。