使用SQL语句对数据操作的基本方法
文章目录
- 前言
- 一、导入数据
- 二、基础语法
-
- 1.查询数据
- 2.删除数据
- 3.更新数据
- 4.插入数据
- 三、数据筛选和排序
-
- 1.精确查询&&模糊查询
- 四、使用函数计算数据
- 五、对数据进行分类汇总
- 六、联表查询
- 七、结果导出
前言
提示:本文采用招聘数据进行分析,数据可以私信我。
一、导入数据
提示:这里使用Navicat Premium(可多重连接的数据库管理开发工具)。
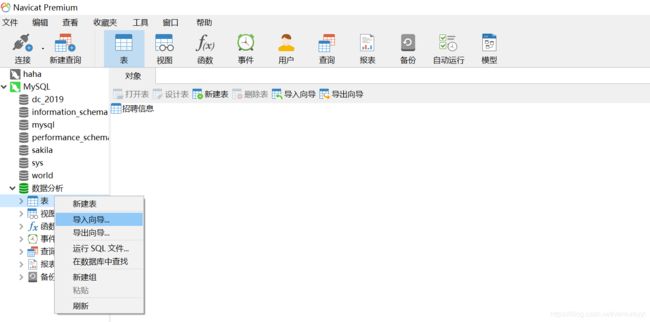
接着选择对应文件的类型,将数据导入进来
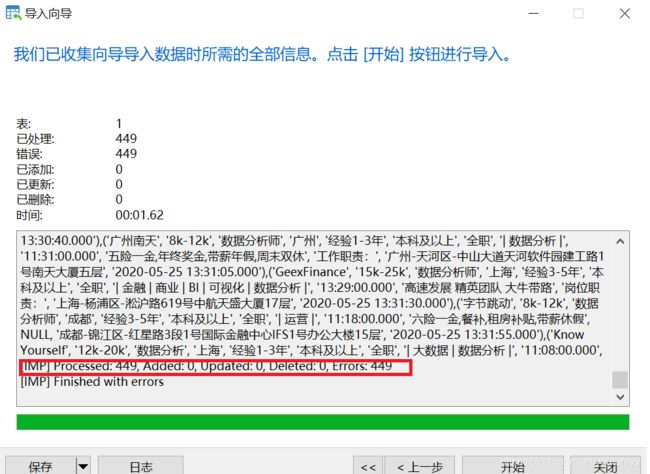
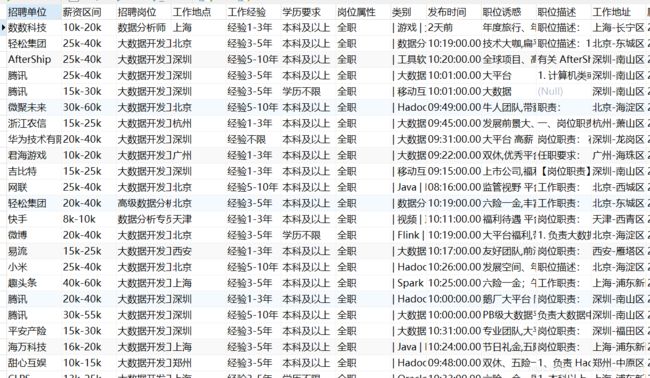
这里说明我们处理了449条数据,增加了0条数据,同时错误的有449条——>说明没有导入表中。
现在我们对数据导入情况进行分析发现:
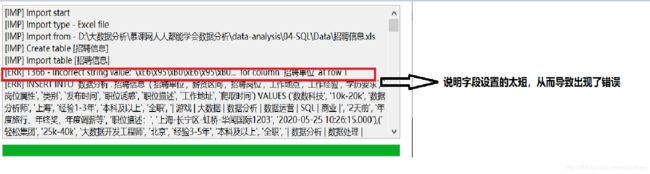
此时我们先将其导入,然后通过设计表来修改其字段大小
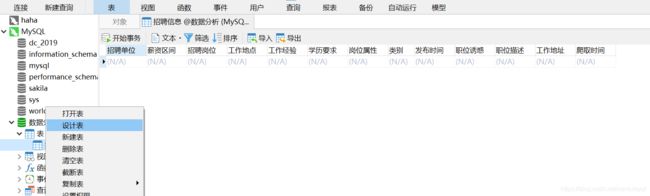

然后对表重新导入,就可以成功导入数据了

导入结果展示:
二、基础语法
1.查询数据

2.删除数据
没有删除前:
进行删除操作:
![]()
3.更新数据

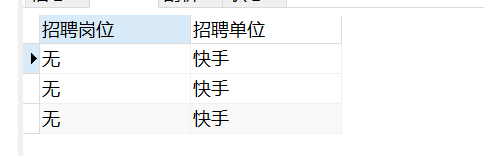
进行操作后三条数据被影响

进行修改结果验证
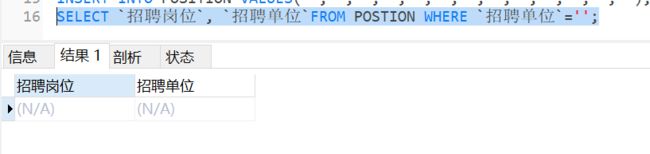
SELECT 招聘岗位, 招聘单位FROM POSTION WHERE 招聘单位=‘快手’;
4.插入数据
![]()
进行查找插入数据
三、数据筛选和排序
1.精确查询&&模糊查询
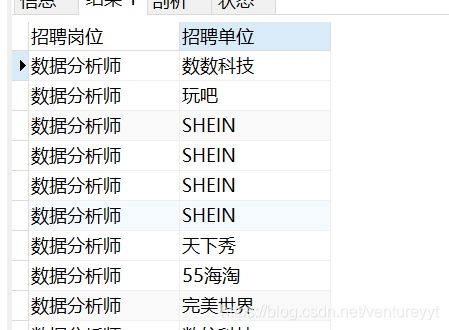
(1)招聘岗位是数据分析师的所有记录
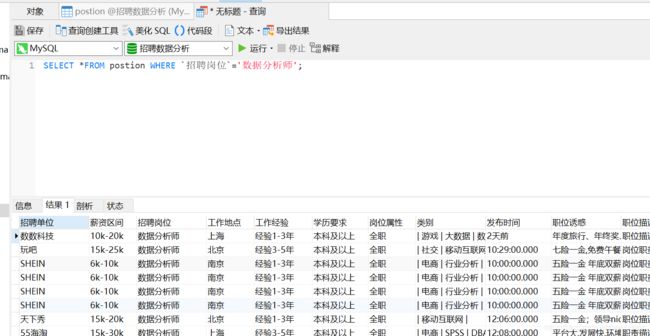
(2)like%
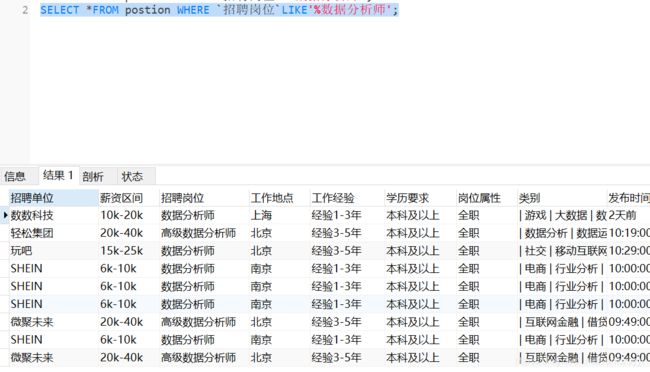
(3)多个目标岗位 in()
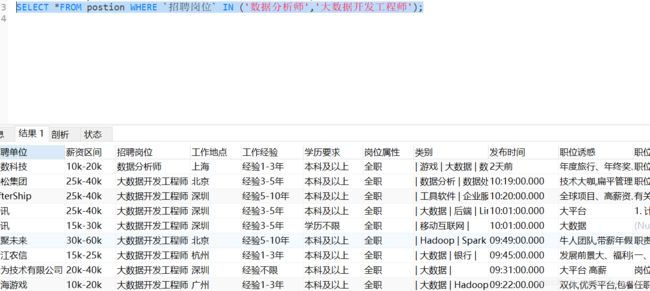
(4)排除法 not
排除1~3年工作经验的人
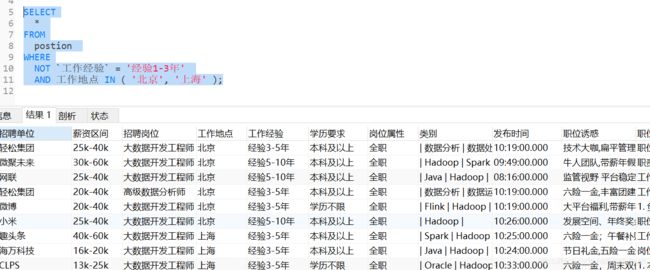
进行优化:我们想要进行排序划分,使用order by (注意,order by有优先级离它越近优先级越高)
SELECT
*
FROM
postion
WHERE
NOT `工作经验` = '经验1-3年'
AND 工作地点 IN ( '北京', '上海' )
ORDER BY
`招聘单位`,
`工作地点`,
`薪资区间`;
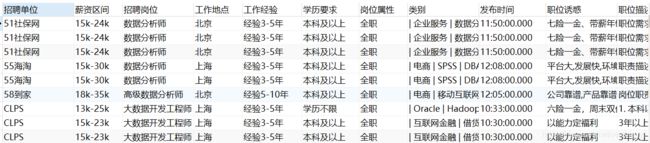
四、使用函数计算数据
SELECT COUNT(`招聘单位`)FROM postion; #对正在招聘的单位计次
SELECT COUNT(DISTINCT`招聘单位`)FROM postion; #加上distinct目的去重后,在进行计次
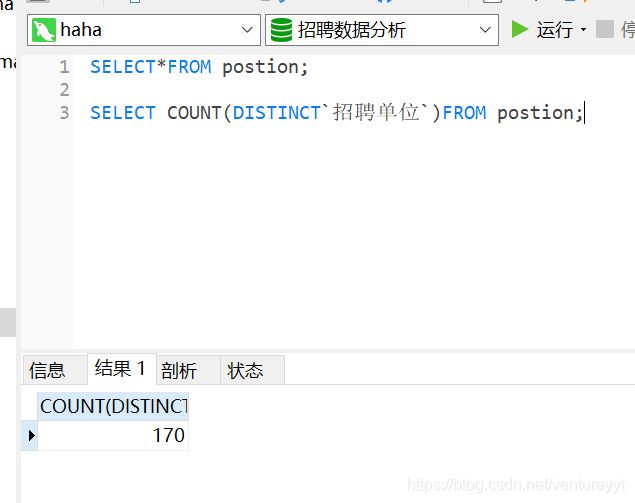
1、对薪资区间进行平均值的计算
(1)最大值
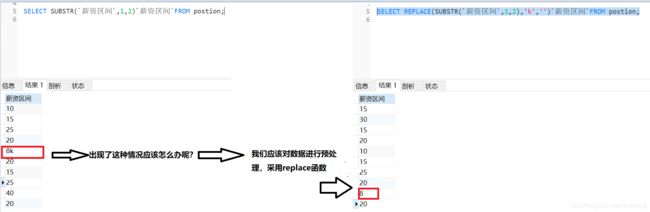
SELECT REPLACE(SUBSTR(`薪资区间`,1,2),'k','')`薪资区间`FROM postion;
#1代表从1开始,2为截取的区间长度
SELECT AVG(REPLACE(SUBSTR(`薪资区间`,1,2),'k',''))FROM postion;
#结果为:15.200445434298441
(2)最小值
SELECT
AVG(
REPLACE ( REPLACE ( SUBSTR( `薪资区间`, 4, 3 ), '-', '' ), 'k', '' ))
FROM
postion;
#结果:25.99554565701559
(3)合并
SELECT
AVG(
REPLACE ( SUBSTR( `薪资区间`, 1, 2 ), 'k', '' ))* 1000 AS 最低薪酬,
AVG(
REPLACE ( REPLACE ( SUBSTR( `薪资区间`, 4, 3 ), '-', '' ), 'k', '' ))* 1000 AS 最高薪酬
FROM
postion;
#结果:25995.54565701559
五、对数据进行分类汇总
执行顺序:FROM——>WHERE——>GROUP BY(去重分组)——>SELECT
SELECT `招聘单位`,COUNT(`招聘单位`)AS 频数
FROM postion GROUP BY `招聘单位` ORDER BY 频数;
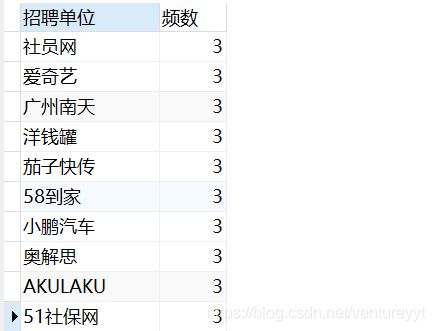
注:ROUND()函数可以设置小数位,设0时表示不留小数位
六、联表查询
1、查询多张表,可以一次性通过结果集的方式浏览——>关键在与公用信息
(通过共同信息项进行信息的提取)
导入新表,我们对city和position进行链表查询
SELECT * FROM postion,city;
如果没有条件直接查询,得到的结果是两张表的横向拼接
SELECT
`招聘单位`,
`招聘岗位`,工作地点,城市名称,城市划分
FROM
postion,
city
WHERE
工作地点 = 城市名称;
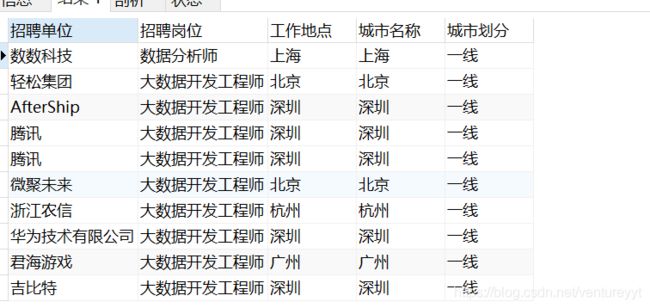 2、轴向合并
2、轴向合并
SELECT `工作地点`FROM postion
UNION
SELECT 城市名称 FROM city ORDER BY `工作地点`;
七、结果导出
 **再会~**