Deep Entity Classification: Abusive Account Detection for Online Social Networks 阅读笔记
Deep Entity Classification: Abusive Account Detection for Online Social Networks(深度实体分类:在线社交网络的滥用帐户检测)
一、key words
- ML: machine learning(机器学习)
- DEC: Deep Entity Classification (深层实体分类)
- MS-MTL: multi-stage multi-task learning(多阶段多任务学习)
- Precision(精确率): 表示的是预测为正的样本中有多少是真正的正样本
- Recall(召回率): 它表示的是样本中的正例有多少被预测正确了
- sparse aggregated features (稀疏聚合特征):
- Embeddings(嵌入): 深度学习的任务就是把高维原始数据(图像,句子)映射到低维流形,使得高维的原始数据被映射到低维流形之后变得可分,而这个映射就叫嵌入(Embedding)。Embedding就是从原始数据提取出来的Feature,也就是那个通过神经网络映射之后的低维向量。
- fan-out: 模块的扇出是指模块的直属下层模块的个数。
- box-cox变换: Box-Cox变换是统计建模中常用的一种数据变换,用于连续的响应变量不满足正态分布的情况。Box-Cox变换之后,可以一定程度上减小不可观测的误差和预测变量的相关性。Box-Cox变换的主要特点是引入一个参数,通过数据本身估计该参数进而确定应采取的数据变换形式,Box-Cox变换可以明显地改善数据的正态性、对称性和方差相等性,对许多实际数据都是行之有效的。
- binary cross-entropy(二值交叉熵): 是一种损失函数。
二、Abstract
- 面临的挑战: 基于机器学习的方法需要大量的真实标记数据对模型进行训练,而且想要将检测方法扩展到社交网络上所有账户的检测是困难的。
- 为了解决上述的挑战,作者提出了新的方法:Deep Entity Classification。这是一个机器学习框架,用于检测在OSN中逃避其他传统滥用检测系统的滥用帐户。
- 系统介绍:
- 通过汇总社交图中的直接和间接邻居的属性和行为特征来提取帐户的“深层特征”
- 采用“多阶段多任务学习”(MS-MTL)范式,通过在不同阶段使用少量高精度人工标记样本和大量低精度自动标记样本,来利用不精确的基础事实数据。这种架构产生了一个单一的模型,为多种类型的滥用帐户提供了高精度的分类。
- 通过各种减少系统负载的采样和重新分类策略,可扩展到数十亿用户。
- 该系统部署在face book上。
三、Introduction
- 滥用假账户在OSN中很多,如何制作具有可扩展性和精确性的程序去检测这些假账户。
- Rule-based heuristics act(基于规则的启发式方法): 基于规则的启发式方法是第一道防线,用于确定基本或常见的攻击者工具,技术和资源。它们专注于准确性而不是recall(召回率),它们通常无法捕捉到帐户行为的复杂性,并且根据定义它们是被动的。
- Machine learning systems: 克服了Rule-based heuristics act的一些问题:它们可以从过去的标签数据中进行泛化以提高召回率,并且可以随着时间的推移对其进行迭代以适应对抗性发展。但是,精确的机器学习系统需要大量高质量的带标签的地面事实数据,部署成本可能很高(无论是在工程上还是在计算资源上),并且可以被学习模仿真实帐户外观的对手所规避。
- 以上两种方法可以检测出一般的社交网站账户滥用问题,但是要确定其余难以分类的帐户(与真实用户非常相似和/或逃避OSN防御的帐户),则需要根本不同且更复杂的解决方案
- Deep Entity Classification: 作者提出的新的检测方法,这种方法不是根据用户的直接特征或是行为对账户进行分类。而是利用了特殊的网络结构,通过在图表中操作为每个帐户提取了20000多个特征。
- 系统面临的挑战:
1. 如果单纯地应用特征空间,大特征空间会显著地增加底层模型的复杂度,导致不合时宜的泛化和性能下降。
2. 要想在如此多的特征中获得正确的泛化,就需要在一个问题空间中进行大量的训练,在这个问题空间中,很难获得数十亿用户规模的高质量的人工标记数据。 - DEC的第二个关键见解是,除了小规模、高质量的人类标记数据外,还可以利用基于规则的启发式结果作为附加的“近似值”
- MS-MTL(多阶段多任务学习): 作者的框架通过使用高容量近似值训练的深度神经网络来导出低维可转换表示,然后根据所学的表示和高质量的人类标记数据对专用模型进行微调
- 模型训练的两个阶段:
- 使用大量精度较低的近似标签在收集的特征上训练多任务深度神经网络。
- 由于这些精度较低的信号所标识的帐户显示出多种不同的滥用类型(例如,垃圾邮件,令人反感的内容或恶意软件),因此我们为每种滥用类型制定了学习“任务”。然后,我们提取神经网络的倒数第二层作为低维特征向量。该向量被输入到模型的第二阶段,该模型的第二阶段使用带有标准二进制分类器的每任务( per-task)高精度人类标记数据进行训练。
- 大致的检测步骤: 检测滥用账户 —> 标记不同的滥用类型
- MS-MTL允许DEC在第一个模型阶段学习不同滥用类型的基本通用表示,然后在第二个阶段使用不同模型的高精度数据来区分不同的滥用类型,从而为每个帐户的每个滥用类型评分。
- 作者贡献:
- DEC的算法设计、系统架构和实现
- 创造了“深层特征”的新颖特征提取过程
- MS-MTL分类范例,允许我们使用单一模型架构为每个滥用类别产生高精度分类器(第6节)。
- 对DEC和MS-MTL相对于其他方法的定量评估,以及对DEC对脸谱网上其他系统(即最难分类的系统)未捕捉到的滥用账户的总体状态的影响的定性评估。
- 讨论从Facebook两年的生产部署中吸取的经验教训。
四、Background
1、滥用账户(Abusive Accounts)
- 滥用账户的定义: 违反OSN给定的规则的任意账户。
- 滥用账户分类:
- 按账户来源分类: 账户可能是假的,即账户不代表真实的账户或组织。另一种是合法的真实账户,但是被攻击者所利用。
- 按滥用行为来分类: 滥用帐户可以通过其所实施的滥用类型来进行分类。
2、防御方法( Defenses)
- Rule-based heuristics(基于规则的启发式方法): 例如通过阈值对用户的操作速率进行限制。缺点是:在超过阈值前允许一定量的滥用,更注重判断的准确性而不关注召回率。
- machine learning-based classification(基于机器学习的分类): 他的缺点一是分类的特征容易被攻击者发现,然后攻击者可以适应并规避分类。缺点二是分类器需要大量的高精度的训练数据,成本高。
- 本文方法: 本文中介绍的系统旨在通过在社交图上使用稀疏聚合特征(攻击者很难操纵这些特征)以及使用多阶段训练框架来缓解这些问题。
3、机器学习术语( sparse aggregated features )
- Deep Neural Networks(深层神经网络): DEC的第一阶段使用了深度神经网络(DNN)架构。
- Embeddings(嵌入): Embedding就是从原始数据提取出来的Feature,也就是那个通过神经网络映射之后的低维向量。
- Gradient Boosted Decision Trees(梯度增强决策树): DEC第一阶段最后一层深度神经网络的嵌入被用作DEC第二阶段训练的输入特征向量,该训练使用梯度增强决策树(GBDTs)模型。
五、Related Work
作者根据技术将已发表的成果分为三类,并描述了相关的机器学习文献,作者在这个部分对前人的工作做了总结概述,并提出了自己工作与他们工作的不同。
1、Detecting Abusive Accounts(检测滥用账户)
- 一些工作已经探索了使用图结构和相邻节点的特征来检测滥用。而作者的工作是创建了一个基于图形、直接和间接邻居特征(“深层实体”)的通用机器学习框架(在许多其他特征中利用这些特征),该框架可扩展到数十亿社交网络用户。
2、 Sybil Accounts(Sybil账户)
- 西比尔攻击是指个别恶意用户以多个假身份多次加入OSN的攻击
3、User Footprint(用户足迹)
- “用户足迹”是一种信号,可用于识别同一用户在不同操作系统中的行为。如果一个用户在一个平台上滥用,他们很可能在其他平台上滥用
4、Machine Learning(机器学习)
- ML for Abuse Detection: 机器学习的方法在滥用账户的检测上被广泛应用
- Other Relevant ML Work: 机器学习的最新进展,特别是图形学习,转移学习和在线学习,也可以应用于基于ML的滥用帐户检测。
- 图学习: 旨在学习嵌入节点或使用图中的关系进行预测
- transfer learning(转移学习): 在DEC中,我们通过训练在第二组标签上进行的第一阶段嵌入来利用转移学习来提高模型性能。
- Active learning(主动学习): 主动学习与在线学习类似,是一种利用新数据重新训练模型的技术,在主动学习中,仅将模型中具有低置信度的数据点分配给人类标记人员进行审核。
六、 DEC System Overview
1、系统概述
- DEC从活跃的Facebook账户中提取特征,然后对他进行分类,然后对被分类出来的滥用账户采取行动。下图显示了DEC架构。在最高层次上,作者将DEC分解为在线和离线组件。
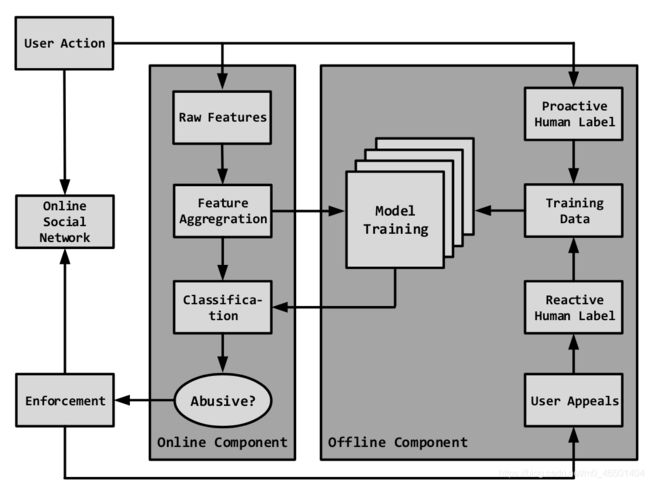
2、Online Component(在线组件)
- DEC由Facebook用户操作触发。当一个动作发生时,DEC可以根据启发式安排一个与用户活动同时进行的任务,开始为目标节点和采样的邻接节点提取原始特征(Raw Features)。
- 对于Facebook上的一个普通账户,DEC需要为其数百个邻居节点中的每一个节点抽取数百个特征,从而产生上万个原始特征被抽取。这样的查询在计算上非常昂贵,而且整个过程是异步离线完成的,不会影响用户的正常站点活动。
- 在特征提取之后,DEC聚合原始特征以形成数值稀疏特征。然后,DEC根据聚集的特征和生产中的模型为客户生成分类结果。如果账户被归类为滥用账户,DEC将对该账户实施强制执行。
3、 Offline Component(离线组件)
- DEC的离线部分包括模型训练和反馈处理
- 为了对多种类型的滥用进行分类,DEC维护了多个模型,每个模型处理不同类型的滥用。
- 每一个专用模型都训练在从并行特征提取(在线组件)收集的原始特征中学习的低维嵌入
- DEC定期接受Face book的再培训,以利用最新的虐待模式和信号
- DEC总结:
- DEC在FaceBook上提取所有活跃账户的“深层特征”,以便分类。
- 使用分类来预测所有活动帐户的滥用程度,为所有积极参与网络的用户保持最新的分类结果。
- 结合用户和标签反馈迭代分类器模型
七、Methods: Deep Feature Extraction(方法:深度特征提取)
- 特征提取是DEC的核心部分,与传统的误用检测系统相比,DEC采用聚集特征计算的过程,目的是提取目标账户的深层特征
1、Deep Feature(深层特征)

- 上图是关于实体类型及其示例直接特征和DEC中的示例深层实体的表格。
- 通过用户的深层特征来进行分类的话,攻击者很难进行避免。

- 上图是DEC中单个“目标”帐户的2级社交图的可视化。居中的橙色节点是要分类的目标节点。蓝色节点是第一个扇出级别中的相邻节点。红色节点来自第二扇出层。两个节点之间的边缘代表了共同朋友的关系。对于此图中可视化的每个节点,提取并汇总了数百个特征以进行分类。
2、Implementation(实现)
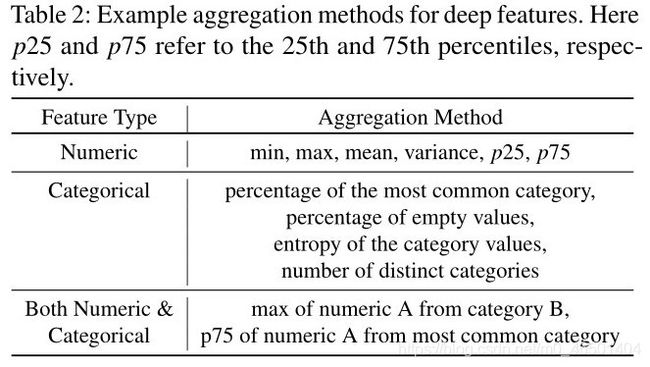
- 上图是深度功能的示例聚合方法举例。
- 活跃时间较长的帐户已经过许多以前的检查,并且通常不太可能被滥用,而新注册的帐户更有可能被滥用。
- 在生产中实时触发(重新)分类时,特征提取和聚合是异步计算的,而不会影响帐户在Facebook上的使用体验
3、Feature selection(特征选择)
- 作者仅使用目标帐户的深层功能,而没有使用直接功能。
4、Feature modification(特征修正)
- 随着对手的适应以及作者团队对他们行为的新见解,作者希望为DEC添加新功能和/或淘汰性能不佳的功能以节省计算成本。
- 作者在要添加一些新的特征或者删除某些旧的特征时,会先放入实验组进行实验,然后才会应用到实际的工程中。
- 当添加新的特征时会影响整个关系图的形成,从而会增加很大的计算开销。
- 为了限制重新计算开销的影响,作者定义了特征的隔离域。(isolated universes of features.)
- 新旧版本的要素将在并行区域中运行,现有模型将使用旧的要素区域运行,直到完成新区域的要素生成为止。然后丢弃旧的模型区域使用新的区域。
八、Methods: Multi-Stage Multi-Task Learning(方法:多阶段多任务学习)

- 上图是MS-MTL模型训练流程。第1阶段使用具有低精度标签的原始深度特征来训练多任务深度神经网络。通过从深度神经网络的最后一个隐藏层中提取嵌入内容,作者使用人类标记数据训练了阶段2中每个任务的专用GBDT模型
- 多任务学习(MTL)是一种用于改善模型泛化的转移学习。 MTL使用单个神经网络模型并行地训练多个相关的“任务”。
- 任务与标签的分类:
- 任务: 任务是指对OSN上特定类别的滥用帐户(例如,伪造帐户,垃圾邮件帐户)进行分类。
- 训练样本的标签是一个布尔值,指示样本是否属于滥用帐户类别。每个训练示例都有多个标签,每个任务一个。此多标签由布尔值向量表示。
- 向量标记举例:[1,0,0,1] --> 此向量可以代表该帐户被识别为伪造并正在进行诈骗,但未被识别为受感染或传播垃圾邮件。
1、 Motivation(动机)
- 作者团队采用了一个多阶段框架来检测Facebook上的滥用帐户。作者的框架解决了滥用帐户分类中的三个主要挑战:1.同时支持各种滥用类型;2.利用高维特征空间;3.克服了高质量的人为标签的数量不足(相对于数十亿个帐户)。
- 由于存在多种滥用帐户的方式,因此我们使用不同的任务来代表滥用的不同子类型,并使用多任务学习来增加模型中编码的信息量。
- 多级框架通过将高维原始特征向量简化为低维表示来解决“维数诅咒”,通过使用来自多任务深度神经网络的最后一个隐藏层的嵌入作为第二阶段训练的输入功能来实现这种减少
- 作者以机器生成的标签的形式拥有大量的低置信度标签数据。
2、Training Data Collection(训练数据收集)
- 标签来源:1. 人工标记。2. 由旨在检测滥用帐户以及用户报告的滥用帐户的自动化(非DEC)算法组成
3、Model Training Flow(模型训练流程)
- 模型的训练分为两个阶段:
- 第一阶段接受了大量低精度数据的训练,以学习原始特征的嵌入。
- 我们应用转移学习技术,并使用嵌入和高精度标签来训练第二阶段模型。分类结果作为第二阶段的输出生成。
- **阶段一:**低精度训练。第一个训练阶段的目标是将聚集的原始深度特征的高维向量减少为低维嵌入向量。对于每个任务,模型使用sigmoid激活函数输出概率。使用Box-Cox转换对输入进行归一化。
- 阶段二: 高精度培训。我们利用转移学习[41]的技术,并从第一阶段模型中提取最后一个隐藏层的输出作为第二阶段的输入。作者使用高精度的人工标记数据训练第二阶段(GBDT模型),以对滥用帐户进行分类,而不考虑违规的子类型。
九、Evaluation(评价)
- 在本节中,作者评估了MS-MTL方法和整个DEC系统的性能。
- 作者具体分析了三个滥用账户的模型:
- 仅行为模型,代表OSN使用的传统检测技术。
- DEC作为单个多任务神经网络(Single Stage“单阶段” ,SS)
- DEC with MS-MTL
1、Datasets(数据集)

- 上图总结了用于DEC的实验和评估的数据集。
- 作者在MS-MTL实施中考虑了四种类型的滥用帐户(任务):伪造,泄露,垃圾邮件和欺诈。
- 伪造帐户很大程度上是由脚本创建驱动的,而被盗用帐户通常是由恶意软件或网络钓鱼造成的。
- 低精度标签的数据来自于三个方面:
- 用户举报
- 网站其他系统的检测规则(如:用户发送好友请求的速度过快、被垃圾邮件检测系统删除了多个内容的用户、用户将链接分发到已知的网络钓鱼域)
- 通过已发现的攻击来进行标签
- 作者的系统第一阶段用上述方法所做的标签,而第二阶段则用更为精确地人类标签。
- 评估数据: 作者通过从Facebook上抽取活跃用户来创建帐户的评估数据集,这些用户中包含一些很难被分辨出来的用户,然后通过作者系统分类和人类分辨进行对比评估。
2、 Model Evaluation(模型评估)
-
作者使用三种不同的模型去评估作者的DEC方法的性能。

-
行为: 此GBDT模型根据每个帐户的直接行为特征(例如,朋友数)对帐户进行分类,并输出帐户是否为独占帐户(不管具体的滥用类型如何)
-
DEC- SS: 该模型使用本文中概述的DEC方法来提取深层特征,但没有利用MTL学习方法。通过组合多个任务的所有近似数据,训练一个单一的深层神经网络模型。如果我们把任何一个被用户标识为违反的任务,我们就认为这是一个违规的任务。由于DEC提取的特征数量巨大,用于训练的人类标记数据量太少。
-
DEC-MS-MTL:
3、性能比较
- ROC Curves(ROC曲线): 在ROC曲线的表现上两个DEC模型的表现比仅行为检测的方法效果更好。两个DEC方法的表现相似。

- Precision and Recall(准确率和召回率): 总的来说DEC方法比仅仅是行为检测的方法在准确率和召回率上表现的更好。

- 定量评估:曲线下的面积(AUC)和精度/召回率: DEC的单级和MS-MTL都具有相似的AUC性能,添加MS-MTL可使模型召回率增加一倍以上
4、Results In Production Environment(生产环境中的结果)
- 作者将该系统部署到了facebook的生产环境中,然后通过查看精度和召回率随时间的稳定性来评估生产中的系统。

- 从上图可以看出系统的精度是稳定的,精度不低于0.97且经常高于0.98。

- 上图中绿线是在Facebook上观察到的滥用帐户数量(以百分比计),红线是DEC删除的帐户数量。蓝线是其他两个相加的总和(也就是未使用EDC的时候,Facebook上的滥用账户的总数量)。因此,灰色阴影区域表示DEC对Facebook上的滥用账户检测的影响。

- 表6显示了DEC在所有帐户中的效果。 DEC在此总体上表现良好,AUC为0.981,以0.95的精度召回0.981,以0.99的精度召回0.955。
十、Discussion and Lessons Learned(讨论与经验教训)
1、Reducing Computational & Human Load(减少计算量和人力)
2、Segmentation and Fairness(细分与公平)
十一、 Conclusion(总结)
- 作者介绍了深度实体分类(DEC),这是一种机器学习框架,旨在检测OSN中的滥用帐户。作者的框架解决了现有滥用检测系统中的两个问题:首先,其“深度特征”提取方法创建的特征对于分类非常有力,并且(到目前为止)没有显示出针对帐户或行为特征的对抗性适应的迹象。其次,它使用新颖的机器学习训练框架来利用高数量,低精度和低数量,高精度的训练数据来改善模型性能。
一些重要内容
- Facebook使用了一个由专家组成的团队,他们可以对一个账户是否滥用进行标识。这些专家会主动(基于功能)和反应性(基于用户反馈)为帐户添加标签。