上次分享会已经介绍了Portal微服化的落地实践,前段时间主要是进行的去Oracle以及部分前端SPA化,本次分享主要介绍Portal在数据库从Oracle迁移到MySQL的实践经验。
应用场景
自助配置相关表迁移(考虑到自助配置数据表与其他模块数据相关性不大且不存在数据关联数据操作的情况,适合Oracle一次性整体迁移到MySQL)
需求
指定表数据迁移
支持Oracle&MySQL差异数据类型的转化
支持字段的增删
支持字段的大小写转换
尽量不停机迁移,能保证数据持续一致性(类数据同步)
数据流方向:Oracle -> MySQL
基本流程
考量指标
迁移前后的数据一致性
停机时间
对现有代码的侵入性
其他功能:表结构调整、字段调整
迁移方案
停机数据迁移
在线数据迁移
停机数据迁移
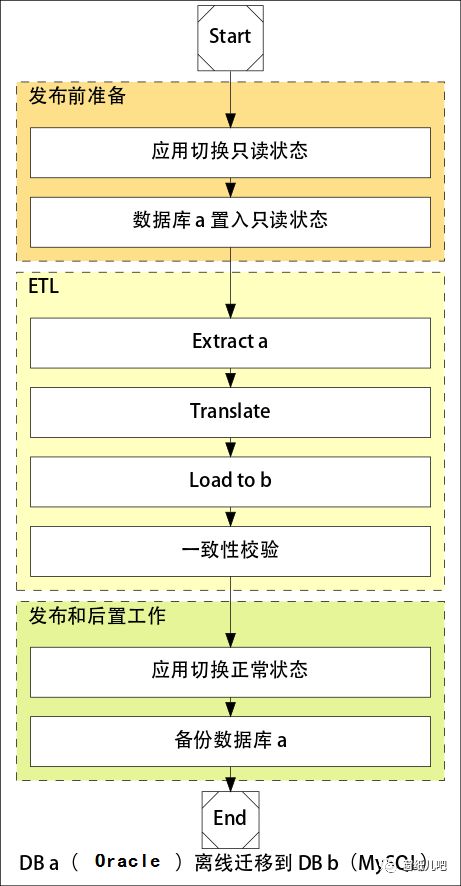
停机迁移逻辑比较简单,使用ETL(Extract Translate Load)工具从 Source 写入 Target,然后进行一致性校验,最后确认应用运行OK,将 Source 表名改掉进行备份。
在线数据迁移

在线迁移的方案稍微复杂一些,流程上有准备全量数据,然后实时同步增量数据, 在数据同步跟上(延迟秒级别)之后,进行短暂停机(确保没有流量), 就可以使用新的应用配置,并使用新的数据库。
工具选型 - ETL工具&一致性校验工具&回滚工具
ETL的全称是 Extract Translate Load(读取、转换、载入),数据库迁移最核心过程就是ETL过程。 如果将ETL过程简化,去掉Translate过程,就退化为一个简单的数据导入导出工具。
MySQL同构数据库数据迁移工具
mysqldump 和 mysqlimport MySQL官方提供的SQL导出导出工具
pt-table-sync Percona提供的主从同步工具
XtraBackup Percona提供的备份工具
异构数据库迁移工具
Database migration and synchronization tools :国外一家提供数据库迁移解决方案的公司
DataX :阿里巴巴开发的数据库同步工具
yugong :阿里巴巴开发的数据库迁移工具
otter :阿里巴巴开发的分布式数据库同步系统,MySQL同步到MySQL/Oracle
MySQL Workbench :MySQL 提供的 GUI 管理工具,包含数据库迁移功能
Data Integration - Kettle :国外的一款 GUI ETL 工具
Ispirer :提供应用程序、数据库异构迁移方案的公司
DB2DB 数据库转换工具 :一个国产的商业数据库迁移软件
Navicat Premium :经典的数据库管理工具,带数据迁移功能,对一些数据类型处理不好
DBImport :个人维护的迁移工具,非常简陋,需要付费
ETL工具特性对比
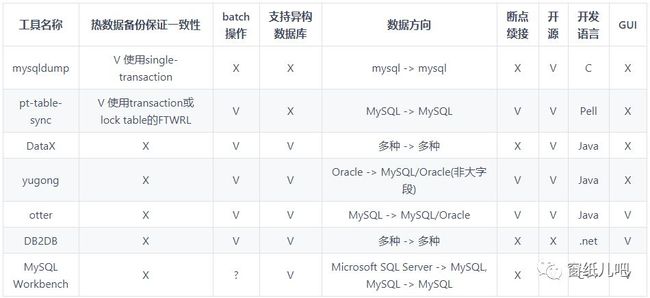
由于本次迁移是异构数据迁移,能进入本次选型的只用:DataX / yugong / otter / DB2DB / MySQL Workbench。
DB2DB 提供小数据量、简单模式的停机模式支持, 足以应付小数据量的停机迁移
DataX 为大数据量的停机模式提供服务, 使用 JSON 进行配置,通过修改查询 SQL,可以完成一部分结构调整工程
yugong 强大可定制性,支持全量&增量迁移
一致性校验工具
在 ETL 之后,需要有一个流程来确认数据迁移前后是否一致。 虽然理论上不会有差异,但是如果中间有程序异常, 或者数据库在迁移过程中发生操作,数据就会不一致。
Percona 提供了 pt-table-checksum 这样的工具, 这个工具设计从 master 使用 checksum 来和 slave 进行数据对比。 这个设计场景是为 MySQL 主从同步设计, 显然无法完成从 SQL Server 到 MySQL 的一致性校验。
yugong 支持 CHECK / FULL / INC / AUTO 四种模式,这也是作为 ETL 工具的一大原因。其中 CHECK 模式就是将 yugong 作为数据一致性检查工具使用。 yugong 工作原理是通过 JDBC 根据主键范围变化,将数据取出进行批量对比。==这个模式有个小问题,如果数据库表没有主键,将无法进行顺序对比==。
回滚
在系统迁移完成后,一段时间后遇到了一些 Critical 级别的问题,必须回滚到迁移之前状态。
使用 Canal 对 MySQL binlog 进行解析, 然后将解析之后的数据作为数据源, 将其中的变更重放到Oracle。
初识yugong
简介
定位:数据迁移 (目前主要支持oracle / mysql / DRDS)
迁移过程:1、全量迁移;2、增量迁移
-

架构
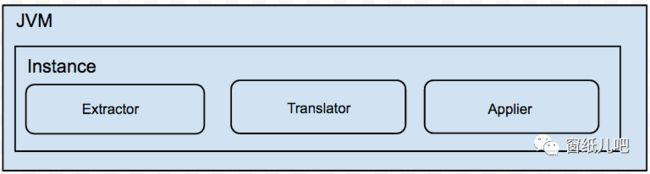
1、一个Jvm Container对应多个instance,每个instance对应于一张表的迁移任务
2、instance分为三部分: a. extractor (从源数据库上提取数据,可分为全量/增量实现) b. translator (将源库上的数据按照目标库的需求进行自定义转化) c. applier (将数据更新到目标库,可分为全量/增量/对比的实现)
设计方案
全量方案
常用方案:
1、数据文件导入/导出,比如EXPDP/IMPDP, mysqldump/source, xtrabackup等;2、ETL数据导入/导出,主要原理为使用JDBC数据查询接口
考虑到数据迁移的==灵活性==和==自定义能力==最终选择基于JDBC接口遍历数据。
基于JDBC 优点:
1、灵活数据同步2、支持异构数据3、实现相对简单
缺点:
1、全量拉取需要配合增量使用,会有部分数据重复同步2、性能和影响,一次性全量拉取,如果持续时间过长,如果此时数据库变更过多,会导致segment过大
增量方案
常用方案:
1、基于时间戳定时dump2、oracle日志文件,比如LogMiner,OGG3、oracle CDC(Change Data Capture)4、oracle trigger机制,比如DataBus , SymmetricDS5、oracle 物化视图(materialized view)6、...
考虑去IOE数据迁移的灵活性,支持多种oracle版本,同时为降低DBA的运维成本,yugong选择了oracle物化视图作为增量方案。
物化视图方案 优点:
1、原理简单,方便理解和学习,可理解为一种固化的简易trigger模式2、运维简单,DBA一次账户授权后,程序可按需create一张物化视图表即可完成增量订阅3、相对透明,不需要像时间戳sql扫描依赖数据库表设计,也不需要关注oracle版本和服务器存储等
缺点:
1、性能和影响,类似于trigger机制会对源库的数据写入造成一定的性能影响.
yugong小试
数据库
源库(oracle)
GRANT SELECT,INSERT,UPDATE,DELETE ON XXX TO XXX; #常见CRUD权限GRANT CREATE ANY MATERIALIZED VIEW TO XXX;GRANT DROP ANY MATERIALIZED VIEW TO XXX;
目标库(mysql/oracle)
GRANT SELECT,INSERT,UPDATE,DELETE ON XXX TO XXX;
目录结构
drwxr-xr-x 2 root root 4096 7月 23 13:18 bindrwxr-xr-x 6 root root 4096 7月 23 12:59 conf--rwxrwxrwx 1 root root 4700 4月 1 2016 logback.xmldrwxrwxrwx 2 root root 4096 7月 21 09:43 positioner ##同步的位置信息drwxr-xr-x 2 root root 4096 7月 21 09:30 translator--rw-r--r-- 1 root root 4266 7月 4 11:14 PortalResourceDataTranslator.java-rw-r--r-- 1 root root 3174 7月 4 10:40 PortalRoleDataTranslator.java-rw-r--r-- 1 root root 2633 7月 4 10:57 PortalRoleToResourceDataTranslator.java-rw-r--r-- 1 root root 2617 7月 4 10:54 PortalUserToRoleDataTranslator.javadrwxr-xr-x 2 root root 4096 7月 23 12:56 libdrwxr-xr-x 7 root root 4096 7月 23 12:56 logs
修改配置
yugong.database.source.username=portalyugong.database.source.password=******yugong.database.source.type=ORACLEyugong.database.source.url=jdbc:oracle:thin:@192.168.1.1:1521:PORTALyugong.database.source.encode=UTF-8yugong.database.source.poolSize=30yugong.database.target.url=jdbc:mysql://192.168.1.1:3306/portalyugong.database.target.username=portalyugong.database.target.password=****yugong.database.target.type=MYSQLyugong.database.target.encode=UTF-8yugong.database.target.poolSize=30yugong.table.batchApply=trueyugong.table.onceCrawNum=1000yugong.table.tpsLimit=0# use connection default schemayugong.table.ignoreSchema=false# skip Applier Load Db failed datayugong.table.skipApplierException=false#yugong.table.white=yugong_example_join,yugong_example_oracle,yugong_example_twoyugong.table.white=PORTAL_ROLE,PORTAL_RESOURCE,PORTAL_USER_TO_ROLE,PORTAL_ROLE_TO_RESOURCEyugong.table.black=# tables use multi-thread enable or disableyugong.table.concurrent.enable=true# tables use multi-thread sizeyugong.table.concurrent.size=23# retry timesyugong.table.retry.times = 3# retry interval or sleep time (ms)yugong.table.retry.interval = 1000# MARK/FULL/INC/ALL(REC+FULL+INC)/CHECK/CLEARyugong.table.mode=ALL# yugong extractoryugong.extractor.dump=falseyugong.extractor.concurrent.enable=trueyugong.extractor.concurrent.global=falseyugong.extractor.concurrent.size=30yugong.extractor.noupdate.sleep=1000yugong.extractor.noupdate.thresold=0yugong.extractor.once=false# {0} is all columns , {1}.{2} is schemaName.tableName , {3} is primaryKey#yugong.extractor.sql=select /*+parallel(t)*/ {0} from {1}.{2} t#yugong.extractor.sql=select * from (select {0} from {1}.{2} t where {3} > ? order by {3} asc) where rownum <= ?# yugong applieryugong.applier.concurrent.enable=trueyugong.applier.concurrent.global=falseyugong.applier.concurrent.size=30yugong.applier.dump=false# statsyugong.stat.print.interval=5yugong.progress.print.interval=1# alarm emailyugong.alarm.email.host = smtp.163.comyugong.alarm.email.username = [email protected]yugong.alarm.email.password =yugong.alarm.email.stmp.port = 465[email protected]
启动停止
别懒,自己探索吧。
查看日志
目录
logs/- yugong/ #系统根日志- table.log- ${table}/ #每张同步表的日志信息- table.log- extractor.log- applier.log- check.log
全量完成的日志:(在yugong/table.log 和 ${table}/table.log中记录)
table[PORTAL.PORTAL_RESOURCE] is end!
增量日志:(在${table}/table.log中记录)
table[PORTAL.PORTAL_RESOURCE] now is CATCH_UP ... #代表已经追上,最后一次增量数据小于onceCrawNum数量table[PORTAL.PORTAL_RESOURCE] now is NO_UPDATE ... #代表最近一次无增量数据
ALL(全量+增量)模式日志: (在${table}/table.log中记录)
table [PORTAL.PORTAL_RESOURCE] full extractor is end , next auto start inc extractor #出现这条代表全量已经完成,进入增量模式
CHECK日志: (在${table}/check.log中diff记录)
------------------ Schema: yugong , Table: test_all_one_pk--------------------PksColumnValue[column=ColumnMeta[index=0,name=ID,type=3],value=2576]---diffColumnMeta[index=3,name=AMOUNT,type=3] , values : [0] vs [0.0]
统计信息:
progress统计,会在主日志下,输出当前全量/增量/异常表的数据
{未启动:0,全量中:2,增量中:3,已追上:3,异常数:0}
stat统计,会在每个表迁移日志下,输出当前迁移的tps信息
{总记录数:180000,采样记录数:5000,同步TPS:4681,最长时间:215,最小时间:212,平均时间:213}
切换流程
当任务处于追上状态时候,表示已经处于实时同步状态
后续通过源数据库进行停写,稍等1-2分钟后(保证延时的数据最终得到同步,此时源库和目标库当前数据是完全一致的)
检查增量持续处于NO_UPDATE状态,可关闭该迁移任务,即可升级新程序,使用新MySQL库,完成切换的流程。
自定义数据转换
如果要迁移的oracle和mysql的表结构不同,比如表名,字段名有差异,字段类型不兼容,需要使用自定义数据转换。数据流:DB -> Extractor -> DataTranslator -> Applier -> DB,可实现==DataTranslator接口==来处理数据逻辑。
举例
public class PortalResourceDataTranslator extends AbstractDataTranslator implements DataTranslator {public boolean translator(Record record) {// 1. schema/table名不同record.setSchemaName("portal");record.setTableName("author_resource");// 2. 字段名字不同ColumnValue c1 = record.getColumnByName("ID");if (c1 != null) {c1.getColumn().setName("id");}ColumnValue c2 = record.getColumnByName("ACCESS_MODULE");if (c2 != null) {c2.getColumn().setName("access_module");}ColumnValue c3 = record.getColumnByName("ACCESS_PATH");if (c3 != null) {c3.getColumn().setName("access_path");}// 3. 字段逻辑处理ColumnValue aliasNameColumn = record.getColumnByName("alias_name");StringBuilder displayNameValue = new StringBuilder(64);displayNameValue.append(ObjectUtils.toString(nameColumn.getValue())).append('(').append(ObjectUtils.toString(aliasNameColumn.getValue())).append(')');nameColumn.setValue(displayNameValue.toString());// 4. 字段类型不同ColumnValue amountColumn = record.getColumnByName("amount");amountColumn.getColumn().setType(Types.VARCHAR);amountColumn.setValue(ObjectUtils.toString(amountColumn.getValue()));// 5. 源库多一个字段record.getColumns().remove(aliasNameColumn);// 6. 目标库多了一个字段ColumnMeta gmtMoveMeta = new ColumnMeta("gmt_move", Types.TIMESTAMP);ColumnValue gmtMoveColumn = new ColumnValue(gmtMoveMeta, new Date());record.addColumn(gmtMoveColumn);return super.translator(record);}}/**疑问:1、DataTranslator动态编译2、DataTranslator查找规则:根据表名自动查找3、其他复杂转换:a、多张Oracle表和一张MySQL转换处理b、一张Oracle表和多张MySQL**/
运行模式细谈
MARK模式(MARK) :创建物化视图
CLEAR模式(CLEAR) : 删除物化视图
全量模式(FULL)
增量模式(INC):依赖记录日志功能
自动模式(ALL):全量+增量模式的一种组合(步骤:1.开日志,2.全量同步,3.增量同步)
对比模式(CHECK)
Portal自助配置在线迁移
准备工作
程序中相关sql已适配MySQL
新发布包关闭多数据源,并将连接改到MySQL(之前微服务应用papi2是多数据源连接,确保适配的sql只应用在MySQL库上)
迁移流程
创建MySQL表(字段类型作相应调整)
Oracle数据库备份
开启yugong数据迁移,并保持数据同步
微服务papi2逐个升级
验证数据整体是否一致
检查页面运行是否正常,并做全量接口的增删改测试
关闭yugong实时同步
完成迁移
迁移疑问
多个微服务连续升级期间如何保证数据完整性?
Oracle和MySQL同时写数据会不会主键重复?
采坑记录
配置jdbc url
转换器的编写
Oracle无主键表
不支持大字段
本文作者:haozi
原文链接:http://blog.chuangzhi8.cn/2018/08/19/异构数据库迁移与同步-一-之yugong/
版权归作者所有,转载请注明出处
捅一下