tags: springbatch
1.引言
最近使用Spring Batch进行做数据迁移、数据同步、数据批处理等工作,感叹Spring Batch设计之简洁,对批处理编程的抽象能力之强大。
众所周知,随着大数据技术发展,企业对数据越来越重视,如何把数据有效转化为信息,以帮助企业提供数据分析、商业决策、提高核心竞争力。而批处理则是实现这一目标的其中一个重要手段。通过批处理,可以完成数据加载、抽取、转换、验证、清洗等功能。这些工作具有数据量大、无需人工操作、与时间密切相关(如隔一段时间处理一次)等特点。
对于批处理数据,无论是数据抽取、数据库迁移、数据同步等业务,涉及的具体操作,不外乎数据读取,数据处理,数据写入三种。按这个思路,在批处理编程过程中,如何做到结构清晰、接口通用,过程可见,出错处理,是需要花费一定的功夫的,而Spring Batch框架的出现,则填补这一空缺。当初看到这个框架后,真的有相见恨晚的感觉,这不就是我想要的吗。读、处理、写分别抽象出来,通过Spring Batch,可以把复杂的业务问题做成简单化的抽象,编程过程中,只需要关心具体的业务实现即可,把流程以及流程的控制交给Spring Batch吧。
在学习过程中,我阅读了Spring Batch的官方文档及刘相的《Spring Batch批处理框架》,本系列将对Spring Batch进行介绍以及结合案例进行实践,希望对入门的同学有帮助,也希望和大家一起交流。本篇先对Spring Batch进行介绍。
2.Spring Batch简介
2.1 Spring Batch是批处理框架
对于使用java技术进行业务编程开发的领域,Spring Framework 无疑是当前企业开发的龙头,从早期的spring开发,到Spring MVC的web开发,再到现在的基于Spring Boot进行微服务开发,都具有简化开发,增强规范,快速集成等特点,而在数据处理领域,spring同样有一个开发框架,那就是Spring Batch。Spring Batch是一个轻量级,完善的批处理框架,旨在帮助企业建立健壮高效的批处理应用程序。 它是以Spring 框架为基础开发,使得原来使用Spring框架的开发者可以更容易利用原来的服务。当前新版本的Spring Batch更是可以直接基于Spring Boot进行开发,使得开发更简单、快捷。
根据官方文档说明,Spring Batch是由Spring Source和Accenture(埃森哲)合作开发的,埃森哲贡献了几十年来在使用和构建批量架构方面的经验,埃森哲与SpringSource之间的合作旨在促进软件处理方法,框架和工具的标准化,在创建批处理应用程序时,企业或用户可以始终如一地利用这些方法,框架和工具。无论如何,这是开发者的福利,避免重复开发。
2.2 Spring Batch不是调度框架
Spring Batch本身是批处理逻辑的抽象,是对执行任务的规范化,跟调度框架是两回事。它可以结合调度框架,由调度框架进行调度Spring Batch作业,完成对批处理的任务。调度框架有相应的开源软件可供选择,如quartz,cron,xxl-job等。
2.3 Spring Batch的简单说明
前面说的,Spring Batch把批处理简单化,标准化是如何体现出来。简单来说,Spring Batch把批处理简化为Job和Job step两部分,在Job step中,把数据处理分为读数据(Reader)、处理数据(Processor)、写数据(Writer)三个步骤,异常处理机制分为跳过、重试、重启三种,作业方式分为多线程、并行、远程、分区四种。开发者在开发过程中,大部分工作是根据业务要求编写Reader、Processor和Writer即可,提高了批处理开发的效率。同时Spring Batch本身也提供了很多默认的Reader和Writer,开箱即用。
3.Spring Batch优势与使用场景
对于Spring Batch的优势和使用场景,在《Spring Batch批处理框架》书中,已经作了比较全面的说明,个人觉得写得比较好了,现摘抄下来,可以供大家参考,以判断Spring Batch是否适用于自己开发的业务。
3.1 Spring Batch优势
丰富的开箱即用组件
开箱即用组件包括各种资源的读、写。读/写:支持文本文件读/写、XML文件读/写、数据库读/写、JMS队列读/写等。还提供作业仓库,作业调度器等基础设施,大大简化开发复杂度。面向chunk处理
支持多次读、一次写、避免多次对资源的写入,大幅提升批处理效率。事务管理能力
默认采用Spring提供的声明式事务管理模型,面向Chunk的操作支持事务管理,同时支持为每个tasklet操作设置细粒度的事务配置:隔离级别、传播行为、超时设置等。元数据管理
自动记录Job和Step的执行情况、包括成功、失败、失败的异常信息、执行次数、重试次数、跳过次数、执行时间等,方便后期的维护和查看。易监控的批处理应用
提供了灵活的监控模式,包括直接查看数据库、通过Spring Batch提供的API查看、JMX控制台查看等。其中还说到Spring Batch Admin,不过这个项目已不维护,改为用Spring Cloud Data Flow了。丰富的流程定义
支持顺序任务、条件分支任务、基于这两种任务可以组织复杂的任务流程。健壮的批处理应用
支持作业的跳过、重试、重启能力、避免因错误导致批处理作业的异常中断。易扩展的批处理应用
扩展机制包括多线程执行一个Step(Multithreaded step)、多线程并行执行多个Step(Parallelizing step)、远程执行作业(Remote chunking)、分区执行(partitioning step)。复用企业现有IT资产
提供多种Adapter能力,使得企业现有的服务可以方便集成到批处理应用中。避免重新开发、达到复用企业遗留的服务资产。
3.2 Spring Batch 使用的典型场景
定期提交批处理任务
并行批处理
企业消息驱动处理
大规模并行批处理
失败后手动或定时重启
按顺序处理依赖的任务(可扩展为工作流驱动的批处理)
部分处理:跳过记录(例如,回滚时)
批处理事务
4.Spring Batch概念预览
上面已经列举了很多Spring Batch的优点和适用场景,接下来我们对它的具体架构及相应使用到的概念做个简要说明,以便实现后缀应用实践的开发。
4.1 Spring Batch架构
从Spring Batch的github开源项目中,可以看到主要是spring-batch-infrastructure和spring-batch-core模块代码,这也构成了它的主要架构。如下图:
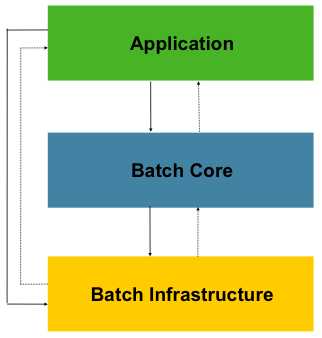
图中突出了三个主要的高级组件:应用层(Application),核心层(Batch Core)和基础架构层(Batch Infrastructure)。其中该应用层包含开发人员使用Spring Batch编写的所有自定义的批处理作业和自定义代码。 核心层包含启动和控制批处理作业所需的核心运行时类。它包括 JobLauncher,Job 和 Step 的实现。 应用层和核心层都建立 在通用基础架构之上。此基础结构包含通用的读(ItemReader)、写(ItemWriter)和服务处理(如RetryTemplate)。在开发应用时,引用spring-batch-infrastructure和spring-batch-core包,即可使用基础架构层及核心层内容,然后基于这两层进行应用业务逻辑的实现。
4.2 Spring Batch基本概念
熟悉Spring Batch,先从基本概念学起,开发过程中不可避免会使用到这些概念,因此需要先了解。下图是Spring Batch批处理的具体组件图:
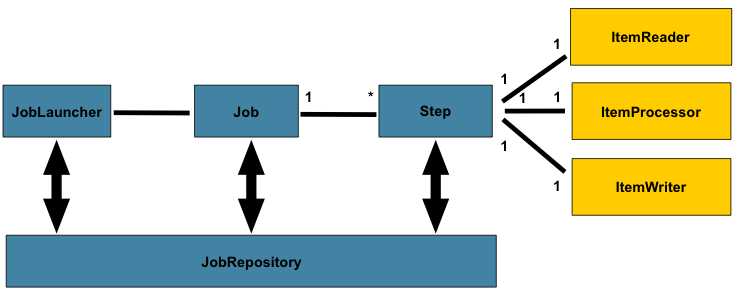
前面已经提到,Spring Batch在基础架构层,把任务抽象为Job和Step,一个Job由多个Step来完成,每个step对应一个ItemReader、ItemProcessor及ItemWriter。Job是通过JobLauncher来启动,Job及Job的运行结果和状态、Step的运行结果和状态,都会保存在JobRepository中。
概念说明可见下表:
| 领域对象 | 描述 |
|---|---|
| JobRepository | 作业仓库,保存Job、Step执行过程中的状态及结果 |
| JobLauncher | 作业执行器,是执行Job的入口 |
| Job | 一个批处理任务,由一个或多个Step组成 |
| Step | 一个任务的具体的执行逻辑单位 |
| Item | 一条数据记录 |
| ItemReader | 从数据源读数据 |
| ItemProcessor | 对数据进行处理,如数据清洗、转换、过滤、校验等 |
| ItemWriter | 写入数据到指定目标 |
| Chunk | 给定数量的Item集合,如读取到chunk数量后,才进行写操作 |
| Tasklet | Step中具体执行逻辑,可重复执行 |
5.批处理工具比较
在实际应用中,在批处理中用得较多的是场景是数据同步。在做数据集成工作中,常常需要从源位置把数据同步到目标位置,以便于进行后续的逻辑操作。在做这种批处理工具时,在网上查资料,发现用得比较多的是kettle及阿里的datax,对于这两款工具,各有各的优缺点,我也试用了一段时间(有机会的话会针对它们的使用再写一下文章),下面可以简要做个说明,做个比较。
5.1 kettle
kettle是一款可以可视化编程的开源ETL工具,把数据处理简化为Job和Transform,在Transform中,提供了各种数据读、写、转换、处理的工具。开发者仅需要以工具界面中拖拽相应的工具,进行步骤连接即可完成一个ETL工作,不同的工具及步骤结合起来可以形成相对复杂的作业流程,以完成ETL工作。它的优点就在于可视化编程,非常容易上手,对于不熟悉编程的人员来说,是一个福利。个人感觉针对简单(即逻辑判断和操作不多的)的ETL工作,是比较推荐用它。但缺点也有,一是易学难精,它提供的操作非常多,要把它们都熟悉而且做到相互结合来完成任务,是有一定难度的。二是对于一些复杂的的逻辑判断及操作,kettle虽然可以做,但操作起来就很复杂。三是不方便调试,尽管它内置有调试功能,但由于在转换中,操作都是并行的,单步调试比较难实现。四是内存消耗,本身kettle界面跑起来已经是比较耗内存的,而作业中数据量大的时候,内存消耗更大。
5.2 datax
DataX 是阿里巴巴集团内被广泛使用的离线数据同步工具/平台,实现包括 MySQL、Oracle、SqlServer、Postgre、HDFS、Hive、ADS、HBase、TableStore(OTS)、MaxCompute(ODPS)、DRDS 等各种异构数据源之间高效的数据同步功能。DataX本身作为数据同步框架,将不同数据源的同步抽象为从源头数据源读取数据的Reader插件,以及向目标端写入数据的Writer插件,理论上DataX框架可以支持任意数据源类型的数据同步工作。同时DataX插件体系作为一套生态系统, 每接入一套新数据源该新加入的数据源即可实现和现有的数据源互通。
DataX从架构上而言也是设计得很简洁的,它作为数据搬运工,支持任意数据类型的同步工作,跟Spring Batch有异曲同工之妙,DataX本身作为离线数据同步框架,采用Framework + plugin架构构建。将数据源读取和写入抽象成为Reader/Writer插件,纳入到整个同步框架中。
Reader:Reader为数据采集模块,负责采集数据源的数据,将数据发送给Framework。
Writer: Writer为数据写入模块,负责不断向Framework取数据,并将数据写入到目的端。
Framework:Framework用于连接reader和writer,作为两者的数据传输通道,并处理缓冲,流控,并发,数据转换等核心技术问题。
DataX本身也提供比较丰富的Reader和Writer,按它的文档,以它作为工具进行数据同步,还是比较简单的。而且有阿里的背书,可放心使用。不过缺点一是不常维护更新,github上最近的更新是去年(2018);二是二次开发有难度,我尝试跑源码,想做二次开发,虽然最终跑起来,但也费了不少力气。三是虽然架构清晰,但使用规则操作起来不是很灵活,基本是通过json配置文件,按规则进行配置,想自定义规则是不行的。
5.3 总体感受
相对而言,统合考虑易用性、可扩展性,灵活性,可编程性,个人感觉Spring Batch会比较适合有点编程基础(特别是使用Spring及SpringBoot框架)的开发人员,针对业务编程,可自由发挥。
6、总结
本文章对Spring Batch框架进行简要介绍,并指出它的优势及使用场景,然后对它使用的组件基本概念进行简要说明,最后跟现在比较通用的kettle和DataX进行比较,希望读者通过这篇文章,对Spring Batch有一定的了解。在接下来的文章,即进入实战类的编写,逐步构建企业级的批处理应用。
参考资源
- 1.Spring Batch官网:有Spring Batch的文档及example
- 2.Spring Batch的github源码:里面包含源码,example,发布情况等。
- 3.刘相《Spring Batch 批处理框架》:书中对Spring Batch进行了详细的描述,本文章主要参考此书。
- 4.kettle官网:kettle的官网,可以在此处下载kettle
- 5.datax官网:datax的github,里面有相应源码和文档,示例