CVPR2021中的目标检测和语义分割论文汇总
作者丨Tom Hardy@知乎 编辑丨计算机视觉工坊
来源丨https://zhuanlan.zhihu.com/p/355137468
感慨:知识蒸馏大放异彩~
目标检测篇
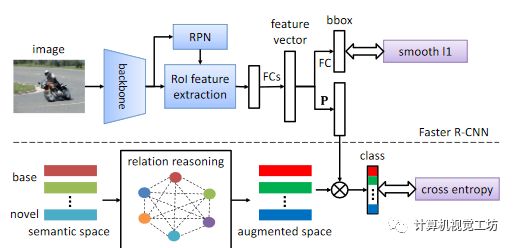
1、Semantic Relation Reasoning for Shot-Stable Few-Shot Object Detection
paper链接:https://arxiv.org/abs/2103.01903
由于真实世界数据固有的长尾分布,few-shot目标检测是一个重要而持久的问题。它的性能很大程度上受到新类数据稀缺的影响。但是无论数据的可用性如何,新类和基类之间的语义关系都是不变的。这篇paper研究了如何利用这种语义关系和视觉信息,并将显式关系推理引入到新目标检测的学习中。

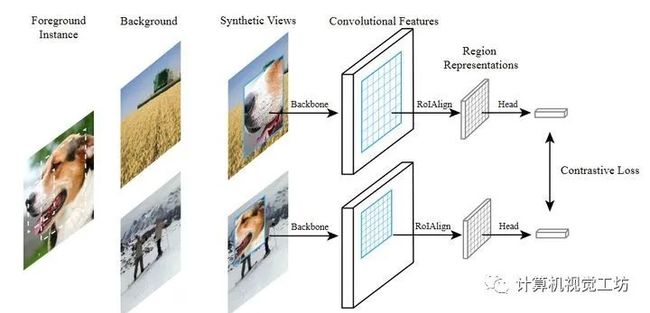
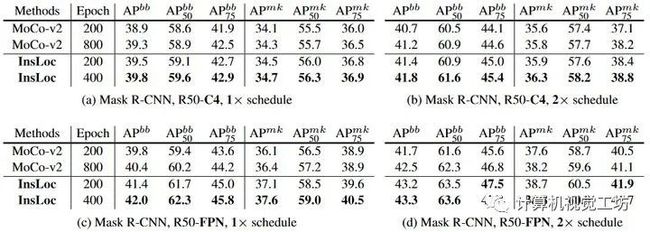
2、Instance Localization for Self-supervised Detection Pretraining(香港大学,微软亚洲研究院)
paper链接:https://arxiv.org/pdf/2102.08318.pdf
以往对自监督学习的研究在图像分类方面取得了相当大的进展,但在目标检测方面往往存在transfer性能下降的问题。本文的目的是提出一种专门用于目标检测的自监督预训练模型。
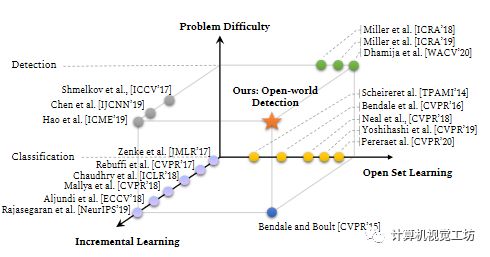
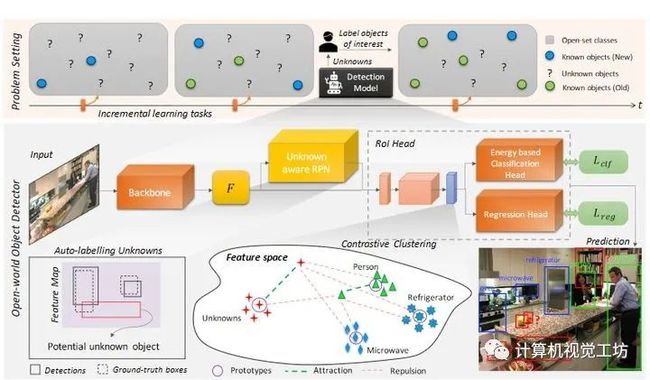
3、Towards Open World Object Detection
paper链接:https://arxiv.org/abs/2103.02603
人类有识别环境中未知物体实例的本能。人类有一种自然的本能来识别未知环境中的物体实例。这促使我们提出了一个新的计算机视觉问题,称为“开放世界目标检测”,模型的任务是:
1)在没有明确监督的情况下,将尚未引入的目标识别为“未知”,
2)逐步学习这些已识别的未知类别,而不忘记以前学习的类,当相应的标签逐渐收到时。
本文提出了一种基于对比聚类和基于能量的未知识别的开放世界目标检测算法。
4、Positive-Unlabeled Data Purification in the Wild for Object Detection
暂未放出
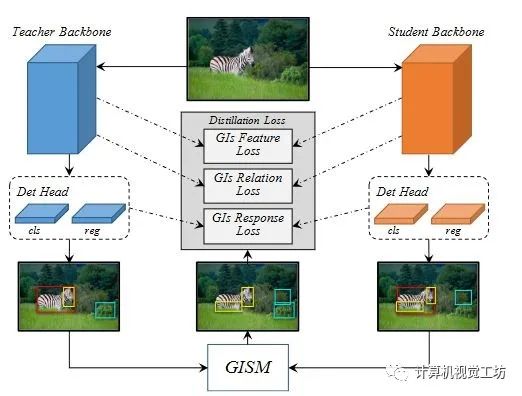
5、General Instance Distillation for Object Detection
paper链接:https://arxiv.org/pdf/2103.02340.pdf
近年来,知识蒸馏被证明是一种有效的模型压缩方法。这种方法可以使轻量级的学生模型从较大的教师模型中获取知识。然而,以往的提取检测方法对不同检测框架的泛化能力较弱,严重依赖于GT,忽略了实例间有价值的关系信息。因此,论文提出了一种新的基于区分性实例的提取方法,即一般实例提取(GID)。该方法包含了通用实例选择模块(GISM),充分利用了基于特征、基于关系和基于响应的知识进行提取。
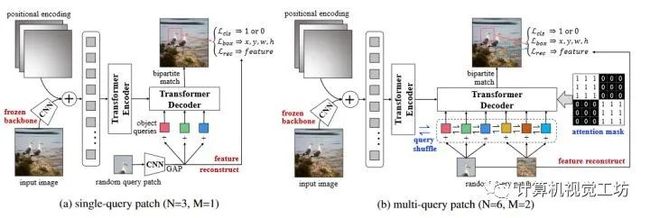
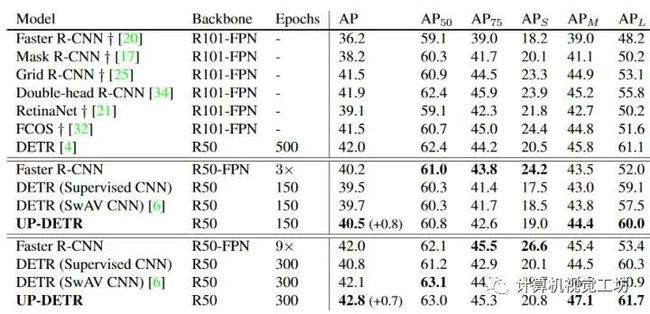
6、UP-DETR: Unsupervised Pre-training for Object Detection with Transformers
paper链接:https://arxiv.org/pdf/2011.09094.pdf
transformer+无监督的一篇paper。
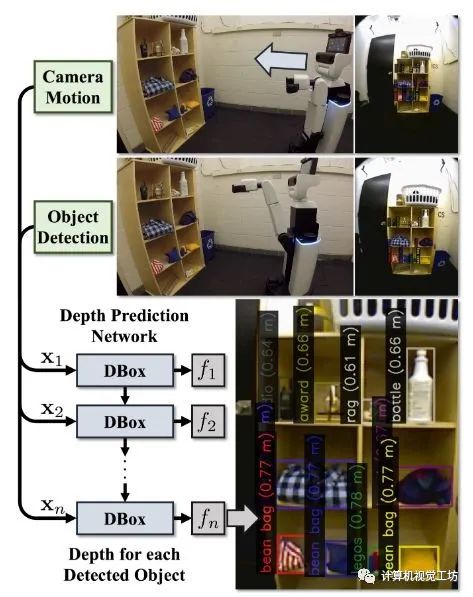
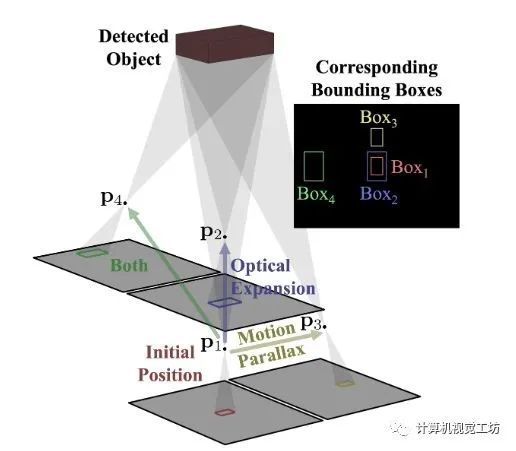
7、Depth from Camera Motion and Object Detection
paper链接:https://arxiv.org/abs/2103.01468
本文讨论了在给定摄像机运动测量值(如机器人运动学或车辆里程计)的情况下,学习估计被测物体深度的问题。论文通过1)设计一个递归神经网络(DBox),使用box和未校准摄像机运动的广义表示来估计物体的深度;2)通过运动和检测数据集(ODMD)引入物体深度。

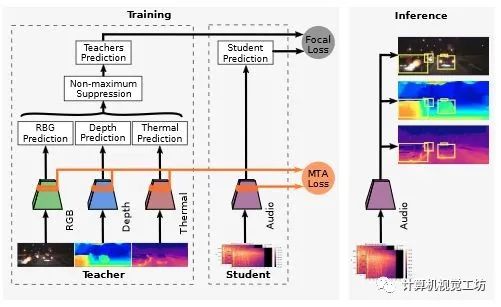
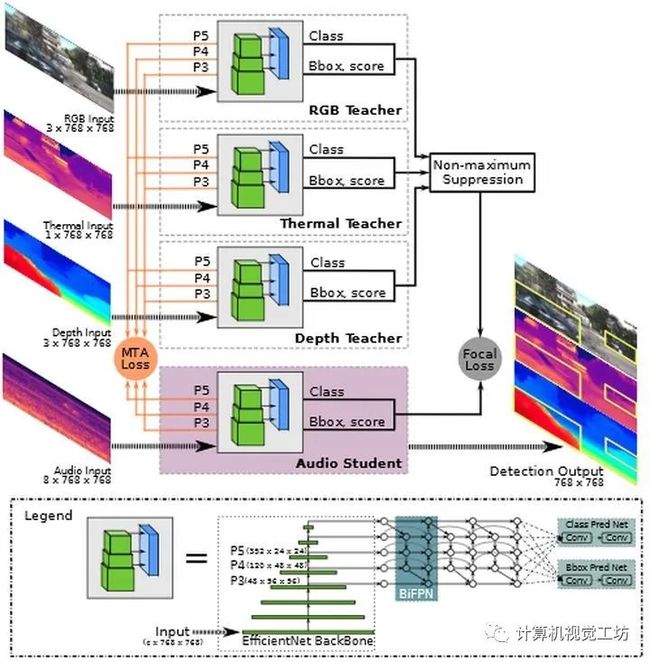
8、There is More than Meets the Eye: Self-Supervised Multi-Object Detection and Tracking with Sound by Distilling Multimodal Knowledge
paper链接:https://arxiv.org/abs/2103.01353
物体固有的声音属性可以为学习丰富的物体检测和跟踪表示提供有价值的线索。此外,可以利用视频中视听事件的同时出现,通过单独监测环境中的声音,在图像场上定位对象。到目前为止,这只适用于摄像机静止和单目标检测的场景。此外,这些方法的鲁棒性受到限制,因为它们主要依赖于对光照和天气变化非常敏感的RGB图像。在这项工作中,我们提出了一个新颖的自监督MM-stewartnet框架,该框架由多个教师组成,他们利用不同的模式,包括RGB、深度和热图像,同时利用互补线索并将知识提取到单一音频学生网络中。
9、Dogfight: Detecting Drones from Drone Videos
暂未放出
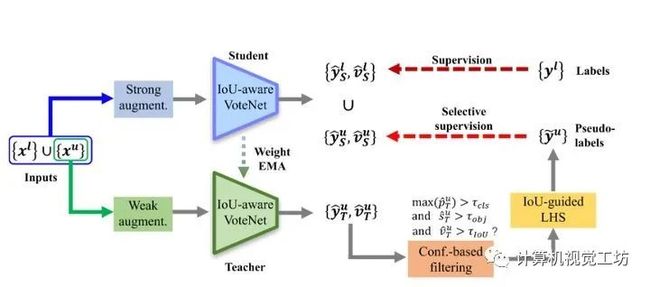
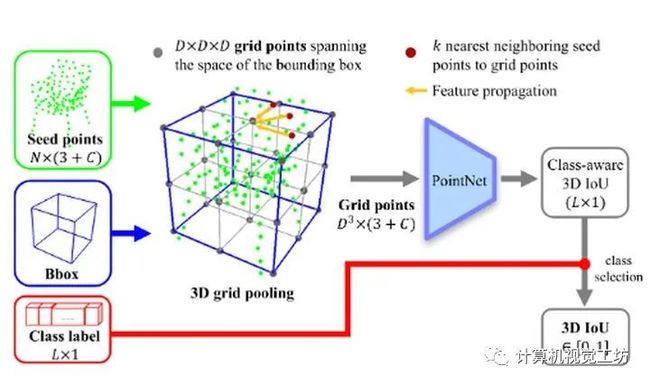
10、3DIoUMatch: Leveraging IoU Predictionfor Semi-Supervised 3D Object Detection
paper链接:https://arxiv.org/pdf/2012.04355.pdf
三维目标检测是一项重要而艰巨的任务,它严重依赖于难以获得的三维标注。为了减少所需的监督量,论文提出了一种新的半监督三维物体检测方法。采用VoteNet(一种流行的基于点云的目标检测器)作为主干,利用一个教师学生互学习网络框架,以伪标签的形式将信息从标注训练集传播到无标注训练集。
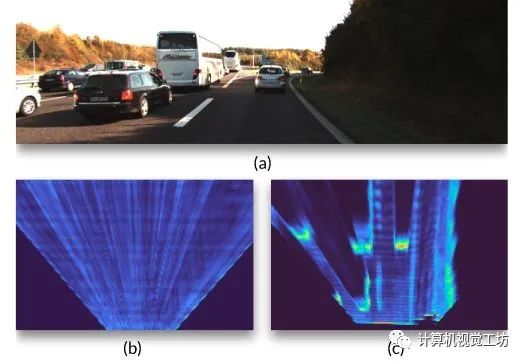
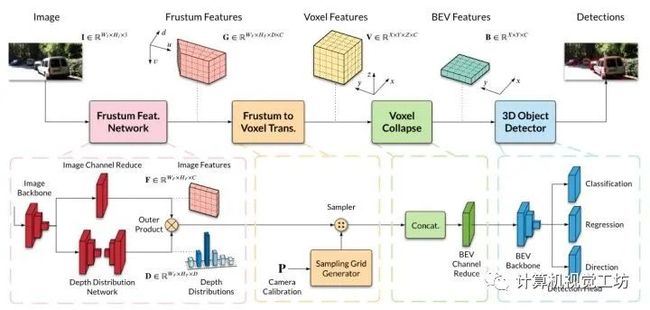
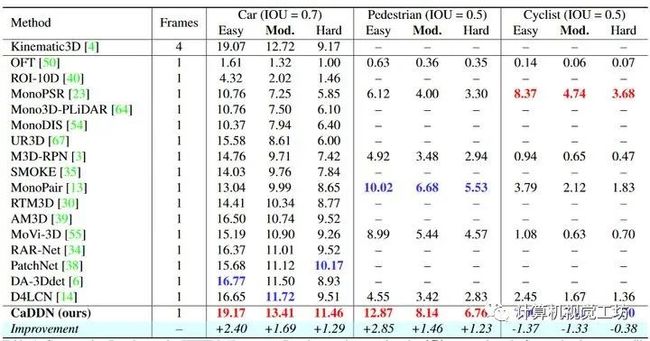
11、Categorical Depth Distribution Network for Monocular 3D Object Detection
paper链接:https://arxiv.org/abs/2103.01100
单目三维目标检测是自动驾驶领域的一个关键问题,与典型的多传感器系统相比,它提供了一种结构简单的解决方案。单目三维检测的主要挑战在于准确预测目标深度,由于缺乏直接的距离测量,必须从目标和场景线索中推断出目标深度。许多方法试图直接估计深度来辅助三维检测,但由于深度不准确,性能有限。论文提出的分类深度分布网络(Categorical Depth Distribution Network,CaDDN)利用每个像素的预测分类深度分布,将丰富的上下文特征信息投射到三维空间中适当的深度区间。然后,使用计算效率高的鸟瞰投影和单级检测器来生成最终的输出边界框。我们将CaDDN设计为一种完全可微的端到端方法,用于联合深度估计和目标检测。
语义/实例全景/分割篇
1、PointFlow: Flowing Semantics Through Points for Aerial Image Segmentation
暂未开放
2、Few-Shot Segmentation Without Meta-Learning: A Good Transductive Inference Is All You Need?
paper链接:https://arxiv.org/abs/2012.06166


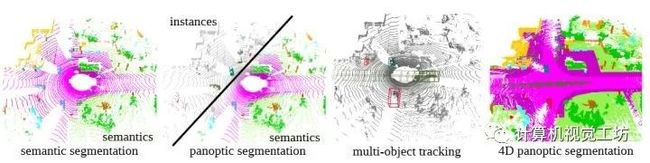
3、4D Panoptic LiDAR Segmentation
paper链接:arxiv.org/abs/2102.1247
时态语义场景理解是自动驾驶车辆或机器人在动态环境中工作的关键。本文提出了4D全景激光雷达分割来分配一个语义类和一个时间上一致的实例ID到一个3D点序列。
4、Towards Semantic Segmentation of Urban-Scale 3D Point Clouds: A Dataset, Benchmarks and Challenges
paper链接:https://arxiv.org/abs/2102.12472
5、PLOP: Learning without Forgetting for Continual Semantic Segmentation
paper链接:https://arxiv.org/abs/2011.11390
目前,深度学习方法广泛应用于处理语义分割等需要大量数据集和强大计算能力的计算机视觉任务。语义连续学习(CSS)是一个新兴的趋势,它通过不断地添加新的语义来更新旧的模型语义。本文提出了一种多尺度池蒸馏方案localpod,该方案在特征级保持长、短距离的空间关系。此外,还设计了一个基于熵的伪标号来处理由旧模型预测的背景类,以避免旧类的灾难性遗忘。我们的方法称为PLOP,在现有CSS场景中,以及在新提出的具有挑战性的基准中,大大超过了最先进的方法。

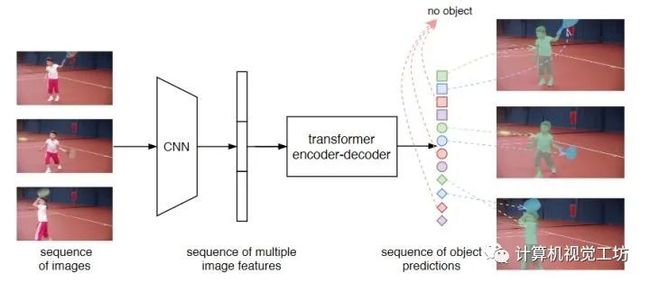
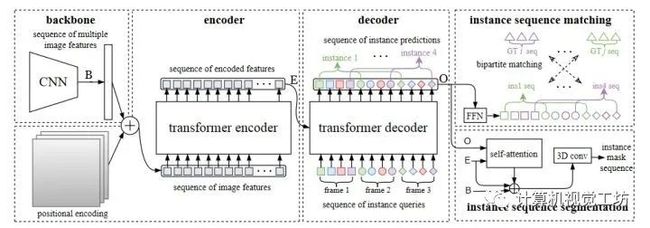
6、End-to-End Video Instance Segmentation with Transformers
paper链接:https://arxiv.org/abs/2011.14503
使用Transformers进行视频实例分割~
本文仅做学术分享,如有侵权,请联系删文。
猜您喜欢:
超100篇!CVPR 2020最全GAN论文梳理汇总!
拆解组新的GAN:解耦表征MixNMatch
StarGAN第2版:多域多样性图像生成
附下载 | 《可解释的机器学习》中文版
附下载 |《TensorFlow 2.0 深度学习算法实战》
附下载 |《计算机视觉中的数学方法》分享
《基于深度学习的表面缺陷检测方法综述》
《零样本图像分类综述: 十年进展》
《基于深度神经网络的少样本学习综述》
