第三周python练习
PS:如果某道题我没有做笔记,这并不是我偷懒,而是我做这道题思路很清晰,我觉得easy.
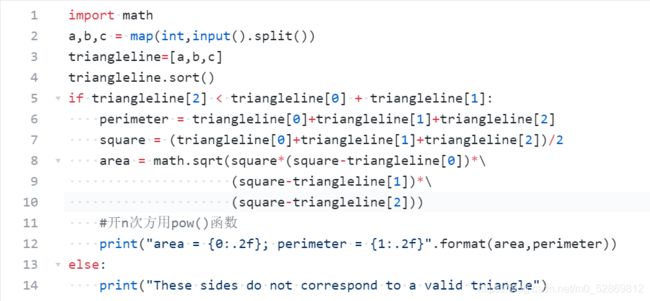
第2章-12 输出三角形面积和周长
本题要求编写程序,根据输入的三角形的三条边a、b、c,计算并输出面积和周长。
注意:在一个三角形中, 任意两边之和大于第三边
三角形面积计算公式:
area=s(s−a)(s−b)(s−c)【整体开根号】
其中s=(a+b+c)/2
我的代码:
别人的代码: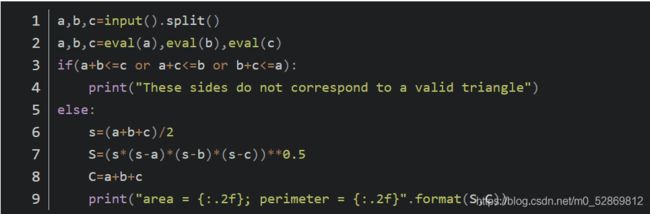
我学到了什么:
①**math.sqrt()==0.5;后者的效率更高,前者看上去更易理解
补充:写python程序时,出现错误:
ValueError: math domain error
原因:
某些操作不符合数学定义,如对负数取对数,对负数开平方。
②list.sort()无返回值。如果把这个赋值给某一个变量,那么它是无类型,编译会报错。即使使用了list()转换也是无效的。
关于list.sort()的补充:
list.sort(cmp=None, key=None, reverse=False)
参数:
cmp – 可选参数, 如果指定了该参数会使用该参数的方法进行排序。注意是方法,一般应该指的是库里面已经定义好的库方法吧
key – 主要是用来进行比较的元素,只有一个参数,具体的函数的参数就是取自于可迭代对象中,指定可迭代对象中的一个元素来进行排序。注意key应该是等于一个已经定义了的函数的名称
reverse – 排序规则,reverse = True 降序, reverse = False 升序**(默认)**。
③相比于别人的答案中使用了if,我的方法中使用了列表储存,创新且效率高,不足之处在于我写的名称太长了
④前面提到我的命名太长,导致截图的时候整个图被拉伸,字体显得很小,所以我温习了一下多行语句的书写,是加上“\”
⑤开始意识到要在等号两边加上一个空格,不然会显得我的代码很拥挤,不够美观
第2章-13 分段计算居民水费
为鼓励居民节约用水,自来水公司采取按用水量阶梯式计价的办法,居民应交水费y(元)与月用水量x(吨)相关:当x不超过15吨时,y=4x/3;超过后,y=2.5x−17.5。`
我的代码:
x = int(input())
if x<=15:
y = 4x/3
else:
y = 2.5x-17.5
print("{0:.2f}".format(y))
这个很简单, 就不再多说了
第2章-14 求整数段和
给定两个整数A和B,输出从A到B的所有整数以及这些数的和。
输出格式:
首先顺序输出从A到B的所有整数,每5个数字占一行,每个数字占5个字符宽度,向右对齐。最后在一行中按Sum = X的格式输出全部数字的和X。
我的代码:

我学到了什么:格式化输出
①温习了换行符是“\n"
②了解了print()里面的end()参数,知道print()默认是在输出后换行的,而加上了end()默认就是print()后不换行。
同时如果在end()里面加上参数,例如",",就会在每一次的输出后产生“,”分割符
③格式化中的{:d}意味着将所有的参数按照十进制(decimal integer)输出,如果在一开始在map()中没有使用(int)参数,在这里也可以将结果转换为整数打出(虽然我没有看出按照十进制打出而不是用来计算有什么用,在这里又不是用来转换进制)
第3章-2 查验身份证
一个合法的身份证号码由17位地区、日期编号和顺序编号加1位校验码组成。校验码的计算规则如下:
首先对前17位数字加权求和,权重分配为:{7,9,10,5,8,4,2,1,6,3,7,9,10,5,8,4,2};然后将计算的和对11取模得到值Z;最后按照以下关系对应Z值与校验码M的值:
Z:0 1 2 3 4 5 6 7 8 9 10
M:1 0 X 9 8 7 6 5 4 3 2
现在给定一些身份证号码,请你验证校验码的有效性,并输出有问题的号码。
我一开始的思路:
把输入的身份证号码放入到列表中作为元素,然后把每个元素提取出来分别进行加权计算,获得Z值,观察到M的取值有一定的顺序:
M=0 1 :M是从1开始递减;
M=2:M=X;
M=3-10:M从9开始递减。
主要存在的问题:
在进行序列每个元素提取进行加权计算时, 不仅代码非常长,写起来很繁琐,主要是很容易打错
而且在Z与M的判断中,先得判断Z和当前的M是否相同,还要在判断列表中最后一位的元素和M的比较结果,在一开始分元素时还需要用split(17)次,时间复杂度高
最后写道一大半就停下来想更简便的方法就没再写下去了
别人的代码:
python
def judge(mlist, jlist, flist):
sum = 0
x = 0
lnum = mlist[-1]
mlist = mlist[:17]
for i in mlist:
if i >= '0' and i <= '9':
#排除前17位数字中混杂有X的情况
#用ASCII值进行判断
sum += int(i) * flist[x]
x += 1
else:
return False
re = sum % 11
if jlist[re] == lnum:
#在这里把Z和M的关系具象化处理,把Z的值对应成jlist的下标,然后进行提取
return True
else:
return False
num = int(input())
cnt = 0
jlist = [‘1’, ‘0’, ‘X’, ‘9’, ‘8’, ‘7’, ‘6’, ‘5’, ‘4’, ‘3’, ‘2’]
flist = [7, 9, 10, 5, 8, 4, 2, 1, 6, 3, 7, 9, 10, 5, 8, 4, 2]
for i in range(num):
mlist = input()
#?为什么不加个list()将输入值进行转换
不然怎么可以进行函数里面的元素提取?
if judge(mlist, jlist, flist) == False:
print(mlist)
else:
cnt = cnt + 1
if cnt == num:
print(“All passed”)
我学到了什么:
①关于我在对mlist进行input()处理时为什么不采用list()转换的原因:str本身就是一个sequence,可以进行下标提取,下表缺省命名和其他的sequence是一样的,因而可以通过下标直接提取
②对列表的熟练应用:
首先:在Z的计算时,没有发现序列一一对应的关系,导致只从一个列表中提取而没有想到创建一个新列表在里面存放权重,然后对应相乘,也因为以前没有看见过对两个列表同时进行运算的例子
其次:在对mlist的最后一个元素的检验中,没有观察到z与m的隐藏对应关系,根本原因时观察角度有问题,没有看z和m的内部逻辑而是选择了z和m的外部逻辑关系,导致后面找错了
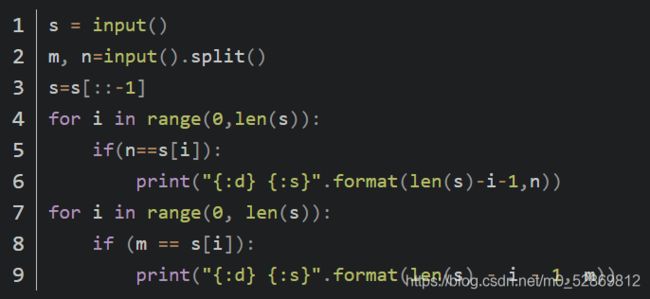
第3章-3 输出字母在字符串中位置索引
输入一个字符串,再输入两个字符,求这两个字符在字符串中的索引
我的代码:

别人的代码:
我学到了什么:
①思路的尝试和改变:我一开始并没有选择for,而是选择写一个函数来代替,发现了一个问题:这样写不可以引用字符串里面的元素,会报错,并且陷入死循环。代码如下:
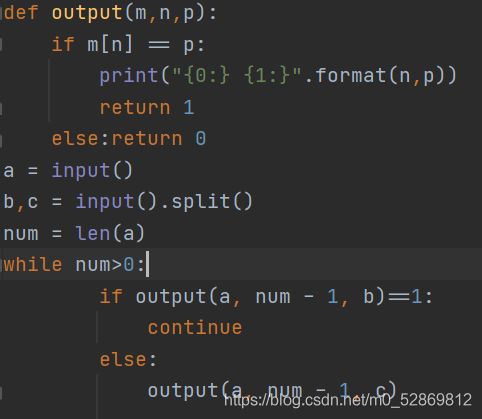
在查找原因的过程中,我发现了str是一个不可变类型的内置数据类型,如果对它其中的某个元素重新赋值,会开辟一个新的space来存储新的str,然后将指向原本str的指针指向新区域,而原来的str会被丢弃
在下面还设置了一个判断条件,只要满足字符串里面的字符与目标字符的对应,就不必进行下一步,提高工作效率
在使用for循环时,我一度困于不知道如何进行字符串的遍历,找到了以下四种方法进行小结:
1)直接进行遍历(for…in…)
-
利用下标遍历(for index,i(双变量,但index在编译时编译器知道它的缺省含义)in…)
-
利用range进行遍历(for index in range(len(strs))
-
利用迭代器(for i in iter())
PS:关于for的一些拓展用法:循环使用 else 语句
在 python 中,for … else 表示这样的意思,for 中的语句和普通的没有区别,else 中的语句会在循环正常执行完(即 for 不是通过 break 跳出而中断的)的情况下执行,while … else 也是一样。
②字符串的操作:
原本只是知道字符串也是一个sequence,但不清楚她具备sequence的哪些操作,今天知道了它可以执行(截取/替换/查找/分割)
NOTE:
截取字符串使用 变量[头下标:尾下标],就可以截取相应的字符串,其中下标是从0开始算起,可以是正数或负数,下标可以为空表示取到头或尾。
替换字符串使用 变量.replace(“被替换的内容”,“替换后的内容”[,次数]),替换次数可以为空,即表示替换所有。要注意的是使用replace替换字符串后仅为临时变量,需重新赋值才能保存。
查找字符串使用 变量.find(“要查找的内容”[,开始位置,结束位置]),开始位置和结束位置,表示要查找的范围,为空则表示查找所有。查找到后会返回位置,位置从0开始算,如果每找到则返回-1。
分割字符串使用 变量.split(“分割标示符号”[分割次数]),分割次数表示分割最大次数,为空则分割所有。
PS: 特殊操作:【::-1】把整个sequence倒转,非常方便
第3章-4 查找指定字符
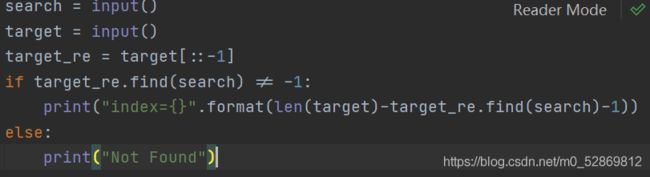
本题要求编写程序,从给定字符串中查找某指定的字符
我的代码:
第3章-5 字符转换
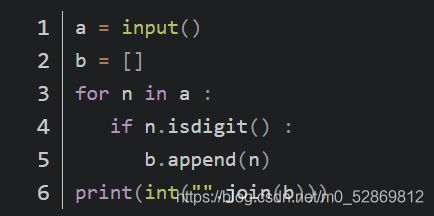
本题要求提取一个字符串中的所有数字字符(‘0’……‘9’),将其转换为一个整数输出。
我的代码:

别人的代码:
我学到了什么:
①join():通过整个函数可以实现将list转化为str,它含有两个参数,一个是在join前面,用来添加序列元素分割的符号,另一个就是在join里面,是目标
②虽然可以按照我的代码用字符串元素是否是“0123456789”来判断,但显然用isdigit()来判断更简洁,我也因此知道了判断字符串中数字的另一种方式
※第3章-6 求整数序列中出现次数最多的数
本题要求统计一个整型序列中出现次数最多的整数及其出现次数。
我的代码:(有人知道第二个测试点为什么报错吗【真让人头大.jpg】)
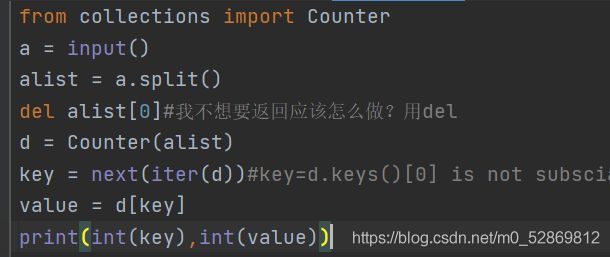
思路:
运用clooections包里面的Counter来使得将列表转化为字典,这样的好处是每一个键值对中,键是元素,值是该元素在序列中出现的次数,符合输出的顺序
接下来是运用在3.7版本及以上的Python,字典从无序性质变为有序来进行迭代器查找第一个键值并且输出,再通过该键值来获得字典中对应的值
他人的代码:
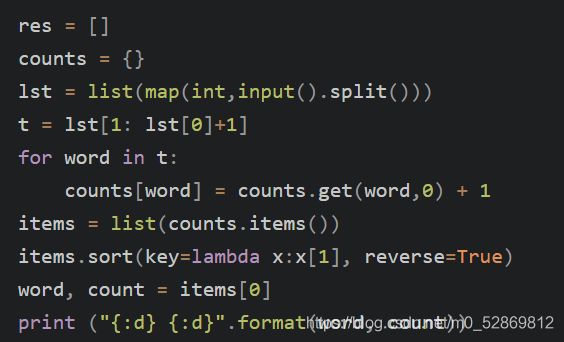
基本思路差不多一致,就对一些不熟悉的步骤进行解析:
我学到了什么episode first:
①map()的具体使用方法:(以前都是直接map(int,input().split(),还以为是要用int只能加个map…理解浅显)
map(function,iterable) 会根据提供的函数对指定序列做映射。
第一个参数 function 以参数序列中的每一个元素调用 function 函数,返回包含每次 function 函数返回值的新列表。
②对空字典的赋值:直接给不存在的键赋值
在这里值的作用与我写的代码是一致的,都是表示键代表的数值在序列中出现的次数
③跳出d.items的特殊结构弊端:
一开始我也是想到用d.items(),但是被它的特殊结构(元组里面包着一个列表,列表里面的元素是键值对)卡住了,这样的结构不能够进行基于下标的提取(本人亲测,把孩子害惨了),我猜测是因为在进行下标提取时元组里面只有一个列表作为元素,但我们想要提取的是列表里面的元素
上面的代码将外层的元组转化为了list()从而跳出(dict_items() is not subsciable的怪圈),虽然我还是不清楚为什么这样就可以了,可能是内外结构一致吧(知道的大神可以教教我吗)
④sort的最后两个参数:key and reverse
我上次已经做过相关的笔记,然而由于缺乏这方面的锻炼,已经忘记了,这次再看又被key里面为什么会有一个lamber困扰,现在知道代码运用了匿名函数在定义后可以直接被引用的优点,直接放在key上,然后key里面的参数x是引用sort的object list,从而以object里面的指定下标的元素为标准进行reverse规定的排列
我学到了什么 episode second:
①对list使用del方法从而不用返回值而进行对List的元素删除,而pop(index)是会返回值的
②来到了我最苦恼的问题——如何把键求出来
在runoob里面只是介绍了dict的内置函数里面唯一的与键提取有关的函数:dict.keys(),不好的一点是它只能返回dict里面所有的键名而不是我唯一想要的第一个键名
对了,关于为什么我要的是第一个键名,是因为我在texting的时候发现的一个regulation——dict的排序是根据value来进行降序排序的,根据(键,值)==(出现的数字,出现的次数),第一个键值对就符合了我的要求
说回正题,我注意到keys()是以一个list的形式返回,因此我想的是把keys()列表里面的first value取出,然而就出现了error:
is not subsciable(有大神知道的可以解答一下吗谢谢)
于是我找到了如下几个找到dict里面的first key的办法
(好家伙我觉得我可以就这个专门写一篇blog做个小结,找了老久了)
第一种方法是通过使用 iter() 函数首先将字典转换为一个迭代对象,然后使用 next 函数获取它的第一个索引键,来获取第一个键。也就是我现在使用的方法。
第二种方法是使用 list() 函数将字典转换为一个列表,然后在索引 0 处获取键。
第三种方法是使用 for 循环获取字典中的第一个键。在我们获得字典的第一个键后,就可以打破循环。
第四种方法就是d.items()了,可以转化为list()后使用,如果是单元素的话可以直接按照格式(key,value)=d.items()
第五种方法是看到qhh0205的blog(具体参考其blog里面的stack overflow 链接)上写的,应该只适用于单元素,简单粗暴:
d = {‘name’:‘haohao’}
key, = d
value, = d.values()
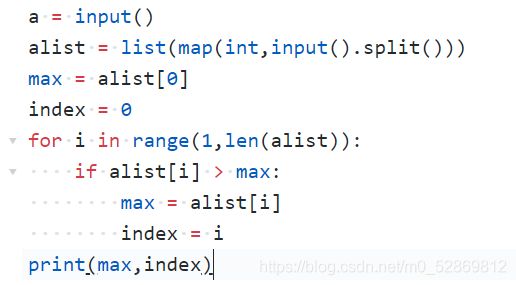
第3章-7 求最大值及其下标
本题要求编写程序,找出给定的n个数中的最大值及其对应的最小下标(下标从0开始)
我的代码:
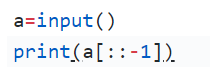
第3章-8 字符串逆序
输入一个字符串,对该字符串进行逆序,输出逆序后的字符串。
我的代码:
第3章-9 字符串转换成十进制整数
输入一个以#结束的字符串,本题要求滤去所有的非十六进制字符(不分大小写),组成一个新的表示十六进制数字的字符串,然后将其转换为十进制数后输出。如果在第一个十六进制字符之前存在字符“-”,则代表该数是负数。
我的代码:

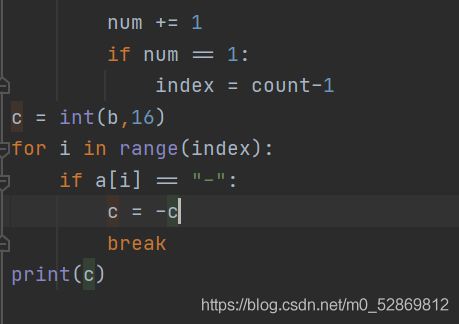
别人的代码: