Tensorflow:实战Google深度学习框架 学习笔记(四): 卷积神经网络
卷积神经网络结构
卷积层
Tensorflow中利用tf.nn.conv2d()函数实现卷积神经网络的卷积层操作。
conv = tf.nn.conv2d(input, filter_weight, stride = [1,1,1,1],padding = 'SAME')
conv2d函数第一个参数input为当前层的节点输入矩阵,注意这个矩阵是一个四维的矩阵input[A,B,C,D],后面三个维度对应一个节点矩阵,第一维定义一个输入的batch的大小,缺省值用None。例如如果input输入是图片,input[0,:,:,:]表示第一张图片,input[1,:,:,:]表示第二张图片。input的第二维第三维参数就表示这个图片(矩阵)的长宽,第四维表示输入图片(矩阵)的深度,即可以认为图片的通道数,比如RGB图片就是3。
conv2d函数第二个参数 filter_weight是卷积层的权重参数,即过滤器的权重矩阵,它也是一个四维的矩阵。
但和上面的input不同,前两维表示过滤器的尺寸,第三维表示当前层的深度,第四维表示过滤器的深度,即也是神经网络下一层节点矩阵的深度。
conv2d函数第三个参数stride为不同维度上的步长,虽然也是一个四维的数组,但第一维和第四维都是固定的1,第二维和第三维表示在长和宽上的步长。
conv2d函数第四个参数padding为填充方法,只有SAME添加填充0,和VALID表示不添加。
注意Tensorflow 里卷积过程的padding操作方式和吴恩达课程讲解不同,详细请见博客。
池化层
池化层的也是通过移动一个类似过滤器的结果完成,不过池化层中的计算不是节点的加权和,而是采用更简单的最大值(max pooling)或者平均值运算(average pooling),前者比后者运用更广泛。
所以与卷积层的过滤器类似,过滤器尺寸,移动步长,是否填充也需要人为设置。
# 实现了最大池化层的前向传播过程,ksize提供过滤器尺寸,同样第一维第四维固定1。
#strides步长,同样第一维第四维固定1。
#padding提供填充方式
pool = tf.nn.max_pool(actived_conv, ksize=[1,3,3,1],strides=[1,2,2,1],padding='SAME')
卷积层、池化层样例
#!/usr/bin/env python
# encoding: utf-8
import tensorflow as tf
import numpy as np
M = np.array([
[[1],[-1],[0]],
[[-1],[2],[1]],
[[0],[2],[-2]]
])
print("Matrix shape is: ",M.shape)
filter_weight = tf.get_variable('weights', [2, 2, 1, 1], initializer = tf.constant_initializer([
[1, -1],
[0, 2]]))
biases = tf.get_variable('biases', [1], initializer = tf.constant_initializer(1))
M = np.asarray(M, dtype='float32')
M = M.reshape(1, 3, 3, 1)
x = tf.placeholder('float32', [1, None, None, 1])
conv = tf.nn.conv2d(x, filter_weight, strides=[1, 2, 2, 1], padding='SAME')
bias = tf.nn.bias_add(conv, biases)
pool = tf.nn.avg_pool(x, ksize=[1, 2, 2, 1], strides=[1, 2, 2, 1], padding='SAME')
with tf.Session() as sess:
tf.global_variables_initializer().run()
convoluted_M = sess.run(bias, feed_dict={
x: M})
pooled_M = sess.run(pool, feed_dict={
x: M})
print("convoluted_M: \n", convoluted_M)
print("pooled_M: \n", pooled_M)
输出结果我们就可以发现Tensorflow如何实现padding操作。
经典卷积网络模型
LeNet-5
LeNet5 这个网络虽然很小,但非常经典,是第一个成功应用于数字识别问题的卷积神经网络,包含了深度学习的基本模块:卷积层,池化层,全连接层,总共七层,是其他深度学习模型的基础。
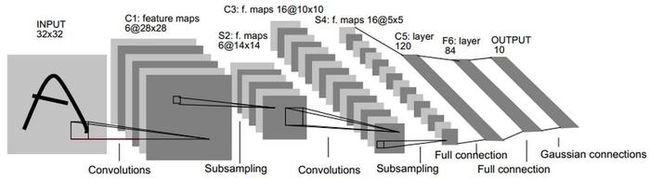
下面给出书上实现类似LeNet-5模型的代码:
由于卷积神经网络相比全连接神经网络只考虑每层多少个节点不同是有了卷积和池化操作要考虑每一层网络长和宽两个维度,所以首先需要修改输入数据的维度,除此之外mnist_train.py和全连接神经网络没有区别。
#!/usr/bin/env python
# encoding: utf-8
import tensorflow as tf
from tensorflow.examples.tutorials.mnist import input_data
import mnist_inference
import os
import numpy as np
INPUT_NODE = 784 # 输入节点
OUTPUT_NODE = 10 # 输出节点
LAYER1_NODE = 800 # 隐藏层神经员个数
BATCH_SIZE = 100 # 每次batch打包的样本个数
# 模型相关的参数
BATCH_SIZE = 100
LEARNING_RATE_BASE = 0.01
LEARNING_RATE_DECAY = 0.99
REGULARIZATION_RATE = 0.0001
TRAINING_STEPS = 60000
MOVING_AVERAGE_DECAY = 0.99
MODEL_SAVE_PATH = "MNIST_model/"
MODEL_NAME = "mnist_model"
def train(mnist):
# 定义输入输出placeholder。
x = tf.placeholder(tf.float32,[
BATCH_SIZE,
mnist_inference.IMAGE_SIZE,
mnist_inference.IMAGE_SIZE,
mnist_inference.NUM_CHANNELS],
name='x-input')
y_ = tf.placeholder(tf.float32, [None, mnist_inference.OUTPUT_NODE], name='y-input')
regularizer = tf.contrib.layers.l2_regularizer(REGULARIZATION_RATE)
y = mnist_inference.inference(x, True, regularizer)
global_step = tf.Variable(0, trainable=False)
# 定义损失函数、学习率、滑动平均操作以及训练过程。
variable_averages = tf.train.ExponentialMovingAverage(MOVING_AVERAGE_DECAY, global_step)
variables_averages_op = variable_averages.apply(tf.trainable_variables())
cross_entropy = tf.nn.sparse_softmax_cross_entropy_with_logits(logits=y, labels=tf.argmax(y_, 1))
cross_entropy_mean = tf.reduce_mean(cross_entropy)
loss = cross_entropy_mean + tf.add_n(tf.get_collection('losses'))
learning_rate = tf.train.exponential_decay(
LEARNING_RATE_BASE,
global_step,
mnist.train.num_examples / BATCH_SIZE, LEARNING_RATE_DECAY,
staircase=True
)
train_step = tf.train.GradientDescentOptimizer(learning_rate).minimize(loss, global_step=global_step)
with tf.control_dependencies([train_step, variables_averages_op]):
train_op = tf.no_op(name='train')
# 初始化TensorFlow持久化类。
saver = tf.train.Saver()
with tf.Session() as sess:
tf.global_variables_initializer().run()
for i in range(TRAINING_STEPS):
xs, ys = mnist.train.next_batch(BATCH_SIZE)
reshaped_xs = np.reshape(xs,(BATCH_SIZE, mnist_inference.IMAGE_SIZE,
mnist_inference.IMAGE_SIZE,mnist_inference.NUM_CHANNELS))
_, loss_value, step = sess.run([train_op, loss, global_step], feed_dict={
x: reshaped_xs, y_: ys})
if i % 1000 == 0:
print("After %d training step(s), loss on training batch is %g." % (step, loss_value))
saver.save(sess, os.path.join(MODEL_SAVE_PATH, MODEL_NAME), global_step=global_step)
def main(argv=None):
mnist = input_data.read_data_sets("data/", one_hot=True)
train(mnist)
if __name__=='__main__':
tf.app.run()
调整输入数据后,就是重头戏——卷积神经网络的前向传播结构。
import tensorflow as tf
#配置神经网络的参数
INPUT_NODE = 784
OUTPUT_NODE = 10
IMAGE_SIZE = 28
NUM_CHANNELS = 1
NUM_LABELS = 10
#第一层卷积层尺寸和深度
CONV1_DEEP = 32
CONV1_SIZE = 5
#第二层卷积层尺寸和深度
CONV2_DEEP = 64
CONV2_SIZE = 5
#全连接层节点的个数
FC_SIZE = 512
def inference(input_tensor, train, regularizer):
with tf.variable_scope('layer1-conv1'):
conv1_weights = tf.get_variable(
"weight", [CONV1_SIZE, CONV1_SIZE, NUM_CHANNELS, CONV1_DEEP],
initializer=tf.truncated_normal_initializer(stddev=0.1))
conv1_biases = tf.get_variable("bias", [CONV1_DEEP], initializer=tf.constant_initializer(0.0))
conv1 = tf.nn.conv2d(input_tensor, conv1_weights, strides=[1, 1, 1, 1], padding='SAME')
relu1 = tf.nn.relu(tf.nn.bias_add(conv1, conv1_biases))
with tf.name_scope("layer2-pool1"):
pool1 = tf.nn.max_pool(relu1, ksize = [1,2,2,1],strides=[1,2,2,1],padding="SAME")
with tf.variable_scope("layer3-conv2"):
conv2_weights = tf.get_variable(
"weight", [CONV2_SIZE, CONV2_SIZE, CONV1_DEEP, CONV2_DEEP],
initializer=tf.truncated_normal_initializer(stddev=0.1))
conv2_biases = tf.get_variable("bias", [CONV2_DEEP], initializer=tf.constant_initializer(0.0))
conv2 = tf.nn.conv2d(pool1, conv2_weights, strides=[1, 1, 1, 1], padding='SAME')
relu2 = tf.nn.relu(tf.nn.bias_add(conv2, conv2_biases))
# 将上一层卷积层的7x7x64的输出用reshape拉成一个向量作为全连接层输入
with tf.name_scope("layer4-pool2"):
pool2 = tf.nn.max_pool(relu2, ksize=[1, 2, 2, 1], strides=[1, 2, 2, 1], padding='SAME')
pool_shape = pool2.get_shape().as_list() # get_shape()得到是一个元组,all_list()将元组list化
nodes = pool_shape[1] * pool_shape[2] * pool_shape[3]
reshaped = tf.reshape(pool2, [-1, nodes])
with tf.variable_scope('layer5-fc1'):
fc1_weights = tf.get_variable("weight", [nodes, FC_SIZE],
initializer=tf.truncated_normal_initializer(stddev=0.1))
if regularizer != None: tf.add_to_collection('losses', regularizer(fc1_weights))
fc1_biases = tf.get_variable("bias", [FC_SIZE], initializer=tf.constant_initializer(0.1))
fc1 = tf.nn.relu(tf.matmul(reshaped, fc1_weights) + fc1_biases)
if train: fc1 = tf.nn.dropout(fc1, 0.5) # 这里引入了droupt的概念
with tf.variable_scope('layer6-fc2'):
fc2_weights = tf.get_variable("weight", [FC_SIZE, NUM_LABELS],
initializer=tf.truncated_normal_initializer(stddev=0.1))
if regularizer != None: tf.add_to_collection('losses', regularizer(fc2_weights))
fc2_biases = tf.get_variable("bias", [NUM_LABELS], initializer=tf.constant_initializer(0.1))
logit = tf.matmul(fc1, fc2_weights) + fc2_biases
return logit
关于每层由于卷积和池化作用导致的矩阵维度的变化的过程书上讲述很详细,就不啰嗦。另外,需要注意的有两个地方:
-
在第四层池化层的输出转换成全连接层的输入时,利用tensor的特权
get_shape()得到矩阵的维度,但由于是元组,用as_list()转换成list。用nodes保存将矩阵拉长的长度,这个长度就是矩阵长和宽的乘积。之后通过tf.reshape函数拉长成一个向量。第一个参数-1是一个缺省值,表示这个值是整个矩阵大小除以拉长nodes大小。
这里就是输入时一次前向传播多少个样例(图片)的数量。
关于tf.shape更多信息可以参考博客。 -
在全连接层引入了droupt的概念,它会在训练时将部分节点的输出改成0,避免过拟合问题,并且一般在全连接层使用,而不是卷积层和池化层。
最后类似修改上一章的验证程序mnist_eval的程序输入部分,就可以测试这个卷积神经网络。
import time
import tensorflow as tf
from tensorflow.examples.tutorials.mnist import input_data
import mnist_inference
import mnist_train
EVAL_INTERVAL_SECS = 10
BATCH_SIZE = 100
import time
import numpy as np
def evaluate(mnist):
with tf.Graph().as_default():
x = tf.placeholder(tf.float32,
shape=[None, mnist_inference.IMAGE_SIZE,
mnist_inference.IMAGE_SIZE, mnist_inference.NUM_CHANNELS], name='x-input')
y_ = tf.placeholder(tf.float32, shape=[None,mnist_inference.OUTPUT_NODE], name='y-input')
xs, ys = mnist.validation.images, mnist.validation.labels
reshape_xs = np.reshape(xs, (-1, mnist_inference.IMAGE_SIZE, mnist_inference.IMAGE_SIZE,
mnist_inference.NUM_CHANNELS))
print(mnist.validation.labels[0])
val_feed = {
x: reshape_xs, y_: mnist.validation.labels}
y = mnist_inference.inference(x,False,None)
correct_prediction = tf.equal(tf.argmax(y, 1), tf.argmax(y_, 1))
accuracy = tf.reduce_mean(tf.cast(correct_prediction, tf.float32))
variable_average = tf.train.ExponentialMovingAverage(mnist_train.MOVING_AVERAGE_DECAY)
val_to_restore = variable_average.variables_to_restore()
saver = tf.train.Saver(val_to_restore)
while True:
with tf.Session() as sess:
ckpt = tf.train.get_checkpoint_state(mnist_train.MODEL_SAVE_PATH)
if ckpt and ckpt.model_checkpoint_path:
saver.restore(sess,ckpt.model_checkpoint_path)
global_step = ckpt.model_checkpoint_path.split('/')[-1].split('-')[-1]
accuracy_score = sess.run(accuracy,feed_dict=val_feed)
print('After %s train ,the accuracy is %g'%(global_step,accuracy_score))
else: print('No Checkpoint file find') # continue
time.sleep(EVAL_INTERVAL_SECS)
def main():
mnist = input_data.read_data_sets('../mni_data',one_hot=True)
evaluate(mnist)
if __name__ == '__main__':
main()
上面给出的卷积神经网络可以将上一章全连接神经网络在mnist数据集上98.4%左右的准确度提高到99.4%。
Inception-v3 模型
Inception结构是和LetNet-5结构完全不同的卷积神经网络的结构。在LetNet-5里将不同的卷积层通过串联在一起,而Inception是将不同的卷积层以并联方式对同一个输入层卷积,然后将卷积得到的结果结合在一起,如下图所示。
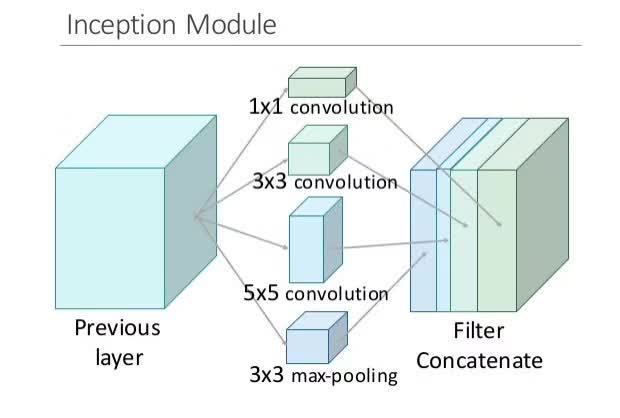
相对于一些卷积神经网络结构倾向于把神经网络做的越来越深,Inception则倾向于更宽.在传统的卷积网络中,每一层都会从之前的层提取信息,以便将输入数据转换成更有用的表征。但是,不同类型的层会提取不同种类的信息。5×5 卷积核的输出中的信息就和 3×3 卷积核的输出不同,又不同于最大池化核的输出……在任意给定层,我们怎么知道什么样的变换能提供最「有用」的信息呢?
Inception 模块会并行计算同一输入映射上的多个不同变换,并将它们的结果都连接到单一一个输出。换句话说,对于每一个层,Inception 都会执行 5×5 卷积变换、3×3 卷积变换和最大池化。然后该模型的下一层会决定是否以及怎样使用各个信息。