用于视觉问答的图形推理网络模型《Graph Reasoning Networks for Visual Question Answering》
目录
一、文献摘要介绍
二、网络框架介绍
三、实验分析
四、结论
这是视觉问答论文阅读的系列笔记之一,本文有点长,请耐心阅读,定会有收货。如有不足,随时欢迎交流和探讨。
一、文献摘要介绍
The interaction between language and visual information has been emphasized in visual question answering (VQA) with the help of attention mechanism. However, the relationship between words in question has been underestimated, which makes it hard to answer questions that involve the relationship between multiple entities, such as comparison and counting. In this paper, we develop the graph reasoning networks to tackle this problem. Two kinds of graphs are investigated, namely inter-graph and intra-graph. The inter-graph transfers features of the detected objects to their related query words, enabling the output nodes to have both semantic and factual information. The intra-graph exchanges information between these output nodes from inter-graph to amplify implicit yet important relationship between objects. These two kinds of graphs cooperate with each other, and thus our resulting model can reason the relationship and dependence between objects, which leads to realization of multi-step reasoning. Experimental results on the GQA v1.1 dataset demonstrate the reasoning ability of our method to handle compositional questions about real-world images. We achieve state-of-the-art performance, boosting accuracy to 57.04%. On the VQA 2.0 dataset, we also receive a promising improvement on overall accuracy, especially on counting problem.
作者认为在视觉问答系统(VQA)中,语言和视觉信息之间的交互作用一直受到重视。然而,有关词语之间的关系被低估了,这使得人们很难回答涉及多个实体之间关系的问题,例如比较和计数。为了解决这一问题,本文开发了图形推理网络。研究了两类图,即图间图和图内图。图间将被检测对象的特征传递给相关的查询词,使得输出节点同时具有语义和事实信息。图内从图间交换这些输出节点之间的信息,以放大对象之间隐含但重要的关系。这两种图相互协作,从而我们得到的模型能够推理对象之间的关系和依赖关系,从而实现多步推理。在GQA v1.1数据集上的实验结果证明了我们的方法处理真实图像合成问题的推理能力。我们实现了最先进的性能,精度提高到57.04%。在VQA 2.0数据集上,我们也得到了一个有希望的整体精度改进,特别是在计数问题上。
二、网络框架介绍
VQA任务的目标是根据图像I回答给定的问题Q。使用对象检测器Faster-RCNN,我们将输入图像  转换为对象特征
转换为对象特征![]() ,其中
,其中![]() ,其中
,其中  是检测到的对象的数量,
是检测到的对象的数量, 是特征维度。问题
是特征维度。问题![]() 是
是  个单词的序列,可以使用LSTM将其编码为
个单词的序列,可以使用LSTM将其编码为![]() ,其中
,其中![]() ,
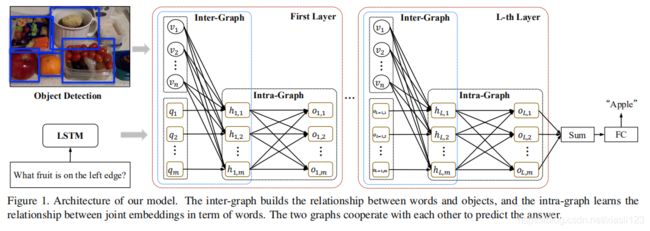
,![]() ,下图1是网络模型框架。
,下图1是网络模型框架。
引入BAN 可以同时减少两个输入通道,并获得问题特征  和图像特征
和图像特征  的统一表示。 它首先计算 和之间的双线性注意图
的统一表示。 它首先计算 和之间的双线性注意图![]() ,并在此条件下生成联合嵌入
,并在此条件下生成联合嵌入  ,如下所示:
,如下所示:
![]()
注意图G定义为:
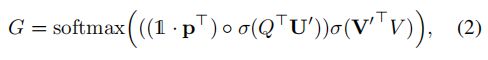
其中,![]() 是要学习的变量,
是要学习的变量,![]() 是一个向量,所有元素等于1,
是一个向量,所有元素等于1,![]() 表示共享嵌入大小,
表示共享嵌入大小,![]() 是sigmoid激活函数,
是sigmoid激活函数,![]() 是Hadamard乘积(元素乘法)。然后,联合嵌入的第k个元素值由下式给出:
是Hadamard乘积(元素乘法)。然后,联合嵌入的第k个元素值由下式给出:

其中,![]() 是要优化的参数,
是要优化的参数,![]() 是
是![]() 的
的  列,
列,![]() 是
是![]() 的 列。
的 列。
之后,我们将 输入到![]() 等分类器中,以计算答案
等分类器中,以计算答案 的得分
的得分![]() ,然后选择最高的一个作为预测答案,其中
,然后选择最高的一个作为预测答案,其中  是答案集。
是答案集。
给定 的计算,式(1)可以改写为:
的计算,式(1)可以改写为:

其中,![]() 和
和![]() ,它与图形注意力网络有着密切的联系,给定输出矩阵为:
,它与图形注意力网络有着密切的联系,给定输出矩阵为:

其中![]() 和
和![]() 分别表示查询,键和值,可以很容易地从图的角度说明等式(4)。等式(4)中的注意力图
分别表示查询,键和值,可以很容易地从图的角度说明等式(4)。等式(4)中的注意力图![]() 等效于等式(6)中的图
等效于等式(6)中的图![]() ,并且
,并且![]() 为值
为值![]() 。查看公式(2)中的关注图的定义,图
。查看公式(2)中的关注图的定义,图![]() 表示从节点
表示从节点![]() 到节点
到节点![]() 应该流过多少信息。
应该流过多少信息。![]() 和
和![]() 分别对应于等式(6)中的查询
分别对应于等式(6)中的查询![]() 和键
和键![]() ,考虑到这一点,等式(6)仅接受单一类型的输入,而VQA模型则需要考虑多模式输入(即图像和问题)。因此,等式(4)中包含
,考虑到这一点,等式(6)仅接受单一类型的输入,而VQA模型则需要考虑多模式输入(即图像和问题)。因此,等式(4)中包含![]() 和
和![]() 的附加Hadamard积,以生成输出节点
的附加Hadamard积,以生成输出节点![]() ,其中
,其中![]() 。最后,通过对等式(5)中
。最后,通过对等式(5)中![]() 中所有节点的汇总,联合嵌入表示整个图。
中所有节点的汇总,联合嵌入表示整个图。
等式(4)和(5)提供了一种优雅的方法来研究问题特征Q和图像特征V之间的关系。但是,对等式(5)中的![]() 列进行简单的汇总不能完全解决与单词对应的联合嵌入
列进行简单的汇总不能完全解决与单词对应的联合嵌入![]() 之间的连接。
之间的连接。
因此,我们提出了图推理网络,如图1所示,该图推理网络的每一层都有两个图,即图间图和图内图。 图间图学习建立单词和对象之间的关系并生成它们的联合嵌入,而图内图将通过利用它们的交互来更新联合嵌入。 而且我们发现可能无法立即确定正确的答案,因此我们堆叠了图以使单词与图像以及单词本身多次交互。
下面进行介绍图形推理网络(Graph Reasoning Networks)。
2.1. Inter-Graph
inter-graph的主要目标是定位与问题中每个词的语义信息相关的对象,从式(4)开始,我们有一个多层多瞥扩展。图的第 层取上一层的输出节点
层取上一层的输出节点![]() ,并将图像特征
,并将图像特征![]() 作为其输入节点,并建立图形
作为其输入节点,并建立图形![]() 在
在![]() 和
和![]() 之间遵循等式(2),其中
之间遵循等式(2),其中![]() 是瞥见次数,第
是瞥见次数,第 个图的注意力计算为:
个图的注意力计算为:
![]()
第 层拥有自己的![]() 和
和![]() ,并且除了
,并且除了![]() 以外,参数之间还共享参数
以外,参数之间还共享参数![]() 和
和 。了解图的注意力后,我们使用等式(4)生成联合嵌入:
。了解图的注意力后,我们使用等式(4)生成联合嵌入:

我们不再从每一个一瞥中串联或总连结接头嵌入,而是遵循BAN,使用残差形式来整合先前学习的接头嵌入,然后式(8)变成:
![]()
其中,![]() ,
,![]() 将联合嵌入投影到
将联合嵌入投影到![]() 的相同尺寸。如上所述,图之间的第一层将
的相同尺寸。如上所述,图之间的第一层将![]() 设为
设为![]() 来定位查询的对象,而更高层将上一层图的输出视为
来定位查询的对象,而更高层将上一层图的输出视为![]() 来包含更多与先验知识相关的可视信息。最后的联合嵌入
来包含更多与先验知识相关的可视信息。最后的联合嵌入![]() 被重写为
被重写为![]() 作为缩写,并被处理到 inter-graph进行进一步的处理。
作为缩写,并被处理到 inter-graph进行进一步的处理。
2.2. Intra-Graph
inter-graph不是在等式(5)中汇总intra-graph的输出,而是在  中在每个节点之间交换信息,后者可以从其他节点学习上下文。
中在每个节点之间交换信息,后者可以从其他节点学习上下文。
我们使用双线性注意图来构建图。第层的图映射![]() 按式(7)
按式(7)![]() 个瞥见计算,在此基础上,瞥见 处的intra-graph节点从其他节点收集信息,表示为式(9):
个瞥见计算,在此基础上,瞥见 处的intra-graph节点从其他节点收集信息,表示为式(9):
![]()
其中,![]() ,
,![]() ,intra-graph
,intra-graph ![]() 的输出(
的输出(![]() 的缩写)可以用来回答问题,也可以视为下一层图间文本输入,再次查看图像,以涉及更多复杂推理的线索。
的缩写)可以用来回答问题,也可以视为下一层图间文本输入,再次查看图像,以涉及更多复杂推理的线索。
在对inter-graph和intra-graph进行L层叠加之后,我们将 ![]() 的所有节点在通道维上进行汇总以表示整个图,并将其传递给一个两层MLP进行分类:
的所有节点在通道维上进行汇总以表示整个图,并将其传递给一个两层MLP进行分类:
![]()
其中,![]() 和
和![]() 是答案词汇量的大小。
是答案词汇量的大小。
三、实验分析
作者在GQA v1.1和VQA 2.0数据集上评估所提出的图形推理网络。对于VQA数据集,通过限制出现在训练和验证数据集中超过8次的单词来构造答案词汇,从而共产生答案集 |Σ|= 3,129。然后,我们将问题的长度m截短或填充到15个单词。LSTM的输入维度为600,我们的模型学习了其中的300个,使用GloVe向量[30]预训练了300个,输出维度C为1024。我们从BottomUp 获得对象特征,D = 2048,并且对象数量 固定为100。联合嵌入大小 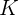 设置为1024,并且 =
设置为1024,并且 = ![]() 以增加注意的能力。为了节省每一层的内存以多次堆叠网络,将瞥见数从BAN 中的8缩小为
以增加注意的能力。为了节省每一层的内存以多次堆叠网络,将瞥见数从BAN 中的8缩小为![]() 。在每个线性映射之后,都添加了权重归一化和丢弃(Dropout)(p = 0.2),以稳定输出并防止过度拟合。由于一个问题可能存在多个正确答案,因此二进制交叉熵损失
。在每个线性映射之后,都添加了权重归一化和丢弃(Dropout)(p = 0.2),以稳定输出并防止过度拟合。由于一个问题可能存在多个正确答案,因此二进制交叉熵损失 计算如下:
计算如下:

其中,![]()
Adamax 是Adam的变体,用于优化我们的模型。 初始学习率是0.001,并且每个周期以0.001的速度增长,直到热启动达到0.004为止,保持恒定直到第11周期,并且每两个周期以1/4的速度衰减至0.00025。 批处理大小为128。
我们对GQA数据集遵循与VQA相同的设置,除了在平衡训练数据集和平衡验证数据集上构造答案词汇表,使|∑|=1567,将问题长度m扩展到22,以适应复杂问题的长描述,使用自下而上从官方网站下载的对象特征对包含在GQA验证集中的图像进行了训练,因此可能会在分数上给出错误的改进,对象数n从36变为100,并更改为softmax交叉熵损失,因为每个问题只有一个正确答案:
![]()
其中,如果答案 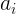 是正确的答案,则
是正确的答案,则![]() ,否则
,否则![]() 。
。
表1 GQA test2019数据集上我们单一模型的准确性

表2 VQA2.0 数据集上我们单一模型的准确性

表3对GQA平衡验证数据集的准确性。

表4在VQA2.0验证数据集上打分

此外,我们还研究了不同长度问题的准确性曲线,以显示我们的模型在图2中的多步推理能力。

图3 显示了不同层数准确率的差异
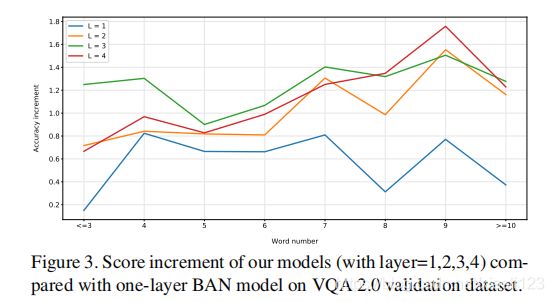
图4 可视化注意力图
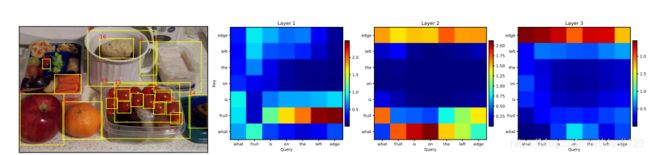

图5.示例说明了BAN和我们的图形模型所预测的答案。

四、结论
In this paper, we develop graph reasoning networks composed of layers of inter-graph and intra-graph, the inter-graph learns the relationship between words in the question and objects in the image and generate the joint embeddings of them, while the intra-graph gets the relationship between these joint embeddings in term of words to exchange context information, which is fifirst taken into consideration by our model for VQA problem. By stacking our graphs, the compositional questions that involve relation between multiple entities can be better understood and correctly answered based on the image. Our method achieves state-of-the-art performance on both GQA v1.1 and VQA v2.0 test server, and the ablation studies show that our networks significantly outperform BAN on a variety of questions, particularly on the long and complex ones.
在本文中,作者开发了由图间(inter-graph)和图内(intra-graph)层组成的图推理网络,图间学习问题中的单词与图像中的对象之间的关系并生成它们的联合嵌入,而图内图以单词的形式获取这些联合嵌入之间的关系以交换上下文信息,这是我们的VQA问题模型首先考虑的。 通过堆叠我们的图,可以更好地理解并正确地回答涉及多个实体之间关系的构图问题。 我们的方法在GQA v1.1和VQA v2.0测试服务器上均达到了最先进的性能,并且消融研究表明,我们的网络在各种问题上,特别是在较长和复杂的问题上,均优于BAN。
此篇文章和《Dynamic Fusion with Intra- and Inter-modality Attention Flow for Visual 》有点相似,都是学习图间和图内的关系,进而提高模型的性能,而在计算方式上略有差别,并且在最近提出的GQA数据集中性能也可观。以后能不能把GQA等数据集融入到VQA数据集,以增强数据提高模型的性能,此篇是值得借鉴的文章。