self_drive car_学习笔记--第12课:基于强化学习的自动驾驶系统
前言:本节是自动驾驶系列课程最后一节。首先介绍一个强化学习在无人驾驶里面的应用情况,然后介绍一些比较好玩的强化学习网页版资源,最后简单总结从第1课到目前所介绍的内容。能力比较弱,有些理解错误地方,还望大大们不吝赐教。觉得写得还行,麻烦赏个赞哈。好了,让我们开始这系列最后一节课吧。
概要:
1 机器学习在自动驾驶中的应用
2 DQN
3 DeepTraffic项目
4 课程总结
1机器学习在自动驾驶中的应用
1.1 2019年机器学习趋势
1)2018年是NLP深度学习技术的重要之年:BERT

BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding
【文献下载:https://arxiv.org/pdf/1810.04805.pdf】
2)Tesla Autopilot Hardware v2+:自动驾驶大规模基础

3)AdaNet:AutoML with NasNet cell searching
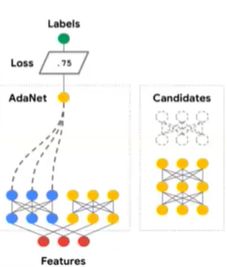
【从事AI领域,无论具体哪一方面,都是需要关注机器学习的前沿技术,很多任务都是相通,相互可以借鉴的;目前可能看起来没有相通,但是不久将来,思想一定是相通的;所以需要关注各个邻域的机器学习前沿技术】
4)BigGAN 和GPT2.0:大模型和大训练对任务的影响【一般对结果有质的飞跃影响】
5)AlphaZero&OpenFive&AlphaStar:强化学习在复杂任务中的应用【这三个是游戏里面的典型强化学习的应用】
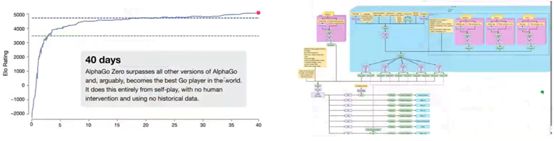
【右侧是OpenFive对应的结构图,并不单纯使用搜索收敛的,用到辅助收敛的】【AlphaStar使用了很多的人类经验来辅助收敛的】
【右图的下载:https://cdn.openai.com/research-covers/openai-five/network-architecture.pdf】
1.2 强化学习认识
1)强化学习:通过和环境交互学习,学到如何在相应管泽【当前环境下】中采取最优策略的行为
----不需要标注
----具有鲁棒性
----对行为(Action)的学习更友好
2)强化学习基本概念:
2-1)Environment:整体任务的工作环境
2-2)Reward:激励、奖励,对行为好坏的一个评价
----Value Function【值函数】
----不同环境可以有不同的奖励
----奖励的设计对RL来说至关重要的
2-3)Policy:智能体的一组Action
2-4)Agent:智能体,一般是RL的作用对象
2-5)Action:智能体可以采用所有可能的行动
2-6)Sensors:环境返回的当前情况
2-7)MDP模型:马尔科夫决策过程
![]()

【图中展示的是强化学习和环境交互作用】
1.3逆强化学习
1)逆强化学习:能够找到一种能够高效可靠的reward的方法
----专家在完成某项任务时,其决策往往时最优的或接近最优的
----当所有的策略所产生的累积回报都不比专家策略所产生的累积回报期望大时,对应的回报函数就是根据示例学到的回报函数
【专家,指的是有经验的人给出的一组结果或者(一组)action】【专家不属于经验数据,而是有效并高质量的数据】
2)学徒学习方法【以专家的为标准,根据当前情况联立方程组,进行求解当前模型的未知参数的学习方法】
3)最大边际规划方法Max Margin Plan
4)基于最大熵的逆向强化学习
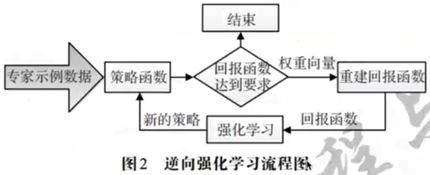
参考:Ng A Y, Russell S J. Algorithms for Inverse Reinforcement-Learning
【https://ai.stanford.edu/~ang/papers/icml00-irl.pdf】
https://github.com/matthewja/inverse-reinforcement-learning
1.4 模仿学习
1)模仿学习:从专家提供的范例中学习,一般提供人类专家的决策数据,每个决策包含状态和动作序列,把状态作为特征,动作走位标记进行分类或回归学习,从而得到最优策略模型
----目标是使得模型生成状态-动作轨迹分布和输入的轨迹分布相匹配
----一种监督学习方法(行为克隆)
2)泛化性很差【这个模型适用,换其他模型的适用不了】,依赖大量数据
3)数据增广【目的提供所需的大量数据】

参考:Alexandre Attia :global overview of imitation learning
【https://arxiv.org/pdf/1801.06503.pdf】
1.5 强化学习主要方法
1)深度学习:感知能力,缺乏一定的决策能力
2)强化学习:决策能力,非常适合做无人车决策规划
3)Model Based VS Model Free
【model based,对环境进行一个基本建模,该模型可以锁定一些基本反馈结果,根据反馈结果做一些最优的探索行为;model free,对环境一无所知,通过一点点尝试得到反馈,根据反馈来做出决策】
4)On-Policy VS Off-Policy 【这两者在深度强化学习领域属于比较重要的】
----SARSA(on-policy例子) VS Q-Learning(off-policy例子)
【生成训练样本的policy,和网络参数更新的policy是否一致,一致则是On-Policy,否则是Off-Policy】
- DQN (Deep Q Network)
----端到端的学习方式
----深度卷积神经网络和Q学习
----经验回放技术
6)DDPG(Deep Deterministic policy Gradient)
----actor-critic算法
----深度神经网络作为逼近器【决策梯度思路】
【DQN和DDPG是当前深度强化学习领域的主要两个流派】
7)主要方法简介:

1.6 无人车如何使用强化学习(模仿学习)
1)传感器感知(输入)
----radar、lidar、GPS、camera ….
2)从原始数据抽取高阶特征
3)机器学习将特征转化为知识
4)只是处理后进行推理
----如,什么是应该躲避的障碍物
5)做出合理的动作决策
6)有多少是可以通过学习得到的
----Mapping
【1)-6)可结合下面的流程图串起来学习】【推理时,加入人类经验信息,告诉怎么处理,下次匹配到同样情况,也采取相同的做法,这就是模仿学习】


【流程图中,高维特征抽取feature extraction到推理reasoning都是可以深度学习来做的】 【右侧上面表示神经网络的感知;右侧下方知识神经网络的推理】【流程图中planning 到 action,主要使用的是蒙特卡洛搜索方法】
1.7 无人车强化学习示例
Nvidia: https://developer.nvidia.com/blog/deep-learning-self-driving-cars/【并不完全强化学习思路,加入了很多人类经验】
Wayve: https://wayve.ai/blog/learning-to-drive-in-a-day-with-reinforcement-learning/【完全强化学习思路】
【强化学习应用在控制层,可视为一个更高级的控制思路】
2 DQN
【DQN的全称是deep Q-network,是一种深层神经网络的算法,用来预测Q值的大小。Q值可以理解为状态动作价值,即智能体在某一状态下执行该动作所带来的预期收益】
2.1 Q-learning
1)Q-Table
----为每一个state上进行的每一个action计算出最大的未来reward的期望
----每个状态允许四种可能的操作:左移、右移、上移、下移
----Table里的参数式给定最佳策略的状态下采取相应动作获取最大未来奖励期望
2)如何计算Q-table中每个元素的值?
----Q-learning
----学习动作值函数(Q值)
----Bellman方程

【图中表示一个骑士想走到城堡,碰到红色敌人就减少15体力,移动一个就消耗0.1体力,移动到城堡加10体力,每个table保存的是未来获得最大reward的可能性,这个可能性的大小就是更新的Q值】
3)更新Q值
----选取一个动作:再基于当前的Q值估计得出的状态state下选择下一个动作action
----采用动作action并且观察输出的状态S’和奖励reward。接着更新函数Q(s,a)。
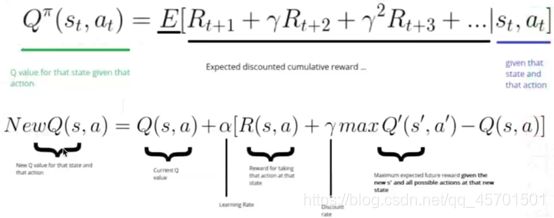
【图中第一条公式就是bellman方程;小写r表示的是衰减项;第二公式就是更新Q值;a表示更新频率】
4)DQN例子

【灰色格子表示不能走的,+1表示目标点并获取+1的reward,而不小心走到-1就是获取了-1的reward了,每走一步都会有衰减0.1的reward】
5)State-Action value function
![]()
6) Q-Learning
----使用最佳策略使得最大化未来的reward值(Q值)
----Off-policy
----持续迭代更新每一步(s,a)
- Exploration VS Exploitation(探索和使用)
----局部最优(贪心)
----初始的时候对信息一无所知
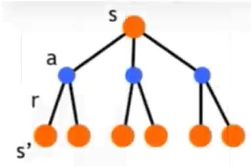
8)持续更新(S,A)是Q-learning的最大问题

9)低效,泛化能力差【高维度时,Q-table存储效率低下,】
10)对复杂问题维数爆炸【Q-table】
11)使用Deep Learning代替Q-Table

12)这是deepmind发表再nature上的一篇文章


参考:playing atari with deep reinforcement learning【https://arxiv.org/pdf/1312.5602.pdf】
2.2 如何训练DQN
1)给定状态转移方式
2)在状态s用前向推理计算所有Action的预测Q值
3)前向推理下一步s’及最大Q’值
![]()
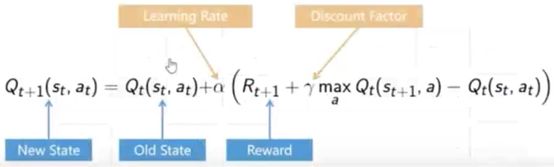
4)Q值设为
![]()
5)并用Loss funtion进行梯度更新

6)经验回放【训练过程中优化方式之一,如DQN论文提出的经验回放;经验回放,把探索完的Q值,回放给网络学习,把这些网络切成片段,一步一步放到网络中,进行反馈学习,有如下两个优点】
----提高数据利用率
----遗忘数据流顺序(加入随机性)【接着上述的网络切成片段,也就是说,让其遗忘这些那些路径是最优,遗忘片段在路径上的顺序,防止模型依赖某一套顺序链】【深度强化学习,训练过程中,都是要添加随机性,防止惯性】
7)【DQN论文中对】learning优化:不到1000步就优化一次loss function
8)reward clipping【DQN论文中减少reward结果】,skip frames【同时跳过一些不好的结构frams】
8)【DQN论文】伪代码

【这里的循环迭代不是训练网络,而是更新Q值和观测结果,需要将这些观测和Action存下来,去更新网络】
9)Epsilon是探索周围空间的概率
----探索和使用的两难困境
【采样,打断replay,对训练结果进行采样,进而做loss funtion】【探索过程中,并不知道哪一步是最优的,或者一开始,加入随机性,网络还是下降到某一个局部最优点,那么该局部点可视为比较好的结果】【在训练过程中加入随机性的思想,目前还是具有很重要意义】
3 DeepTraffic项目
3.1 deep traffic
1)MIT课程的作业【毕业时,需要将车辆训练到每小时65码速度】
MIT 6.S094
https://selfdrivingcars.mit.edu/deeptraffic【该链接无效了,只是跳转到
https://deeplearning.mit.edu/,可能是关闭了还是咋滴,不清楚;不过真的很好玩,看起来】
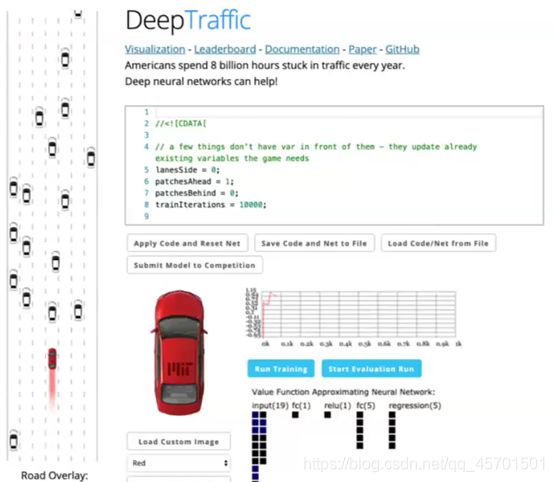
【老师就是把这个作业里面的内容做了介绍,但是现在找不到该页面了,说不再提供了。一种在线编写代码,利用本地的gpu进行强化学习训练方式,太cool了,可惜现在找不到这界面来自己学学玩玩】
2)paper:
DeepTraffic: Crowdsourced Hyperparameter Tuning of Deep Reinforcement Learning Systems for Multi-Agent Dense Traffic Navigation【https://arxiv.org/pdf/1801.02805.pdf】
4 系列课程总结

自动驾驶能力要求:

图片来源【截图只是部分】:http://taylorliu.com/topics/data/apollo-v2.pdf
【左侧是基本技能,可能做非无人驾驶也是可以用到的;右侧是无人车开发必须掌握的技能,需要主动下功夫去学习的】
【读论文,老师推荐读那些有项目的论文,因为没项目的论文看起来很虚】
【http://rail.eecs.berkeley.edu/deeprlcourse/这个大学的课,讲授强化学习模仿学习非常好。】
答疑环节:
1)专家指的是,有经验的人给出的一组结果或者action。例如,王者荣耀职业玩家提供的数据可视为一组专家数据。
2)强化学习和逆强化学习区别在于,强化学习就是让智能体在环境中给出一个最佳决策;强化学习做决策时需要使用reward参数,逆强化学习,就是为了获取reward参数的。这些使用到的探索信息,就是专家给出的,数据就是重点学习对象。
强化学习就是让智能体学会做决策的方式;逆强化学习就是怎么让智能体学习的过程中reward获取。
3)sarsa是在更新Q时已经想好了下一步的动作是什么,而Q-learning是最大化Q方向来更新Q,等到下一状态时再想怎么走
个人小结:这节课简单介绍了一些强化学习基本概念这些,然后介绍了mit一个作业,也讲解了其中的一些代码。这次看着有些激动地方是,原来可以网页端进行强化学习训练的,当然只是使用到gpu。比较遗憾的是,现在这些网页都不开放了,有点可惜了。多查找一些,到底是什么原因导致页面没有了。是原因,还是麻省理工把这个课程下架了?好了,自动驾驶的基本课程到今天(20210201)结课。但是,自己还是很多地方都是不懂得,仍需要下很大功夫来学习。
#####################
感恩授课老师的付出
图片版权归原作者所有
不积硅步,无以至千里
好记性不如烂笔头
感觉有点收获的话,麻烦大大们点赞收藏哈