python做正态分布的例子_多因子探索分析知识点总结及Python实现
0 目录
1. 假设检验
2. 卡方检验
3. 方差检验
4. 相关系数
5. 线性回归
6. 主成分分析PCA
7. 交叉分析
8. 分组与钻取
9. 相关分析
10. 因子分析
11. 小结
正文
1. 假设检验
(1)原理说明

假设检验就是根据一定的假设条件,从样本推断总体或者推断样本与样本之间关系的一种方法。
我们换一个说法来解释假设检验就是做出一个假设,然后根据数据或者已知的分布性质来推断这个假设成立的概率有多大,具体的过程为:
第一步,建立原假设
这个假设,我们用一个记号来表示,就是
第二步,选择检验统计量
这里提到的检验统计量是根据数据的均值、方差等性质构造的一个转换函数。构造的这个函数的目的,是让这个数据符合一个已知的分布比较容易解决的格式。比如,把一些数据减去它的均值,再除以标准差,这样判断这个转换后的统计量,也就是我们所说的检验统计量是否符合标准正态分布,即可以判断数据的分布是否是正态分布的概率了。
第三步,根据显著性水平确定拒绝域
显著性水平,一般用希腊字母
显著性水平一般是人为定的一个值,这个值定的越低,那么相当于对数据和分布的契合程度的要求就越高。这个值我们一般取 0.05,也就是说要求数据有 95% 的可能与某分布一致。一旦确定了显著性水平,那么这个已知的分布上就可以画出一段与这个分布相似性比较高的区域,我们叫做接受域。接受域以外的区域,就是拒绝域。如果上一步说到的检验统计量落入了拒绝域,那
第四步,计算P直或者样本统计值,并作出判断
最后一步就是根据计算的统计量和我们要比较的分布进行判断的过程。判断的思路有两种,第一种是根据我们前面讲到的区间估计的方法,计算一个检验统计量的分布区间,看这个区间是不是包含了我们要比较的分布的特征;另一个方法就是计算一个P值直接和显著性水平进行比较。这个P值可以理解成比我们计算出来的检验统计量结果更差的概率,如果P值小于
(2)举例
下面通过一个例子说明假设检验。

比如有一个洗衣粉制造厂,因为各种因素产出的每袋洗衣粉不可能每袋重量都相同。根据历史经验产出的规格,均值为500g,标准差为2g。现在抽样某台机器产出的洗衣粉重量为501.8g、502.4g、499g、500.3g、504.5g、498.2g、505.6g,由此判断这台机器是不是符合该洗衣粉厂的要求。我们来根据上面的方法进行假设检验:
第一步,我们先确定原假设和备则假设。原假设应尽可能接近于某分布,所以这里我们假设这个机器生产的这些样本是符合均值500g、标准差2g的正态分布的。这个就是原假设,也就是
第二步,既然我们假设分布均值符合500g,标准差2g的正态分布,那我们就像这样构造它的统计量。这个统计量,他的分子是它的均值减去我们假设的正态分布均值,而它的分母则是每袋洗衣粉的误差,那么这个统计量应该是符合标准正态分布的。
第三步,确定显著性水平。我们选择0.05,一旦显著性水平,确定了我们就可以确定他的接受域。那么接受域以外,就是他的拒绝域。以正态分布图为例,
最后一步计算检验统计量、计算P值。检验统计量我们可以得到2.23(公式中x为样本均值),于是我们就可以确定P值了。P值像我们上面讲到的定义,它是比这个结果更差的概率。现在我们的统计量落入了2.23这个位置。则比他更差的就是比它更大的这部分。我们把从这个点开始到正无穷大计算,他的累积概率得到他的概率值是0.013,这个0.013就是单边检验的P值。如果我们不仅要算比他大的,还要考虑以均值为对称的位置的话,就像这里就会得到一个双边检验的P值,即是单边检验P值的 2 倍,即0.026。这个双边检验P值一般比单边要常用的多。我们前面假定的0.05的显著性水平也指的是双边的情况。所以我们就算双边检验的情况,那P值我们就取双边检验的P值,即0.026。
由于这个0.026 < 0.05,它落入了拒绝域,那么这就意味着我们之前的假设
(3)python实现
这里以正态分布的假设检验为例。
先生成标准正态分布
import numpy as np
import scipy.stats as ss
norm_dist = ss.norm.rvs(size=20)
norm_dist输出

检测是否为正态分布
ss.normaltest(norm_dist) 输出

注意:normaltest检验是基于偏态和峰度的检验法,而非
另外,可以用QQ图检验已知分布是否符合正态分布:
原理是已知分布找到分位数,由对应的分位数找到正态分布(默认分布)的分位数。
QQ图横轴是正态分布的分位数的值,而纵轴是已知分布的分位数,所以得到一个曲线或散点图。这个图如果正对着x轴和y轴的平分线,和这条平分线是重合的。那么它就是符合正态分布的。
输入
from statsmodels.graphics.api import qqplot
import matplotlib.pyplot as plt
plt.show(qqplot(ss.norm.rvs(size=100)))输出

因图像是一条直线,所以已知分布是正态分布。
2. 卡方检验
(1)概念
假设检验的方法有很多,这些方法的差别一般取决于检验统计量的选取上。比如说,第1部分洗衣粉的例子进行的是

还有的比如说卡方检验,t分布检验,F检验等等。它们流程上是一样的,只是检验时使用的统计量不同,应用的场景也有可能有些差异。例如t 分布检验常用来比较两组样本分布的均值是不是有差异性,像临床医疗上药物有没有效果,就可以用t分布检验的方法来进行实验。F检验常用在方差分析,这在第3部分将会涉及。
下面举一个卡方检验的例子。我们想看一下化妆这个跟性别有没有关系,于是经过调查得到了这样的一个表。如下图所示

我们确定原假设化妆与性别无关,即所有的人群中,化妆与不化妆的人群中,男女分布都是一致的。然后假设检验量就是卡方分布的假设检验量。就像上图所示的公式一样。
这里
比如在这张表中,男士化妆的实际人数是15,而他的理论分布应该是55,因为一共有100人。而男女假设是分布一致的,是都是55。因为男士有100,女士也有100。
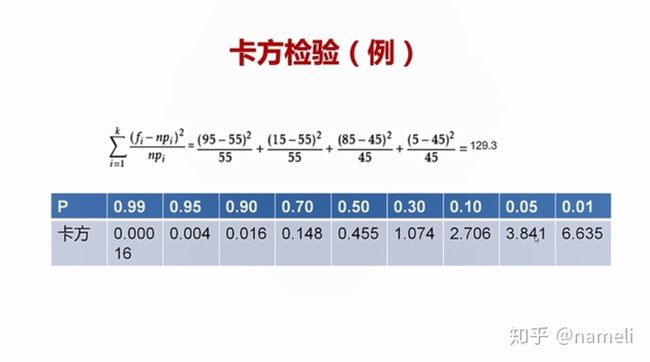
我们把这些值都计算出来,得到129.3,这个值就是卡方值,上图有卡方值和p值的对应表。我们来看,如果p取0.05的话,那么卡方值应该是不大于3.481。而这里卡方值算得129.3,明显的大于了3.841,所以我们可以拒绝原假设。得到的结论是性别和化妆与否是有比较强的关系,即原假设性别与化妆与否没有关系就可以被拒绝掉。使用卡方检验进行这样的分析的方法,也叫做四格表检验法,常用来检验两个因素之间有没有比较强的联系。
(2)python实现
以前面的化妆品案例来实施卡方检验

输入
ss.chi2_contingency([[15,95],[85,5]]) 输出

上述结果解读
126.08是检验统计量;2.9521414005078985e-29是P值;1是自由度;array([[55., 55.], [45., 45.]]是理论分布。
下面举一个 独立
注:独立 t 检验可以参阅资料
小于:两独立样本t检验zhuanlan.zhihu.com
这里检验两个标准正态分布的均值有无差异
ss.ttest_ind(ss.norm.rvs(size=10),ss.norm.rvs(size=20)) #原假设无差异输出

假如以0.05 作为显著性水平,则 P值 = 0.75表明不拒绝原假设。从而在0.05的显著性水平下,两个正态分布的均值无差异。
3. 方差检验
(1)概念
前面的例子中,我们只研究了一个样本或者两个样本的研究方法,那么如何有检验多个样本两两之间是不是有差异呢?
一个思路就是用按卡方检验例子中提到的方法进行两两分析,但这样对比次数可能就会比较大。如果数据样本数量比较多,就比较耗时耗力。还有一种方法就是我们要接触到的方差检验方法,因为他用到了F分布,所以也叫F检验。
我们先来看例子:

我们想看一下三组电池寿命的均值是不是有差别?这里就可以使用方差检验方法。此处有两个参数需要重点关注:我们把数据分为m组,一共n个采样。拿这个例子来说,m = 3,而
n = 15,这里的 n 是所有数据量的总和。
下面先来介绍三个公式:

第一个SST,总变差平方和,是用每个数据的数据值减去整体样本的均值,也就是刚才所说的 15 个数据的均值,然后再取平方和。注意这里的
第二个SSM,平均平方和,是指每组的均值减去总体的均值的平方和。因为指的是每个组与整体均值的平方和。所以也叫组间平方和。
最后一个SSE,残差平方和,是每一个数减去他所属的组的平均值的平方和。(一般情况下带有SS指的都是平方和)。因为它是指每个组内部的平方和,所以叫组内平方和。
那么方差检验的检验统计量是什么呢?公式如下图所示,它满足自由度为(m -1, n - m)的F分布。这样就可以进行方差检验了。

具体计算过程如下图所示。
其中,第一步是确定他的原假设,也就是三组电池的均值是一定的,它是没有差别的。
第二步确定检验统计量呢,我们也可以确定了,
第三步,把F的显著性水平设成0.05。
第四步,计算检验统计量F值和P值。我们可以计算每个组的均值分别是44.2、30和42.6。总体均值是38.93,然后可以得到SSM、SSE的值,以及F值。进一步查表得到P值是0.00027,因为小于0.05,所以可以拒绝原假设,即认为他们三者的均值是有差异的,而并不是没有差异。

(2)python 实现
以上述电池寿命的案例实施方差检验
ss.f_oneway([49, 50, 39, 40, 43],[28, 32, 30, 26, 34],[38, 40, 45, 42, 48])输出

由于P值=0.00027 < 0.05 , 所以拒绝原假设,表明三组电池的均值在0.05的显著性水平下有差异。
4 相关系数
相关系数是衡量两组数据或者说两组样本的分布趋势、变化趋势一致性程度的因子。
相关系数有正相关、负相关、不相关之分:
(1)相关系数越大,越接近于1,二者变化趋势越正向同步。也就是说,一个变大,一个也变大,一个变小,另一个也跟着变小。
(2)相关系数越小,越接近于-1,二者的变化趋势越反向同步。也就是说,一个数据变大,另外一个数据就会变小。
(3)相关系数趋近于0时,则可以认为二者没有相关关系.。
常用的相关系数有两种,皮尔逊相关系数和斯皮尔曼相关系数。
(1)皮尔逊(Pearson)相关系数
我们先来介绍一下皮尔逊(Pearson)相关系数,它的形式如下:

皮尔逊相关系数的分子是两组数的协方差,而分母呢是两组数据的标准差的极。标准差的极,相当于一个归一化因子。这里协方差的定义展开就像右边的展开式一样,两组数据各减去他的均值,再进行相乘取他的期望值那么简单。
举两个小例子
(1)X = (1, 0,1),Y =(2,0,2) ,则皮尔逊相关系数就是1。此时x变小,y也变小;x变大,y也变大。它们变化趋势是一样的。
(2)X = (1,-3,1),Y =(-2,6,-2)。则皮尔逊相关系数就是-1。意味着X变小的时候,Y是变大了,而变大幅度也是一致的。X变大的时候,Y又是变小的,并且缩小的幅度也是一致的。
(2)斯皮尔曼相关系数
下面来看第二个相关系数,斯皮尔曼相关系数。
斯皮尔曼相关系数表示如下:

这里的 n 指的是每组数据的数量;d指的是两组数据排名后的名次差。
如图中例子,X = (6,11,8),Y =(7,4,3)。计算他的名次可以得到X的名次(1,3,2),也就是从小到大排列。6排第一的,11是排第三、8是排第二。同理Y的排名为(3,2,1)。然后取X和Y的名次差:1减3等于-2,3减2等于1,2减1等于1,再带入公式求得spearman相关系数是-0.5。
斯皮尔曼相关系数只跟名次差有关,跟具体的数值关系不是那么大。这点和皮尔逊相关系数是不一样的。比如说我们把X的 6 换成一个更小的数,那么他们斯皮尔曼相关系数也不变,还是-0.5。比如说我们把外里面的7换成100或者是更大的数,那么也不会影响到他的斯皮尔曼相关系数,所以斯皮尔曼相关系数运用于相对比较的情况下比较适合。
(注:原则上无法准确定义顺序变量各类别之间的距离,导致计算出来的相关系数不是变量间的关联性的真实表示。因此,建议对顺序变量使用斯皮尔曼相关系数。)
(3)python 实现
求 Series 间相关系数
import pandas as pd
s1 = pd.Series([0.1, 0.2, 1.1, 2.4, 1.3, 0.3, 0.5])
s2 = pd.Series([0.5, 0.4, 1.2, 2.5, 1.1, 0.7, 0.1])
s1.corr(s2) #默认是求皮尔逊相关系数输出

求斯皮尔曼相关系数
s1.corr(s2, method='spearman')输出

求DataFrame列与列之间的相关系数
df = pd.DataFrame([s1, s2])
df.T.corr()输出

5 线性回归
(1)概念
什么是回归呢?回归是指确定两种或两种以上变量间相互依赖的定量关系的一种统计分析方法。那么,如果所谓的因变量与自变量的这种依赖关系是线性的关系,则称之为线性回归。
线性回归最常见的解法,就是最小二乘法。最小二乘法的本质是最小化误差的平方的方法,它的具体公式如下:

回归方程如上式。通过这样的公式求出因子 b 和截距 a 就可以得到回归方程。
线性回归的效果的判定主要有以下两种度量:一个是决定系数,另外一个是残差不相关决定系数。如下图所示,
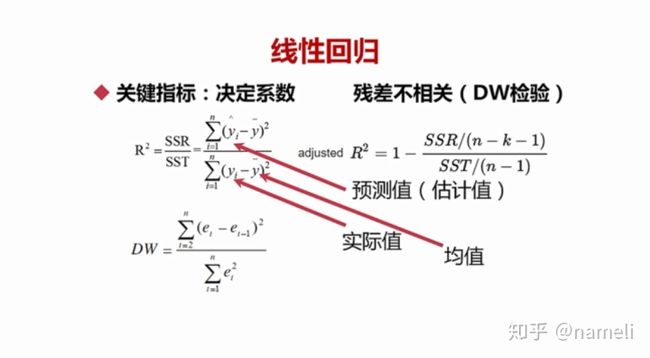
左边的决定系数
决定系数越接近于1,说明回归效果是越好。越接近于0,回归效果就越差。
对于多元线性回归的情况来说,采用了一种叫做校正式的决定系数(adjusted
还有一个检验指标,就是
(2)python 实现
输入
from sklearn.linear_model import LinearRegression
import numpy as np
x = np.arange(10).astype(np.float).reshape((10,1))
y = x*3 + 4 + np.random.random((10,1))
reg = LinearRegression()
res = reg.fit(x,y)
y_pred = reg.predict(x)
y_pred输出

对应的系数:
reg.coef_ #系数输出

对应的截距项:
reg.intercept_ #截距输出

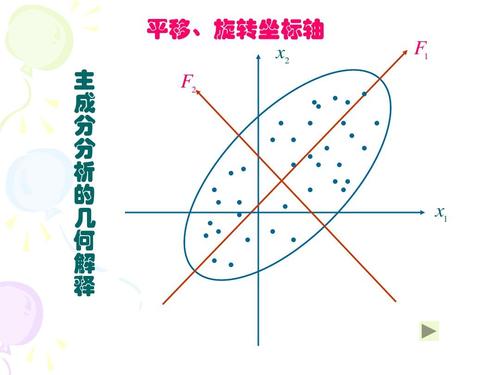
6 主成分分析PCA
(1)概念
我们在学习矩阵理论的时候,常把一个数据表看做一个空间,那么这个矩阵的行对应每个数据对象的各个属性,矩阵的列就代表一个属性的不同内容。我们也常把每个属性当做整个这张表构成空间的一个维度,每行所代表的实体代表的就是一个向量,用这个表的内容代表的就是一个巨大的空间。以下图为例,

这张表里有四个属性,每个属性都是一个维度,每一行的数据都包含四个维度,构成一个向量。
虽然每个向量有四个维度,但维度也是有主要次要之分的。比如维度A或者说是属性A,它就是一个比较次要的维度,因为通过它我们不能把几个对象区分开来。而维度B他的区分度就比较大,就可以认为是个明显的维度,即是个主要的成分。
更为灵活的可以通过正交变换将一组可能存在相关性的变量转化为一组线性不相关的变量。在这个转化后的新的维度上,有的尺度被拉伸,有着尺度被收缩,我们取最能代表转化后维度的成分及尺度比较大的维度,就是主成分。那么相应的分析就是我们这里讲的主成分分析。那么这个变换过程就是PCA变换。
PCA变换的一般过程如下图:

第一步,求特征的协方差矩阵;
第二步,求协方差矩阵的特征值和特征向量;
第三步,将特征值按照从大到小的顺序排序,选择其中最大的k个;
第四步,将样本点投影到选取的特征向量上。
我们通过例子来说明主成分分析的一般方法。下图这张表里有两个属性,而每一条数据所对应的就有两个维度,它们所构成的空间也就是一个我们所谓的二维空间。

图中PCA变换的详细过程如下:
第一步,求它的协方差矩阵,就是x减去它的均值,y也减去它的均值,然后对它们求期望,得到一个协方差矩阵
第二步,求
注意这里矩阵相乘的形式是x减去它的平均值,同时y再减去它的平均值和这个向量(1.28对应的特征向量
用主成分分析最重要的一个作用就是降维,有的时候,我们会得到一个数据量,他的维度特别多,比如说它可能有几百个维度或者几千个维度。那么有些维度就是没有必要的,所以我们这个时候就需要把它最主要的成分提出来。通过主成分分析,我们以尽可能少的失真减少了比较大的工作量,使得后续的分析更加的快速简单。
除了基本的pca方法以外呢,奇异值分解也是一种常用的线性降维与成分提取的思路。注意奇异值分解也可以认为是一种pca的方法。
我们简单的介绍一下,奇异值分解是将矩阵分解成如下形式:

中间
通过调整奇异值矩阵的奇异值维度,比如取最大的一些奇异值,去掉一些较小的奇异值,同时缩小
奇异值分解的方法涉及到矩阵理论的一些知识,涉及到的理论还是比较深的,比如说它的推导等等,这里就不做介绍了,感兴趣的朋友可以查找相关资料,自行学习。
(2)python 实现
数据采用例子中的 Data
from sklearn.decomposition import PCA
data=np.array([np.array([2.5, 0.5, 2.2, 1.9, 3.1, 2.3, 2, 1, 1.5, 1.1]),
np.array([2.4, 0.7, 2.9, 2.2, 3, 2.7, 1.6, 1.1, 1.6, 0.9])]).T
lower_dim = PCA(n_components=1) #降成一维
lower_dim.fit(data)
lower_dim.explained_variance_ratio_ #降维后的信息量96%输出

降维后的数值:
lower_dim.fit_transform(data) #sklearn这是用奇异值分解的方法,得到降维后的数值输出:

7 交叉分析
(1)概念
我们得到如下一张数据表,需要进行分析的时候最直观的。

我们有两个分析的切入点,一个是从列的角度进行分析,每个属性的特点并进行归纳和总结;另一个从行的角度进行分析,也就是从案例的角度进行分析,尤其当数据有了标注的时候,以标注为关注点,案例分析越多,也就越接近于数据整体的质量。
这两种分析方法也是最为浅层次的分析,如果仅仅进行这两方面的分析,有时并不能得到最为真实、最为客观的结论。这是因为直接使用这种纵向分析或横向分析忽略了数据间属性间的关联性,即很可能有信息的失真,所以我们需要分析属性和属性间的关系,进而得到更多的能反映数据内涵的信息。交叉分析就是一种重要的分析属性和属性之间关系的方法。
交叉分析的含义比较广,所涉及到的分析方法也比较多。比如,我们可以任意取两列,也就是两个属性,根据我们所学到的假设检验的方法来判断他们之间是否有联系。也可以直接以一个或几个属性为行,另一个或几个属性为列做成一张交叉表(也叫透视表)。通过关注这张新生成的表的性质,可以更直观的分析两个属性或者几个属性之间的关系。
(2)python实现
首先检验两个部门的离职率是否有显著差异:
import pandas as pd
import numpy as np
import scipy.stats as ss
import matplotlib as plt
df = pd.read_csv(r'D:Documentspython_documentsmu_2_HRHR.csv')
# 去除异常值
df = df.dropna(axis=0,how='any')
df = df[df['last_evaluation']<=1][df["salary"]!='nme'][df['department']!='sale']
dp_indices = df.groupby(by='department').indices #按部门分组,并得到其索引
sales_values = df['left'].iloc[dp_indices['sales']].values #取出sales 部门的离职情况
technical_values = df['left'].iloc[dp_indices['technical']].values #取出technical 部门的离职情况
print(ss.ttest_ind(sales_values, technical_values)) #打印t检验统计量和P值,检验两个部门的离职率是否有差异输出:
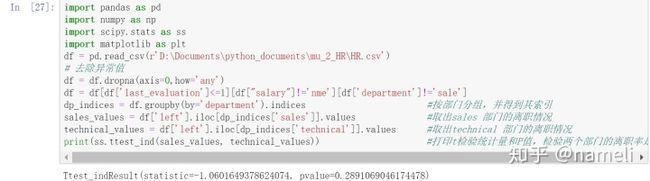
由于 P值 = 0.289 > 0.05,所以认为部门“sales”和“technical”的离职率的均值是没有显著差异的。
再检验所有部门离职率两两之间的差异性:
import seaborn as sns
import scipy.stats as ss
dp_keys = list(dp_indices.keys())
dp_t_mat = np.zeros([len(dp_keys), len(dp_keys)])
for i in range(len(dp_keys)):
for j in range(len(dp_keys)):
p_value = ss.ttest_ind(df['left'].iloc[dp_indices[dp_keys[i]]].values,
df['left'].iloc[dp_indices[dp_keys[j]]].values)[1]
if p_value < 0.05:
dp_t_mat[i][j] = -1 #颜色越深,说明部门之间的离职率有显著差异(拒绝原假设)
else:
dp_t_mat[i][j] = p_value
sns.heatmap(dp_t_mat, xticklabels=dp_keys, yticklabels=dp_keys) 输出:

热力图中黑色部分说明是两个部门的离职率均值是有显著差异的,其他颜色则说明两个部门的离职率的均值没有显著差异。
下面展示另一种交叉分析法:透视表
import numpy as np
piv_tb = pd.pivot_table(df, values='left', index=['salary', 'promotion_last_5years'],
columns=['Work_accident'], aggfunc=np.mean)
piv_tb输出:
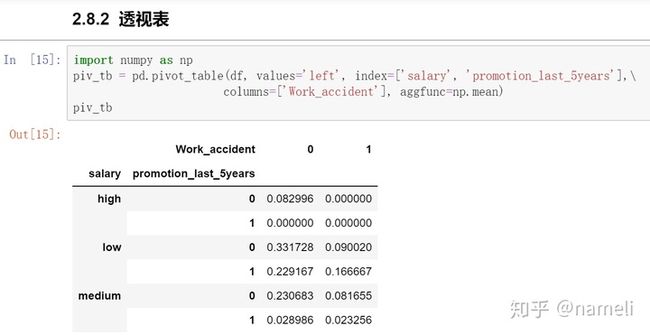
当salary = low, promotion_last_5years = 0,Work_accident = 0时,离职率“left”最高为0.33,需要重点关注。
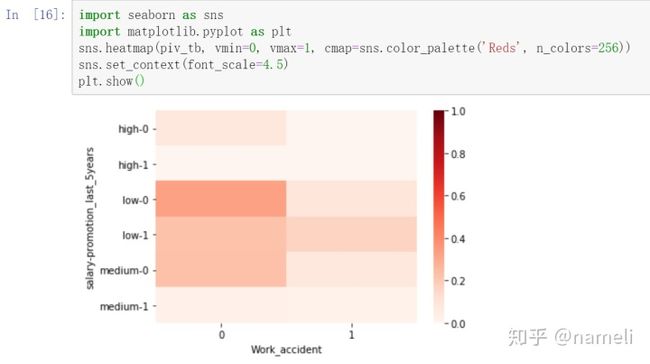
可以将上述透视表以热力图的形式显示出来:
import seaborn as sns
import matplotlib.pyplot as plt
sns.heatmap(piv_tb, vmin=0, vmax=1, cmap=sns.color_palette('Reds', n_colors=256))
sns.set_context(font_scale=4.5)
plt.show()输出:
8 分组分析
(1)概念
分组分析有两种不同的含义:
第一种含义,顾名思义,就是将数据进行分组后再进行分析比较;
第二种含义,就是根据数据的特征,将数据进行切分,分成不同的组,使得组内成员尽可能靠拢,组间的成员尽可能远离。那么在这种含义下,如果我们指定了每一条数据的分组,来计算当未知分组的数据出现的时候,更精确的判断它是哪个分组,这个过程我们可以叫做分类。那如果我们不知道分组,仅是想让数据尽可能的物以类聚,我们可以把这个过程叫做聚类。分类和聚类都是机器学习或者数据建模的主要内容。
我们先讲第一种含义的分组分析,即将数据进行分组后进行分析。分组分析一般要结合其他分析方法进行配合使用。从这个角度来讲,分组分析更像是一种辅助手段,而不是一种目的性的分析。数据分组可以更直观的发现数据中属性的差异。分组分析最常用到的具体手段就是钻取。

钻取就是改变数据维度的层次,变换分析粒度的过程。根据钻取方向的不同,可以分为向下钻取和向上钻取。向下钻取就是展开数据查看数据细节的过程。比如一门考试,每个班都是一个分组,假如我们知道每个班的平均成绩,如果进一步想知道每个班里男生和女生分别的平均成绩是多少,这个过程就是向下钻取的过程。
那么向上钻取就是汇总分组数据的过程,比如我们知道每个人的分数,汇总成每个班的平均分就是向上钻取的过程;再比如我们知道一个品牌汽车每天的销售额,然后汇总成每个月的销售额,以月为单位进行分析,也是向上钻取的过程。
离散属性的分组是比较容易的,而连续属性的分组在分组前需要进行离散化。当然,在进行连续属性的离散化之前,我们需要先看一下数据分布,是不是有明显的可以区分的标志,比如将数据从小到大排列后有没有一个明显的分隔或者明显的拐点。如果有,可以直接使用,这里说到了分隔实际上就是相邻两个数据的差,我们可以认为他是一阶差分,刚才说到的拐点就是二阶差分。

另外一个思路是连续属性的分组要尽可能满足相同的分组比较聚拢,不同的分组比较分离的特点,所以我们可以用聚类的方法进行连续属性的分组。比如,我们可以用 kmeans 方法来进行指定分组数目的连续属性分组。如果考虑标注的话,我们也可以结合不纯度的检验指标基尼系数来进行连续数据的离散化分组。
下面说明衡量不纯度的指标基尼系数的计算。
基尼系数的定义如下:这里
比如下面两幅图中,我们想衡量 X 相对于 Y 来讲是不是具有很好的区分度,我们就可以带入第二幅图的公式,然后就可求得基尼系数。在这里,


那么连续值的基尼系数印尼系数怎么进行计算呢?
如下图,我们需要先将表按照连续值的大小进行排序,然后相邻两两之间划定界线分别确定分组值。比如这里,我们确定

根据不纯度进行分组使用最多的,是分类模型中决策树算法中的CART算法。
(2)python实现
向下根据hue = “department”钻取
import pandas as pd
import seaborn as sns
import matplotlib.pyplot as plt
plt.rcParams['figure.figsize'] = (10.0, 6.0) #调整图片大小
sns.barplot(x='salary', y='left', hue='department', data=df)输出:

9 相关分析
(1)概念
相关分析是衡量两组数据或者说两组样本分布趋势或者变化趋势大小的分析方法。
相关分析最常用的是之前说明的皮尔逊相关系数和斯皮尔曼相关系数。用相关系数直接衡量相关性的大小最为直接和方便。
皮尔逊相关系数和斯皮尔曼相关系数适用于衡量连续值的相关性。离散属性的相关性如何衡量?
这是一个问题,我们来拆分一下,先分析一个特例。比如有个二类离散属性的相关性问题,二类离散属性,也就说它只有两个分类,一个是0,一个是1,比如像是否的判断,有或者没有的判断之类的属性值,这样二类属性就被编码成 0 和 1。二类属性是可以用皮尔逊相关系数来直接衡量相关性的大小的。
二类属性和连续值属性的相关性,我们可以使用不纯度来进行解决和计算。当然,我们也可以直接把二类属性进行相关性的计算,但这样的话可能会有些失真。
多类离散属性的相关系数会有些麻烦。如果多类离散属性都是定序数据的话,比如像低、中、高之类的,我们就直接可以编码成0、1、2这些值进行皮尔逊相关系数的计算。注意的是,这样也是有失真的。另外更为一般的,我们可以使用熵这个定义进行离散属性的相关性系数的计算,我们先来介绍一下什么是熵:
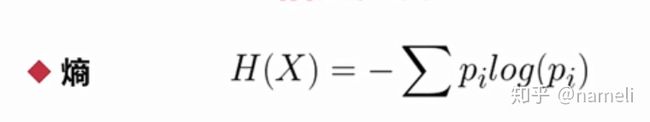
熵是用来衡量不确定性的一个值,那么他的定义如上图公式所示,它把一个属性的每一个值出现的概率,乘以log(概率),然后把所有的这些值的这种转换加起来得到他的熵。
熵越接近于零,那么意味着看到不确定性越小。这个log值,他的底数就决定了熵的单位,如果它的底数为二的话,那么熵的单位就是我们比较熟悉的比特。
我们列几个例子:
比如说有一个属性,他的分布是0和1,也就是说他有两种备选值,但他只出现了1这一种值。则根据熵这个公式算出来的就是0。也就是说这个属性就已经可以确定了,它没有什么信息量;
那我们再来看,比如有一个分布有两种备选值。这两种备选值,各占50%。于是计算它的熵最终得到1。也就是说,如果他的分布是(0.5, 0.5)的话,那么,他的熵就是1比特;
更为一般的,如果样本都属于一个类别,那么,他的伤就是0;反而如果样本的类别越多,而且分布越均匀,那么他的信息熵就越大。
还有个概念条件熵。条件熵的定义如下:

即在
另一个比较重要的概念是互信息。
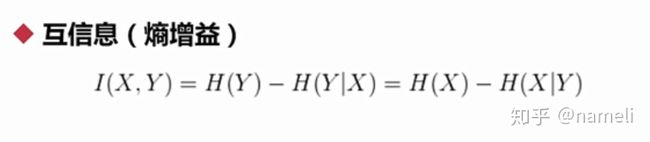
互信息是有实际意义的,
条件熵相对于原来的熵一定是减少的。所以互信息的含义,其实就是这个过程中减少的熵。
另外有个性质
为了解决这个问题,我们可以定义这么一个值,熵的增益率:

那么
但直接只用熵的增益率去衡量相关性的话,也是不妥的。这是因为熵的增益率是不对称的,也就是说

我们把分母换成
注意:
在实际的使用场景中,计算哪些因子的相关性,是根据具体的业务需求来的。比如,我们想了解公司离职与其它各个因子的相关关系,就需要把离职属性与各个属性都拿出来,分别根据离散或者连续的特性,进行计算。如果对工资和入司时长间的关系有兴趣,也可以拿这两个出来进行计算。在公司,在一个分析型业务中,计算哪些变量之间的关系,一般由产品经理或者其它需求方提出。当然,也可以自己把所有属性两两之间根据离散或者连续进行相关对比,一并输出,也是Ok的。
连续变量和离散变量之间的相关性考量,可以有以下几种思路:一是把连续值离散化,或者把离散值连续化,再进行对比;二是根据离散值对数据集进行分群,然后对各个群进行卡方分析、方差分析等假设检验类的分析,得到它们的差异是否显著,如果差异较大,说明离散值与连续值有较大的相关联系。
(2)python 实现
求熵:
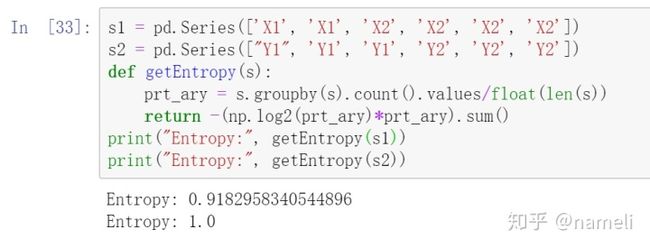
s1 = pd.Series(['X1', 'X1', 'X2', 'X2', 'X2', 'X2'])
s2 = pd.Series(["Y1", 'Y1', 'Y1', 'Y2', 'Y2', 'Y2'])
def getEntropy(s):
prt_ary = s.groupby(s).count().values/float(len(s))
return -(np.log2(prt_ary)*prt_ary).sum()
print("Entropy:", getEntropy(s1))
print("Entropy:", getEntropy(s2))输出:
条件熵:
def getCondEntropy(s1, s2):
d = dict() #结构体
for i in list(range(len(s1))):
d[s1[i]] = d.get(s1[i],[]) + [s2[i]] #结构体,key是s1的值
#value是一个数组,数组记录了s1值下s2的分布
return sum([getEntropy(d[k])* len(d[k])/float(len(s1)) for k in d])
print('getCondEntropy', getCondEntropy(s1, s2))输出:

互信息(熵增益):
def getEntropyGain(s1, s2):
return getEntropy(s2) - getCondEntropy(s1, s2)
print('EntropyGain', getEntropyGain(s1, s2))输出:

熵增益率:
def getEntropyGainRatio(s1, s2):
return getEntropyGain(s1, s2)/getEntropy(s2)
print('EntropyGainRatio', getEntropyGainRatio(s1, s2))输出:

衡量离散属性的相关性:
import math
def getDiscreteCorr(s1, s2):
return getEntropyGain(s1, s2)/math.sqrt(getEntropy(s1)*getEntropy(s2))
print('DiscreteCorr', getDiscreteCorr(s1, s2))输出:

Gini 系数:
def getProbSS(s):
if not isinstance(s, pd.core.series.Series):
s = pd.Series(s)
prt_ary = s.groupby(s).count().values/float(len(s))
return sum(prt_ary**2)
def getGini(s1, s2):
d = dict() #结构体
for i in list(range(len(s1))):
d[s1[i]] = d.get(s1[i],[]) + [s2[i]] #结构体,key是s1的值
#value是一个数组,数组记录了s1值下s2的分布
return 1-sum([getProbSS(d[k])*len(d[k])/float(len(s1)) for k in d])
print('Gini', getGini(s2, s1))输出:

10 因子分析
(1)概念
因子分析就是从多个属性变量中分析共性相关因子的方法。
因子分析是个比较综合的分析方法,它几乎用到了我们这这里多因子探索分析所有的知识点。
仔细一点讲,因子分析可以分为探索性因子分析和验证性因子分析。探索性因子分析是指通过协方差矩阵、相关性矩阵等指标分析多元属性变量的本质结构,并可以进行转化、降维等操作得到数据空间中或者影响目标属性的最主要因子。我们前面讲到的主成分分析法就是一种比较典型的探索性因子分析方法。
验证性因子分析是验证一个因子与我们关注的属性之间是否有关联,有什么样的关联,是不是符合我们的预期等等。验证性因子分析常用到我们之前说的假设检验、相关分析、回归分析等等各种理论知识。

我们来举个例子来说明这两种分析。比如说我们得到了一张数据表,或者得到了非常多的属性。有的时候,我们也会得到一个我们关注的目标属性或者标注。比如我们通过问卷调查的方式,可以得到用户对某产品是否满意,还有像年龄、性别等基本信息,以及各种生活习惯等个性的信息。如下图,

如果我们关注用户对产品的满意情况,我们可以通过主成分分析,把除满意情况外全部的因子进行主成分降维。然后直接分析降维后因子与满意情况,进行对比分析,就是探索性因子分析的一种方法。或者我们也可以不转化,直接来看相关矩阵,看哪个其他属性和我们关注的属性都比较强的关系,这也是一种探索性因子分析的思路。
如果我们换个角度,我们想看一下某个具体属性与满意度的关系,我们就会去验证这个属性和满意度是不是有关系,得到像相关性、一致性之类的指标。或者我们直观上可以猜测某几个属性和满意度有关系,也可以用回归方法去拟合这几个属性与满意度的关联,根据误差大小来应验我们的假设是否准确,这些都是验证性因子分析的方法。
(2)python 实现
去除离散变量后,主成分分析:
from sklearn.decomposition import PCA
my_pca = PCA(n_components=7)
lower_mat = my_pca.fit_transform(df.drop(labels=['salary', 'department', 'left'], axis=1)) #去除离散值
print("Ratio:", my_pca.explained_variance_ratio_)输出各个主成分重要性所占比例:

查看以上主成分转换后的相关图:
import seaborn as sns
sns.heatmap(pd.DataFrame(lower_mat).corr(), vmin=-1, vmax=1, cmap=sns.color_palette("RdBu", n_colors=128))输出:

主成分转换后,各个主成分之间不相关(相关性接近于0),所以我们会看到一片灰。
11. 小结
以上提到了交叉分析、分组分析、相关分析和因子分析这些分析,大多为多个属性之间的复合分析,涉及到的概念和数据类型也比较多,可以参考以下这张表:

实际工作中数据分析的范围应该尽可能广,比如交叉分析我们应该把所有可交叉的属性,都尝试分析一遍,或者把大部分属性的组合都分析一遍。同样像相关分析,我们应该根据数据类型进行区分,多尝试几种方法进行分析。当然,这样的工作量可能会很大,但数据分析工作就是这样,在看似繁琐的工作中,找到数据真正的价值。