背景问题
隐私会通过泄露的用户位置信息被推测出来。
以前研究的不足
以前的研究多采用真实位置隐匿或扰动,但是忽略了攻击者可能具备关于所采取的隐私保护方法的相关知识(加了保护方法还是有比较大的危险被反算出位置隐私)。
本文贡献
1. 提出一个可以让设计者找到最优LPPM(location-privacy preserving mechanism)的方法论,针对用户服务质量约束和攻击者有关于真是user位置的相关知识、已经实现最优推测算法的情况下,并实现最大的位置失真。
原理
隐私保护措施直接在用户机上实现。
总区域离散分为M块:
一个user u 在时间 t 的真实事件:
user u 在时间 t 位置 r 接入LBS的概率分布满足:
位置隐私保护机理:
将真实位置r 转换为 r' (r' 属于 R' ,一般R' 是 R 的powerset,此处取R' = R),再发送给LBS(location based server)。
被LBS感知到的user位置记为:
对每个真实事件 a(t) =
Q:两次user接入LBS是条件独立的,接入时间越长俩次位置越独立?
服务质量

服务质量需要满足:
位置隐私
攻击者的目标是通过扰动位置 o(t)= < t, r' >推测user实际位置 a(t)= < t, r >,在有背景知识 user profile ψ(.)的情况下。
攻击结果为下列概率密度函数h(.):
此处,本文假设攻击者知道时间背后user的身份。
用户位置隐私程度被量化为攻击者攻击错误的期望值:

问题声明
条件:
1. 最大容忍服务质量 Qloss 通过dp(.)计算;
2. 攻击者知道user profile,r' ,知道 f(.),已经算好了 最优 h(.)。
目标: 找最优 f(.)最大化 Privacy。
博弈
假设攻击者已有知识下,user 找一个有最优 Privacy 的问题,是一个 和为0的 Bayesian Stackelberg 博弈。
在Stackelberg博弈中,leader - user 先选一个LPPM 然后提交;follower - 攻击者 随后,在知道LPPM的情况下,估算user位置。
之所以是 Bayesian 博弈,是因为攻击者有关于user位置的不完全信息,然后靠自己的推测来play。
user 的 Privacy 刚好就是攻击者攻击的错误率,所以是zero-sum博弈。
具体定义本问题的博弈:
0. 自然地根据 ψ(.)选一个位置 r;
1. user 通过LPPM f(r'|r)(满足服务质量条件)选一个 r';
2. 在知道 f(r'|r)、ψ(.)的情况下(不知道实际位置r),攻击者通过h(r尖|r')选出推测位置r尖;
3. 攻击者付一个数 dp(r尖,r)给user(这个数既是攻击错误值,也是隐私保护值)。
上述步骤user、攻击者双方都清楚,双方都想最大化自己的收益。
解决办法
构造2个线性规划,条件为 ψ(.)、dp(.)、dq(.),计算最优f(.)和h(.)。
攻击者可构造后验分布:

攻击者选 r尖 使:

当有多个最优 r尖 时,上式写做:
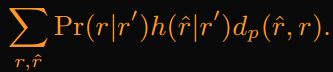
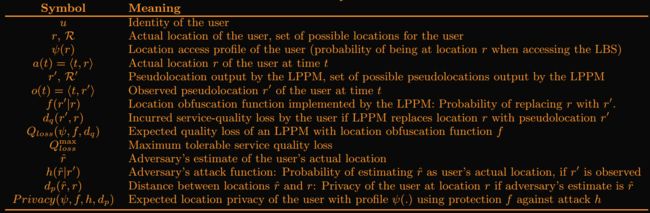
user非条件隐私期望为:

为方便书写:
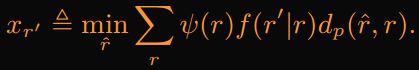
则user非条件隐私期望为:

Q:最小化操作会使此问题变为非线性?
(13)可转化为:

在(13)的情况下最大化(14),与在(15)的情况下最大化(14)等价。
需要选择 f(r′ | r), xr′ , ∀r, r′,user的线性规划如下:

对于攻击者的线性规划和user构造类似,用户隐私条件期望:

user选一个 r' 最大化(21),因此最大user条件期望:
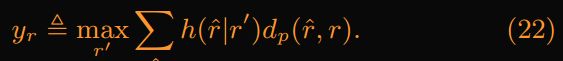
非条件user隐私:

攻击者旨在通过选 h(r|r')最小化(23),与前面相似(22)转化为:

通过选 h(r尖 | r′), yr,∀r , r′, r尖,和大于等于0的z,攻击者的线性规划为:
