CNN典型模型及pytorch实现 —— GoogleNet
目录
Inception 结构
1*1的卷积
GoogleNet 结构
GoogleNet_Model代码(Pytorch)
14年的冠军 model;
GoogleNet(把网络结构增加到了22层)证明了用更多的卷积、更深的层次,可以得到更好的效果;
但是纯粹增大网络也有一些缺点:
- 参数太多,容易过拟合;
- 网络越大,计算的复杂度越大;
- 网络越深,越容易出现梯度消失或梯度弥散;
为了在增加网络深度和宽度的同时减少参数,提出了 Inception;
GoogleNet 和 AlexNet 结构的区别在于中间有好几个 Inception 结构;
GoogleNet 参数总量并不大,但是计算次数非常多;
Inception 结构(有多个版本,以下为v1版本):
把输入一分为四,做不同大小的卷积(多尺度卷积),再聚合;
思想来源于1*1的卷积 + 激活函数;
v1(原始版本):
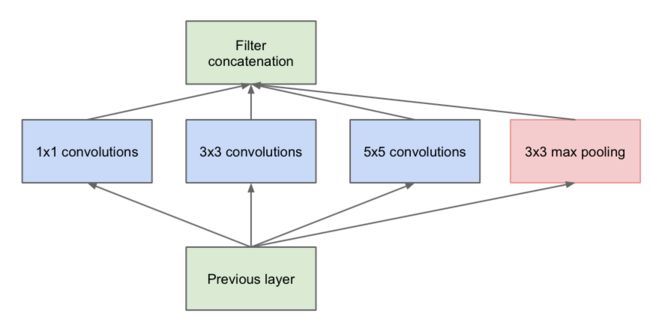
将1*1、3*3、5*5的卷积层和3*3的池化层堆叠在一起,能提取输入的每个细节,5*5能覆盖大部分的接受层的输入,实际上在每个卷积层后还有RELU激活函数(图中未画出),增加网络的非线性特征;
v1存在的问题:所有的卷积都是在上一层的输出上做的,5*5的卷积核计算量会非常大,造成特征图的厚度非常大,导致参数非常多;
经过不同的卷积和池化后,得到的输出大小、以及将四种不同类型,但大小相同的特征图堆叠起来,新的特征图的大小如下图:
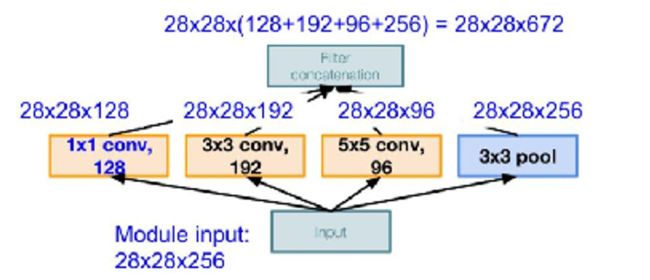
参数数量如下:
【1*1 conv,128】28*28*128*1*1*256
【3*3 conv,192】28*28*192*3*3*256
【5*5 conv,96】28*28*96*5*5*256
参数总量共854M;
为了解决v1计算量很大,占用太多计算资源的问题,又提出一种新的结构:加入了1*1的卷积进行数据的降维,结构图如下:

每层特征相应图的大小及通道数如下图所示:
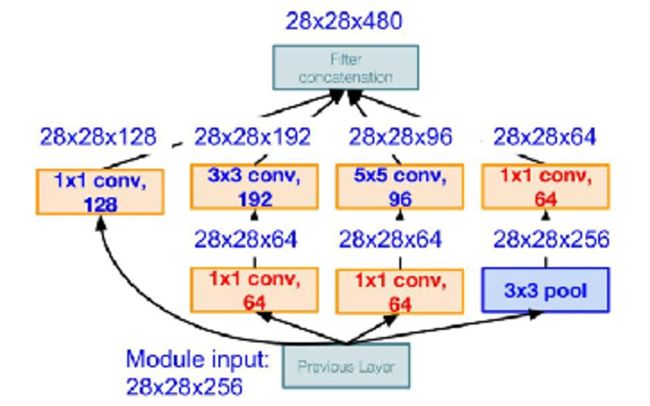
参数数量如下:
【1*1 conv,64】28*28*64*1*1*256
【1*1 conv,64】28*28*64*1*1*256
【1*1 conv,128】28*28*128*1*1*256
【3*3 conv,192】28*28*192*3*3*64
【5*5 conv,96】28*28*96*5*5*64
【1*1 conv,64】28*28*64*1*1*256
参数总量共358M;
可以看出,加了1*1的卷积后,参数量大大减少了(由原来的 854M 减为 358M);
Inception 结构的三个步骤:
- 通过3*3的池化和三种不同尺度的卷积核,以四种方式对输入的响应图进行特征提取;
- 为降低计算量,用1*1卷积核进行降维,让信息通过更少的连接传递达到更稀疏的特性;
- 在输出层之前有一个并置层,将四种不同类型的,但是大小相等的四张图并排叠在一起,形成一种新的特征响应图;
1*1的卷积(输入为m通道,输出为n通道):

卷积核大小为1;
相当于对所有的输入特征响应图做一次线性组合,输出一组新的特征相应图;
若 m>n,训练后相当于数据的降维(1*1卷积最大的作用),再接新的卷积层只需要在更少的n个通道上做卷积,节省了计算资源;
若把激活函数考虑进来,1*1卷积后加激活函数,那么就是神经网络,这就是Network in Network 的含义;
GoogleNet 结构:
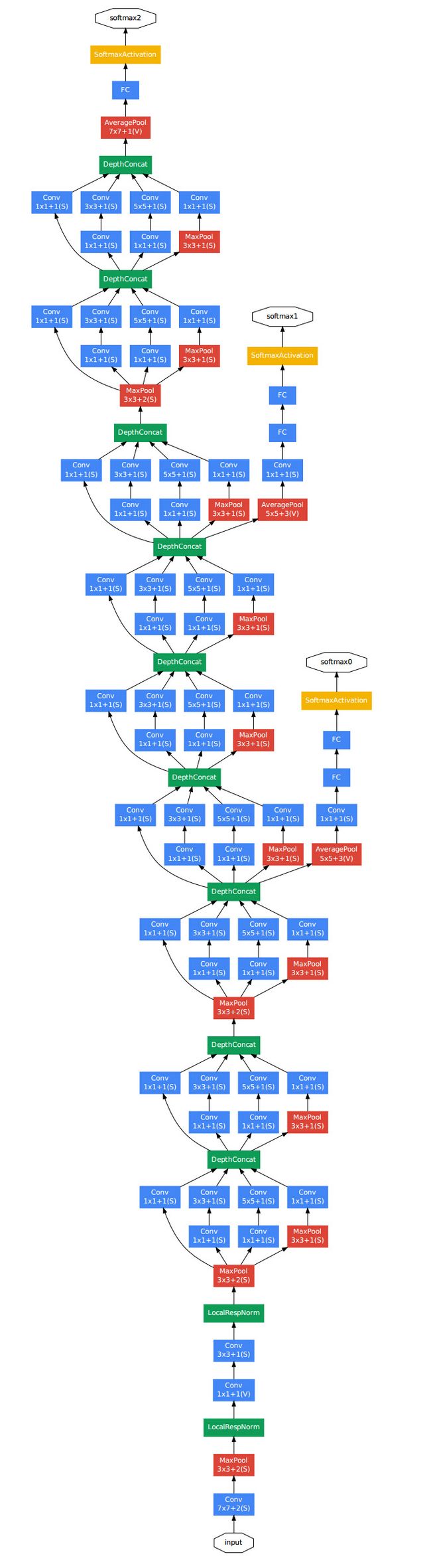
22层;
参数有500万个,远小于 AlexNet 和 VGG(约为 AlexNet 参数的1/12);
采用 Inception 结构,不仅进一步提升了预测分类的成功率,而且极大的减少了参数量;
此模型特点:
- 采用模块化的结构,方便增添和修改;
- 网络最后用 average pooling 代替全连接层,将模型准确率提高了 0.6%;
- 网络移除了全连接层,但保留 Dropout 层;
- 网络增加了两个辅助的 softmax,用于向前传递导数,辅助分类器,避免梯度消失;
GoogleNet 共9个 Inception 模块(18层)、3个卷积层,1个softmax全连接层,共22层;
输入:input后接1卷积层+1池化层+2*卷积层+1池化层;
中间:9个 Inception 结构;
最后:分类输出层(舍弃了两层全连接层,参数大大减少),最后一个 Inception 模块输出7*7大小、1024通道的特征相应图,对每个特征相应图求平均池化,得到1024维的向量,再通过全连接得到和输出数目对应的1000维的向量用于分类;
两个辅助的Softmax,辅助的分类器,主要用来向前传递导数,将中间某一层的输出用于分类,并按照较小的权重(一般取0.3)加到最终分类中,相当于做了模型的融合,增加了反向传播的梯度信号,避免梯度消失和梯度发散,提供了额外的正则化,对网络的训练很有帮助,在实际测试中,这两个Softmax会被去掉;
GoogleNet_Model代码(Pytorch):
import torch
from torch import nn
import torch.nn.functional as F
class InceptionModel(nn.Module):
def __init__(self, input_11, output_11, input_33_1, output_33_1,
input_33_2, output_33_2, input_55_1, output_55_1,
input_55_2, output_55_2, input_pool, output_pool):
super(InceptionModel, self).__init__()
self.layer1_1 = nn.Sequential(
nn.Conv2d(input_11, output_11, 1, 1),
nn.ReLU()
)
self.layer3_3 = nn.Sequential(
nn.Conv2d(input_33_1, output_33_1, 1, 1),
nn.ReLU(),
nn.Conv2d(input_33_2, output_33_2, 3, 1, 1),
nn.ReLU()
)
self.layer5_5 = nn.Sequential(
nn.Conv2d(input_55_1, output_55_1, 1, 1),
nn.ReLU(),
nn.Conv2d(input_55_2, output_55_2, 5, 1, 2),
nn.ReLU()
)
self.layer_pool = nn.Sequential(
nn.MaxPool2d(3, 1, 1),
nn.Conv2d(input_pool, output_pool, 1, 1),
nn.ReLU()
)
def forward(self, x):
x1 = self.layer1_1(x)
x2 = self.layer3_3(x)
x3 = self.layer5_5(x)
x4 = self.layer_pool(x)
x = [x1, x2, x3, x4]
out = torch.cat(x, 1)
print(out.shape)
return out
class AddCla(nn.Module):
def __init__(self, input_filter):
super(AddCla, self).__init__()
self.layer1 = nn.Sequential(
nn.MaxPool2d(5, 3),
nn.Conv2d(input_filter, 128, 1, 1),
)
self.layer2 = nn.Linear(128*4*4, 1024)
self.layer3 = nn.Linear(1024, 1000)
def forward(self, x):
x = self.layer1(x)
x = x.view(x.size(0), -1)
x = self.layer2(x)
x = self.layer3(x)
output = F.softmax(x, dim=1)
return output
class GoogleNet(nn.Module):
def __init__(self):
super(GoogleNet, self).__init__()
self.layer_maxpooling = nn.Sequential(
nn.MaxPool2d(3, 2, 1)
)
self.layer1 = nn.Sequential(
nn.Conv2d(3, 64, 7, 2, 3)
)
self.layer2_3 = nn.Sequential(
nn.Conv2d(64, 64, 1, 1),
nn.Conv2d(64, 192, 3, 1, 1)
)
self.layer4_5 = InceptionModel(input_11=192, output_11=64, input_33_1=192, output_33_1=96,
input_33_2=96, output_33_2=128, input_55_1=192, output_55_1=16,
input_55_2=16, output_55_2=32, input_pool=192, output_pool=32)
self.layer6_7 = InceptionModel(input_11=256, output_11=128, input_33_1=256, output_33_1=128,
input_33_2=128, output_33_2=192, input_55_1=256, output_55_1=32,
input_55_2=32, output_55_2=96, input_pool=256, output_pool=64)
self.layer8_9 = InceptionModel(input_11=480, output_11=192, input_33_1=480, output_33_1=96,
input_33_2=96, output_33_2=208, input_55_1=480, output_55_1=16,
input_55_2=16, output_55_2=48, input_pool=480, output_pool=64)
self.layer10_11 = InceptionModel(input_11=512, output_11=160, input_33_1=512, output_33_1=112,
input_33_2=112, output_33_2=224, input_55_1=512, output_55_1=24,
input_55_2=24, output_55_2=64, input_pool=512, output_pool=64)
self.layer12_13 = InceptionModel(input_11=512, output_11=128, input_33_1=512, output_33_1=128,
input_33_2=128, output_33_2=256, input_55_1=512, output_55_1=24,
input_55_2=24, output_55_2=64, input_pool=512, output_pool=64)
self.layer14_15 = InceptionModel(input_11=512, output_11=112, input_33_1=512, output_33_1=144,
input_33_2=144, output_33_2=288, input_55_1=512, output_55_1=32,
input_55_2=32, output_55_2=64, input_pool=512, output_pool=64)
self.layer16_17 = InceptionModel(input_11=528, output_11=256, input_33_1=528, output_33_1=160,
input_33_2=160, output_33_2=320, input_55_1=528, output_55_1=32,
input_55_2=32, output_55_2=128, input_pool=528, output_pool=128)
self.layer18_19 = InceptionModel(input_11=832, output_11=256, input_33_1=832, output_33_1=160,
input_33_2=160, output_33_2=320, input_55_1=832, output_55_1=32,
input_55_2=32, output_55_2=128, input_pool=832, output_pool=128)
self.layer20_21 = InceptionModel(input_11=832, output_11=384, input_33_1=832, output_33_1=192,
input_33_2=192, output_33_2=384, input_55_1=832, output_55_1=48,
input_55_2=48, output_55_2=128, input_pool=832, output_pool=128)
self.pooling = nn.AvgPool2d(7, 1)
self.layer22 = nn.Linear(1024, 1000)
def forward(self, x):
x = self.layer1(x)
x = self.layer_maxpooling(x)
x = self.layer2_3(x)
x = self.layer_maxpooling(x)
x = self.layer4_5(x)
x = self.layer6_7(x)
x = self.layer_maxpooling(x)
x = self.layer8_9(x)
addcla1 = AddCla(512)(x)
x = self.layer10_11(x)
x = self.layer12_13(x)
x = self.layer14_15(x)
addcla2 = AddCla(528)(x)
x = self.layer16_17(x)
x = self.layer_maxpooling(x)
x = self.layer18_19(x)
x = self.layer20_21(x)
x = self.pooling(x)
x = nn.Dropout(0.4)(x)
x = x.view(x.size(0), -1)
x = self.layer22(x)
output = F.softmax(x, dim=1)
return output, addcla1, addcla2