金融风控训练营Task01基础知识学习笔记
金融风控训练营Task01基础知识学习笔记
-
- 一、学习知识点概要
- 二、学习内容及问题与解答
-
- 1.读取数据
- 2.预测指标
- 3.拓展知识——评分卡
- 三、学习思考与总结
一、学习知识点概要
- 理解赛题数据和目标
- 清楚评分体系
- 熟悉比赛流程
二、学习内容及问题与解答
1.读取数据
补充:
- wget:
Linux下的一个命令行从网络上自动下载文件的自由工具,它支持HTTP,HTTPS和FTP协议,可以使用HTTP代理。在Python中可以直接通过安装包后使用。wget命令用来从指定的URL下载文件。wget非常稳定,它在带宽很窄的情况下和不稳定网络中有很强的适应性,如果是由于网络的原因下载失败,wget会不断的尝试,直到整个文件下载完毕。如果是服务器打断下载过程,它会再次联到服务器上从停止的地方继续下载。这对从那些限定了链接时间的服务器上下载大文件非常有用。
-dsw:
工作区文件
- 通过wget命令从链接直接下载数据到dsw
# 导入数据读取模块
import pandas as pd
# 直接下载到dsw本地,这样的好处是后面数据读取会快点,但是直接下载到本地会占用比较多的内存
# 下载测试数据集 41.33mb
!wget http://tianchi-media.oss-cn-beijing.aliyuncs.com/dragonball/FRC/data_set/testA.csv
# 下载训练数据集 166.77mb
!wget http://tianchi-media.oss-cn-beijing.aliyuncs.com/dragonball/FRC/data_set/train.csv
train = pd.read_csv('train.csv')
testA = pd.read_csv('testA.csv')
报错:
!wget http://tianchi-media.oss-cn-beijing.aliyuncs.com/dragonball/FRC/data_set/testA.csv
SyntaxError: invalid syntax
- wget的第二种用法
import wget
testAUrl = 'http://tianchi-media.oss-cn-beijing.aliyuncs.com/dragonball/FRC/data_set/testA.csv'
trainUrl = 'http://tianchi-media.oss-cn-beijing.aliyuncs.com/dragonball/FRC/data_set/train.csv'
testAPos = 'D:/Python/python_file/learn-tianchi/testA.csv'
trainPos = 'D:/Python/python_file/learn-tianchi/train.csv'
wget.download(testAUrl,testAPos)
wget.download(trainUrl,trainPos)
train = pd.read_csv('train.csv')
testA = pd.read_csv('testA.csv')
报错:
ModuleNotFoundError: No module named ‘wget’
在cmd中“pip3 install wget”之后也不行
解决:
Spyder要用Anaconda prompt来装模块,不能用在cmd用pip装

补充:
如果conda install安装不了,改用pip install
- 直接利用pandas读取链接数据
# 导入数据读取模块
import pandas as pd
# (推荐)方法二:直接读取链接数据,这样的好处是不占dsw内存,但是读取速度相对会比较慢点
train = pd.read_csv('http://tianchi-media.oss-cn-beijing.aliyuncs.com/dragonball/FRC/data_set/train.csv')
testA = pd.read_csv('http://tianchi-media.oss-cn-beijing.aliyuncs.com/dragonball/FRC/data_set/testA.csv')
加载过慢:
运行了半个多小时还是运行不出来
- 直接通过链接在浏览器下载到本地(数据量大,也需要一定的时间)
import pandas as pd
#直接通过浏览器下载
train = pd.read_csv('train.csv')
testA = pd.read_csv('testA.csv')
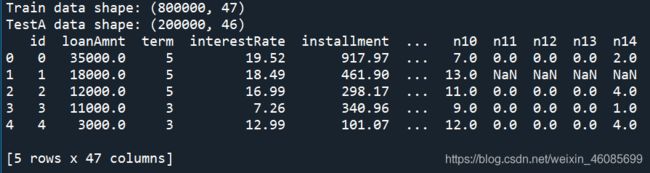
print('Train data shape:',train.shape)
print('TestA data shape:',testA.shape)
print(train.head())
结果:
2.预测指标
- 分类算法常见的评估指标如下
| Name | Formula | Explanation |
|---|---|---|
| 混淆矩阵(Confuse Matrix) | - | (1)若一个实例是正类,并且被预测为正类,即为真正类TP(True Positive );(2)若一个实例是正类,但是被预测为负类,即为假负类FN(False Negative );(3)若一个实例是负类,但是被预测为正类,即为假正类FP(False Positive );(4)若一个实例是负类,并且被预测为负类,即为真负类TN(True Negative ) |
| 准确率(Accuracy) | A c c u r a c y = T P + T N T P + T N + F P + F N Accuracy=\frac{TP+TN}{TP+TN+FP+FN} Accuracy=TP+TN+FP+FNTP+TN | 准确率是常用的一个评价指标,但是不适合样本不均衡的情况 |
| 精确率(Precision) | P r e c i s i o n = T P T P + F P Precision=\frac{TP}{TP+FP} Precision=TP+FPTP | 又称查准率,正确预测为正样本(TP)占预测为正样本(TP+FP)的百分比 |
| 召回率(Recall) | R e c a l l = T P T P + F N Recall=\frac{TP}{TP+FN} Recall=TP+FNTP | 又称为查全率,正确预测为正样本(TP)占正样本(TP+FN)的百分比 |
| F1-Score | F 1 − S c o r e = 2 1 P r e c i s i o n + 1 R e c a l l F1-Score=\frac{2}{\frac{1}{Precision}+\frac{1}{Recall}} F1−Score=Precision1+Recall12 | F1 Score 精确率和召回率是相互影响的,精确率升高则召回率下降,召回率升高则精确率下降,如果需要兼顾二者,就需要精确率、召回率的结合F1 Score。 |
| ROC(Receiver Operating Characteristic) | - | ROC空间将假正例率(FPR)定义为 X 轴,真正例率(TPR)定义为 Y 轴。 |
| TPR | T P R ( = R e c a l l ) = T P T P + F N TPR (=Recall)=\frac{TP}{TP+FN} TPR(=Recall)=TP+FNTP | 在所有实际为正例的样本中,被正确地判断为正例之比率 |
| FPR | F P R = F P T P + F N FPR =\frac{FP}{TP+FN} FPR=TP+FNFP | 在所有实际为负例的样本中,被错误地判断为正例之比率 |
| AUC(Area Under Curve) | - | AUC(Area Under Curve)被定义为 ROC曲线 下与坐标轴围成的面积,显然这个面积的数值不会大于1。又由于ROC曲线一般都处于y=x这条直线的上方,所以AUC的取值范围在0.5和1之间。AUC越接近1.0,检测方法真实性越高;等于0.5时,则真实性最低,无应用价值。 |
- 对于金融风控预测类常见的评估指标如下:
| Name | Value | Explanation |
|---|---|---|
| KS(Kolmogorov-Smirnov) | K S = m a x ( T P R − F P R ) KS=max(TPR-FPR) KS=max(TPR−FPR) | 在风控中,KS常用于评估模型区分度。区分度越大,说明模型的风险排序能力(ranking ability)越强。KS不同代表的不同情况,一般情况KS值越大,模型的区分能力越强,但是也不是越大模型效果就越好,如果KS过大,模型可能存在异常,所以当KS值过高可能需要检查模型是否过拟合。以下为KS值对应的模型情况,但此对应不是唯一的,只代表大致趋势。 |
| ROC(Receiver Operating Characteristic) | - | ROC空间将假正例率(FPR)定义为 X 轴,真正例率(TPR)定义为 Y 轴。 |
| AUC(Area Under Curve) | - | AUC(Area Under Curve)被定义为 ROC曲线 下与坐标轴围成的面积,显然这个面积的数值不会大于1。又由于ROC曲线一般都处于y=x这条直线的上方,所以AUC的取值范围在0.5和1之间。AUC越接近1.0,检测方法真实性越高;等于0.5时,则真实性最低,无应用价值。 |
分类指标评价计算示例
## 混淆矩阵
import numpy as np
from sklearn.metrics import confusion_matrix
y_pred = [0, 1, 0, 1]
y_true = [0, 1, 1, 0]
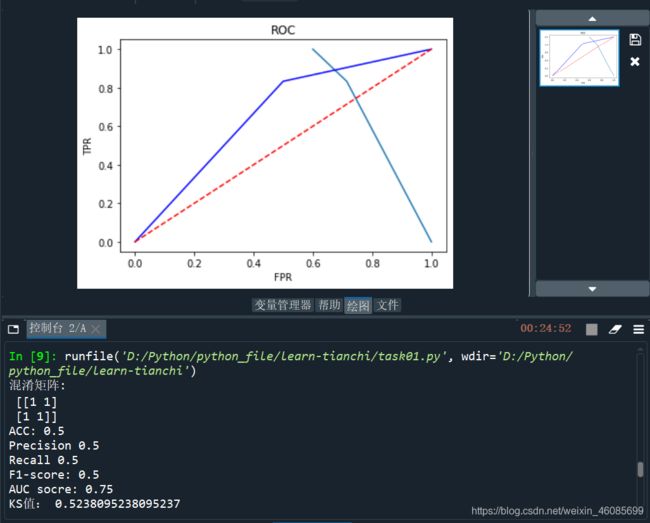
print('混淆矩阵:\n',confusion_matrix(y_true, y_pred))
## accuracy
from sklearn.metrics import accuracy_score
y_pred = [0, 1, 0, 1]
y_true = [0, 1, 1, 0]
print('ACC:',accuracy_score(y_true, y_pred))
## Precision,Recall,F1-score
from sklearn import metrics
y_pred = [0, 1, 0, 1]
y_true = [0, 1, 1, 0]
print('Precision',metrics.precision_score(y_true, y_pred))
print('Recall',metrics.recall_score(y_true, y_pred))
print('F1-score:',metrics.f1_score(y_true, y_pred))
## P-R曲线
import matplotlib.pyplot as plt
from sklearn.metrics import precision_recall_curve
y_pred = [0, 1, 1, 0, 1, 1, 0, 1, 1, 1]
y_true = [0, 1, 1, 0, 1, 0, 1, 1, 0, 1]
precision, recall, thresholds = precision_recall_curve(y_true, y_pred)
plt.plot(precision, recall)
## ROC曲线
from sklearn.metrics import roc_curve
y_pred = [0, 1, 1, 0, 1, 1, 0, 1, 1, 1]
y_true = [0, 1, 1, 0, 1, 0, 1, 1, 0, 1]
FPR,TPR,thresholds=roc_curve(y_true, y_pred)
plt.title('ROC')
plt.plot(FPR, TPR,'b')
plt.plot([0,1],[0,1],'r--')
plt.ylabel('TPR')
plt.xlabel('FPR')
## AUC
import numpy as np
from sklearn.metrics import roc_auc_score
y_true = np.array([0, 0, 1, 1])
y_scores = np.array([0.1, 0.4, 0.35, 0.8])
print('AUC socre:',roc_auc_score(y_true, y_scores))
## KS值 在实际操作时往往使用ROC曲线配合求出KS值
from sklearn.metrics import roc_curve
y_pred = [0, 1, 1, 0, 1, 1, 0, 1, 1, 1]
y_true = [0, 1, 1, 0, 1, 0, 1, 1, 1, 1]
FPR,TPR,thresholds=roc_curve(y_true, y_pred)
KS=abs(FPR-TPR).max()
print('KS值:',KS)
结果:
3.拓展知识——评分卡
评分卡是一张拥有分数刻度会让相应阈值的表。信用评分卡是用于用户信用的一张刻度表。以下代码是一个非标准评分卡的代码流程,用于刻画用户的信用评分。评分卡是金融风控中常用的一种对于用户信用进行刻画的手段!
#评分卡 不是标准评分卡
def Score(prob,P0=600,PDO=20,badrate=None,goodrate=None):
P0 = P0
PDO = PDO
theta0 = badrate/goodrate
B = PDO/np.log(2)
A = P0 + B*np.log(2*theta0)
score = A-B*np.log(prob/(1-prob))
return score
三、学习思考与总结
越学习越发现自己的无知,前段时间师姐给了我们一个可视化任务,需要对比不同分类的Accuracy、Precision、Recall、F1-Score,还以为数据集的样式、sklearn模块以及上述四种指标是师姐自己设计的,如今才恍然大悟。学习了这些基础知识之后,才能说自己知道数据分析吧。现在的我,对数据分析的认识变成了:计算出数据集的各个指标,得到这些指标后进行分析,提取有用信息和形成结论进而对数据加以详细研究和概括总结的过程。同时,学习一个新知识一定要动手实践,才能真正学会运用。