文献阅读(十五):Multi-modal Conditional Attention Fusion for Dimensional Emotion Prediction基于多模态条件注意融合的多维情感
文献阅读(十五):Multi-modal Conditional Attention Fusion for Dimensional Emotion Prediction基于多模态条件注意融合的多维情感预测
- ABSTRACT
- 1 INTRODUCTION
- 2 MULTI-MODAL FEATURES
-
- 2.1 Audio Features
- 2.2 Visual Features
- 3 EMOTION PREDICTION MODEL
-
- 3.1 Uni-Modality Prediction Model
- 3.2 Conditional Attention Fusion Model
- 3.3 Model Learning
- 4 EXPERIMENTS
-
- 4.1 Dataset
- 4.2 Experimental Setup
- 4.3 Experimental Results
- 5 CONCLUSIONS
- 标题:基于多模态条件注意融合的多维情感预测
- 出处:CoRR abs/1709.02251 (2017)
ABSTRACT
连续维度情感预测是一项具有挑战性的任务,各种形态的融合通常达到最先进的性能,如早期融合或晚期融合。
本文提出了一种新的多模态融合策略——条件注意融合,该策略能够在每个时间步动态关注不同的模态。
采用长-短时记忆循环神经网络(LSTM-RNN)作为基本的单模态模型来捕获长时间依赖关系。分配给不同模式的权重是由当前输入特征和最近的历史信息自动决定的,而不是在任何情况下固定的。
在AVEC2015基准数据集上的实验结果表明,该方法的有效性优于几种常用的valence预测策略。
1 INTRODUCTION
理解人类情感是改善人机交互的一个关键组成部分。情感识别的应用范围很广,比如客户呼叫中心、计算机辅导系统和心理健康诊断。
维度情感是情感识别中最常用的计算模型之一。它将情绪状态映射到连续空间中的一个点上。典型的空间由三个维度组成: arousal (a measure of affective activation), valence (a measure of pleasure) and dominance (a measure of power or control)。这种表现可以表达自然、微妙、复杂的情感。近年来,为了更好地理解人类情绪,有很多关于情感维度分析的研究工作[3-5]。
由于情感是通过人类的各种行为来传递的,过去的作品中已经运用了广泛的方式来进行情感识别,包括语音[6]、文本[7]、面部表情[8]、手势[9]、生理信号[10]等。其中,面部表情和言语是传递人类情感最常见的渠道。使用多种模式进行情感识别是有益的。
以往工作中针对不同模态的融合策略可以分为三类,即特征级(早期)融合、决策级(后期)融合和模型级([11])融合。

早期融合使用来自不同模式的连接特征作为分类器的输入特征。该方法在文献中得到了广泛的应用,成功提高了[12]的性能。然而,它遭受了维度诅咒。当特性没有及时同步时,它也不是很有用。晚期融合消除了早期融合的一些缺点。它结合了不同模态的预测,训练了RVM[13]、BLSTM[14]等二级模型。但它忽略了不同情态特征之间的相互作用和相关性。模型级融合是这两个极端之间的妥协。模型级融合的实现依赖于特定的分类器。例如,对于神经网络,模型级融合可以是来自不同模式[15]的不同隐藏层的串联。对于内核分类器,模型级融合可以是内核融合[16]。对于隐马尔可夫模型(HMM)分类器,提出了新的特征交互形式[17]。
在本文中,我们提出了一种新的融合架构,称为条件注意融合。
我们使用长-短期记忆循环神经网络(lstm)作为每个单模态的基本模型,因为lstm能够捕获长时间依赖。对于每个时间步,融合模型根据其当前输入的多模态特征和最近的历史信息,学习对每个模态应给予多少关注。这种方法类似于人类的感知,因为人类可以动态地关注更明显和可信的模态来理解情绪。与早期的融合不同,我们动态地结合了不同模式的预测,避免了不同特征之间的维数和同步的诅咒。与后期融合不同的是,输入特征在更高层次上相互作用来学习当前的注意力,而不是在不同模式之间没有任何相互作用的情况下被孤立。主要架构如图2所示。我们使用AVEC2015维度情感数据集[5]来评估我们的方法。实验结果表明了该融合体系结构的有效性。
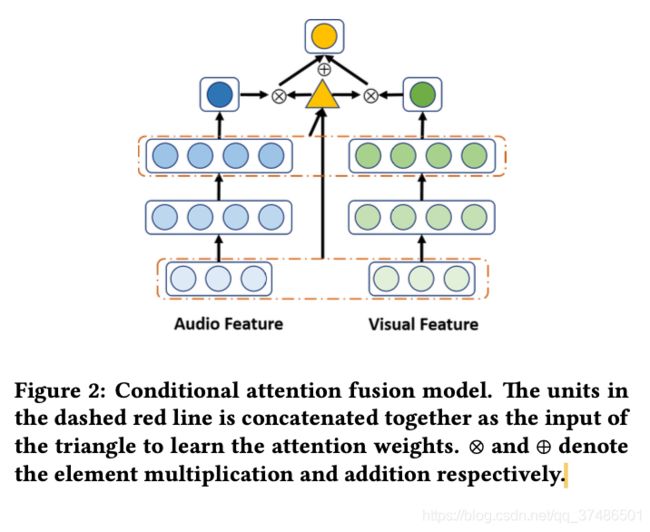
2 MULTI-MODAL FEATURES
2.1 Audio Features
我们利用OpenSMILE工具箱[18]来提取低级特征,包括MFCCs,响度,F0,抖动和微光。所有的特征提取使用40ms的帧窗口大小,没有重叠与groundtruth标签匹配,因为在[19]中证明了短时间特征可以揭示更多的细节,从而提高lstm情感预测的性能。低层声学特征有76个维度。
2.2 Visual Features
从面部表情中提取两组视觉特征:基于外观特征和基于几何特征[5]。采用局部Gabor Binary Patterns from Three正交平面(LGBP-TOP)计算基于外观的特征,并通过PCA压缩到84维。从49个面部特征点计算316个维度的几何特征。未检测到人脸的帧用零填充。我们将基于外观的特征和基于几何的特征作为我们的视觉特征表示。
3 EMOTION PREDICTION MODEL
3.1 Uni-Modality Prediction Model
LSTM (Long - short - term memory)体系结构[20]是状态用于序列分析的艺术模型,可以利用数据中的长期依赖关系。本文采用Graves[21]提出的窥视孔LSTM版本。隐藏单元和门的功能定义如下。

3.2 Conditional Attention Fusion Model
让xta和xtv分别指第t帧的音频特征和视觉特征。Hta和HVT为
最后一层隐层分别来自具有音频或视觉特征的单模态模型。Fθa和fθv是指将音频或视觉特征映射到预测中的单模态模型。我们将时间步t时两种模式预测的条件注意融合定义为:

λt的计算基于当前的视觉特征和他们的高水平历史信息有两个原因。首先,电流输入特征是显示模态是否可靠的最直接指标。例如,对于面部特征,输入满0表示当前的人脸检测失败,因此应该被赋予较少的置信度。其次,通过考虑高水平的历史特征和当前特征的添加,分配给每个模态的权重将被平滑。这样,模型可以动态关注不同的模态,从而提高不同情况下的稳定性。
3.3 Model Learning
从直观上看,当声能较高时,声学特征更可靠,因为耳机麦克风可以记录谈话中主讲人和其他讲话人的讲话。更高的能量可能意味着更有信心的演讲是从目标主题。类似地,只有当人脸被正确检测出来时,面部特征才是可靠的。因此,添加这些次要信息可能有助于了解注意力权重。
我们将声能转换为尺度[0,1],用дta表示第t个时间步长的值。对于视觉特征,由于数据集提供的人脸检测没有检测置信度,我们使用дtv∈{0,1}来表示是否检测到被试的人脸。因此,我们定义一个序列的最终损失函数如下:

4 EXPERIMENTS
4.1 Dataset
AVEC2015维度情感数据集是RECOLA数据集[22]的一个子集,RECOLA数据集是一个多模态的远程协作情感交互语料。数据集中有27个主题,平均分为training, development and testing sets。在前5分钟的互动中,每个参与者的音频、视频和physiological生理数据都被收集。每40ms[5]的Arousal and valence [- 1,1]标度标注。由于测试集上的提交时间有限,我们对开发集进行交叉验证。我们随机选取5名受试者作为优化超参数的开发集,其余4名作为测试集。我们做了8次实验。The concordance correlation coefficient (CCC) [5] 作为评价指标。
4.2 Experimental Setup
Annotation delay compensation注释延迟补偿[13]的应用,因为信号内容和groundtruth标签之间存在延迟,由于解说者的感知处理。我们去掉第N个groundtruth标签和最后N个输入特征帧。在训练集上采用非时间回归模型支持向量机对N进行优化。在本文中,N被优化为20帧的音频和视觉特征。当预测结果时,模型的输出会向后移动N帧。前N个坐标系中缺失的预测用零填充。
最后,采用二项滤波器平滑预测。在接下来的实验中采用了一种多符号的延迟补偿和平滑方法。
输入特征被归一化到范围[-1,1]。对于声学特征,LSTM有2层,每层100个单元。对于视觉特征,LSTM有2层,每层120个单元。mini-batch的大小为256,采用截断backpropagation through time (BPTT)[23]。初始学习速率设置为0.01,学习速率衰减。Dropout被用作正则化。培训时代为100,以开发集中表现最好的模型作为最终模型。
我们将条件注意融合模型与早期融合、晚期融合和模型级融合进行了比较。对于早期融合,LSTM每层有150个单元,其参数大小与其他融合方法相似。对于后期的、模型级的和条件级的注意融合,使用训练的单模态LSTM初始化LSTM中的参数。为了避免过拟合,我们只微调了10个epoch,初始学习率较小,为0.001。唤醒预测的超参数α和β分别设为0,价预测的超参数为0.04和0.02。
4.3 Experimental Results

表1显示了使用单模态特征的预测性能。听觉特征在arousal prediction方面表现最好,视觉特征在效价预测方面略优于听觉特征。
不同融合方法对arousal prediction的性能如图4(a)所示。
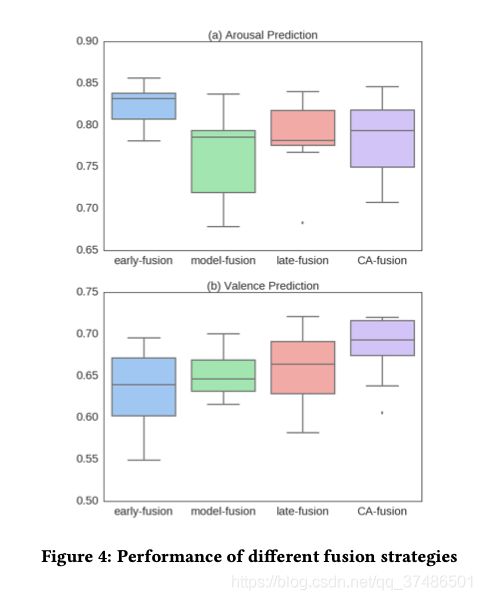
在arousal预测上,CA-fusion效果较早期略差,在valence预测上,CA-fusion是最优的。
在所有融合策略中,早期融合达到了平均最好的性能,我们提出的融合方法是第二好的。图4(a)与表1 (Student t-test, p-value = 0.07)相比,早期融合预测与声学单模态预测没有显著差异。我们发现arousal and acoustic之间存在很强的相关性,如图3所示,我们用窗口100 acoustic energy,并根据能量和arousal标签之间的均值和标准差进行移位和缩放。开发组的Pearson相关系数较高,为0.558,CCC为0.4。这表明,人类对唤醒的感知可能主要基于声学特征,因此融合其他模式可能带来较少的好处。
但是对于valence预测,所有的融合策略都优于原始的单模态模型(如表1所示)。一个有趣的发现是,融合策略应用的级别越高,性能越好,如图4(b)所示。其中,我们提出的条件注意融合模型的融合效果最好,且通过t检验明显优于其他融合策略(与次优融合策略的融合晚期相比p < 0.02,与其他融合策略相比p < 0.007)。这说明动态适应不同模式的融合权值是有益的。表2显示了Lt处于损耗状态和不处于损耗状态时的CCC性能。我们可以看到在loss function中考虑Lдt可以进一步提高性能,因为它有助于指导不同模式的重要性。这可能是由于数据不足,在没有任何监督信息的情况下,模型无法有效地学习注意权值。实验还发现,当α和β在10−2左右时,预测性能没有显著变化。
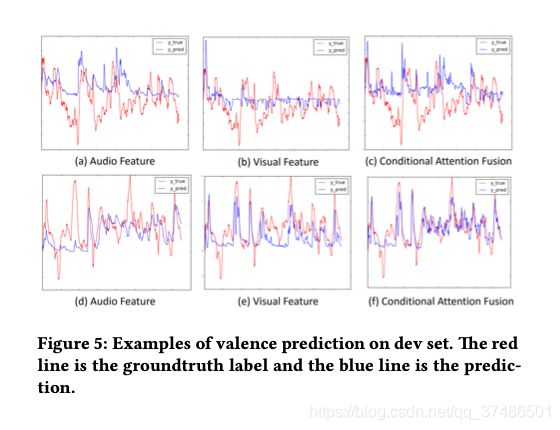
图5显示了条件注意融合方法的情绪预测的一些例子。
上:视觉特征缺失,显示了大多数视觉特征缺失的情况。
下:含大量视觉特征,含有在大多数帧中都可以提取出视觉特征的情况。
可以看出,在这两种情况下, CA-fusion:能自动融合不同特征,融合方法可以自动利用音频和视觉特征的互补信息。
条件注意融合方法在测试集上的效价预测性能如表3所示。Chen等人的[19]使用与我们相同的特征集,Chao等人的[24]使用更多的特征,包括cnn用于价预测。对比结果进一步证明了该方法的有效性。
5 CONCLUSIONS
本文提出了一种基于LSTM-RNN的连续维情感预测的多模态融合策略——条件注意融合。它可以根据当前模态特征和历史信息动态关注不同的模态,增加了模型的稳定性。在AVEC 2015基准数据集上的实验结果表明,本文提出的融合方法明显优于早期融合、模型级融合和后期融合等常用的化合价预测方法。今后,我们将更多地利用不同模态的特征,运用策略更好地表达不同模态特征的相关性和独立性。