Python_Pandas的ETL数据处理方法
Python_Pandas的ETL数据处理方法
-
-
- 一、数据加载与导出
-
- 1. read_csv数据加载
- 2. to_csv写入文件并导出
- 二、数据清洗
-
- 1. 处理缺失值
-
- 1. info()发现缺失值
- 2. dropna()丢弃缺失值
- 3. fillna()填充缺失值
- 2. 处理无效值
-
- describe()检测无效值
- 3. 处理重复值
-
- 1. duplicated()发现重复值
- 2. drop_duplicates()删除重复值
- 三、数据过滤
-
-
- query()数据过滤
-
- 四、数据转换
-
-
- 1. 应用apply与映射map
- 2. replace()替换
- 3. 字符串矢量级运算
-
- 五、数据合并
-
-
- 1. concat()索引连接
- 2. append()类似concat()
- 3. merge 类似SQL的join()
- 5. join()类似merge()
-
-
- 多层索引与分组聚合
-
-
- 3. MultiIndex多层索引
-
- 创建方式
- 多层索引操作
-
- Series多层索引
- DataFrame多层索引
- 2. swaplevel交换索引
-
- sort_index索引排序
- stack索引堆叠
- unstack取消堆叠
- set_index设置索引
- reset_index重置索引
- 3. groupby分组
-
- 迭代
- 分组的方式
- apply
- 4. 聚合
-
# 导入及查看
import numpy as np #导入numpy
import pandas as pd #导入pandas
np.__version__ #打印numpy版本号
pd.__version__ #打印pandas版本号
pd.set_option("max_columns", 10) #用于设置列中单独元素的最大长度,默认为50
df.head() #默认显示5行
df.tail() # 显示后n行
df.sample(5) # 随机采样,随机选择n行。n默认为1.
df.shape[0] #数据条数
df.shape[1] #数列列的个数
df.columns #打印出全部的列名称
chipo.index #查看列索引
# 处理
t.info() #查看空值
t[t.duplicated()] #查看重复
t.drop_duplicates(inplace=True) #删除重复
sp = t[2].str.split(";", expand=True) #对列拆分
sp.drop([8, 9], axis=1, inplace=True) #删除列
sp[7] = sp[7].str.replace("票房(万)", "").astype(np.float64) #替换列内无用信息,提取数据并做类型转换
result = pd.concat((t, sp), axis=1) #与原表按列进行拼接
result.columns = list(range(result.columns.size)) #重新指定列索引
g = result.groupby(0) #按列分组
g[10].sum().sort_values(ascending=False) #统计并排序
一、数据加载与导出
1. read_csv数据加载
常用函数:
-
read_csv
-
read_table
-
read_sql
说明:read_csv与read_table默认使用的分隔符不同。
常用参数:
-
sep / delimiter:导入文件时候指定分隔符,默认使用","
# 读取csv文件,返回一个DataFrame类型的对象。 # 在读取的时候,默认会将第一行记录当成标题。如果没有标题,我们可以指定header=None。 # read_csv默认使用逗号作为分隔符,我们可以使用sep或delimiter来指定分隔符。 df = pd.read_csv(r"student.csv", header=None, sep=",") display(df.head()) -
header:生成列标签,默认"0, 1, 2, 3, ……"
# 如果header为None,read_csv默认会自己生成列标签。(0, 1, 2, 3……)。我们可以通过names参数来指定列标签(标题) df = pd.read_csv(r"student.csv", header=None, names=["学号", "姓名", "性别", "年龄", "部门"]) display(df.head()) -
index_col:生成行标签,默认"0, 1, 2, 3, ……"
# 对于行索引,默认会自动生成(0, 1, 2, 3 ……)如果我们需要自己指定某列充当行索引(例如,数据库,数据表中的主键) # 我们可以使用index_col参数来进行设置。 df = pd.read_csv(r"student.csv", header=None, index_col=0, names=["学号", "姓名", "性别", "年龄", "部门"]) display(df.head()) -
usecols:控制载入的列数
# 我们可以使用usecols来控制需要哪些列。如果某列充当索引列(index_col),则充当索引列的标签,也需要指定在usecols中。 df = pd.read_csv(r"student.csv", header=None, index_col=0, usecols=[0, 1, 2],names=["学号", "姓名", "性别"]) display(df.head())
2. to_csv写入文件并导出
to_csv:DataFrame与Series对象的to_csv方法,可以将数据写入文件或者指定的数据流中。
常用参数:
-
sep:分隔符
# 默认以逗号作为分隔符,可以使用sep来自定义分隔符。 df.to_csv("data1.csv", sep="-") -
header:是否写入标题行,默认为True。
# 默认情况会写入标题(行标签索引)。可以使用header进行设置是否写入标题。True,写入(默认),False不写入。 df.to_csv("data2.csv", header=False) -
na_rep:空值的表示
# 默认情况下,空值不显示,我们可以自定义空值的显式效果(内容)。 df.to_csv("data3.csv", header=False, na_rep="空") -
index:是否写入索引,默认为True。
# 行索引,默认写入,我们可以通过参数index来设置是否写入行索引。True,写入(默认), False,不写入。 df.to_csv("data4.csv", header=False, na_rep="空", index=False) -
index_label:索引字段的名称
# 可以通过index_label来设置行索引的名称。 df.to_csv("data5.csv", index_label="index_name", na_rep="空") -
columns:写入的字段,默认为全部写入。
# 我们可以通过colomns列来设置那些列写入到文件中。默认为写入所有列。 df.to_csv("data6.csv", columns=[1, 3], header=False, na_rep="空", index=False)
二、数据清洗
1. 处理缺失值
1. info()发现缺失值
Pandas中,会将float类型的nan与None视为缺失值,我们可以通过如下方法来检测缺失值:
说明:判断是否存在空值,可以将isnull与any或all结合使用。
-
info:显示DataFrame中每列的相关信息
# 检测缺失值,首先可以调用info方法进行整体查看。 df.info()
RangeIndex: 22 entries, 0 to 21 #22条记录,范围为0-21
Data columns (total 5 columns): #共有5列数据# Column Non-Null Count Dtype
— ------ -------------- -----
0 0 22 non-null int64
1 1 22 non-null object
2 2 22 non-null object
3 3 22 non-null int64
4 4 22 non-null object
dtypes: int64(2), object(3)
memory usage: 1008.0+ bytes
-
isnull:是否存在空值
display(df.isnull().head()) display(df[2].isnull().any()) display(df[3].isnull().any())0 1 2 3 4 0 False False False False False 1 False False False False False 2 False False False True True 3 False False False False False 4 False False False True True False #第二列不存在空值 True #第三列存在空值 -
notnull:与isnull相反
2. dropna()丢弃缺失值
dropna:对于缺失值,我们可以将其进行丢弃处理。
常用参数:
-
how:指定dropna丢弃缺失值的行为,默认为any。
# 处理空值。丢弃空值,使用dropna。 df.dropna().info() # 默认情况下,how的值为any,表示只要存在空值,就丢弃行(列),我们可以指定为all,表示所有值为空值时,才进行删除。 df.dropna(how="all").info() -
axis:指定丢弃行或者丢弃列(默认为丢弃行)。
# 默认,存在空值,会丢弃行,我们可以指定丢弃列。(axis=0表示按行删除,axis=1表示按列删除。) display(df.dropna(axis=1).head()) -
thresh:当非空数值达到该值时,保留数据,否则删除。
# 有时候,how的any与all可能都不太合适。any的条件太宽松,all又太严格。我们可以自定义删除的门槛。 # 通过thresh来指定(门槛)。指的是非空的数据至少要达到thresh指定的数量时,整个行(列)才会保留,否则就删除。 # 可以使用inplace来设置是否进行就地修改。默认为False。 df.dropna(thresh=3, inplace=False).head() -
inplace:指定是否就地修改,默认为False。
# # 默认,存在空值,会丢弃行,我们可以指定丢弃列。(axis=0表示按行删除,axis=1表示按列删除。) display(df.dropna(axis=1).head())
3. fillna()填充缺失值
fillna():我们也可以对缺失值进行填充(fillna)。
常用参数:
-
value:填充所使用的值。可以是一个字典,这样就可以为DataFrame的不同列指定不同的填充值。
# 填充值 fillna进行填充。 # 使用固定值来填充所有的列。 df1 = df.fillna(10000) display(df1.head()) # 可以提供一个字典,这样就能够为不同的列,填充不同的值。 # 字典的key指定索引,value指定填充值。 df2 = df.fillna({ 3: 5000, 4:1000}) display(df2.head()) -
method:指定前值(上一个有效值)填充(pad / ffill),还是后值(下一个有效值)填充(backfill / bfill)。
# 我们可以使用method,来指定向前(后)填充。此种情况下,主要应用是记录之间有着紧密的关联(趋势)。例如,房价,股票。 # 使用上一个有效值进行填充。 display(df.fillna(method="ffill").head(6)) # 使用下一个有效值进行填充。 display(df.fillna(method="bfill").head(6)) -
limit:如果指定method,表示最大连续NaN的填充数量,如果没有指定method,则表示最大的NaN填充数量。
# limit参数。如果指定method,则表示最多连续填充。 # 如果没有指定method,则表示总共填充。 display(df.fillna(method="bfill", limit=1).head(6)) display(df.fillna(value=50000, limit=2).head(6)) -
inplace:指定是否就地修改,默认为False。
# 设置是否就地修改,默认为False。 df.fillna("aa", inplace=True) display(df.head(6))
2. 处理无效值
describe()检测无效值
可以通过DataFrame对象的describe方法查看数据的统计信息。不同类型的列,统计信息也不太相同。
# 如果DataFrame当中存在数值列,则describe值显示数值列。
display(df.describe())
# 数值列的统计与非数值列的统计,结果不同。
display(df[[0, 1, 2]].describe())
3 4 count 1098.000000 1098.000000 mean 143.082878 1017.034235 std 80.803922 550.759464 min 6.000000 51.390000 25% 73.250000 555.042500 50% 139.500000 1009.025000 75% 213.750000 1500.265000 max 289.000000 1992.640000
0 1 2 count 1396 1396 1396 unique 213 23 60 top 2015-12-10 http://www.movie.com/bor/ 最冷一天;陈奕迅;90;伤感 freq 16 100 32
3. 处理重复值
1. duplicated()发现重复值
我们可以通过duplicated方法来发现重复值。该方法返回Series类型的对象,值为布尔类型,表示是否与上一行重复。
# 检测重复值
display(df.duplicated().any())
# 查看重复记录
display(df[df.duplicated()])
常用参数
-
keep:指定记录被标记为重复(True)的规则。默认为first。
# 如果需要查看所有重复的记录,可以使用keep参数。 # keep: # frist:前面的记录标记为True。 # last: 后面的记录标记为True。 # False:所有记录都标记为True。 display(df[df.duplicated(keep=False)]) -
subset:指定依据哪些列判断是否重复,默认为所有列。
# 可以使用subset参数来指定重复的规则。默认为所有列一致才认为是重复的。 # 规则改为:只要第0,与第1列相同,则认为是重复的。 display(df.duplicated(subset=[0, 1]))
2. drop_duplicates()删除重复值
# 删除重复值
df.drop_duplicates([0])
三、数据过滤
query()数据过滤
可以使用布尔数组或者索引数组的方式来过滤数据。
另外,也可以用DataFrame类的query方法来进行数据过滤。在query方法中也可以使用外面定义的变量,需要在变量前加上@。
# 数据过滤通常的方式:
# 通过判断条件生成一个布尔类型的数组,然后,DataFrame使用该布尔数组进行行过滤。
display(df[df[0] == "2015-12-25"])
# 过滤的第二种方式。
df.columns = ["date", "url", "name", "num1", "num2"]
display(df.query("date == '2015-12-25'"))
# 如果在query方法中,需要使用外面定义的变量,可以在变量名称前加上@符号,进行引用。
s = "2015-12-25"
display(df.query("date == @s"))
四、数据转换
1. 应用apply与映射map
Series与DataFrame对象可以进行行(列)或元素级别的映射转换操作。对于Series,可以调用apply或map方法。对于DataFrame,可以调用apply或applymap方法。
常用参数:
-
apply:通过函数实现映射转换。【Series传递元素,DataFrame传递行或列。】
# 向apply方法中传递的函数,需要定义一个参数。 # 对于Series,依次传递每一个元素。对于DataFrame,则会依次传递每一行(每一列)。(取决于axis的值。) # 函数的返回值,用来表示处理的结果。 def manage(x): return x * 10 + x s = pd.Series([1, 2, 3, 4]) s1 = s.apply(manage) display(s1) # 对于非常简单的函数,我们可以使用lambda来实现。 s2 = s.apply(lambda x: x * 10 + x) display(s2) -
map:对当前Series的值进行映射转换。参数可以是一个Series,一个字典或者是一个函数。
# Series的map函数,提供的是一种映射。 s = pd.Series([1, 2, 3, 4]) # 里面的值,就类似于可以看做是位置索引 # 参数可以是Series,则根据Series的index来进行映射,获取结果值。 map_series = pd.Series(["a", "b", "c", "e"], index=[1, 2, 3, 4]) s1 = s.map(map_series) display(s1) # 参数也可以是一个字典。则根据字典的key进行映射,获取字典的value值。 map_dict = { 1:"a", 2:"b", 3:"c", 4:"d"} s2 = s.map(map_dict) display(s2) # map的参数也可以是一个函数,此时与apply有些类似。 s3 = s.map(lambda x: x + 3) display(s3) -
applymap:通过函数实现元素级的映射转换。
df = pd.read_csv("spider.csv", header=None) df.columns = ["date", "url", "name", "num1", "num2"] display(df.head(10)) # 关于DataFrame的apply与applymap方法。 df1 = df.apply(lambda x : print(type(x))) # 自行求均值。 df2 = df[["num1", "num2"]].apply(lambda x: x.mean()) display(df2) # 参数为一个函数,DataFrame中的每个元素都会调用一次该函数(将元素传递给该函数),获得一个映射的结果(函数的返回值)。 # applymap函数是一个元素级的映射,类似与Series的map函数。 df1 = df[["num1", "num2"]].applymap(lambda x: x + 100000) display(df1[df.notnull()].dropna().head(5))
2. replace()替换
Series或DataFrame可以通过replace方法可以实现元素值的替换操作。
常用参数:
-
[to_replace]:被替换值,支持单一值,列表,字典,正则表达式。
# 显示date,url这两列 s = df[["date", "url"]].head() display(s)# 替换。支持单个值,字典,列表,正则表达式 df1 = df.replace("http://www.apinpai.com/", "xxx") display(df1) # 字典1 df1 = df.replace({ "http://www.apinpai.com/":"xxx", "http://www.favolist.com/":"aaa"}) display(df1) # 字典2 df1 = df.replace(["http://www.apinpai.com/", "http://www.favolist.com/"], ["aaa", "bbb"]) display(df1) # 字典3 df2 = df.replace(["http://www.apinpai.com/", "http://www.favolist.com/"], "aaaaaa") display(df2) -
regex:是否使用正则表达式,默认为False。
# replace也支持正则表达式的形式。(这种是最为灵活的方式) # 注意:当需要进行正则表达式模式匹配时,需要将regex参数设置为True。(默认为False) s5 = s.replace(r"[0-9]{4}-4-28", "2017-01-01", regex=True) display(s5) -
apply或map
# replace的操作我们也可以通过apply或map来实现。 # s.map({"2015-4-28":"2034"}) def t(item): return "2034" if item == "2015-4-28" else item display(df["date"].map(t).head())
3. 字符串矢量级运算
Series含有一个str属性,通过str能够进行字符串的矢量级运算。
-
str.upper():大写转换运算、str.contains():bool运算
s = pd.Series([1, 2, 3]) display(s) # 使用Series的str属性时,需要Series元素的值是str(字符串)类型。 s = pd.Series(["abc", "def", "kefe"]) # str 的类型为pandas.core.strings.StringMethods,该类型提供了很多方法(与Python中str类型提供的方法相似),能够进行字符串的矢量级运算。 display(s.str) display(s.str.upper()) display(s.str.contains("b")) -
str.startswith():检查字符串是否是以指定子字符串开头,如果是则返回 True,否则返回 False。
df2 = df["url"].str.startswith("http://www.movie") display(df2.head()) -
pd.set_option()设置dataframe的输出显示
# pd.set_option()过滤 pd.set_option('max_colwidth',70) t = df[df["url"].str.startswith("http://www.movie")] sp = t["name"].str.split(";") display(sp.head()) -
str.split()切割
# 一列拆分成多列,在split的同时,增加参数expand的值为True。如果没有使用expand(默认为Fasle),则使用一个列表来存放拆分之后的元素。 sp = t["name"].str.split(";", expand=True) sp.info() display(sp.head()) -
注意事项
# 注意:我们执行替换之后,尽管Series元素的值是数值类型,但是,我们Series对象的类型是没有改变的。 sp[7] = sp[7].str.replace("票房(万)", "") display(sp.head()) # 对类型进行转换,转换成我们需要的类型(float) sp[7] = sp[7].astype(np.float64) display(sp[7].mean())
五、数据合并
head = df[["date", "num1", "num2"]].head() #设置前5行数据
tail = df[["date", "num1", "num2"]].tail() #设置后5行数据
tail.columns = ["date", "num4", "num3"] #设置后5行列名
display(head, tail) #打印前5行及后5行
date num1 num2 0 2015-4-28 216.0 1392.68 1 2015-8-24 273.0 1447.17 2 2015-12-14 NaN NaN 3 2015-4-2 52.0 337.27 4 2015-12-19 NaN NaN
date num4 num3 1391 2015-7-31 87.0 927.30 1392 2015-4-20 31.0 684.56 1393 2015-4-2 47.0 1419.74 1394 2015-4-15 124.0 1434.67 1395 2015-5-16 103.0 1020.50
1. concat()索引连接
我们可以通过DataFrame或Series类型的concat方法,来进行连接操作,连接时,会根据索引进行对齐。
# 在进行concat拼接(堆叠),时,会根据索引进行对齐。如果无法对齐,会产生空值。(NaN)
display(pd.concat((head, tail), sort=False))
date num1 num2 num4 num3 0 2015-4-28 216.0 1392.68 NaN NaN 1 2015-8-24 273.0 1447.17 NaN NaN 2 2015-12-14 NaN NaN NaN NaN 3 2015-4-2 52.0 337.27 NaN NaN 4 2015-12-19 NaN NaN NaN NaN 1391 2015-7-31 NaN NaN 87.0 927.30 1392 2015-4-20 NaN NaN 31.0 684.56 1393 2015-4-2 NaN NaN 47.0 1419.74 1394 2015-4-15 NaN NaN 124.0 1434.67 1395 2015-5-16 NaN NaN 103.0 1020.50
常用参数:
-
axis:指定连接轴,默认为0。
# 通过轴axis指定堆叠方向。0竖直方向,1水平方向。 display(pd.concat((head, tail), axis=0, sort=False)) display(pd.concat((head, tail), axis=1, sort=False)) -
join:指定连接方式,默认为外连接。【outer:并集,inner:交集】
# 我们可以通过join指定连接方式。(outer,结果集显示并集, inner结果集显示交集。) display(pd.concat((head, tail), join="inner")) -
keys:可以用来区分不同的数据组。
# 可以通过keys观看数据来源那一张表。(产生一个层级索引) display(pd.concat((head, tail), keys=["head", "tail"])) -
join_axes:指定连接结果集中保留的索引。
# 通过join_axes指定要保留的索引。列索引 display(pd.concat((head, tail), join_axes=[head.columns])) display(pd.concat((head, tail), join_axes=[tail.columns])) -
ignore_index:忽略原来连接的索引,创建新的整数序列索引,默认为False。
# 可以通过ignore_index设置为True,忽略以前的索引(行索引),重新创建连续的索引。 display(pd.concat((head, tail), ignore_index=True) -
sort:concat之后,是否按照索引排序
# 可以通过ignore_index设置为True,忽略以前的索引(行索引),重新创建连续的索引。 display(pd.concat((head, tail), ignore_index=True, sort=True))
2. append()类似concat()
在对行进行连接时,也可以使用Series或DataFrame的append方法。
append是concat的简略形式,只不过只能在axis=0上进行合并
# 测试pandas.append方法
def use_pd_append():
df = pd.DataFrame([[1, 2], [3, 4]], columns=list('AB'))
df2 = pd.DataFrame([[5, 6], [7, 8]], columns=list('AB'))
print(df)
print(df2)
# 一定要给出一个名字,这样才能存储,不在原有的dataFrame上操作
d = df.append(df2)
print(d)
A B #df结果
0 1 2
1 3 4
A B #df2结果
0 5 6
1 7 8
A B #d结果
0 1 2
1 3 4
0 5 6
1 7 8
3. merge 类似SQL的join()
通过pandas或DataFrame的merge方法,可以进行两个DataFrame的连接,这种连接类似于SQL中对两张表进行的join连接。
df1 = pd.DataFrame([[1, 2, 3], [3, 4, 5], [7, 8, 9]])
df2 = pd.DataFrame([[1, 2, 4], [3, 4, 6], [10, 11, 12]], columns=[0, 1, 3])
display(df1, df2)
# 根据所有同名字段(标签名)进行等值连接。默认是所有相同的列索引的值和行索引要一致
df1.merge(df2)
常用参数:
-
how:指定连接方式。可以是inner, outer, left, right,默认为inner。
# 通过how指定连接方式。默认为内连接。 df_r1 = df1.merge(df2, how="left") display(df_r1) df_r2 = df1.merge(df2, how="right") display(df_r2) df_r3 = df1.merge(df2, how="outer") display(df_r3) -
on 指定连接使用的列(该列必须同时出现在两个DataFrame中),默认使用两个DataFrame中的所有同名列进行连接。
# 通过on来指定连接的列(on指定的列必须同时出现在两个表之中)。(默认使用所有同名的列进行等值连接) display(df1.merge(df2)) display(df1.merge(df2, on=1)) -
left_on / right_on:指定左右DataFrame中连接所使用的列。
# 如果连接的列名不同,则我们可以使用left_on与right_on参数分别指定左,右两张表用来进行等值连接的索引名。 df1.merge(df2, left_on=1, right_on=3) -
left_index / right_index:是否将左边(右边)DataFrame中的索引作为连接列,默认为False。
# 通过left_index,right_index来指定,是否使用索引来充当连接条件。True,是,False,不是。 # 注意:left_index(right_index)与left_on(right_on)不能同时指定。 df_r1 = df.merge(df2, left_index=True, right_index=True) display(df_r1) df_r2 = df.merge(df2, left_index=True, right_on=1) display(df_r2) -
suffixes:当两个DataFrame列名相同时,指定每个列名的后缀(用来区分),默认为_x与_y。
df2["num2"] = [11,22,33] # 我们也可以自定义连接的后缀。(两张表存在同名字段时,可以使用。默认为_x,_y) df.merge(df2, left_index=True, right_index=True, suffixes=["_table1", "_table2"])
5. join()类似merge()
与merge方法类似,但是默认使用索引进行连接。
merge与join侧重点不同,merge侧重的是使用字段进行连接,而join侧重的是使用索引进行连接。
不同点:
- merge默认进行的内连接(inner),join默认进行的左外连接(left)。
- 当出现同名字段(列索引)时,merge可以自动补后缀(_x, _y),但是join不会自动补后缀,而是会产生错误。
- merge默认使用同名的列进行等值连接。join默认使用左右两表的索引进行连接。
- merge中on参数,指定两张表中共同的字段,而join中on参数,仅指定左表中的字段(右表依然使用索引)。
# 如果没有指定连接方式,默认为左外连接(left)
df.join(df2,lsuffix="_x", rsuffix="_y").head()
常用参数:
-
how:指定连接方式。可以是inner, outer, left, right,默认为left。
# 我们可以通过how指定连接方式。 df.join(df2, lsuffix="_x", rsuffix="_y", how="outer").head() -
on:设置当前DataFrame对象使用哪个列与参数对象的索引进行连接。
# on参数指定当前的表中使用哪个列与参数表(右侧表)的索引进行连接。 df1.join(df2, lsuffix="_x", rsuffix="_y", on=0) -
lsuffix / rsuffix:当两个DataFrame列名相同时,指定每个列名的后缀(用来区分),如果不指定,列名相同会产生错误。
多层索引与分组聚合
3. MultiIndex多层索引
通过多层次索引,我们就可以使用高层次的索引,来操作整个索引组的数据。
创建方式
-
第一种
我们在创建Series或DataFrame时,可以通过给
index(columns)参数传递多维数组,进而构建多维索引。
【数组中每个维度对应位置的元素,组成每个索引值】多维索引的也可以设置名称
names属性,属性的值为一维数组,元素的个数需要与索引的层数相同(每层索引都需要具有一个名称)。# Series创建多层索引, 通过index指定一个多维的列表(数组)。 # 单层索引,指定一个一维数组。 s = pd.Series([1, 2, 3, 4], index=["a", "b", "c", "d"]) display(s) # 多层索引,指定一个多维数组。多维数组中,逐级给出每层索引的值。 s = pd.Series([1, 2, 3, 4], index=[["A", "A", "B", "B"], ["a", "b", "c", "d"]]) # 多于多层索引,每一层都具有一个名字。 s.index.names = ["abc", "def"] display(s)# DataFrame创建多层索引 df = pd.DataFrame([[1, 2, 3], [4, 5, 6], [7, 8, 9]], index=[["A", "A", "B"], ["a", 'b', 'b']]) display(df) df = pd.DataFrame(np.arange(9).reshape(3, 3), columns=[["A", "A", "B"], ["a", 'b', 'b']]) display(df) display(df["A"]) display(df["A", "a"]) -
第二种
我们可以通过
MultiIndex类的相关方法,预先创建一个MultiIndex对象,然后作为Series与DataFrame中的index(或columns)参数值。同时,可以通过names参数指定多层索引的名称。-
from_arrays:接收一个多维数组参数,高维指定高层索引,低维指定底层索引。
# 通过列表的方式进行创建。(每个内嵌列表元素指定层次的索引,[[第0层索引], [第1层索引],……[第n层索引]]) m1 = pd.MultiIndex.from_arrays([["A", "A", "B"], ["a", "b", "b"]]) df1 = pd.DataFrame(np.random.random((3,3)), index=m1) display(df1) -
from_tuples:接收一个元组的列表,每个元组指定每个索引(高维索引,低维索引)。
# 通过元组构成列表的方式进行创建。[(高层,底层), (高层, 底层), ……] m2 = pd.MultiIndex.from_tuples([("A", "a"), ("A", "b"), ("B", "b")]) df2 = pd.DataFrame(np.random.random((3, 3)), index=m2) display(df2) -
from_product:接收一个可迭代对象的列表,根据多个可迭代对象元素的笛卡尔积进行创建索引。
# 通过乘积(笛卡尔积)的方式进行创建。 m3 = pd.MultiIndex.from_product([["A", "B"], ["a", "b"]]) df3 = pd.DataFrame(np.random.random((4, 3)), index=m3) display(df3)
-
多层索引操作
对于多层索引,同样也支持单层索引的相关操作,例如,索引元素,切片,索引数组选择元素等。我们也可以根据多级索引,按层次逐级选择元素。
多层索引的优势:通过创建多层索引,我们就可以使用高层次的索引,来操作整个索引组的数据。
常用参数:其中,操作可以是索引,切片,数组索引,布尔索引。
- s[操作]
- s.loc[操作]
- s.iloc[操作]
Series多层索引
-
通过
loc(标签索引)操作,可以通过多层索引,获取该索引所对应的一组值。s = pd.Series([1, 2, 3, 4], index=[["A", "A", "B", "B"], ["a", "b", "a", "b"]]) display(s) # 通过访问外层索引,可以获取该外层索引对应的一组值。 display(s["A"]) # 多层索引,不直接直接使用内层索引访问。 # display(s["a"]) # 代码会报错 # 可以通过索引逐层进行访问 display(s["A", "a"]) -
通过
iloc(位置索引)操作,会获取对应位置的元素值(与是否多层索引无关)。# 对于iloc,就是根据位置进行访问,与是否存在多层索引,关系不大。 display(s.iloc[1]) display(s[["A", "B"]]) -
通过
s[操作]的行为有些诡异,建议不用。- 对于索引(单级),首先按照标签选择,如果标签不存在,则按照位置选择。
- 对于多级索引,则按照标签进行选择。
- 对于切片,如果提供的是整数,则按照位置选择,否则按照标签选择。
- 对于数组索引, 如果数组元素都是整数,则根据位置进行索引,否则,根据标签进行索引。
DataFrame多层索引
-
通过loc(标签索引)操作,可以通过多层索引,获取该索引所对应的一组值。
df = pd.DataFrame(np.random.rand(3, 3), index=[["A", "A", "B"], ["a", "b", "b"]]) display(df) # 通过多层索引来访问 display(df.loc["A", "a"]) -
通过iloc(位置索引)操作,会获取对应位置的一行(与是否多层索引无关)。
# 通过位置索引来访问 display(df.iloc[0]) -
通过s[操作]的行为有些诡异,建议不用。
- 对于索引,根据标签获取相应的列(如果是多层索引,则可以获得多列)。
- 对于数组索引, 根据标签,获取相应的列(如果是多层索引,则可以获得多列)。
- 对于切片,首先按照标签进行索引,然后再按照位置进行索引(取行)。
2. swaplevel交换索引
我们可以调用DataFrame对象的swaplevel方法来交换两个层级索引。该方法默认对倒数第2层与倒数第1层进行交换。我们也可以指定交换的层。层次从0开始,由外向内递增(或者由上到下递增),也可以指定负值,负值表示倒数第n层。除此之外,我们也可以使用层次索引的名称来进行交换。
df = pd.DataFrame(np.random.rand(4, 4), index=[["A", "A", "B", "B"], ["a1", "a1", "b1", "c1"], ["a2", "b2", "c2", "c2"]])
df.index.names = ["layer1", "layer2", "layer3"]
display(df)
# 多层索引,编号从外向内,0, 1, 2, 3.同时,索引编号也支持负值。
# 负值表示从内向外,-1, -2, -3. -1表示最内容。
# 交换多层索引的两层。默认交换最内层与倒数第二层。(最里面的两层)
display(df.swaplevel(0, 2))
# 交换多层索引时,我们除了可以指定层次的编号外,也可以指定索引层次的名称。
display(df.swaplevel("layer1", "layer3"))
sort_index索引排序
我们可以使用sort_index方法对索引进行排序处理。
df = pd.DataFrame(np.random.rand(4, 4), index=[["A", "B", "B", "A"], ["b", "b", "a", "c"], ["b2", "c2", "a2", "c2"]])
df.index.names = ["layer1", "layer2", "layer3"]
display(df)
# 索引排序,默认进行最外层的排序。
display(df.sort_index())
-
level:指定根据哪一层进行排序,默认为最外(上)层。该值可以是数值,索引名,或者是由二者构成的列表。
# 自定义排序的层次。 display(df.sort_index(level=1)) display(df.sort_index(level=2)) # 也可以通过索引的名称进行排序。 display(df.sort_index(level="layer1")) display(df.sort_index(level="layer2")) -
inplace:是否就地修改。默认为False。
stack索引堆叠
通过DataFrame对象的stack方法,可以进行索引堆叠,即将指定层级的列转换成行。 level:指定转换的层级,默认为-1。
# 进行堆叠 列->行 取消堆叠 行->列
df.stack()
# stack堆叠也可以指定层次。
# stack堆叠也可以通过索引名进行操作。
df.stack(0)
unstack取消堆叠
通过DataFrame对象的unstack方法,可以取消索引堆叠,即将指定层级的行转换成列。 level:指定转换的层级,默认为-1。 fill_value:指定填充值。默认为NaN。
# 取消堆叠,如果没有匹配的数据,则显示空值NaN。
display(df.unstack())
# 我们可以指定值去填充NaN(空值)。
df.unstack(fill_value=11)
# unstack默认会将最内层取消堆叠,我们也可以自行来指定层次。
display(df.unstack(0))
# 除了指定层次序号外,我们也可以指定层次(索引)的名称。
display(df.unstack("layer1"))
set_index设置索引
在DataFrame中,如果我们需要将现有的某一(几)列作为索引列,可以调用set_index方法来实现。
# 设置参数指定的列,充当新的索引。
display(df.set_index("pk"))
# 也可以设置层级索引。
display(df.set_index(["pk", "name"]))
-
reindex:字典重组索引
# 字典是无序的,如果需要顺序调整。 df = df[["pk", "name", "age"]] display(df) # 也可以通过reindex来重新组织索引。 df1 = df.reindex(["pk", "age", "name"], axis=1) display(df1) -
drop:是否丢弃作为新索引的列,默认为True。
# 默认情况下,充当新索引的列会被丢弃,我们可以通过drop=False设置依然保留。 df1 = df.set_index("pk", drop=False) display(df1) -
append:是否以追加的方式设置索引,默认为False。
# append用来设置是否以追加的形式设置索引(层级索引)。默认为False(取代以前的索引)。 df2 = df.set_index("name", append=True) display(df2) -
inplace:是否就地修改,默认为False。
# df就地生效 df.set_index("pk", inplace=True) display(df)
reset_index重置索引
调用在DataFrame对象的reset_index,可以重置索引。该操作与set_index正好相反。
# 重置索引。默认情况下重置所有层次的索引。如果所有层次的索引均被重置,则重新生成整数序列的索引。
df2 = df.reset_index()
display(df2)
-
level:重置索引的层级,默认重置所有层级的索引。如果重置所有索引,将会创建默认整数序列索引。
-
drop:是否丢弃重置的索引列,默认为False。
# 默认情况下,充当新索引的列会被丢弃,我们可以通过drop=False设置依然保留。 df1 = df.set_index("pk", drop=True) display(df1) -
inplace:是否就地修改,默认为False。
# 我们也可以指定重置索引的层次。【如果重置索引之后,还有索引层次(没有重置所有层次的索引),则不会重新生成整数序列的索引。】 df.reset_index(0, inplace=True) # 重置索引后,默认重置索引会充当新的列,如果不需要重置的索引充当新的列,可以指定drop=True。 df.reset_index(0, drop=True)
3. groupby分组
我们可以通过groupby方法来对Series或DataFrame对象实现分组操作。该方法会返回一个分组对象。不过,如果直接查看(输出)该对象,并不能看到任何的分组信息。
df = pd.DataFrame({
"部门":["A", "A", "B", "B"], "利润":[10, 20, 15, 28], "人员":["a", "b", "c", "d"], "年龄":[20, 15, 18, 30]})
# 根据部门进行分组,返回一个分组对象。
g = df.groupby("部门")
display(g)
{‘A’: Int64Index([0, 1], dtype=‘int64’),
‘B’: Int64Index([2, 3], dtype=‘int64’)}
# 返回每组的统计信息。
display(g.describe())

-
groups(属性):返回一个字典类型对象,包含分组信息。
# 返回分组对象的信息。 display(g.groups) -
size:返回每组记录的数量。
# 返回每组的数量。 display(g.size())部门
A 2
B 2
dtype: int64 -
discribe:分组查看统计信息。
# 返回每组的统计信息。 display(g.describe())
迭代
我们也可以使用for循环来对分组对象进行迭代。迭代每次会返回一个元组,第1个元素为用来分组的key,第2个元素为该组对应的数据。
# 分组信息不像列表那样,我们可以直接输出查看。(类似于迭代器的机制,是需要时,动态进行计算的。)
# 我们可以通过for循环来查看分组对象的数据。类似字典的形式,key-> 分组列的值。 value-> 分组对应的数据记录。
for k, v in g:
display(k, v)
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-rIJbwGrx-1606285252796)(http://qnimg.cryueh.com/img/image-20201123130112547.png)]
分组的方式
使用groupby进行分组时,分组的参数可以是如下的形式:
-
索引名:根据该索引进行分组。
# 进行单一的分组,提供单一的标签。 g = df.groupby("部门") for k, v in g: display(k, v)[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-njModtLx-1606285252798)(http://qnimg.cryueh.com/img/image-20201123130300457.png)]
-
索引名构成的数组:根据数组中每个索引进行分组。
# 进行多分组,提供多标签构成的列表。 g = df.groupby(["部门", "小组"]) for k, v in g: display(k, v)[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-1yh7pOWQ-1606285252799)(http://qnimg.cryueh.com/img/image-20201123130338315.png)]
-
字典或Series:key指定索引,value指定分组依据,即value值相等的,会分为一组。
# 提供一个字典(Series),key提供索引, value提供组名。结果就会根据value相同的记录,分到一组。 g = df.groupby({ 0:1, 1:1, 2:2, 3:2}) for k, v in g: display(k, v)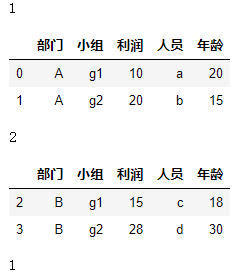
# 我们还可以根据列进行分组。将axis参数指定为1。 g = df.groupby({ "人员":1, "利润":1, "小组":2, "年龄":2, "部门":2}, axis=1) for k, v in g: display(k, v)
-
函数:接受索引,返回分组依据的value值。
# 4 提供一个函数。函数需要具有一个参数。用来依次接收索引值。函数还需要具有一个返回值,用来指定组。 # 如果看成字典的形式,函数接收key,返回value。 # x就是索引值 g = df.groupby(lambda x: x % 2) for k, v in g: display(k, v)[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-Yrefz1wy-1606285252801)(http://qnimg.cryueh.com/img/image-20201123130531435.png)]
apply
对分组对象,可以调用apply函数,该函数接收每个组的数据,返回操作之后的结果。apply最后会将每个组的操作结果进行合并(concat)。
# 分组的方式:
# 每个索引,会依次传递到函数中(index)。
def group_helper(index):
# if index > 5:
# return 0
# else:
# return 1
return 0 if index > 2 else 1
# 对于传递进行的索引 0, 1, 2, 3
# 每个索引对应的返回值
# 0 -> 1
# 1 -> 1
# 2 -> 1
# 3 -> 0
# 根据函数返回的value值,索引0, 1, 2 分到一组,索引3分到一组。
# 类似的,对于Series或字典来说,
# df.groupby({0:1, 1:1, 2:1, 3:0})
# df.groupby(group_helper)
# 分组对象也可以进行apply。apply接收一个函数(参数)。函数具有一个参数,用来依次接收每一个分组数据,并且返回每一个分组数据的结果。
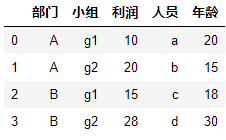
df = pd.DataFrame({
"部门":["A", "A", "B", "B"],"小组":["g1", "g2", "g1", "g2"], "利润":[10, 20, 15, 28],
"人员":["a", "b", "c", "d"], "年龄":[20, 15, 18, 30]})
display(df)
# apply当前实现的细节:对于第一个分组,会调用函数两次。(但是,不影响apply最后进行concat合并的结果)
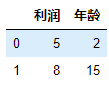
g.apply(lambda x: x.sum(numeric_only=True))

g.apply(lambda x: x.max(numeric_only=True) - x.min(numeric_only=True))
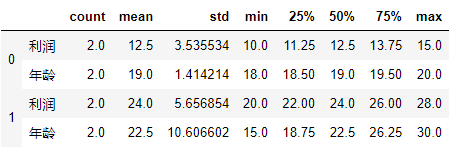
g.apply(lambda x: x.describe().T)
4. 聚合
可以在分组对象上进行聚合(多个值变成一个值)。例如,mean(),sum()等。
除此之外,我们也可以调用agg方法,实现自定义的聚合方式。函数接收一行(一列),返回该行(列)聚合后的结果。
# 在整个DataFrame上进行聚合。
g.sum()
# 在指定的列上进行聚合。
g["利润"].sum()
df = pd.DataFrame({
"利润":[10, 20, 15, 28], "年龄":[20, 15, 18, 30]})
display(df)

# DataFrame与分组对象可以调用agg / aggregate方法,来实现聚合操作。
# 关于agg方法,可以接收的参数类型:
# 1 函数说明字符串,例如,sum,mean,std
display(df.mean())
display(df.agg("mean"))

# DataFrame 进行聚合时,默认会包含所有列,我们可以指定numeric_only参数为True,这样只会聚合(统计)数值类型的行(列)。
display(df.sum(numeric_only=True))
利润 73
年龄 83
dtype: int64
# 2 多个函数字符串构成的列表
display(df.agg(["mean", "sum", "max"]))
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-wZTyblYv-1606285252803)(http://qnimg.cryueh.com/img/image-20201123132026100.png)]
# 3 字典 key:指定列标签,value:指定统计的信息。
# 优势:可以针对不同的列, 提供不同的聚合信息。
display(df.agg({
"利润":["mean", "sum"] , "年龄":["max", "min"]}))

# 4 函数, 可以实现自己的聚合方式。函数具有一个参数,用来接收DataFrame传递过来的每一列(行),返回操作之后的结果。
display(df.agg(lambda x: x.mean()))
利润 18.25
年龄 20.75
dtype: float64
# 函数接收的是每个组的每一个列(行)。函数的返回值作为最终聚合的结果。
display(g.agg(lambda x: x.max()))
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-vFI8jj5U-1606285252804)(http://qnimg.cryueh.com/img/image-20201123132135604.png)]