开学到现在,可以说我还没有从假期的状态中恢复过来,计划好的每天要看两篇文献却迟迟没有付诸行动,直到今天(不好意思中)。所以一直很佩服那些自制力强的人。
细读了两篇,只有以下一篇让我收获最多,因此对此进行总结,并非个人想法。
[1]荆永君,李兆君,李 昕.基础教育资源网中个性化资源推荐服务研究[J].中国电化教育,2009,(8)102-105.
该文章建立用户兴趣模型和资源描述模型,通过将两种模型进行匹配,从而向用户推荐所需要的资源。
一、建模
1.用户兴趣模型
信息来源通过在线兴趣调查和行为跟踪(使用、搜索和定制资源等行为)。对收集到的信息采用关键词向量空间来表示拥护兴趣模型。由于对某一关键词所表示的内容不同知识背景的用户会有不用的理解。所以模型中引入学科、学段作为知识背景限制。在关键词向量空间中引入基于时态变化的兴趣权重,来表示用户兴趣的衰减与更新。根据艾宾浩斯的遗忘曲线,对于兴趣权重,采用基于时间窗原理进行用户兴趣的衰减和更新。即:在时间窗Δt内,如果关键词kn每出现一次,则关键词kn的兴趣权重增加单位a;否则兴趣权重衰减单位b。如某学科教师用户兴趣模型为:
{语文,小学一年,{(唐诗,0.9),(李白,0.9),(静夜思,5.95),(领读,1.9),(司马光,2),(历史典故,2)}}
2.资源描述模型
在描述资源模型时,下面两方面因素是应该考虑的:(1)资源的适用对象和所属学科。因为同样的关于“三角形”的资源,五年级介绍的是认识三角形的边、角及面积计算,而在七年级介绍的是三角形的三线及内、外角和的定理。(2)描述资源内容特征的属性。其中,关键词是最能体现资源内容特征的属性。一个资源一般由多个关键词项(5—10个)组成,权重则表示关键词对描述资源内容的重要程度。所以,系统中的资源描述采用和用户兴趣模型类似的表示方法,每个资源由学科、学段为知识背景的关键词向量空间表示,资源描述信息(所属学科、学段、关键词列表以及关键词的权重值),都在资源设计阶段由资源创意人员给出。如:一个七年级数学关于多边形内角和的课件,其资源描述模型为:{数学,初中七年,{(多边形,0.4),(内角和,0.4),(探究,0.2)}}
二、模型
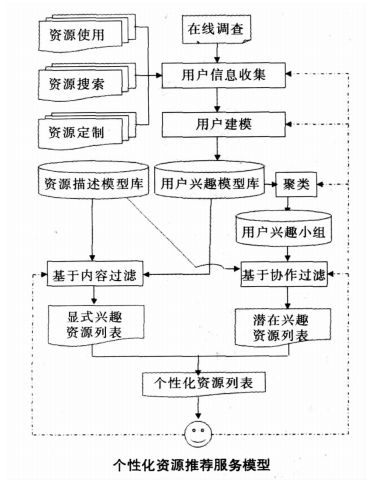
个性化服务可以通过基于内容和基于协作的信息过滤技术来实现。基于内容的过滤技术是通过比较资源与用户兴趣模型来推荐资源,其优点是简单、有效,缺点是只能发现与用户已有兴趣相似的资源,不能为用户发现新的感兴趣资源。基于协作的过滤技术是比较用户兴趣模型,根据用户的相似性来推荐资源。其优点是有可能为用户推荐出新的感兴趣资源,缺点是用户过少或过多时该方法性能很低。为了提高个性化推荐服务的性能,本文讨论的资源推荐方法,将基于内容和基于协作结合起来,实现混合推荐。
在模型中,用户信息收集模块是个性化服务系统的基础模块,负责收集用户兴趣信息,一方面通过在线兴趣调查获得用户主动描述出来的显式兴趣信息,如媒体类型偏好,兴趣主题描述等;另一方面通过行为跟踪收集用户在资源使用过程中的隐式兴趣信息。行为跟踪主要包括:(1)用户的资源使用信息。(2)用户的资源搜索信息。(3)用户的资源定制信息。
用户建模模块根据收集到的用户兴趣信息,进行去噪、加权、构建或更新用户兴趣模型,通过聚类分析等数据挖掘技术,形成用户兴趣小组存入用户兴趣小组信息库。通过混合推荐技术,形成显性和潜在兴趣资源组成的用户个性化资源列 表 提 供 给 用户。资源列表呈现方式根据用户的选择可以采用网页或e-Mail的方式推送给用户。模型中虚线表示用户的反馈信息。
三、个性化资源推荐的实现方法
在个性化服务模型中基于内容过滤的处理是通过比较资源与用户兴趣模型来推荐资源,其关键步骤是资源和用户兴趣相似度的计算。对于向量空间模型来说,通常采用的方法有欧氏距离、余弦距离和内积。
用户兴趣关键词向量和资源描述关键词向量的距离越大表明它们的相似度也就越大,反之则越小。实现流程为:首先提取用户兴趣,然后选取与用户具有相同背景(学科、学段)的资源,分别计算资源与用户兴趣的欧氏距离存入资源与兴趣距离列表中并按照相似度大小降序排列,最后按照TOPn原则从距离列表中,选择前n个相关度较高的资源推荐给用户。
基于协作过滤技术的关键是建立用户兴趣小组,在用户兴趣小组聚类时,以相同背景为前提,对同一学科和学段的所有用户兴趣关键词采用成熟的聚类算法(如蚁群聚类)进行聚类,从而形成用户兴趣小组。
用户兴趣小组建立后,便可以根据用户兴趣小组来推荐资源。在选择资源时,对每个资源计算它和兴趣小组的相似度,将相似度高并且不在用户已推荐资源列表中的资源作为该用户潜在感兴趣的资源推荐给用户。为用户兴趣小组进行个性化资源选择的处理方法和基于内容过滤的资源选择方法相同。