初露锋芒的深度学习
【神经网络系列】初露锋芒的深度学(一)
就在最近,Google Brain 高级研究科学家 Barret Zoph发帖表示他们设计了一个名为Switch Transformer的简化稀疏架构,直接将参数量从GPT-3的1750亿拉高到1.6万亿,并比之前最大的、由google开发的语言模型T5-XXL足足快了4倍。

庞大的数据规模和成熟的并行式计算框架,让超大规模神经网络再次突破了训练瓶颈,也展现了数据时代中深度学习的无限可能。不敢说此次推出的“巨无霸”模型——Switch Transformer已经达到了深度学习规模的天花板,但它确是深度学习疯狂成长时期的又一大事记。
正值年末,我们就一起回顾一下嗷嗷待哺中的深度学习幼年时期的重要成果,你将会了解到一些经典网络模型的发展过程。
我们知道,神经网络的发展,迄今有三次浪潮,第三次发展才真正是深度学习的革命,为了更好了解深度学习的发展过程,我们就一起简单回顾一下它发生在上个世纪的前世情缘。
第一代神经网络是1957年心理学家罗森布拉特(Frank RosenBlatt)构想的感知机,它可以解决简单的分类的问题,如果利用多层感知机还可以解决具有多个输出值或者多分类的问题。
但它的算法只有输入和输出层两层,主要是线性结构,不能解决线性不可分的问题(如异或XOR),对稍微复杂的函数就无能为力了。对于多层感知机来说,也没有合适的训练方法。于是在1969年,人工智能之父 Minsky(和Seymour Papert)在《感知器》(Perceptrons)一书里就给感知器判了“死刑”,神经网络的第一次浪潮也就此结束。
而第二个神经网络时代的开启就意味着第一代神经网络的缺陷有了解决方案。相比于第一代神经网络,第二代在输入层和输出层之间填空了含有多个隐含层的感知机,可以引用非线性结构,同时Hinton等人还提出了BP算法来解决多层神经网络训练的问题。
大家也都对神经网络报有了很高的期待,数以千计的新模型被提出来,比如Hopfield网络、自组织特征映射(SOM)网络、双向联想记忆(BAM)、卷积神经网络(CNN)、循环神经网络(RNN)、玻尔兹曼机等。其中很多网络都在后来深度学习的时代又继续被发扬光大。
但在训练过程中,随着网络层数的增加,参数的数量也会爆炸式增长,这就直接提高了训练的成本。同时,优化函数也更容易出现局部最优解的情况,训练效果可能还不如浅层的网络。这些问题又导致神经网络的研究进入了“寒冬”。
时间很快来到了2006年,Hinton 发表了一篇论文《A Fast Learning Algorithm for Deep Belief Nets》,提出了降维和逐层预训练方法,该方法可成功运用于训练多层神经网络DNN,在一定程度上解决了梯度消失的问题,使深度网络的实用化成为可能。
由此揭开了以数据驱动的深度学习的浪潮,第三代神经网络开始正式兴起,而其中标志性事件之一就是ImageNet ILSVRC 2012竞赛。
在竞赛中,Hinton团队应用AlexNet和Dropout 方法处理ImageNet,取得了惊人的效果。讲到AlexNet,就不得不说早在20世纪80年代就被提出的卷积神经网络(CNN)。
结合图像处理和神经网络的卷积神经网络CNN是通过卷积核将上下层进行链接,同一个卷积核在所有图像中是共享的,图像通过卷积操作后仍然保留原先的位置关系,它不仅能有效的减少隐藏层中的参数,还能够通过卷积核函数来挖掘局部特征。
总体来看,卷积神经网络主要由两部分组成,一部分是特征提取(卷积、激活函数、池化),另一部分是分类识别(全连接层),下图便是著名的手写文字识别卷积神经网络LeNet结构图:

当然,CNN在处理图像识别有天然优势,它已经成为了图像分类的黄金标准,一直在不断的发展和改进。刘昕博士总结了CNN的演化历史,如下图所示:

CNN的起点是神经认知机模型,此时已经出现了卷积结构,经典的LeNet诞生于1998年。随着ReLU、dropout的提出,以及GPU和大数据带来的历史机遇,CNN在2012年迎来了历史突破:AlexNet。随后几年,CNN呈现爆发式发展,各种CNN模型涌现出来。下图是几个经典模型(AlexNet、VGG、NIN、GoogLeNet、ResNet)的对比图,可见网络层次越来越深、结构越来越复杂,当然模型效果也是越来越好:

下面将简要说一下站在前人的肩膀上,这些后起之秀们究竟做了哪些改变。
对于AlexNet来说,采用ReLU作为激活函数,使用了数据增强,使用了mini-batch SGD优化函数,在GPU上加速训练,又通过Dropout层来实现过拟合。但其实除了Dropout之外,其他的亮点都是之前其他人工作的拼接。
而对于VGG来说,它探索了卷积神经网络的深度和其性能之间的关系,成功地构建了16-19层深的卷积神经网络,最后不仅错误率大幅下降,且拓展性很强,迁移到其他的数据的泛化性能也很好。其实除了加深层数,在VGG中还使用多个较小卷积核的卷积层来代替一个卷积核较大的卷积层,一方面可以减少参数,另一方面相当于进行了更多的非线性映射,可以增加网络的拟合和表征能力。

VGG网络结构图
作为2014年的ImageNet挑战赛双雄之一的GoogLeNet,它和第二名的VGG共同的特点是层次更深了,VGG继承了LeNet以及AlexNet的一些框架结构,而GoogLeNet则做了更加大胆的网络结构尝试,虽然深度只有22层,但大小却比AlexNet和VGG小很多,GoogleNet参数为500万个,AlexNet参数个数是GoogleNet的12倍,VGGNet参数又是AlexNet的3倍,因此在内存或计算资源有限时,GoogleNet是比较好的选择;从模型结果来看,GoogLeNet的性能也更加优越。它的创造性尝试就是搭建了一个兼具稀疏性、高计算性能的Inception网络结构,从而用稀疏连接来代替全连接,减少参数训练成本。下图是Inception的基本结构。

Inception的基本结构
仅仅过了一年,何凯明大神又提出了大名鼎鼎Resnet网络,相信大家不会陌生。它比之前的网络更深了,同时它还是第一个在ImageNet图片分类上表现超过人类水准的算法。但前面提到,网络太深会出现梯度消失或梯度爆炸的问题,难以训练。但该网络不仅能解决了模型太深而导致的网络退化的问题,还能提升模型精度。
如何做到的呢?
简单来说,就是通过叠加多层网络,使某一层的输出X可以直接跨过几层作为后面某一层的输入,训练目标值H(x)和x的差值F(x)的直至结果逼近0,来保证中间这段训练网络没有退化。

ResNet在ILSVRC2015竞赛中惊艳亮相,一下子将网络深度提升到152层,将错误率降到了3.57%,在图像识别错误率和网络深度方面,比往届比赛有了非常大的提升,毫无悬念地夺得了ILSVRC2015的第一名。
想要了解更多,可以去阅读下何凯明关于深度残差网络的两篇经典论文。
《Deep Residual Learning for Image Recognition》(基于深度残差学习的图像识别)
《Identity Mappings in Deep Residual Networks》(深度残差网络中的特征映射)
讲完基于CNN的几个经典模型,我们再来看看循环神经网络(RNN)。
虽然RNN和LSTM(长短记忆网络)被发明于上世纪80、90年代,但于2014年死而复生。接下来的几年里,它们成为了解决序列学习、序列转换(seq2seq)的方式,这也使得语音到文本识别和Siri、Cortana、Google语音助理、Alexa的能力得到惊人的提升。
在普通的全连接网络或CNN中,每层神经元的信号只能向上一层传播,样本的处理在各个时刻独立,因此又被成为前向神经网络(Feed-forward Neural Networks)。而在RNN中,神经元的输出可以在下一个时间段直接作用到自身,所以(t+1)时刻网络的最终结果O(t+1)就是该时刻输入和所有历史共同作用的结果,这就达到了对时间序列建模的目的。
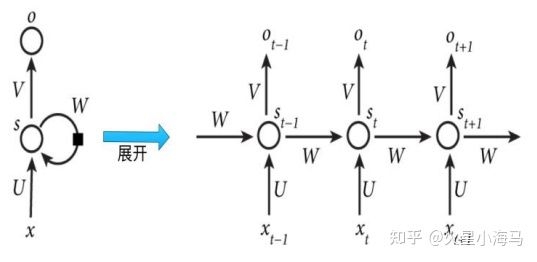
但如果时间太长,也就是深度太深,同样难以训练,所以RNN存在无法解决长时依赖的问题。为了解决这个问题呢,又提出了长短记忆网络(LSTM),通过cell门开关实现时间上的记忆功能,保证网络不退化。

可以看到图中LSTM在输入上多了一个C的参数,它能对上一个阶段的传进来的输入进行遗忘和记忆的筛选,得到更新的输入,最后得到传输状态ht,最终得到本阶段的输出ct。
简单来说,LSTM就是通过门控状态来控制传输状态,记住需要长时间记忆的,忘记不重要的信息;而不像普通的RNN那样只能够“呆萌”地仅有一种记忆叠加方式。LSTM能够学习复杂的序列,如莎士比亚式写作、原生态音乐的创作。
但LSTM及其衍生网络(如GRU)也只能在一定程度上解决长时带来的梯度问题,且参数量更大,训练对硬件条件要求非常高,计算费时。
下一篇呢,我们会继续介绍一些其他的经典网络模型。
参考文献:
【1】Britz D.,Deep Learning's Most Important Ideas - A Brief Historical Review
原文链接:https://dennybritz.com/blog/deep-learning-most-important-ideas/
【2】雪饼,CNN进化史,https://my.oschina.net/u/876354/blog/1797489
【3】Charniak E. 深度学习导论【M】. 北京:人民邮电出版社,2020
【4】Kurenkov A. A Brief History of Neural Nets and Deep Learning
原文链接:https://www.skynettoday.com/overviews/neural-net-history